SiameseFC
- 前言
- 論文來源
- 參考文章
- 論文原理解讀
- 首先要知道什么是SOT?(Siamese要做什么)
- SiameseFC要解決什么問題?
- SiameseFC用了什么方法解決?
- SiameseFC網絡效果如何?
- SiameseFC基本框架結構
- SiameseFC網絡結構
- SiameseFC基本流程
- SiamFC完整的跟蹤過程
- 論文的思考與優化
- SiameseFC的優點:
- SiameseFC的不足:(Siamese一直有魯棒性不好的問題)
- 論文代碼解讀
- 訓練階段:
- 1.backbones.py分析
- 2.heads.py分析
- 3.train.py分析
- 4.transforms.py分析
- 5.ops.py分析(train相關部分)
- 6.datasets.py
- 7.siamfc.py分析(重點:train相關部分)
- tracking部分:
- siamfc.py(tracking部分)
- 論文翻譯+解讀
- Abstract
- 1 Introduction
- 2 Deep Similarity Learning for Tracking
- 2.1 Fully-Convolutional Siamese Architecture
- 2.2 Training with Large Search Images
- 2.3 ImageNet Video for Tracking
- 2.4 Practical Considerations
- 3 Related Work
- 4 Experiments
- 4.1 Implementation Details
- 4.2 Evaluation
- 4.3 The OTB-13 Benchmark
- 4.4 The VOT Benchmarks
- 4.5 Dataset Size
- 5 Conclusion
前言
論文來源
論文:Fully-Convolutional Siamese Networks for Object Tracking
項目官方地址(包括論文下載地址、源碼地址等):這里
參考文章
論文閱讀:SiameseFC
精讀深度學習論文(31) SiameseFC
【SOT】siameseFC論文和代碼解析
淺談SiameseFC的優點與不足
siamfc-pytorch代碼講解(一):backbone&head
SiamFC完整的跟蹤過程
其余的文章參考較少,在文中時會給出參考文章。
論文原理解讀
首先要知道什么是SOT?(Siamese要做什么)
SOT的思想是,在視頻中的某一幀中框出你需要跟蹤目標的bounding box,在后續的視頻幀中,無需你再檢測出物體的bounding box進行匹配,而是通過某種相似度的計算,尋找需要跟蹤的對象在后續幀的位置,如下動圖所示(圖中使用的是本章所講siameseFC的升級版siameseMask),常見的經典的方法有KCF[2]等。
SiameseFC要解決什么問題?
而目前基于深度學習的方法,要不就是采用 shallow methods(如:correlation filters)利用網絡的中間表示作為 feature;要不就是執行 SGD 算法來微調多層網絡結構。但是,利用 shallow 的方法并不能充分發揮 end-to-end 訓練的優勢,采用 SGD 的方法來微調也無法達到實時的要求。
將DL用于tracking中,有兩點制約其發展:
1、訓練數據的稀缺。由于跟蹤目標事先未知,只能通過最初的框選定,無法預先準備大量訓練數據。
2、實時的約束。對于跟蹤問題來說,基于DL的做法雖然能有效提升模型的豐富度,能夠很好的提升跟蹤的效果,但是在時效性這一方面卻做的很差,因為DL復雜的模型往往需要很大的計算量,尤其是當使用的DL模型在跟蹤的時候需要對模型進行更新的話,需要在線SGD調整網絡參數,限制了速度,可能使用GPU都沒法達到實時。
SiameseFC分別針對這兩點,利用ILSVRC15 數據庫中用于目標檢測的視頻來訓練模型(離線訓練),在跟蹤時,不更新模型(也就沒有fine-tuning),保證速度夠快。成為了使用了CNN進行跟蹤,同時又具有很高的效率的跟蹤算法。并因其速度很快,效果很好,成為之后很多算法(例如CFNet、DCFNet)的baseline。
SiameseFC用了什么方法解決?
使用孿生網絡(Siamese Net)結構來進行相似度比較,對比模版圖片(在訓練前應該指定好)和需比較的目標圖片之間的相似度。
SiameseFC網絡效果如何?
