SiamRPN++
- 論文來源
- 論文背景
- 什么是目標跟蹤
- 什么是孿生網絡結構
- Siamese的局限
- 解決的問題
- 論文分析
- 創新點一:空間感知策略
- 創新點二:ResNet-50深層網絡
- 創新點三:多層特征融合
- 創新點四:深層互相關
- 代碼分析
- 整體代碼簡述
- (1)特征提取網絡
- (2)逐層的特征融合(Layerwise Aggregation)
- (3)深層互相關Depthwise Cross Correlation
- 總結
- 論文翻譯
- Abstract
- 1. Introduction
- 2. Related Work
- 3. Siamese Tracking with Very Deep Networks
- 3.1. Analysis on Siamese Networks for Tracking
- 3.2. ResNet-driven Siamese Tracking
- 3.3. Layer-wise Aggregation
- 3.4. Depthwise Cross Correlation
- 4. Experimental Results
- 4.1. Training Dataset and Evaluation
- 4.2. Implementation Details
- 4.3. Ablation Experiments
- 4.4. Comparison with the state-of-the-art
- 5. Conclusions
論文來源
論文鏈接
代碼鏈接
本文參考:
如何理解SiamRPN++?
SiamRPN++理解
SiamRPN++: 基于深度網絡的孿生視覺跟蹤的進化
【SOT】Siamese RPN++ 論文和代碼解析
SiamRPN++算法詳解
論文背景
什么是目標跟蹤
使用視頻序列第一幀的圖像(包括bounding box的位置),來找出目標出現在后序幀位置的一種方法。
什么是孿生網絡結構
在進入到正式理解SiamRPN++之前,為了更好的理解這篇論文,我們需要先了解一下孿生網絡的結構。
孿生網絡是一種度量學習的方法,而度量學習又被稱為相似度學習。
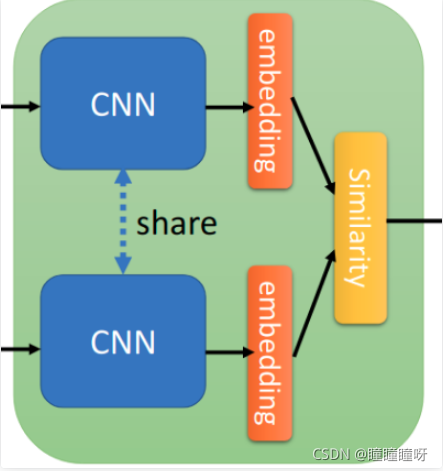
孿生網絡結構被較早地利用在人臉識別的領域(《Learning a Similarity Metric Discriminatively, with Application to Face Verification》)。其思想是將一個訓練樣本(已知類別)和一個測試樣本(未知類別)輸入到兩個CNN(這兩個CNN往往是權值共享的)中,從而獲得兩個特征向量,然后通過計算這兩個特征向量的的相似度,相似度越高表明其越可能是同一個類別。在上面這篇論文中,衡量這種相似度的方法是L1距離。
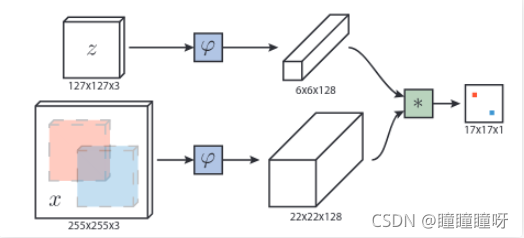
在目標領域中,最早利用這種思想的是SiamFC,其網絡結構如上圖。輸入的z 是第一幀ROI(也就是在手動在第一幀選擇的bounding box),x則是后一幀的圖片。兩者分別通過兩個CNN,得到兩張特征圖。再通過一次卷積操作(L=(22-6)/1+1=17),獲得最后形狀為17×17×1的特征圖。在特征圖上響應值越高的位置,代表其越可能有目標存在。其想法就類似于對上面的人臉識別孿生網絡添加了一次卷積操作。獲得特征圖后,可以獲得相應的損失函數。y={-1,+1}為真實標簽,v是特征圖相應位置的值。下列第一個式子是特征圖上每一個點的loss,第二個式子是對第一個式子作一個平均,第三個式子就是優化目標。
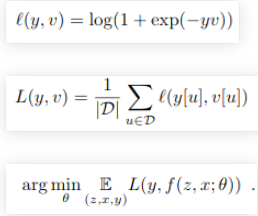
However, both Siamese-FC and CFNet are lack of boundingbox regression and need to do multi-scale test which makesit less elegant. The main drawback of these real-time track-ers is their unsatisfying accuracy and robustness comparedto state-of-the-art correlation filter approaches.但是,Siamese-FC和CFNet都沒有邊界框回歸,因此需要進行多尺度測試,這使得它不太美觀。這些實時跟蹤器的主要缺點是,與最新的相關濾波器方法相比,它們的精度和魯棒性不令人滿意。
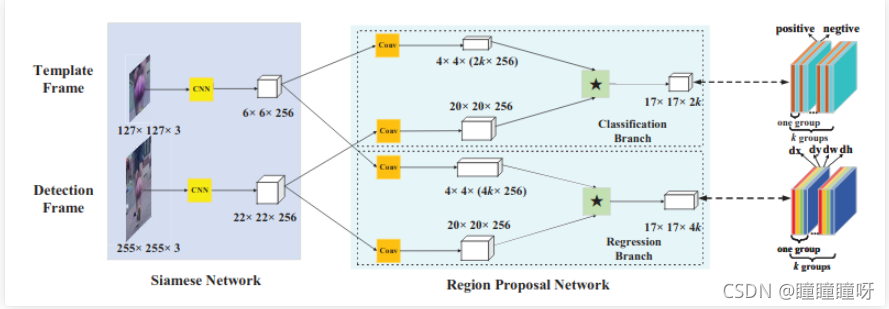
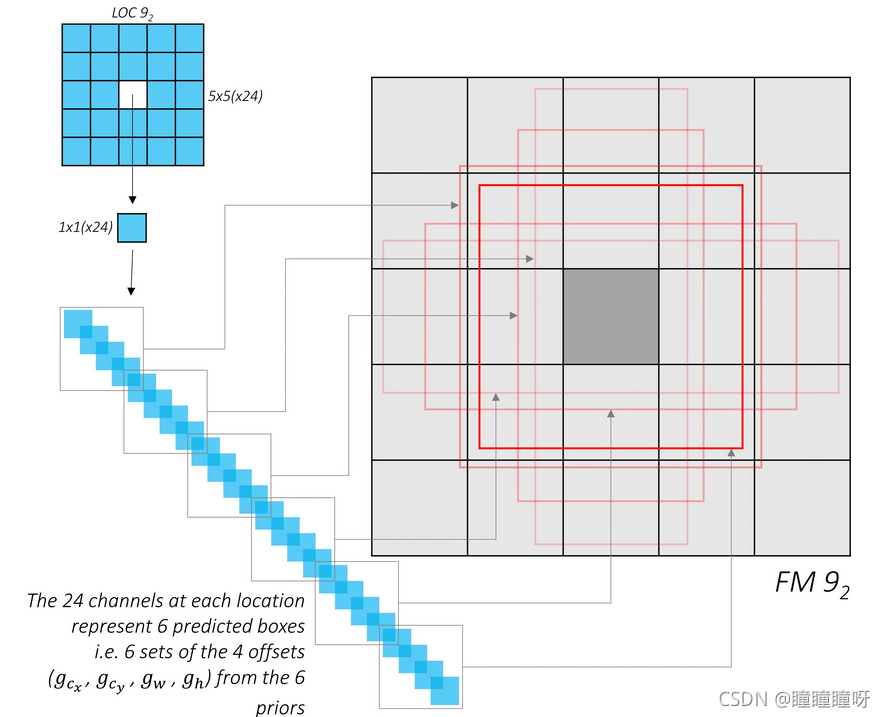
