北方工業大學gpa計算
This is my firts publication here and i will start simple.
這是我的第一篇出版物,這里我將簡單介紹 。
I want to make an exploratory data analysis of UFRN’s warehouse and answer some questions about the data using Python and Power BI.
我想對UFRN的倉庫進行探索性數據分析,并使用Python和Power BI回答有關數據的一些問題。
I have downloaded the dataset from “dados.gov.br”, wich is an open source website of public data from Brazil. You can have the used dataset here 👈
我已經從“ dados.gov.br ”下載了數據集,該數據集是來自巴西的公共數據的開源網站。 您可以在這里擁有使用的數據集👈
QUESTIONS TO BE ANSWERED:
需要回答的問題:
What are the items with the greatest quantity in stock;
庫存量最大的物品是什么?
What are the items with the greatest value in stock;
庫存中價值最大的物品是什么?
Wich warehouse has the greatest quantity of items in stock and wich has the lower quantity;
Wich 倉庫的庫存物品最多,而數量 較少的 倉庫 ;
Wich warehouse has the greatest value in stock;
Wich 倉庫的庫存價值 最大 。
What are the most expensive items.
什么是最昂貴的物品。
So, let’s start importing pandas in the Jupyter Notebook and opening the csv file:
因此,讓我們開始在Jupyter Notebook中導入熊貓并打開csv文件:
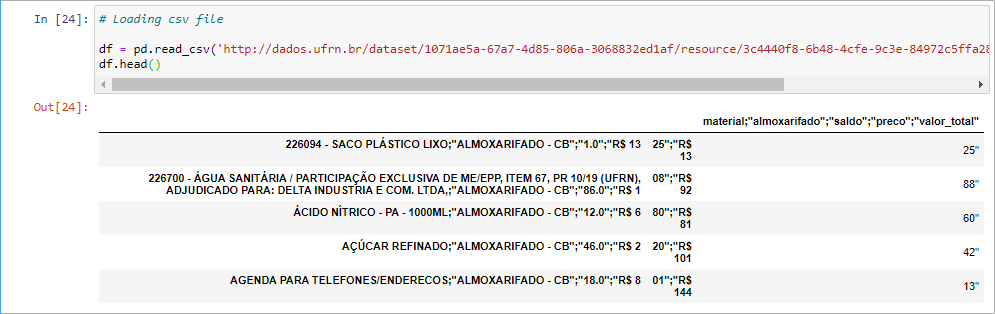
Here ? we have our first problem:
?我們有第一個問題:
File is strange. Seems that all informations are in the same column…
文件很奇怪 。 似乎所有信息都在同一列中…
This factor makes it impossible to analyse the dataframe by column as we can see below:
這個因素使我們無法按列分析數據幀,如下所示:

The problem in this case is the separator. Pandas uses the comma as default delimiter (or separator), and in this file, the delimiter is semicolon.
在這種情況下,問題是分隔符。 Pandas使用逗號作為默認定界符(或分隔符),在此文件中,定界符為分號。
So, we need to inform the delimiter right after the path file:
因此,我們需要在路徑文件之后立即通知定界符:
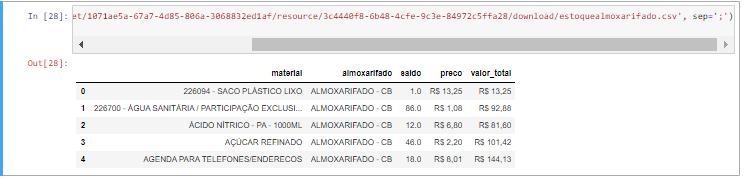
Now, here we go! ?
現在,我們開始! ?
Let’s check some informations about the dataset, like columns, data types, lenght, and missing values.
讓我們檢查有關數據集的一些信息,例如列 , 數據類型 , 長度和缺失 值 。
Note that we have 5 columns:
請注意,我們有5列:


material (Item): object;almoxarifado (Warehouse): object;saldo (balance): float;preco (price): object;valor_total (Amount): object;
材料 (項目):對象; almoxarifado (倉庫):對象; saldo (平衡):浮動; preco (價格):對象; valor_total (金額):對象;
If we had to make some operations between columns, we should probably change some object types to integer or float values, but in this case we won’t need.
如果必須在列之間進行某些操作,則可能應將某些對象類型更改為整數或浮點值,但在這種情況下,我們將不需要。
Now we can analyse data through columns
現在我們可以通過列分析數據
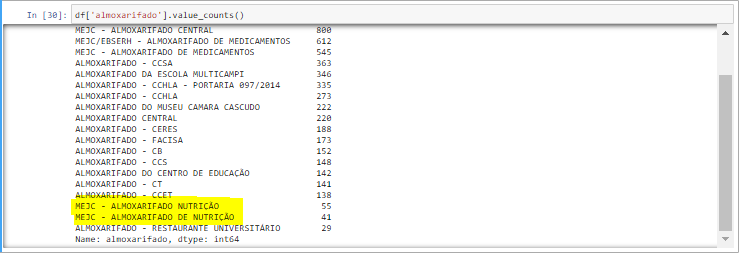
? Above we have the second issue:
?以上是第二個問題:
There are 2 different names for the same warehouse: “MEJC — ALMOXARIFADO NUTRI??O” and “MEJC — ALMOXARIFADO DE NUTRI??O”.
有對同一倉庫2個不同的名字:“MEJC - ALMOXARIFADONUTRI??O”和“MEJC - ALMOXARIFADO DENUTRI??O”。
It’s a typo, so let’s make them one.
這是一個錯字,因此讓我們將它們設為一個。

Done!
做完了!
A very quick and easy way to have a lot of information in one code line is using Pandas Profilling.
使用Pandas Profilling是在一個代碼行中具有很多信息的非常快速,簡便的方法。
Analysing the earlier infos and Pandas Profilling below, we have: 9087 rows and 4536 distinct items. 49.9% unique items and 0 missing cells.