速度是SiameseFC的最大優勢。
可以用于追蹤任意物體(不需要預先訓練)。
在當時某幾個benchmark上達到了最優。
SiameseFC基本框架結構
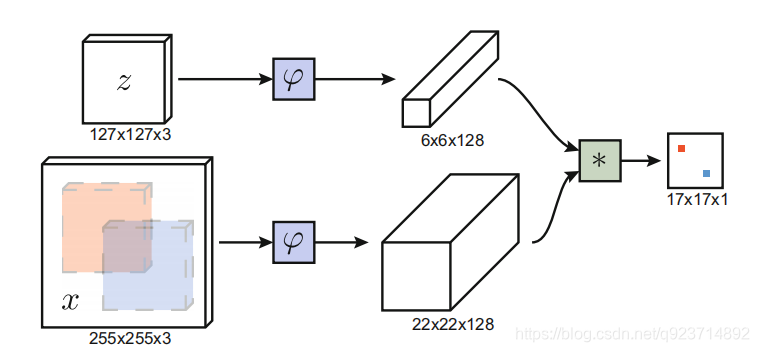
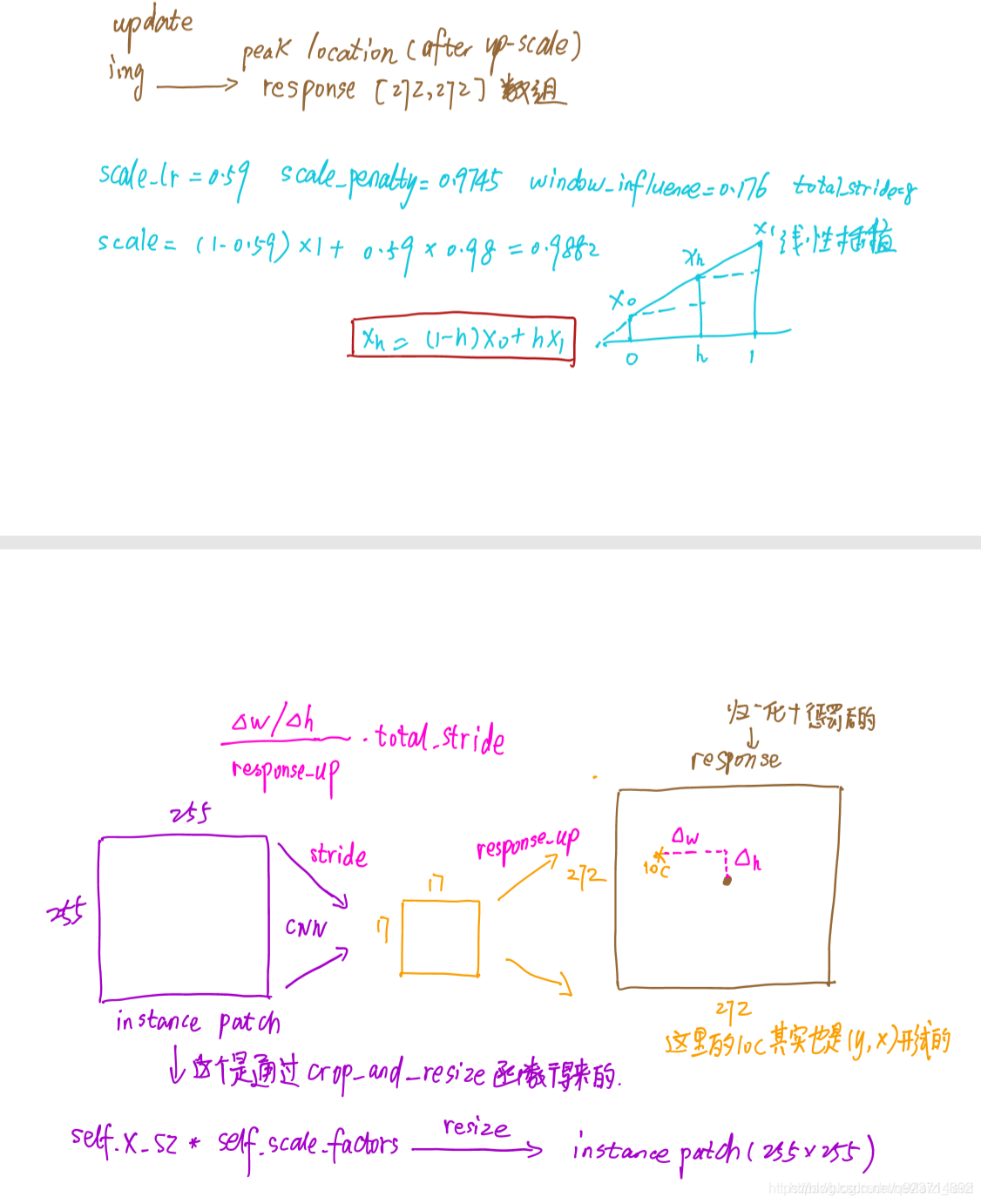
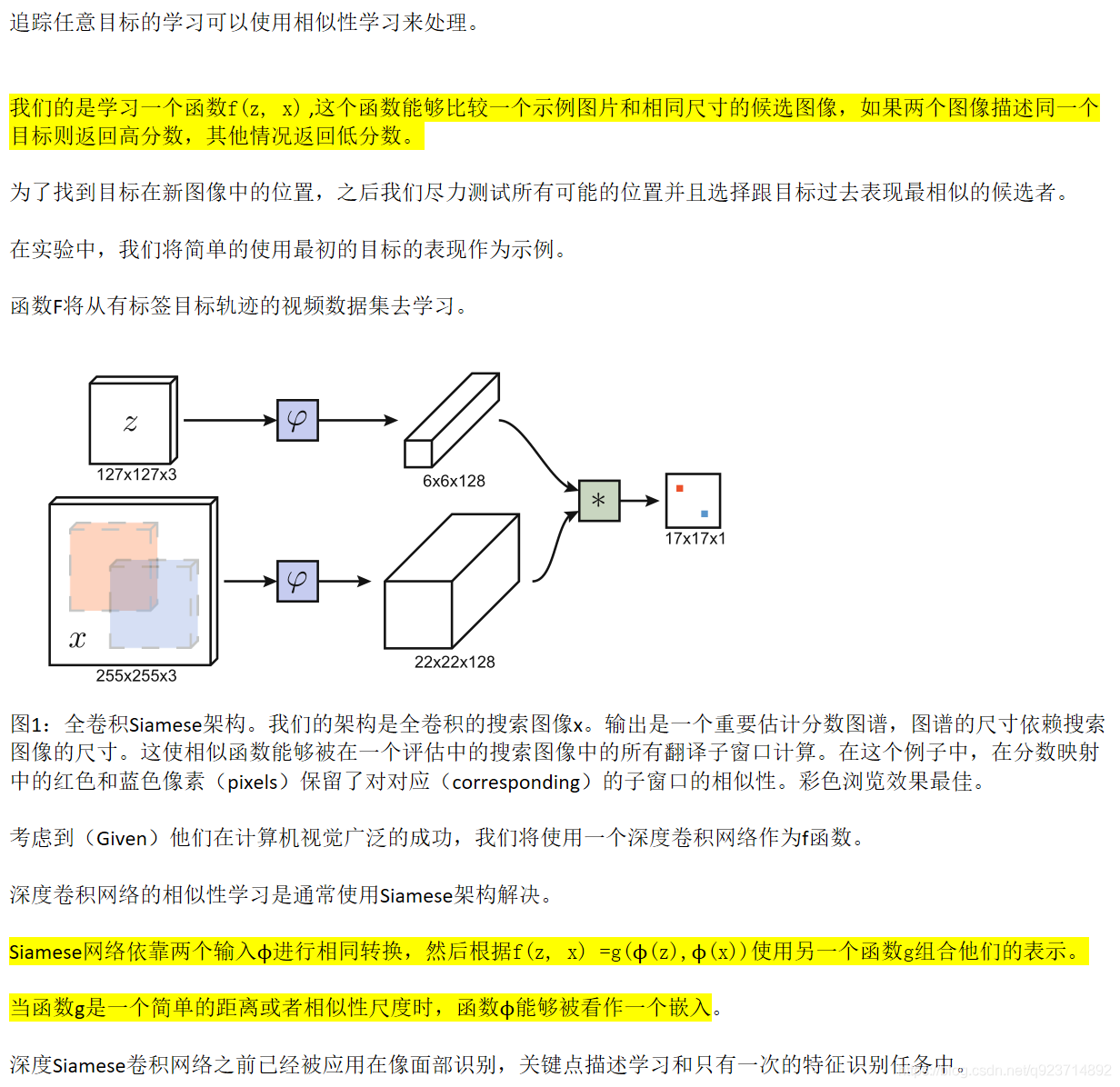
圖中z代表的是模板圖像,算法中使用的是第一幀的groundtruth;x代表的是search region,代表在后面的待跟蹤幀中的候選框搜索區域;?代表的是一種特征映射操作,將原始圖像映射到特定的特征空間,文中采用的是CNN中的卷積層和pooling層;66128代表z經過?后得到的特征,是一個128通道66大小feature,同理,2222128是x經過?后的特征;后面的代表卷積操作,讓2222128的feature被66128的卷積核卷積,得到一個17*17的score map,代表著search region中各個位置與模板相似度值。score越大,相似度越大,越有可能是同一個物體。
總體來說,卷積網絡將search image作為整體輸入,直接計算兩個輸入圖像的feature map的相似度匹配,節省了計算。計算得到相似度最高的位置,并反向計算出目標在原圖中的位置。
算法本身是比較搜索區域與目標模板的相似度,最后得到搜索區域的score map。其實從原理上來說,這種方法和相關性濾波的方法很相似。其在搜索區域中逐個的對目標模板進行匹配,將這種逐個平移匹配計算相似度的方法看成是一種卷積,然后在卷積結果中找到相似度值最大的點,作為新的目標的中心。