為了解決SiamFC的這兩個問題,就有了SiamRPN。可以看到前半部分Siamese Network部分和SiamFC一模一樣(通道數有變化)。區別就在于后面的RPN網絡部分。特征圖會通過一個卷積層進入到兩個分支中,在Classification Branch中的4×4×(2k×256)特征圖等價于有2k個4×4×256形狀的卷積核,對20×20×256作卷積操作,于是可以獲得17×17×2k的特征圖,Regression Branch操作同理。而RPN網絡進行的是多任務的學習。17×17×2k做的是區分目標和背景,其會被分為k個groups,每個group會有一層正例,一層負例。最后會用softmax + cross-entropy loss進行損失計算。17×17×4k同樣會被分為k groups,每個group有四層,分別預測dx,dy,dw,dh。而k的值即為生成的anchors的數目。而關于anchor box的運行機制,可以看下方第二張圖(來自SSD)。
correlation操作詳解(涉及到后續改進):以分類分支為例,在RPN中,分類分支需要輸出一個通道數為 2k 的特征圖( k 為anchor個數),SiamFC中使用的correlation只能提供通道數為1的響應圖,無法滿足要求。所以我們換了一個想法,把correlation層當成一個卷積層,template分支提取的特征作為卷積核,detection分支提取的特征作為卷積層的input,這樣只需要改變卷積核的形狀就可以達到輸出2k通道數的目的。具體做法為使用了兩個不同的卷積層,template分支的卷積層負責升維,把通道數提升到 256*2k ,為了保持對齊,detection分支也增加了一個卷積層,不過保持通道數不變。之后進行correlation操作(卷積),得到最終的分類結果。
Siamese的局限
作者的實驗發現,較深的網絡,如 ResNet, 無法帶來跟蹤精度提升的原因在于:
-
更深的網絡的填充會破壞嚴格的平移不變性(Strict translation invariance)
padding會破壞這種性質
現代化網絡:隨著何鎧明等提出殘差網絡以后,網絡的深度得到了巨大的釋放,通常物體檢測和語義分割的baseline backbone都采用ResNet50的結構。為了保證網絡具有適當/整齊的分辨率,幾乎所有的現代網絡backbone都需要執行padding操作。而ResNet網絡中具有padding操作,即該網絡肯定不具備嚴格的平移不變性,padding的引入會使得網絡輸出的響應對不同位置有了不同的認知。而我們進行進一步的訓練是希望網絡學習到如何通過物體的表觀特征來分辨回歸物體,這就限制了深網絡在tracking領域的應用。 -
RPN要求分類和回歸具有不對稱特征
即如果將搜索區域圖像和模板區域圖像進行互換,輸出的結果應該保持不變。(因為是相似度,所以應該有對稱性)。
由于SiamRPN不再是進行相似度計算,而是通過計算回歸的偏移量和分類的分數來選擇最終的目標,這將使得該網絡不再具有對稱性。因而在SiamRPN的改進中需要引入非對稱的部件,如果完全Siamese的話沒法達到目的,這一點主要會引導后面的correlation設計。
文中作者引入空間感知策略來克服第一個困難,并對第二個問題進行討論。
針對第一個問題作者認為Strict translation invariance只存在沒有padding的網絡中例如Alexnet,并且假設違反了這種限制將導致空間的傾斜(spatial bias)。
作者發現如下的幾個參數,對跟蹤結果的影響,非常巨大:the receptive field size of neurons; network stride; feature padding。
具體來說,感受野決定了用于計算 feature 的圖像區域。較大的感受野,提供了更好的 image context 信息,而一個較小的感受野可能無法捕獲目標的結構信息;
網絡的步長,影響了定位準確性的程度,特別是對小目標而言;與此同時,它也控制了輸出 feature map 的大小,從而影響了 feature 的判別性和檢測精度。
此外,對于一個全卷積的結構來說,feature padding 對卷積來說,會在模型訓練中,引入潛在的位置偏移,從而使得當一個目標移動到接近搜索范圍邊界的時候,很難做出準確的預測。這三個因素,同時造成了 Siamese Tracker 無法很好的從更頂尖的模型中收益。
解決的問題
該論文主要解決的問題是將深層基準網絡ResNet、Inception等網絡應用到基于孿生網絡的跟蹤網絡中。在SiameseFC算法之后,盡管已經有很多的基于孿生網絡的跟蹤算法,但是大家可能會注意到一個問題是,這些網絡都使用淺層的類AlexNet做為基準特征提取器。其實在這之前,也有學者們嘗試著使用深層的網絡,但是發現直接使用預訓練好的深層網絡反而會導致跟蹤算法精度的下降,因此,這成為了一個基于孿生網絡的跟蹤器需要解決的一個關鍵問題!
