SiameseRPN
- 論文來源
- 論文背景
- 一,簡介
- 二,研究動機
- 三、相關工作
- 論文理論
- 注意:
- 網絡結構:
- 1.Siamese Network
- 2.RPN
- 3.LOSS計算
- 4.Tracking
- 論文的優缺點分析
- 一、Siamese-RPN的貢獻/優點:
- 二、Siamese-RPN的缺點:
- 代碼流程
- 一、訓練部分:
- 二、跟蹤部分
- 論文翻譯
- 學術詞語知識
- Abstract
- 1. Introduction
- 2. Related Works
- 2.1. Trackers based on Siamese network structure
- 2.2. RPN in detection
- 2.3. One-shot learning
- 3. Siamese-RPN framework
- 3.1. Siamese feature extraction subnetwork
- 3.2. Region proposal subnetwork
- 3.3. Training phase: End-to-end train Siamese-RPN
- 4. Tracking as one-shot detection
- 4.1. Formulation
- 4.2. Inference phase: Perform one-shot detection
- 4.3. Proposal selection
- 5. Experiments
- 5.1. Implementation details
- 5.2. Result on VOT2015
- 5.3. Result on VOT2016
- 5.4. Result on VOT2017 real-time experiment
- 5.5. Result on OTB2015
- 5.6. Discussion
- 6. Conclusion
論文來源
論文鏈接:這里
本文參考:
論文閱讀:Siam-RPN
【SOT】Siamese RPN論文解讀和代碼解析
[深度學習] [目標跟蹤] Siamese-RPN論文閱讀筆記
【論文筆記】目標跟蹤算法之Siamese-RPN
論文閱讀,目標跟蹤 SiameseRPN
論文背景
一,簡介
這篇文章是在SiamFC的基礎上改進的,其特征提取網絡跟SiamFC一模一樣,不同的是引入了目標檢測領域的區域推薦網絡(RPN),通過RPN網絡的回歸避免多尺度測試,一方面提升了速度,另一方面可以得到更加準確的目標框。另一個強大的地方在于,該算法可以利用稀疏標注的數據進行訓練,如Youtube-BB,該數據集不是每一幀都有標注,而是隔幾十幀標注一幀,這樣極大地擴充了訓練數據,大家都知道跟蹤屆的數據是非常寶貴的。要訓練一個好的模型,數據量大是關鍵啊。
二,研究動機
作者將流行的跟蹤算法分為兩類,一類是基于相關濾波類并進行在線更新的跟蹤算法,另一類是使用深度特征拋棄在線更新的跟蹤算法,前者嚴重限制了跟蹤速度,后者沒有使用域特定信息(即某個特定的跟蹤視頻的信息)。
作者提出的網絡分為模板支和檢測支。訓練過程中,在相關特征圖上執行proposal extraction、沒有預定義好的類別信息;在跟蹤過程中使用one-shot檢測框架和meta-learning。其中,兩個原因使得跟蹤算法效果很好:大量數據訓練;RPN結構使得跟蹤尺度和比例都非常好。
三、相關工作
相關濾波類的跟蹤算法:GOTURN、Re3、Siamese-FC、CFNet。后兩個沒有做回歸去調整候選框位置,并且需要多尺度測試,破壞了模型的優雅性。
RPN網絡:RPN網絡廣泛應用在目標檢測任務中,從RCNN到Faster-RCNN,RPN網絡產生proposals代替了原始的selective search方法,提高了檢測速度,后來FPN改進了RPN網絡,提高了對微小物體的檢測能力,以及后來的PRN的改進版本的使用,像SSD、YOLO等都是非常高效的檢測器。
One-shot learning:貝葉斯方法和meta-learning方法。后者用新的神經網絡估計目標網絡前向傳播的梯度。(However, the performance of Learnet is not competitive the modern DCF based methods, e.g.CCOT in multiple benchmarks )
論文理論
注意:
特別注意:RPN首次是從Faster RCNN中引入過來的
如果對其中某些參數不明白,可以參考一文讀懂Faster RCNN
網絡結構:
- Siamese Network
- RPN
- LOSS計算
- Tracking
1.Siamese Network
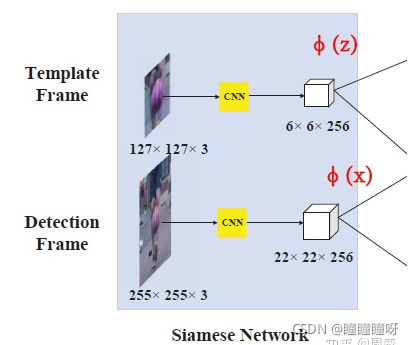
Siamese網絡用來提取特征。
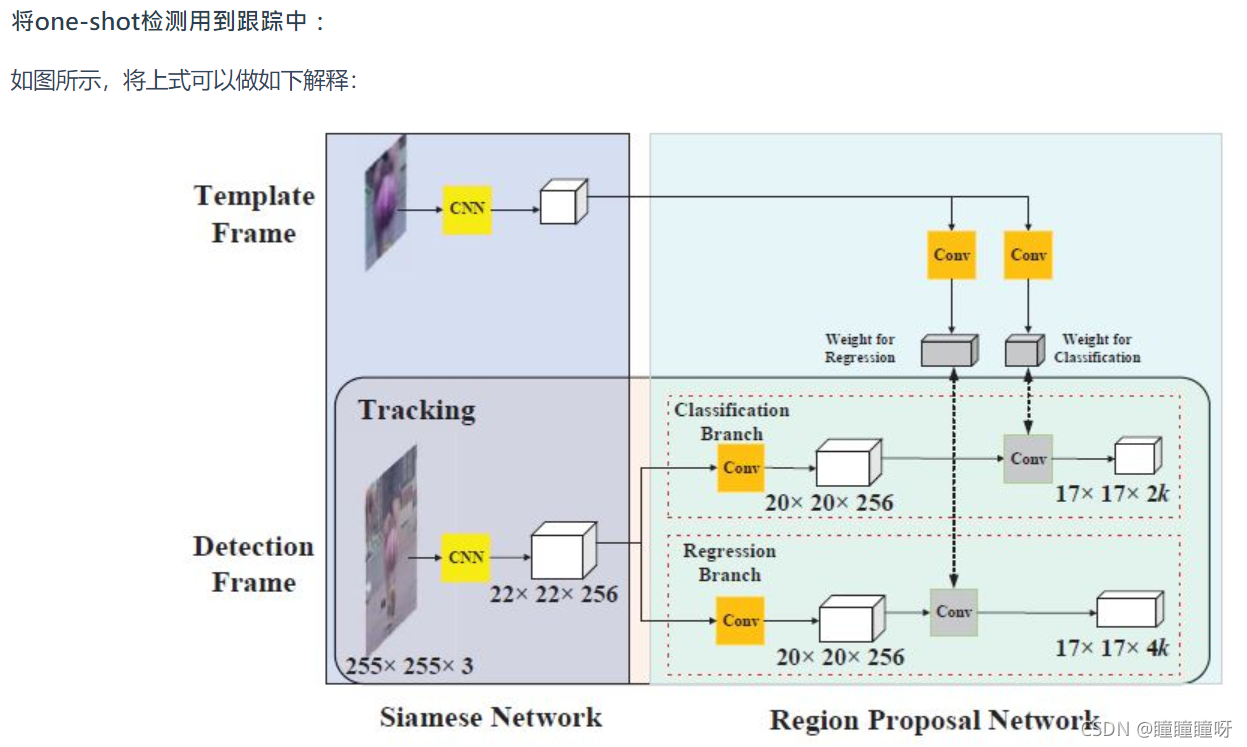
該孿生網絡接受兩個輸入,一個叫做template frame(模板幀),是從視頻第一幀中人為框出來(可以理解為原圖中裁剪的一個區域)的物體位置;另一個輸入叫做detection frame(檢測幀),是被檢測的視頻段除了第一幀之外的其他幀。該Siamese(AlexNet)網絡將這兩個圖像分別映射為6x6x256大小的特征圖z 和22x22x256大小的特征圖 x。
2.RPN
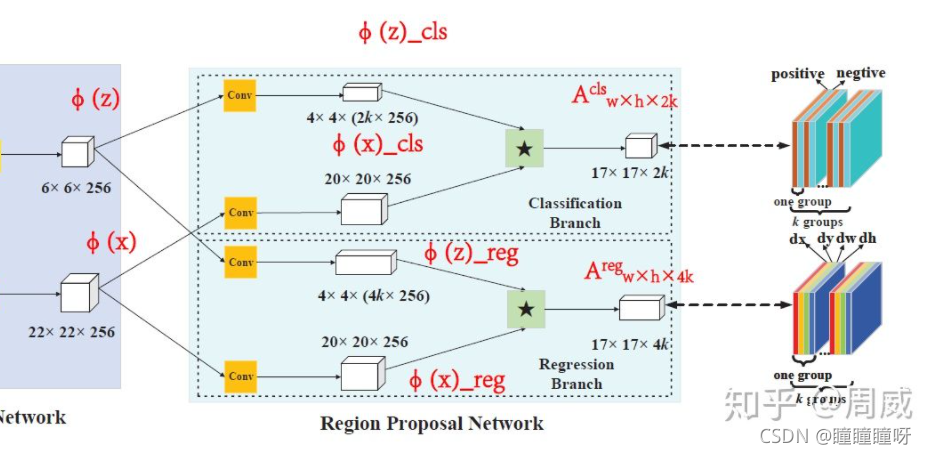