上述互相關運算的步驟,像極了我們手里拿著一張目標的照片(模板圖像),然后把這個照片按在需要尋找目標的圖片上(搜索圖像)進行移動,然后求重疊部分的相似度,從而找到這個目標,只不過為了計算機計算的方便,使用AlexNet對圖像數據進行了編碼/特征提取。
上圖所畫的?其實是CNN中的一部分,并且兩個?的網絡結構是一樣的,這是一種典型的孿生神經網絡,并且在整個模型中只有conv層和pooling層,因此這也是一種典型的全卷積(fully-convolutional)神經網絡。
如果上面沒看懂,下面給出另一種我覺得也很棒的解釋:
孿生結構網絡是卷積神經網絡中的一種特殊結構。其結構如上圖所示,它由兩個結構相同的子網絡構成,網絡的輸入是兩張像,其中一張稱為模板圖像,通常選取的是序列第一幀,另外一張稱為搜索圖像,選取的是后續幀,每一個子網絡負責處理一張圖像,通過子網絡的前向計算,可以提取圖像的特征,最后將兩者特征通過相似性度量函數,最終計算得到一個17×17×1的熱力圖,代表著搜索圖像中各個位置與模板圖像的相似度值。并根據以下函數計算相似度(卷積函數):
其中z是模板圖像,x是搜索圖像,
φ代表的是一種特征映射操作,將原始圖像映射成特定的空間特征,這里采用的是卷積神經網絡里的卷積層和池化層,f是相似性度量函數,這里代表的是卷積函數。模板圖像雖然使用的是視頻序列的第一幀,但是它是經過裁剪而來的,以待跟蹤目標為中心,把原圖像裁剪成127×127的尺寸。
也是經過裁剪而來的,它是以網絡上一次輸出的目標位置的中心點作為裁剪的中心,裁剪成固定的255×255的尺寸。