論文分析
創新點一:空間感知策略
1.平移不變性的問題
作者認為Strict translation invariance只存在沒有padding的網絡中例如Alexnet,并且假設違反了這種限制將導致空間的傾斜(spatial bias)。作者發現如下的幾個參數,對跟蹤結果的影響,非常巨大:the receptive field size of neurons; network stride; feature padding。具體來說,感受野決定了用于計算 feature 的圖像區域。較大的感受野,提供了更好的 image context 信息,而一個較小的感受野可能無法捕獲目標的結構信息;網絡的步長,影響了定位準確性的程度,特別是對小目標而言;與此同時,它也控制了輸出 feature map 的大小,從而影響了 feature 的判別性和檢測精度。此外,對于一個全卷積的結構來說,feature padding 對卷積來說,會在模型訓練中,引入潛在的位置偏移,從而使得當一個目標移動到接近搜索范圍邊界的時候,很難做出準確的預測。這三個因素,同時造成了 Siamese Tracker 無法很好的從更頂尖的模型中收益。
2.如果破壞了網絡的平移不變性,具體會帶來什么問題呢?
如果現代化網絡的平移不變性被破壞以后,帶來的弊端就是會學習到位置偏見:按照SiamFC的訓練方法,正樣本都在正中心,網絡逐漸會學習到這種統計特性,學到樣本中正樣本分布的情況。即簡而言之,網絡會給圖像的中心位置分配更大的權重。
3.空間感知策略
要想使用更深的特征提取網絡,就要避免對目標產生強烈的中心偏移,我們采用空間感知采樣策略訓練了具有ResNet-50骨干網的SiamRPN。在訓練過程中,我們不再把正樣本塊放在圖像正中心,而是按照均勻分布的采樣方式讓目標在中心點附近進行偏移。隨著偏移的范圍增大,深度網絡可以由剛開始的完全沒有效果逐漸變好。
具體的效果如下圖所示:當我們將shift設置為0時,網絡只會關注圖像中心的位置,對應到圖中就是只有中心位置具有較大的響應值;而當我們將shift設置為16時,網絡開始關注更多的圖像范圍,對應到圖中就是響應的范圍會擴大,顏色由深變淺;而當我們將shift設置為32時,網絡會關注更大額圖像范圍,對應到圖中就是響應的范圍變得更大,顏色也更加多樣化。
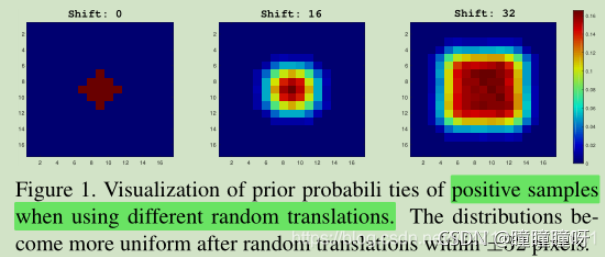
所以說,通過均勻分布的采樣方式讓目標在中心點附近進行偏移,可以緩解網絡因為破壞了嚴格平移不變性帶來的影響,即消除了位置偏見,讓現代化網絡可以應用于跟蹤算法中。
4.為什么該問題在檢測任務和語義分割任務中并不存在?
因為對于物體檢測和語義分割而言,訓練過程中,物體本身就是在全圖的每個位置較為均勻的分布。我們可以很容易的驗證,如果在物體檢測網絡只訓練標注在圖像中心的樣本,而邊緣的樣本都不進行訓練,那么顯然,這樣訓練的網絡只會對圖像的中心位置產生高響應,邊緣位置就隨緣了,不難想象這種時候邊緣位置的性能顯然會大幅衰減。而更為致命的是,按照SiamFC的訓練方式,中心位置為正樣本,邊緣位置為負樣本。那么網絡只會記錄下邊緣永遠為負,不管表觀是什么樣子了。這完全背離了我們訓練的初衷。
創新點二:ResNet-50深層網絡
我們主要的實驗實在ResNet-50上做的。現代化網絡一般都是stride32,但跟蹤為了定位的準確性,一般stride都比較小(Siamese系列一般都為8),所以我們把ResNet最后兩個block的stride去掉了,同時增加了dilated convolution,一是為了增加感受野,二是為了能利用上預訓練參數。論文中提到的MobileNet等現代化網絡也是進行了這樣的改動。如上圖所示,改過之后,后面三個block的分辨率就一致了。
在訓練過程中采用了新的采樣策略后,我們可以訓練ResNet網絡了,并且能夠正常跟蹤一些視頻了。(之前跟蹤過程中一直聚集在中心,根本無法正常跟蹤目標)。對backbone進行finetune以后,又能夠進一步得到一些性能提升。
由于所有層的填充都保持不變,模板特征的空間大小增加到15,這給相關模塊帶來了沉重的計算負擔。因此,作者裁剪中心7×7區域作為模板特征,其中每個特征單元仍然可以捕獲整個目標區域。
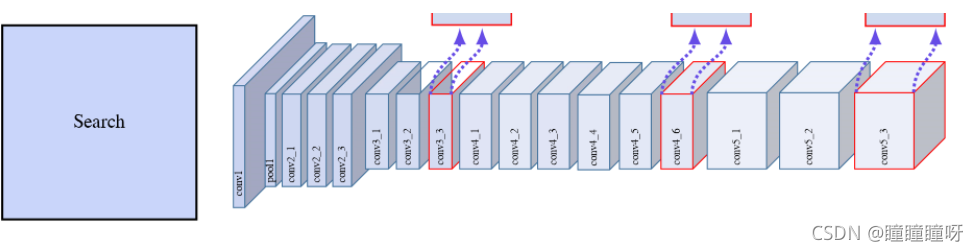
創新點三:多層特征融合
在以前的工作中,僅使用像AlexNet這樣的淺層網絡,多層特性不能提供非常不同的作用。然而,考慮到感受野的變化,ResNet中的不同層更有意義。淺層的特征主要集中在低層次的信息上,如顏色、形狀等,對于定位是必不可少的,而缺乏語義信息;深層的特征具有豐富的語義信息,在某些挑戰場景(如運動模糊、形變等)中是有益的。使用這種豐富的層次信息有助于跟蹤。