1、在RPN子網絡中需要將z的輸出通過不同卷積核resize成4×4×2k×256和4×4×4k×256的尺寸,這里k表示k個anchor,anchor的概念在Faster R-CNN中介紹。本文使用一種尺度的anchor,用五種不同的比例,所以這篇文章中k為5;
2、其中2k中兩個通道分別表示這個anchor是正樣本和負樣本的概率,4k表示anchor和ground-truth之間的差別;
3.LOSS計算
SiameseRPN使用的損失函數與faster rcnn的損失函數一樣。在分類上使用了softmax,回歸bounding box使用了smooth L1損失。這里只簡單介紹回歸的損失。
首先來看看什么是smooth L1損失函數。
借用一下知乎尹博的圖
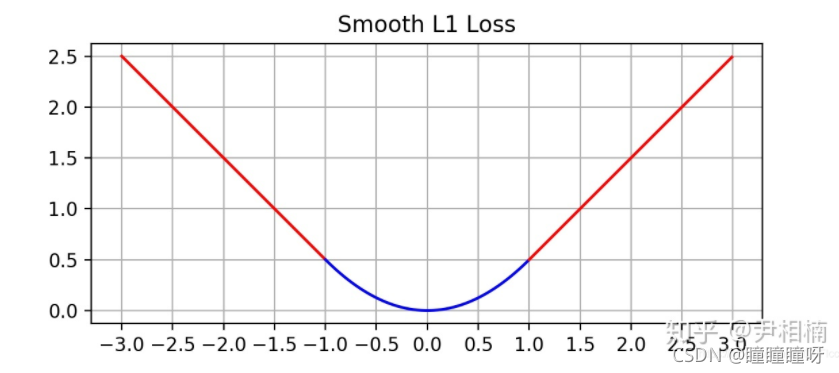
從圖中可以看到,在遠離坐標原點處,圖像和L 1 L1L1 損失很接近,而在坐標原點附近,轉折十分平滑,不像L 1 L1L1損失那樣有個尖角,因此叫做smooth L 1 L1L1損失。
smoothL 1 L1L1損失函數的數學表達式為:
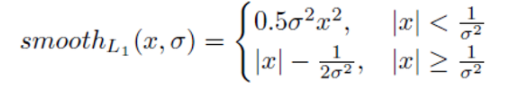

