SiameseFC
- Siamese網絡(孿生神經網絡)
- 本文參考文章:
- Siamese背景
- Siamese網絡解決的問題
- 要解決什么問題?
- 用了什么方法解決?
- 應用的場景:
- Siamese的創新
- Siamese的理論
- Siamese的損失函數——Contrastive Loss
- 損失函數的選擇
- 論文中Contrastive Loss
- 目前的Contrastive Loss:
- Siamese的思考
- Siamese的思想總結
- Siamese network是雙胞胎連體,整一個三胞胎連體行不行?
Siamese網絡(孿生神經網絡)
本文參考文章:
精讀深度學習論文(25) Siamese Network
詳解Siamese網絡
孿生神經網絡(Siamese Network)詳解
孿生神經網絡(Siamese neural network)
Siamese network 孿生神經網絡–一個簡單神奇的結構
Siamese背景
Siamese和Chinese有點像。Siam是古時候泰國的稱呼,中文譯作暹羅。Siamese也就是“暹羅”人或“泰國”人。Siamese在英語中是“孿生”、“連體”的意思,這是為什么呢?
十九世紀泰國出生了一對連體嬰兒,當時的醫學技術無法使兩人分離出來,于是兩人頑強地生活了一生,1829年被英國商人發現,進入馬戲團,在全世界各地表演,1839年他們訪問美國北卡羅萊那州后來成為“玲玲馬戲團” 的臺柱,最后成為美國公民。1843年4月13日跟英國一對姐妹結婚,恩生了10個小孩,昌生了12個,姐妹吵架時,兄弟就要輪流到每個老婆家住三天。1874年恩因肺病去世,另一位不久也去世,兩人均于63歲離開人間。兩人的肝至今仍保存在費城的馬特博物館內。從此之后“暹羅雙胞胎”(Siamesetwins)就成了連體人的代名詞,也因為這對雙胞胎讓全世界都重視到這項特殊疾病。
簡單來說,Siamese network就是“連體的神經網絡”
Siamese網絡解決的問題
要解決什么問題?
第一類,分類數量較少,每一類的數據量較多,比如ImageNet、VOC等。這種分類問題可以使用神經網絡或者SVM解決,只要事先知道了所有的類。
第二類,分類數量較多(或者說無法確認具體數量),每一類的數據量較少,比如人臉識別、人臉驗證任務。
用了什么方法解決?
解決以上兩個問題,本文提出了以下解決方法:
-
提出了一種思路:將輸入映射為一個特征向量,使用兩個向量之間的“距離”(L1 Norm)來表示輸入之間的差異(圖像語義上的差距)。
-
基于上述思路設計了Siamese Network。每次需要輸入兩個樣本作為一個樣本對計算損失函數。
1)用的softmax只需要輸入一個樣本。
2)FaceNet中的Triplet Loss需要輸入三個樣本。 -
提出了Contrastive Loss用于訓練。
應用的場景:
孿生神經網絡用于處理兩個輸入"比較類似"的情況。偽孿生神經網絡適用于處理兩個輸入"有一定差別"的情況。比如,我們要計算兩個句子或者詞匯的語義相似度,使用siamese network比較適合;如果驗證標題與正文的描述是否一致(標題和正文長度差別很大),或者文字是否描述了一幅圖片(一個是圖片,一個是文字),就應該使用pseudo-siamese network。也就是說,要根據具體的應用,判斷應該使用哪一種結構,哪一種Loss。
Siamese的創新
這個網絡主要的優點是淡化了標簽,使得網絡具有很好的擴展性,可以對那些沒有訓練過的類別進行分類,這點是優于很多算法的。而且這個算法對一些小數據量的數據集也適用,變相的增加了整個數據集的大小,使得數據量相對較小的數據集也能用深度網絡訓練出不錯的效果。
Siamese的理論