在多層使用siamrpn的好處
如創新點2中的圖所示,我們會觀察到作者分別在conv3_3、conv4_6和conv5_3的分支上使用siamrpn網絡,并將前面siamrpn的結果輸入到后面的siamrpn網絡中,該思路類似于cvpr2019值的C-RPN算法,通過多級級聯具有兩個優點:
- 可以通過多個siamrpn來選擇出多樣化的樣本或者具有判別性的樣本塊,第一個siamrpn可以去除掉一些特別簡單的樣本塊,而后面的網絡進一步進行濾除,最終剩余一些hard negative sample,這樣其實有利于提升網絡的判別能力。
- 由于使用了多級回歸操作,因此可以獲得一個更加準確的BB。
創新點四:深層互相關
互相關模塊是嵌入兩個分支信息的核心操作。SiamFC利用互相關層獲得用于目標定位的單信道響應圖。在SiamRPN中,通過添加一個巨大的卷積層來縮放信道,擴展了互相關以嵌入更高級別的信息,例如anchors。重上行信道模塊使得參數分布嚴重不平衡,使得SiamRPN訓練優化困難。
??作者提出了一個輕量級的互相關層,稱為深度互相關,以實現有效的信息關聯。深度互相關層包含的參數比SiamRPN中使用的互相關層少10倍,性能與之相當。
??為了達到這個目標,作者采用一個 conv-bn block 來調整特征,來適應跟蹤任務。Bounding box prediction 和 基于 anchor 的分類都是非對稱的 (asymmetrical)。為了編碼這種不同,the template branch 和 search branch 傳輸兩個 non-shared convolutional layers。然后,這兩個 feature maps 是有相同個數的 channels,然后一個 channel 一個 channel 的進行 correlation operation。另一個 conv-bn-relu block,用于融合不同 channel 的輸出。最終,最后一個卷積層,用于輸出 classification 和 regression 的結果。
通過用 Depthwise correlation 替換掉 cross-correlation,我們可以很大程度上降低計算代價和內存使用。通過這種方式,template 和 search branch 的參數數量就會趨于平衡,導致訓練過程更加穩定。
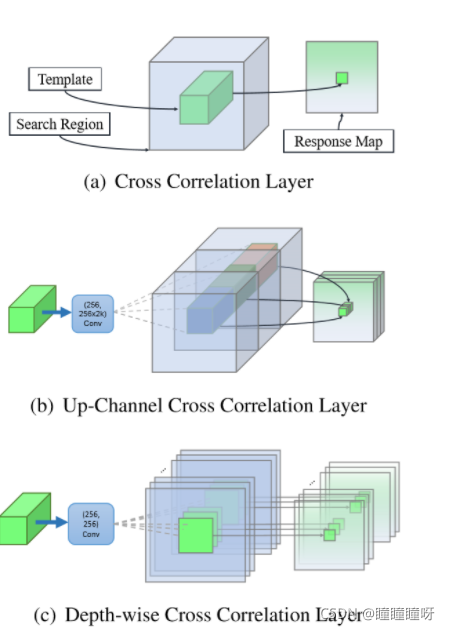
如上圖所示,圖中(a)互相關層預測方法是取自SiamFC中目標模板和搜索圖像之間的單通道相似性映射。模板圖像和搜索圖像在經過網絡后輸出通道數相同的featuremap,兩者逐通道相互卷積,最后取平均值。
圖中(b)上行信道互相關層,取自SiamRPN,模板圖像和搜索圖像經過特征提取網絡生成feature map后,輸入RPN網絡,分類分支和回歸分支分別經過非權值共享的卷積層后在相互卷積,參數量十分巨大。
圖中(c)深度互相關層預測模板和搜索圖像之間的多通道相關性特征,取自SiamRPN++,模板圖像經過卷積層后并不像SiamRPN那樣將通道數增加2k倍(每個grid生成k個anchors),而是保持不變,同時搜索圖像也與模板圖像保持一致,兩者逐通道相互卷積,之后接一個1×1的卷積層,再改變通道數,這樣在保持精度的同時減少了參數量。如下第一張圖,輸入兩個從ResNet獲得的特征層(channel數目是一致的),先同樣分別通過一個卷積層(由于需要學的任務不同,所以卷積層參數不共享),再分別進行DW卷積操作,然后兩分支再分別通過一層不同的卷積層改變通道數以獲得想要的分類和回歸結果。這樣一來,就可以減少計算量,且使得兩個分支更加平衡。
通道數的研究:
下圖說明了一個有趣的現象。同一類別的對象在同一信道(148信道的car、222信道的person和226信道的face)上具有高響應,而其余信道的響應被抑制。這一特性可以理解為,由深度互相關產生的信道方向特征幾乎是正交的,每個信道代表一些語義信息。我們還分析了當使用上通道互相關時的熱圖,而響應圖的解釋性較差。
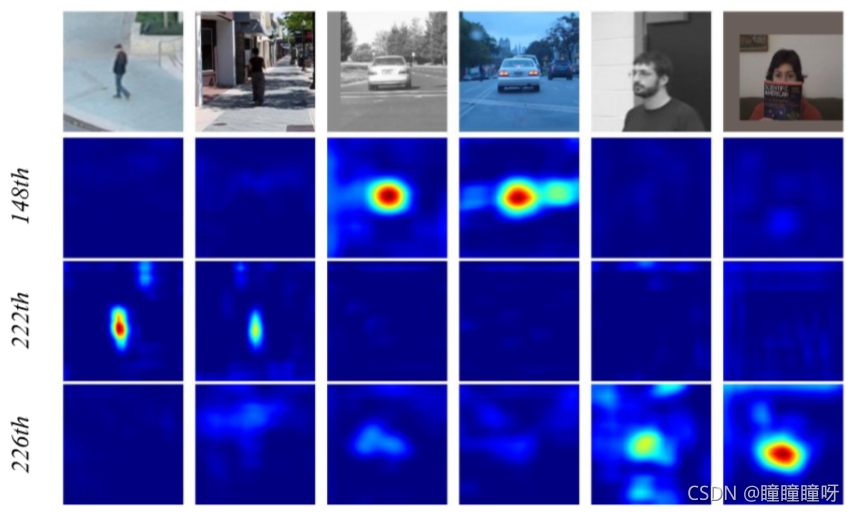
上圖為conv4中的深度相關輸出通道。conv4共有256個通道,但只有少數信道在跟蹤過程中有較高的響應。因此,選擇第148、222、226個通道作為演示,它們是圖中的第2、3、4行。第一行包含來自OTB數據集的六個相應的搜索區域。不同的通道表示不同的語義,第148通道對汽車的響應較高,而對人和臉的響應較低。第222頻道和第226頻道分別對人和臉有很高的響應。
代碼分析
整體代碼簡述
整體代碼主要分成兩個部分,第一個是初始幀標記的目標box為temple,第二個部分為追蹤過程中的track目標。
代碼首先將初始幀進行處理成127×127的形式然后進入主體網絡(包括resnet50(經過resnet50后輸出三個feature_map大小分別是[1, 512, 15, 15]、[1, 1024, 15, 15]、[1, 2048, 15, 15])和adjustnect)框架中,并將輸出的3個feature_map,其大小分別是[1, 128, 7, 7]、[1, 256, 7, 7]、[1, 512, 7, 7]進行保存。
追蹤過程(始終保持上一幀目標位置的中心),根據上一幀目標位置的得分判斷是否進行長期追蹤(長期追蹤圍繞中心位置搜索的面積較大寫,短期追蹤圍繞中心面積搜索的范圍較小,是否進行長期追蹤主要是根據上上衣目標幀的得分決定),按照追蹤形式將上一幀范圍內的像素進行剪裁填充以及resize成255×255,將剪裁過后的圖片輸入到網絡框架中(包括resnet50經過resnet50后輸出三個feature_map大小分別是[1, 512, 31, 31]、[1, 1024, 31, 31]、[1, 2048, 31, 31])和adjustnect),并輸出三個feature_map大小分別為[1, 128, 31, 31]、[1, 256, 31, 31]、[1, 512, 31, 31]
最后temple和track中分別輸出的feature_map進入rpn網絡中,按照索引一一對應進行卷積操,之后將templw中的feature展開成[temple.size[0]*temple.size[1], 1,temple.size[2],temple. zise[3]]的形式作為kernel,track同樣改變通道數作輸入層進行卷積操作,之后將三次卷積操作的結果按照一定權重(網絡中訓練出來的權重參數)相加最后輸出。rpn中有兩個分支一個用來預測是否是目標類別cls輸出的tensor大小[1, 10, 25,25](選擇的anchor數為5,預測為2分類因此第二個維度上的通道數為10),另一個分支預測位置的偏移量loc,輸出的tensor大小為[1, 20, 25, 25](選擇的anchor為5,預測四個位置上的偏移[x, y, w, h])。