(偷偷說一下,代碼中的權重為5)
4.Tracking
1.One-shot跟蹤:
one-shot檢測:
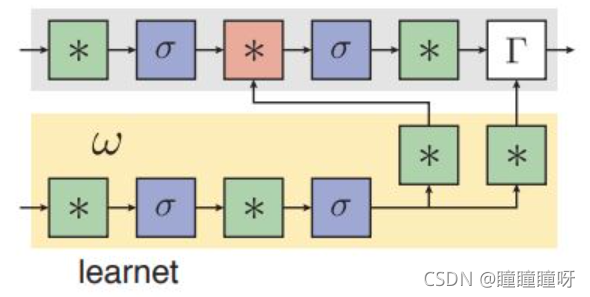
該篇文章是第一次將one-shot策略用在跟蹤任務中,這篇文章是講如何實現one-shot learning的。最核心的思想方法就是通過離線訓練的方法得到一個了learner net(文章里簡稱為learnet),然后通過在線的方式動態生成一個pupil net的參數,而且learnet只需要一張樣本就可以生成pupil net的網絡參數。Pupil net可以為分類器或者其他任務。為了簡單起見,參數為動態生成的只有其中一層或者兩層,如圖所示,*代表有參數的層,紅色的代表參數由learnet動態生成的。