不同輸入X_1, X_2通過統一G_W得到兩個向量G_W(X_1), G_W(X_2),計算兩個向量之間的L1距離獲得E_W。
其中,兩個network是兩個共享權值的網絡,實際上就是兩個完全相同的網絡。孿生神經網絡有兩個輸入(X1 and X2),將兩個輸入feed進入兩個神經網絡(Network1 and Network2),這兩個神經網絡分別將輸入映射到新的空間,形成輸入在新的空間中的表示。通過Loss的計算,評價兩個輸入的相似度。
如果左右兩邊不共享權值,而是兩個不同的神經網絡,叫做pseudo-siamese network,偽孿生神經網絡。對于pseudo-siamese network,兩邊可以是不同的神經網絡(如一個是lstm,一個是cnn),也可以是相同類型的神經網絡。
Siamese的損失函數——Contrastive Loss
損失函數的選擇
Softmax當然是一種好的選擇,但不一定是最優選擇,即使是在分類問題中。傳統的siamese network使用Contrastive Loss。損失函數還有更多的選擇,siamese network的初衷是計算兩個輸入的相似度,。左右兩個神經網絡分別將輸入轉換成一個"向量",在新的空間中,通過判斷cosine距離就能得到相似度了。Cosine是一個選擇,exp function也是一種選擇,歐式距離什么的都可以,訓練的目標是讓兩個相似的輸入距離盡可能的小,兩個不同類別的輸入距離盡可能的大。
論文中Contrastive Loss
論文中的損失函數定義如下:
Y代表X_1, X_2是否屬于同一類別。輸入同一類別為0,不屬于同一類別為1。
P代表輸入數據數量。
i表示當前輸入數據下標。
L_G代表兩個輸入數據屬于同一類別時的損失函數(G,genuine)。
L_I代表兩個輸入數據不屬于同一類別的損失函數(I,imposter)。

根據我們對兩個向量間舉例的定義,可以得到以下條件:
即不同類別向量間的距離比相同類別向量間距離大。
兩個向量之間距離越小,屬于同一類別的可能性就越大。
目前的Contrastive Loss:
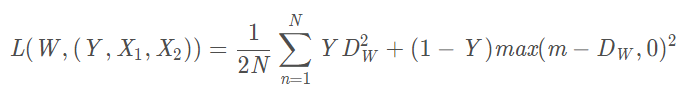
其中:
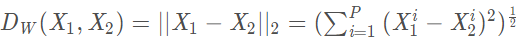
代表兩個樣本特征X1和X2 的歐氏距離(二范數)P 表示樣本的特征維數,Y 為兩個樣本是否匹配的標簽,Y=1 代表兩個樣本相似或者匹配,Y=0 則代表不匹配,m 為設定的閾值,N 為樣本個數。
觀察上述的contrastive loss的表達式可以發現,這種損失函數可以很好的表達成對樣本的匹配程度,也能夠很好用于訓練提取特征的模型。
當 Y=1(即樣本相似時),損失函數只剩下
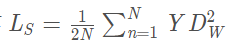
即當樣本不相似時,其特征空間的歐式距離反而小的話,損失值會變大,這也正好符號我們的要求。
當 Y=0 (即樣本不相似時),損失函數為
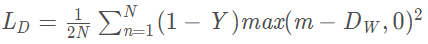
即當樣本不相似時,其特征空間的歐式距離反而小的話,損失值會變大,這也正好符號我們的要求。
注意:
這里設置了一個閾值margin,表示我們只考慮不相似特征歐式距離在0~margin之間的,當距離超過margin的,則把其loss看做為0(即不相似的特征離的很遠,其loss應該是很低的;而對于相似的特征反而離的很遠,我們就需要增加其loss,從而不斷更新成對樣本的匹配程度)
Siamese的思考
Siamese的思想總結
其實講了這么多,主要思想就是三點:
- 輸入不再是單個樣本,而是一對樣本,不再給單個的樣本確切的標簽,而且給定一對樣本是否來自同一個類的標簽,是就是0,不是就是1
- 設計了兩個一模一樣的網絡,網絡共享權值W,對輸出進行了距離度量,可以說l1、l2等。
- 針對輸入的樣本對是否來自同一個類別設計了損失函數,損失函數形式有點類似交叉熵損失:
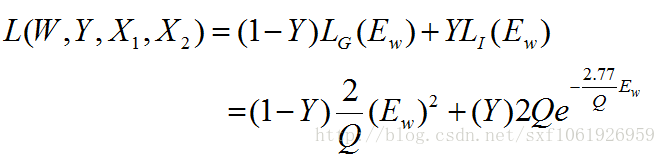
最后使用獲得的損失函數,使用梯度反傳去更新兩個網絡共享的權值W。
Siamese network是雙胞胎連體,整一個三胞胎連體行不行?
不好意思,已經有人整過了,叫Triplet network,論文是《Deep metric learning using Triplet network》,輸入是三個,一個正例+兩個負例,或者一個負例+兩個正例,訓練的目標是讓相同類別間的距離盡可能的小,讓不同類別間的距離盡可能的大。Triplet在cifar, mnist的數據集上,效果都是很不錯的,超過了siamese network。四胞胎,五胞胎會不會更屌?。。。。。目前還沒見過。。。






)












 :解析)