分析下面的早期信息和Pandas Profilling,我們有9087行和4536個不同的項目。 49.9%的獨特物品和0個丟失的單元格。
It means that dataframe doesn’t need much effort in cleaning and treatment.
這意味著數據幀在清理和處理方面不需要太多的工作。

This dataset is small and brings us just a few columns. Like i said, first publication, simple things (sorry 😬)
這個數據集很小,只給我們帶來了幾列。 就像我說的那樣,第一次出版,簡單的事情(對不起😬)
Excepting “saldo”, “preco” and “valor_total”, the columns are categorical data. So now, we can go to Power BI to make some visualizations and answer some questions.
除“ saldo”,“ preco”和“ valor_total”外,這些列均為分類數據。 現在,我們可以去Power BI進行可視化并回答一些問題。
But first, we need to export the dataset we edited in Jupyter Notebook:
但是首先,我們需要導出在Jupyter Notebook中編輯的數據集:
With the file saved in the same folder of the actual project, we just need to open it in Power BI
將文件保存在實際項目的同一文件夾中,我們只需要在Power BI中打開它
The data is configured by default as a “Western European” source. Because of this, some words in brazilian portuguese are misspelled
默認情況下,數據配置為“西歐”來源。 因此,巴西葡萄牙語中的某些單詞 拼寫錯誤
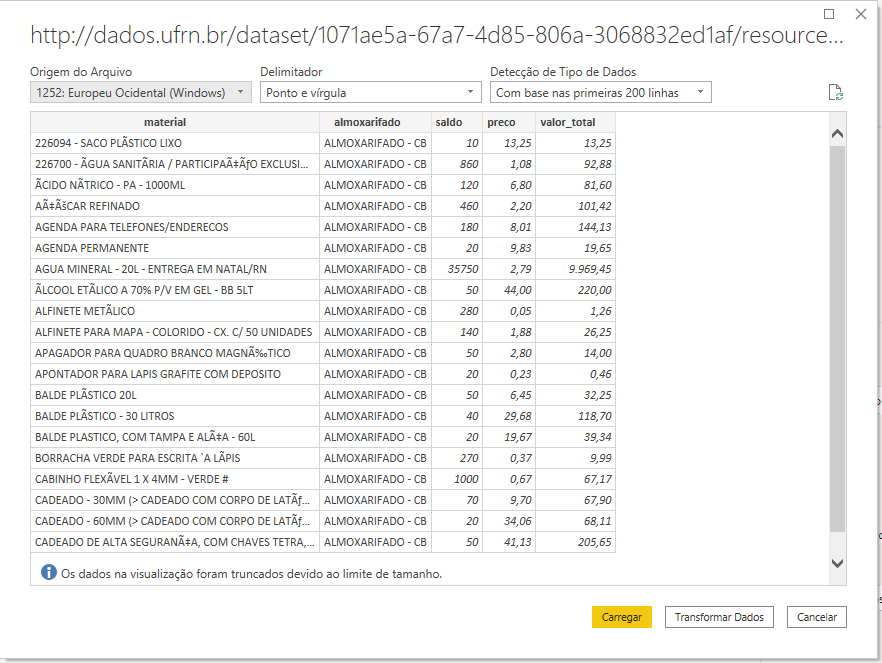
We solve this issue choosing “Unicode — UTF8” as the file source
我們選擇“ Unicode — UTF8”作為文件源來解決此問題