在這里就相當于充當一個待跟蹤目標的外觀模型,與后續圖像幀里面的對象進行配對,熱力圖最里面分值最高的那個點則認為是與待跟蹤對象外觀模型最相似,就認為它是后續幀里的待跟蹤對象。
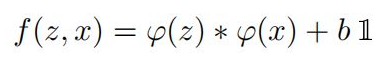
SiameseFC網絡結構
用模板的CNN特征與搜索圖像的特征進行卷積,得到整個圖像的相似圖。網絡結構如下:(有的博客中說整個網絡結構類似與AlexNet,但是沒有最后的全連接層,只有前面的卷積層和pooling層。 )
整個網絡結構入上表,其中pooling層采用的是max-pooling,每個卷積層后面都有一個ReLU非線性激活層,但是第五層沒有。另外,在訓練的時候,每個ReLU層前都使用了batch normalization,用于降低過擬合的風險。
SiameseFC基本流程
一,獲取輸入數據:
SiameseFC需要的輸入數據有模版圖片z和候選圖片x。
- 模版圖片z的構建:
- 構建模版圖片時,知道當前幀的bbox。
- 訓練時,所有圖片的bbox都是已知的。
- 預測時,第一幀bbox已知的,且預測是順序預測,因此,預測過程中,預測幀前一幀的bbox是已知的。
- 總體過程:
- 以bbox的中心為中心,構建一個面積為127*127的區域,如果超出范圍則通過平均值進行pad。
- 將該區域resize為127*127。(上一步中的長寬可能不是127)
- 構建127127區域的方式如下:其中A=127127,h和w代表bbox的長寬:
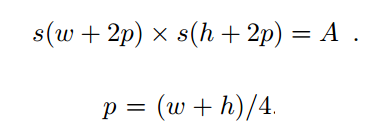