根據cls何loc的輸出預測是否是目標以及目標位置,將cls何loc分別展開成[3125, 2], [3125, 4]的形式,cls經過softmax分類器,并取最后一列最為目標位置的預測概率。anchor box結合回歸結果得出bounding box。最后使用余弦窗和尺度變化懲罰來對cls中經過softmax處理過后的最后一列進行排序,選最好的。余弦窗是為了抑制距離過大的,尺度懲罰是為了抑制尺度大的變化
特征提取網絡: 改進的殘差網絡ResNet-50
逐層特征融合(Layerwise Aggregation)
Depthwise Cross Correlation
接下來按照分成的三部分進行詳細說明。
(1)特征提取網絡
論文中提到
The original ResNet has a large stride of 32 pixels, which is not suitable for dense Siamese network prediction. As shown in Fig.3, we reduce the effective strides at the last two block from 16 pixels and 32 pixels to 8 pixels by modifying the conv4 and conv5 block to have unit spatial stride, and also increase its receptive field by dilated convolutions. An extra 1 x 1 convolution layer is appended to each of block outputs to reduce the channel to 256.
作者的意思就是嫌棄原來ResNet的stride過大,從而在conv4和conv5中將stride=2改動為stride=1。但是同時為了保持之前的感受野,采用了空洞卷積。其代碼定義如下:
class ResNetPP(nn.Module):def __init__(self, block, layers, used_layers):self.inplanes = 64super(ResNetPP, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=0, # 3bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = self._make_layer(block, 64, layers[0])self.layer2 = self._make_layer(block, 128, layers[1], stride=2)self.feature_size = 128 * block.expansionself.used_layers = used_layerslayer3 = True if 3 in used_layers else Falselayer4 = True if 4 in used_layers else Falseif layer3:self.layer3 = self._make_layer(block, 256, layers[2],stride=1, dilation=2) # 15x15, 7x7self.feature_size = (256 + 128) * block.expansionelse:self.layer3 = lambda x: x # identityif layer4:self.layer4 = self._make_layer(block, 512, layers[3],stride=1, dilation=4) # 7x7, 3x3self.feature_size = 512 * block.expansionelse:self.layer4 = lambda x: x # identityfor m in self.modules():if isinstance(m, nn.Conv2d):n = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsm.weight.data.normal_(0, math.sqrt(2. / n))elif isinstance(m, nn.BatchNorm2d):m.weight.data.fill_(1)m.bias.data.zero_()def _make_layer(self, block, planes, blocks, stride=1, dilation=1):downsample = Nonedd = dilationif stride != 1 or self.inplanes != planes * block.expansion:if stride == 1 and dilation == 1:downsample = nn.Sequential(nn.Conv2d(self.inplanes, planes * block.expansion,kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(planes * block.expansion),)else:if dilation > 1:dd = dilation // 2padding = ddelse:dd = 1padding = 0downsample = nn.Sequential(nn.Conv2d(self.inplanes, planes * block.expansion,kernel_size=3, stride=stride, bias=False,padding=padding, dilation=dd),nn.BatchNorm2d(planes * block.expansion),)layers = []layers.append(block(self.inplanes, planes, stride,downsample, dilation=dilation))self.inplanes = planes * block.expansionfor i in range(1, blocks):layers.append(block(self.inplanes, planes, dilation=dilation))return nn.Sequential(*layers)def forward(self, x):x = self.conv1(x)x = self.bn1(x)x_ = self.relu(x)x = self.maxpool(x_)p1 = self.layer1(x)p2 = self.layer2(p1)p3 = self.layer3(p2)p4 = self.layer4(p3)out = [x_, p1, p2, p3, p4]out = [out[i] for i in self.used_layers]if len(out) == 1:return out[0]else:return out
從上述代碼中的這段代碼可以看出
if layer3:self.layer3 = self._make_layer(block, 256, layers[2],stride=1, dilation=2) # 15x15, 7x7self.feature_size = (256 + 128) * block.expansionelse:self.layer3 = lambda x: x # identityif layer4:self.layer4 = self._make_layer(block, 512, layers[3],stride=1, dilation=4) # 7x7, 3x3self.feature_size = 512 * block.expansion
作者在原來的ResNet-50的基礎上進行了一些修改,包括stride=1與空洞卷積的使用。
(2)逐層的特征融合(Layerwise Aggregation)
熟悉目標檢測的FPN網絡的小伙伴們一定不會對Layerwise Aggregation陌生。一般而言,淺層的網絡包含的信息更多有關于物體的顏色、條紋等,深層的網絡包含的信息更多包含物體的語義特征。正如作者文中提到的那樣:
Features from earlier layers will mainly focus on low level information such as color, shape, are essential for localization, while lacking of semantic information
使用特征融合可以彌補淺層信息和深層信息的不足,更有助于單目標追蹤。
本文中的Siamese RPN++利用了ResNet-50在conv3、conv4、conv5的輸出作為輸入。如下圖所示。
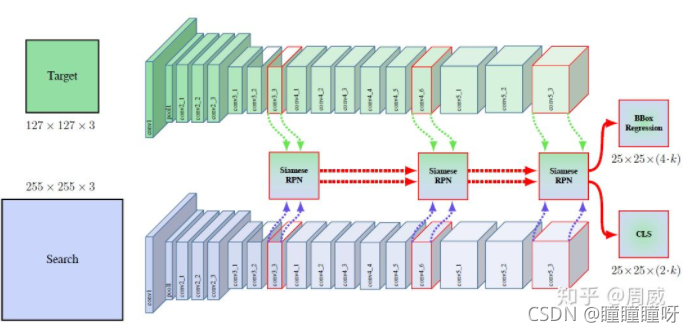
也就是這三個輸出分別都有各自的RPN網絡,并不是通過堆疊或者相加進行融合。這在代碼中是這樣體現的
self.features = resnet50(**{'used_layers': [2, 3, 4]})
先使用改進后的resnet50作為特征提取網絡,返回輸出的層 id 為[2,3,4],其實就是conv3、conv4、conv5的輸出。
然后分別對template圖像和需要detection的圖像分別進行特征提取。
zf = self.features(template)xf = self.features(detection)
事實上,zf 和 xf 并不是單一的特征圖,而是一個列表,每個列表中包含了三個特征圖。
接著,在特征提取結束后,需要對提取的特征進行調整,代碼中是這樣實現的:
zf = self.neck(zf)xf = self.neck(xf)
那么這個neck的定義如下:
AdjustAllLayer(**{'in_channels': [512, 1024, 2048], 'out_channels': [256, 256, 256]})
AdjustAllLayer定義如下:
class AdjustLayer(nn.Module):def __init__(self, in_channels, out_channels):super(AdjustLayer, self).__init__()self.downsample = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),nn.BatchNorm2d(out_channels),)def forward(self, x):x = self.downsample(x)if x.size(3) < 20:l = 4r = l + 7x = x[:, :, l:r, l:r]return xclass AdjustAllLayer(nn.Module):def __init__(self, in_channels, out_channels):super(AdjustAllLayer, self).__init__()self.num = len(out_channels)if self.num == 1:self.downsample = AdjustLayer(in_channels[0], out_channels[0])else:for i in range(self.num):self.add_module('downsample'+str(i+2),AdjustLayer(in_channels[i], out_channels[i]))def forward(self, features):if self.num == 1:return self.downsample(features)else:out = []for i in range(self.num):adj_layer = getattr(self, 'downsample'+str(i+2))out.append(adj_layer(features[i]))return out
可見上面的AdjustAllLayer的作用就是對特征提取網絡輸出的三個特征圖分別做1x1卷積,調整所有特征圖的通道數為256。論文中也有提及:
An extra 1 x 1 convolution layer is appended to each of block outputs to reduce the channel to 256
上述代碼中有個很有趣的forward,即
def forward(self, x):x = self.downsample(x)if x.size(3) < 20:l = 4r = l + 7x = x[:, :, l:r, l:r]return x
這么做是為了什么呢?我們發現原文中提到:
Since the paddings of all layers are kept, the spatial size of the template feature increases to 15, which imposes a heavy computational burden on the correlation module. Thus we crop the center 7 x 7 regions as the template feature where each feature cell can still capture the entire target region.
原來是因為降低運算量所以對template的特征圖進行了裁剪,恍然大悟呀!原來原文中的細節都在代碼中有所描述,所以我十分推薦大家結合代碼看論文,這是非常容易進行理解的。
特征提取以及所有通道都壓縮至256后,緊接著代碼實現如下:
cls, loc = self.head(zf, xf)
其中head定義如下:
self.head = MultiRPN(**{'anchor_num': 5, 'in_channels': [256, 256, 256], 'weighted': True})
其中MultiRPN定義如下:
class MultiRPN(RPN):def __init__(self, anchor_num, in_channels, weighted=False):super(MultiRPN, self).__init__()self.weighted = weightedfor i in range(len(in_channels)):self.add_module('rpn'+str(i+2),DepthwiseRPN(anchor_num, in_channels[i], in_channels[i]))if self.weighted:self.cls_weight = nn.Parameter(torch.ones(len(in_channels)))self.loc_weight = nn.Parameter(torch.ones(len(in_channels)))def forward(self, z_fs, x_fs):cls = []loc = []for idx, (z_f, x_f) in enumerate(zip(z_fs, x_fs), start=2):rpn = getattr(self, 'rpn'+str(idx))c, l = rpn(z_f, x_f)cls.append(c)loc.append(l)if self.weighted:cls_weight = F.softmax(self.cls_weight, 0)loc_weight = F.softmax(self.loc_weight, 0)def avg(lst):return sum(lst) / len(lst)def weighted_avg(lst, weight):s = 0for i in range(len(weight)):s += lst[i] * weight[i]return sif self.weighted:return weighted_avg(cls, cls_weight), weighted_avg(loc, loc_weight)else:return avg(cls), avg(loc)
(3)深層互相關Depthwise Cross Correlation
Siamese RPN++中選用了Depth-wise Cross Correlation Layer對Template和Search Region進行卷積運算。這么做是為了降低計算量。具體實現過程如下
class DepthwiseXCorr(nn.Module):def __init__(self, in_channels, hidden, out_channels, kernel_size=3, hidden_kernel_size=5):super(DepthwiseXCorr, self).__init__()self.conv_kernel = nn.Sequential(nn.Conv2d(in_channels, hidden, kernel_size=kernel_size, bias=False),nn.BatchNorm2d(hidden),nn.ReLU(inplace=True),)self.conv_search = nn.Sequential(nn.Conv2d(in_channels, hidden, kernel_size=kernel_size, bias=False),nn.BatchNorm2d(hidden),nn.ReLU(inplace=True),)self.head = nn.Sequential(nn.Conv2d(hidden, hidden, kernel_size=1, bias=False),nn.BatchNorm2d(hidden),nn.ReLU(inplace=True),nn.Conv2d(hidden, out_channels, kernel_size=1))def forward(self, kernel, search):kernel = self.conv_kernel(kernel)search = self.conv_search(search)feature = xcorr_depthwise(search, kernel)out = self.head(feature) #維度提升return outclass DepthwiseRPN(RPN):def __init__(self, anchor_num=5, in_channels=256, out_channels=256):super(DepthwiseRPN, self).__init__()self.cls = DepthwiseXCorr(in_channels, out_channels, 2 * anchor_num)self.loc = DepthwiseXCorr(in_channels, out_channels, 4 * anchor_num)def forward(self, z_f, x_f):cls = self.cls(z_f, x_f)loc = self.loc(z_f, x_f)return cls, loc