At the Power Query editor, we can see that the columns are already in the right format (Text, Text, Role Number, Currency, Currency). So it doesn’t need any transformation, just close and apply.
在Power Query編輯器中,我們可以看到列的格式已經正確(文本,文本,角色編號,貨幣,貨幣)。 因此,它不需要任何轉換,只需關閉并應用即可。

LET’S GO TO THE QUESTIONS!
讓我們去解決問題!
What are the items with the greatest quantity in stock:
什么是物品 庫存數量最多的庫存:

Almost 2 millions syringes and double-distilled water.
近200萬支注射器和雙蒸餾水 。
2. What are the items with the greatest value in stock:
2.什么是物品 庫存最大的價值 :

WOW! Wait..close to 1 million $ in coffee??? Seems that teachers are driven by coffee! 😂
哇! 等待..接近一百萬美元的咖啡 ??? 看來老師是被咖啡驅動的! 😂
Note that the value of these 2 items is very different from the others (could they be outliers?)
請注意,這兩項的價值與其他項有很大不同 (它們可能是離群值嗎?)
3. Wich warehouse has the greatest quantity of items in stock and wich has the lower quantity:
3. Wich 倉庫中的物品數量最多 ,而其中的物品數量 較少:
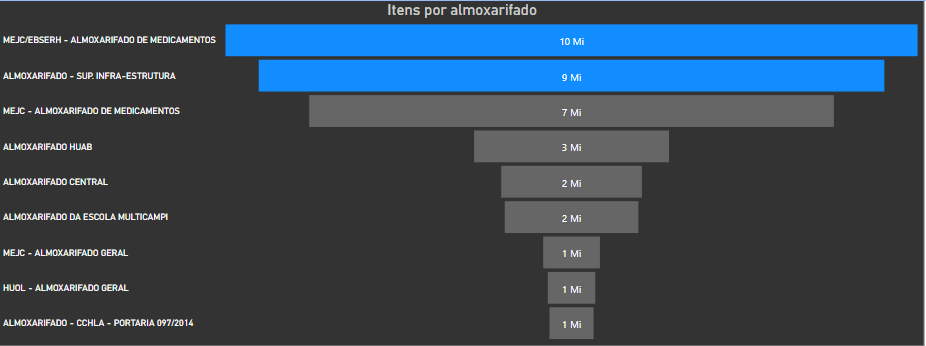
Despite these values are being rounded, the medicine warehouse has the largest number of items, followed by the infra-structure warehouse.
盡管對這些值進行了四舍五入,但藥品倉庫的物品數量最多 ,其次是基礎結構倉庫。
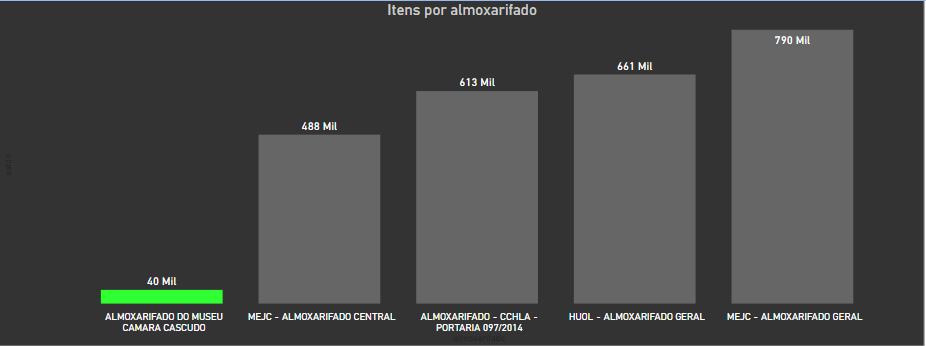
And the museum warehouse has de lower number of items.
博物館倉庫的物品數量較少 。
4. Wich warehouse has the greatest value in stock:
4. Wich 倉庫的庫存最大 價值 :
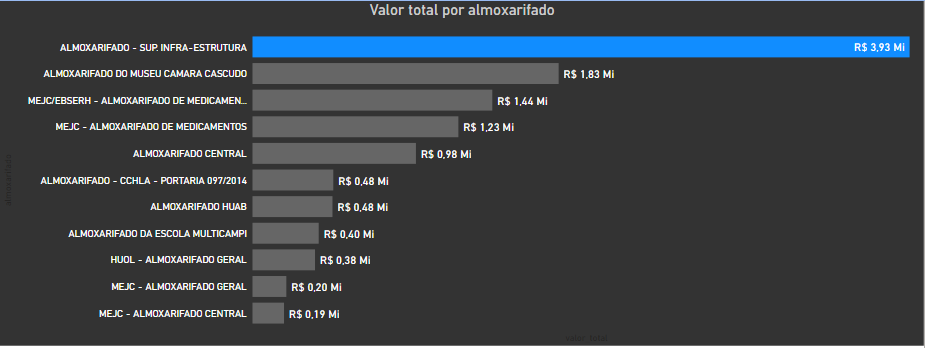
We saw earlier that the Medicine Warehouse has the largest number of items, slightly larger than that of Infrastructure. But the stock value of the Infra Warehouse is twice that of Medicine.
前面我們看到, 藥品倉庫的物品數量最多 ,比基礎設施的數量略大。 但是Infra倉庫的庫存價值 是醫學的兩倍 。
5. What are the most expensive items.
5.什么是最昂貴的物品。