- 構建模版圖片時,知道當前幀的bbox。
- 候選圖片x的構建:
- 構建時已知其上一幀bbox的信息。
- 總體過程:
- 以上一幀bbox的中心為中心,構建一個面積為255*255的區域,如果超出范圍則通過平均值進行pad。
- 將該區域resize為255*255。(上一步中的長寬可能不是255)
- 構建255*255區域與構建模版圖片z時采用相同的縮放比例。
二,通過分數矩陣獲取追蹤結果
總體過程:
- 首先,對分數矩陣進行線性變換,變換到原始圖片的大小。
- 如圖中,將圖片1717分數矩陣轉換為255255。
- 然后,結合位置信息,獲取最終得分信息。
- 最后,選擇得分最高的位置作為中心,獲取最新的bbox。
- bbox的長寬跟之前一幀的長寬一致。
三,通過分數矩陣進行訓練
-
使用交叉熵作為損失函數。對于score map中每個點,損失函數如下:
- 其中,其中v是score map中每個點真實值,y∈{+1,?1}是這個點所對應的標簽。
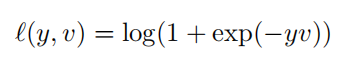
- 其中,其中v是score map中每個點真實值,y∈{+1,?1}是這個點所對應的標簽。
-
總體損失函數如下:
6×6和22×22的feature map“卷積”得到17×17的score map。對于每個score map,計算其loss為每個卷積得到的6*6小圖的loss的均值。即:
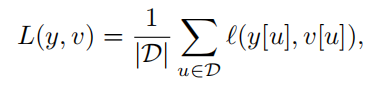