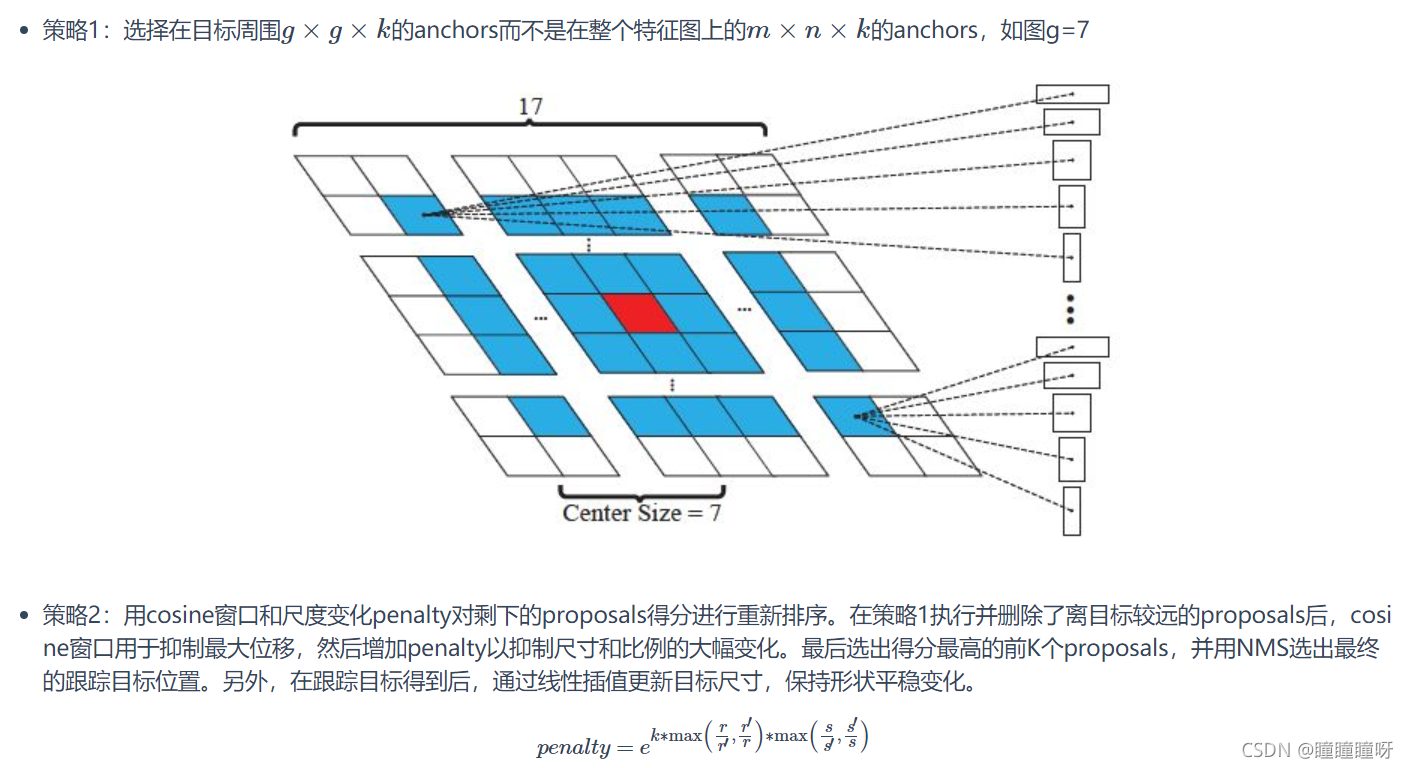
2.proposals選擇策略:
論文的優缺點分析
一、Siamese-RPN的貢獻/優點:
-
提出siamese region proposal network(Siamese-RPN)用于解決目標跟蹤問題。該網絡可利用“圖片對”進行端到端地離線訓練;
-
該模型可將在線跟蹤任務轉換為one-shot檢測任務,而不是使用低效費時的多尺度測試(multi-scale test);
-
該模型將SiameseFC和Faster R-CNN巧妙結合起來,讓RPN的計算變成并行,大大降低了運行時間,在保證準確率的同時,達到了較高的速度。
二、Siamese-RPN的缺點:
-
使用第一幀作為模板匹配,對目標巨大變化不具有魯棒性;
-
與SiameseFC相比,這篇文章的方法需要對輸入圖片resize,丟失一些信息。
代碼流程
一、訓練部分:
9.
9.9日更新:新推兩篇文章在這方面講的也非常好!
RPN的功能實現(流程與理解)
RPN的深度理解(實現層面)
二、跟蹤部分
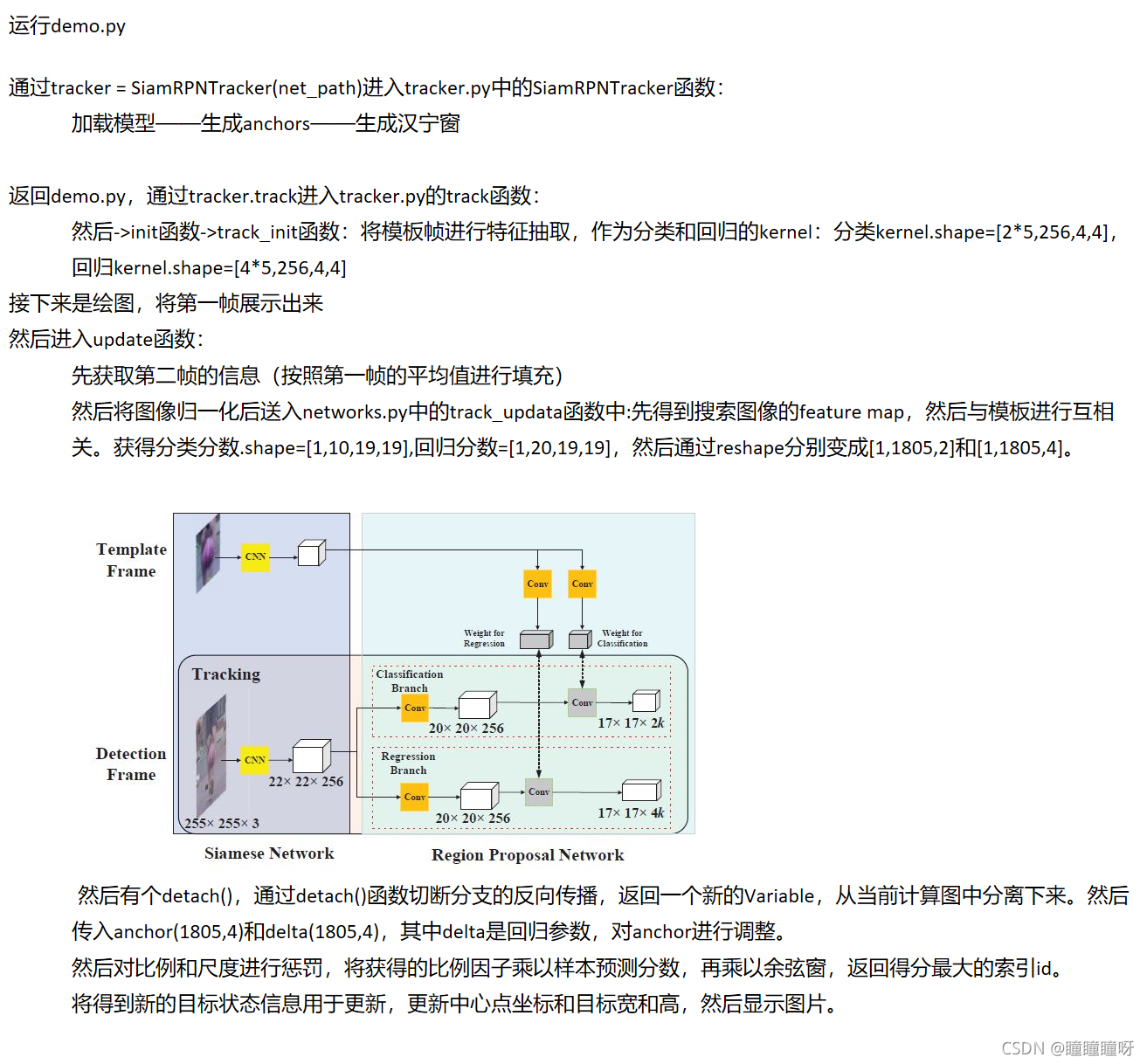
論文翻譯
學術詞語知識
對于文章的一些學術詞語:
one-short Learning:
參考什么是One-shot Learning 、Zero-shot Learning?
meta-learning:
參考:什么是meta-learning?
affine transformation:
參考:仿射變換(Affine Transformation)
ground truth:
參考:機器學習里經常出現ground truth這個詞,能否準確解釋一下?
還有我找到了一個比較好的關于卷積公式的解釋:

Abstract

1. Introduction

2. Related Works

2.1. Trackers based on Siamese network structure

2.2. RPN in detection

2.3. One-shot learning

3. Siamese-RPN framework

3.1. Siamese feature extraction subnetwork

3.2. Region proposal subnetwork

3.3. Training phase: End-to-end train Siamese-RPN

4. Tracking as one-shot detection

4.1. Formulation

4.2. Inference phase: Perform one-shot detection

4.3. Proposal selection

5. Experiments

5.1. Implementation details

5.2. Result on VOT2015

5.3. Result on VOT2016

5.4. Result on VOT2017 real-time experiment

5.5. Result on OTB2015

5.6. Discussion

6. Conclusion







 :解析)