Ok, so a 250g package of coffee costs 30.4 thousands?? Sounds weird 🤔
好的,一包250克咖啡的價格為30,400歐元? 聽起來很奇怪🤔
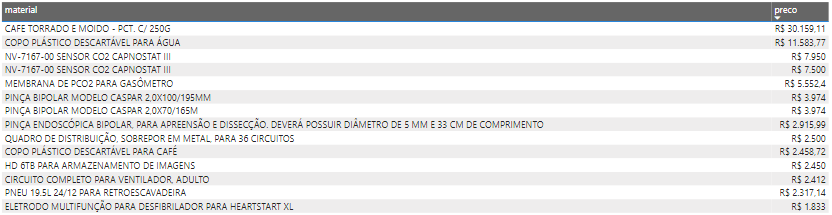
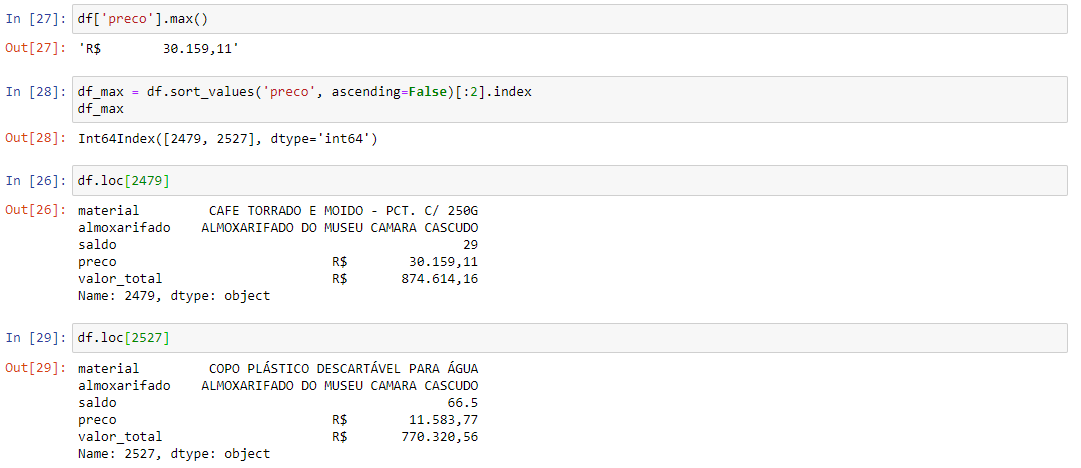
Well, it’s true! 😐 Also 11 thousand $ in plastic cups.
好吧,這是真的! 😐還有一萬一千美元的塑料杯。
Another strange thing that i realize is that 107 items have 1 cent as a price:
我意識到的另一件奇怪的事是107件商品的價格為1美分 :
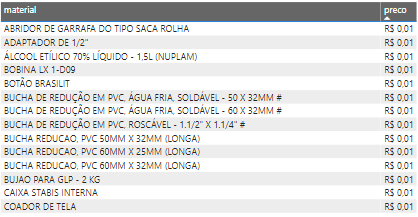

Does all these items really costs just 1 cent? Someone will need to answer it.
所有這些物品真的只花費1美分嗎? 有人需要回答。
SO WHAT??
所以呢??
Analysing this dataset we have seen that there is A LOT of money spent in coffe and plastic cup. ALMOST 1 MILLION!!!??? 💸💸💸
通過分析該數據集,我們發現在咖啡和塑料杯上花費了很多錢。 幾乎一百萬!!!!!! 💸💸💸
Maybe something it’s wrong…With this information i would probably check the veracity of the facts. Perhaps, the item’s description is not as much meaningfull as it could be (how big is this package?)
也許有些問題……有了這些信息,我可能會檢查事實的真實性。 也許,該項目的描述沒有那么有意義(此包裝有多大?)
Some inconclusions can turn into conclusions. In this case, some data curation could be needed.
一些結論可以得出結論。 在這種情況下,可能需要一些數據管理。
If you have some tips, comments or any suggestions, i would be very happy to learn more with you guys. I’m just a begginer.
如果您有任何提示,意見或建議,我將非常高興與你們一起學習更多。 我只是一個初學者。
Thank you for your time! 🙏
感謝您的時間! 🙏
翻譯自: https://medium.com/análises-exploratórias-de-dados/exploratory-analysis-of-ufrn-universidade-federal-do-rio-grande-do-norte-warehouses-e6f2ff334b0f
北方工業大學gpa計算
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389288.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389288.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389288.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
)
泰坦尼克數據集預測分析_探索性數據分析-泰坦尼克號數據集案例研究(第二部分)

各種數據庫連接的總結



基于PyTorch搭建CNN實現視頻動作分類任務代碼詳解

missforest_missforest最佳丟失數據插補算法

華碩猛禽1080ti_F-22猛禽動力回路的視頻分析

 的認知)
溫故而知新:柯里化 與 bind() 的認知


Memory-Associated Differential Learning論文及代碼解讀

大數據技術 學習之旅_如何開始您的數據科學之旅?

純API函數實現串口讀寫。

數據可視化工具_數據可視化

Android Studio調試時遇見Install Repository and sync project的問題
: Ignite Java Thin Client)
Apache Ignite 學習筆記(二): Ignite Java Thin Client
論文及代碼解讀)
VGAE(Variational graph auto-encoders)論文及代碼解讀


tableau大屏bi_Excel,Tableau,Power BI ...您應該使用什么?