其中xcorr_depthwise定義如下
def xcorr_depthwise(x, kernel):"""depthwise cross correlation"""batch = kernel.size(0)channel = kernel.size(1)x = x.view(1, batch*channel, x.size(2), x.size(3))kernel = kernel.view(batch*channel, 1, kernel.size(2), kernel.size(3))out = F.conv2d(x, kernel, groups=batch*channel)out = out.view(batch, channel, out.size(2), out.size(3))return out
實質上Depthwise Cross Correlation采用的就是分組卷積的思想,分組卷積可以帶來運算量的大幅度降低,被廣泛用于MobileNet系列網絡中。
通過上述代碼可以看出,與Siamese RPN網絡不同,Siamese RPN++提升網絡通道數為2k或者4k的操作是在卷積操作( Cross Correlation)之后,而Siamese RPN網絡是在卷積操作之前,這樣就減少了大量的計算量了。這在DepthwiseXCorr類中的forward中定義出來了,如下:
def forward(self, kernel, search):kernel = self.conv_kernel(kernel)search = self.conv_search(search)feature = xcorr_depthwise(search, kernel)out = self.head(feature) #維度提升return out
上面的self.head運算就是升維運算(到2k或者4k),可以看出,其發生在xcorr_depthwise之后。
最后的最后,網絡最后輸出的3個cls和loc分支進行了按權重融合。這在MultiRPN的forward定義了,如下:
def forward(self, z_fs, x_fs):cls = []loc = []for idx, (z_f, x_f) in enumerate(zip(z_fs, x_fs), start=2):rpn = getattr(self, 'rpn'+str(idx))c, l = rpn(z_f, x_f)cls.append(c)loc.append(l)if self.weighted:cls_weight = F.softmax(self.cls_weight, 0)loc_weight = F.softmax(self.loc_weight, 0)def avg(lst):return sum(lst) / len(lst)def weighted_avg(lst, weight):s = 0for i in range(len(weight)):s += lst[i] * weight[i]return sif self.weighted:return weighted_avg(cls, cls_weight), weighted_avg(loc, loc_weight)else:return avg(cls), avg(loc)
總結
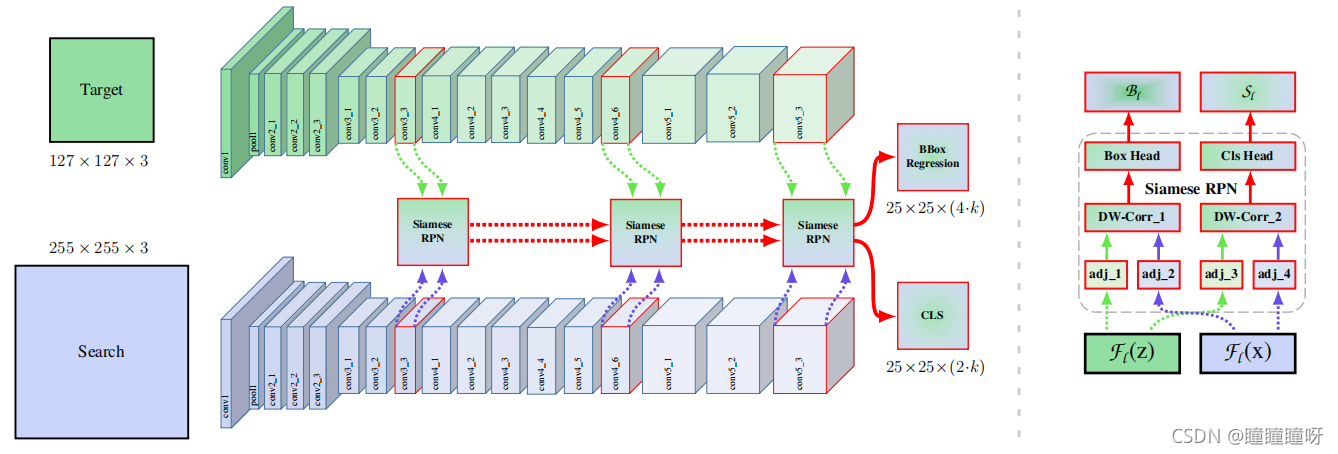
至此,Siamese RPN++的網絡結構就講解結束了,代碼總結如下:
def forward(self, template, detection):zf = self.features(template) #ResNet-50特征提取xf = self.features(detection)zf = self.neck(zf) #降低維度為256xf = self.neck(xf)cls, loc = self.head(zf, xf) #RPNreturn cls, loc
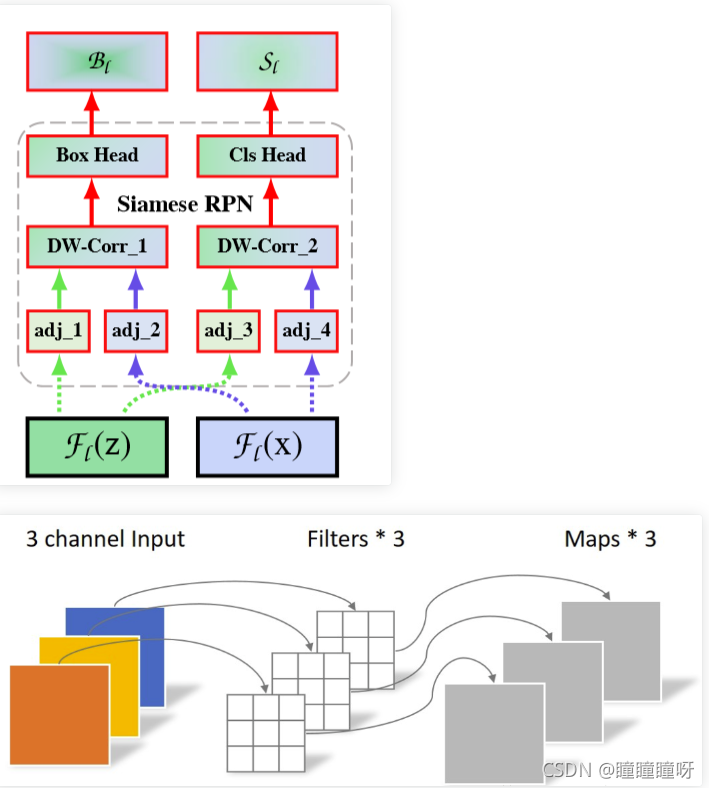
總體的結構圖如下:
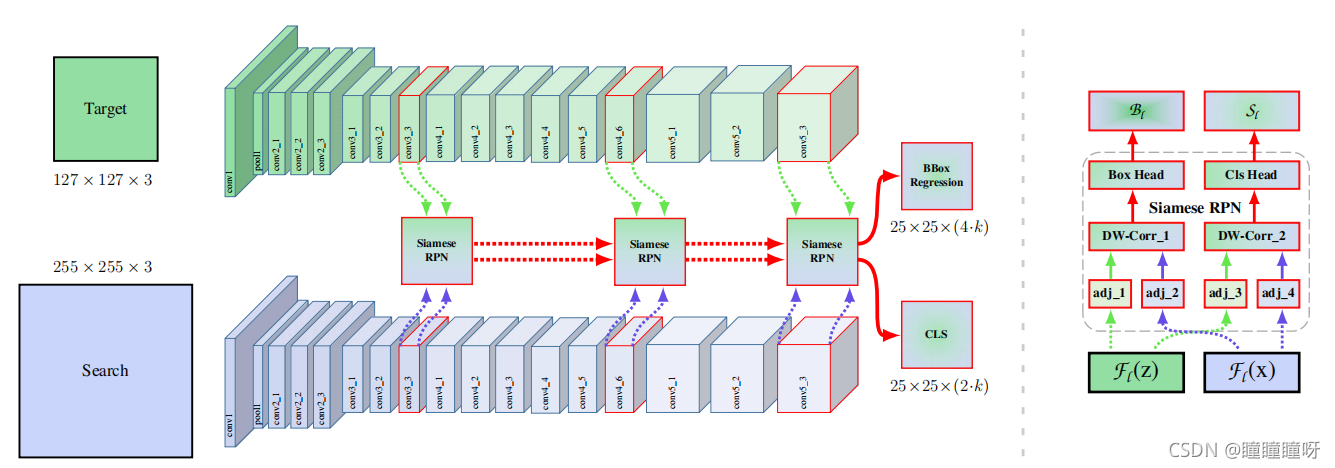
圖中右側的支路中
- adj系列就是降維為256的1x1卷積
- DW_Conv就是Depthwise Cross Correlation操作
- Box_Head就是提升維度為4k的1x1卷積
- Cls_Head就是提升維度為2k的1x1卷積
至此,Siamese RPN++的結構解析也結束了。
論文翻譯
Abstract

1. Introduction

2. Related Work

3. Siamese Tracking with Very Deep Networks

3.1. Analysis on Siamese Networks for Tracking

3.2. ResNet-driven Siamese Tracking

3.3. Layer-wise Aggregation

3.4. Depthwise Cross Correlation

4. Experimental Results
4.1. Training Dataset and Evaluation

4.2. Implementation Details

4.3. Ablation Experiments

4.4. Comparison with the state-of-the-art

5. Conclusions

 :解析)


















![bzoj 1016 [JSOI2008]最小生成樹計數——matrix tree(相同權值的邊為階段縮點)(碼力)...](http://pic.xiahunao.cn/bzoj 1016 [JSOI2008]最小生成樹計數——matrix tree(相同權值的邊為階段縮點)(碼力)...)