這里的u∈D代表score map中的位置。 卷積網絡的參數由SGD方法最小化上圖損失函數得到。這里采用的是卷積神經網絡里的卷積層和池化層,f是相似性度量函數,這里代表的是卷積函數。 -
構建標簽y
比較預測bbox中心點與 ground truth 的bbox中心點之間的距離。
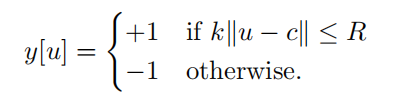
-
計算相似度(卷積函數)
根據以下函數計算相似度(卷積函數):
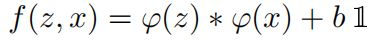
其中z是模板圖像,x是搜索圖像, φ代表的是一種特征映射操作,將原始圖像映射成特定的空間特征
四, 多尺寸處理
思路:
- 模版圖片z保持不變。
- 對搜索圖片x進行尺寸變換,同樣提取255*255的區域,計算相似度,獲取相似度最大點的坐標。
- 對于最終bbox進行等比例變換(比例就是對搜索圖片x進行變換的比例)。
五,訓練的一些細節
- 訓練采用的框架是MatConvNet
- 訓練采用的優化算法就是batch SGD,batch大小是8
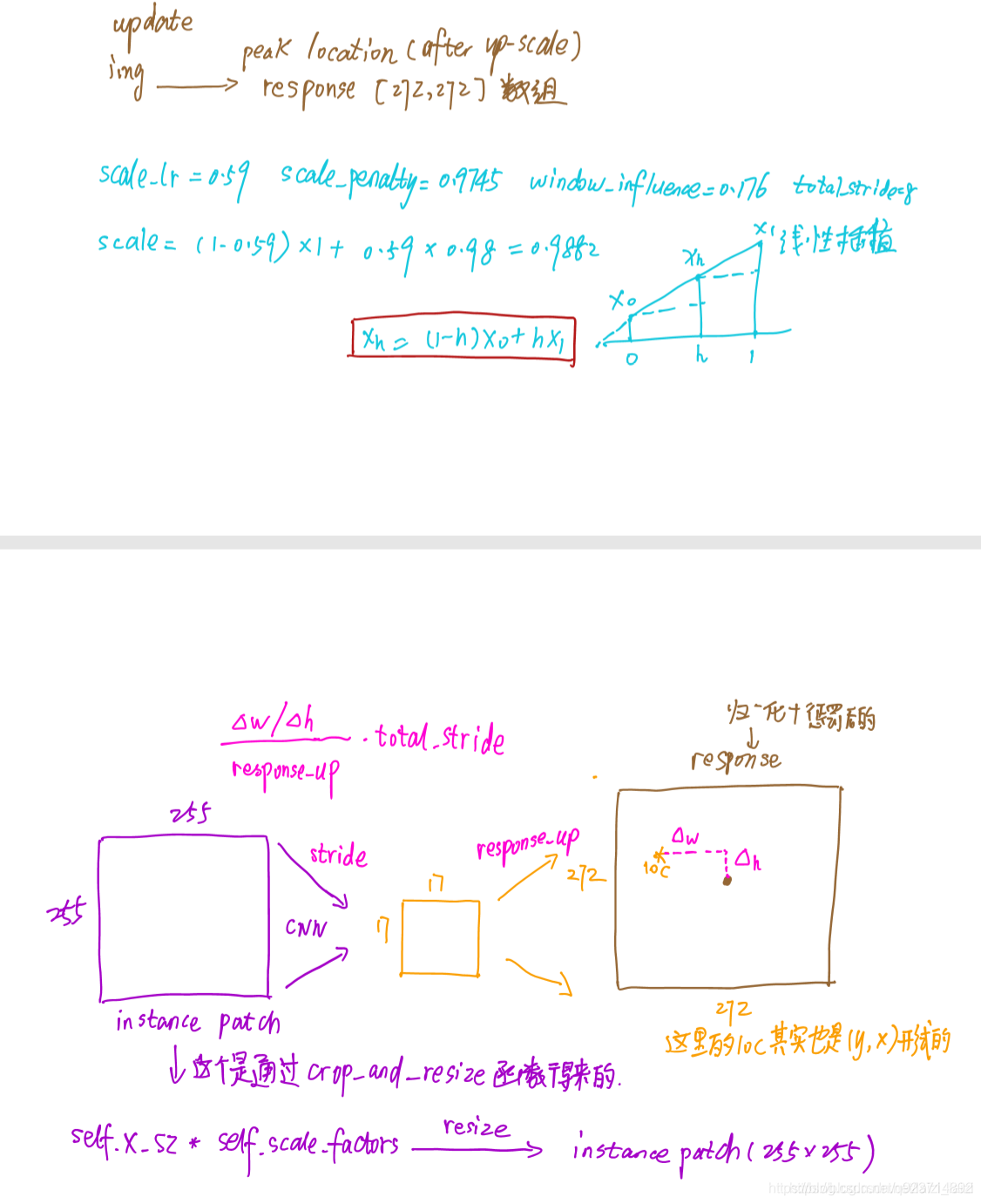
- 跟蹤時直接對score map進行線性插值,將1717的score map擴大為272272,這樣原來score map中響應值最大的點映射回272*272目標位置。
- 對訓練的數據庫中數據進行一些處理
- 扔掉一些類別: snake,train,whale,lizard 等,因為這些物體經常僅僅出現身體的某一部分,且常在圖像邊緣出現;
- 排除太大 或者 太小的物體;
- 排除離邊界很近的物體。
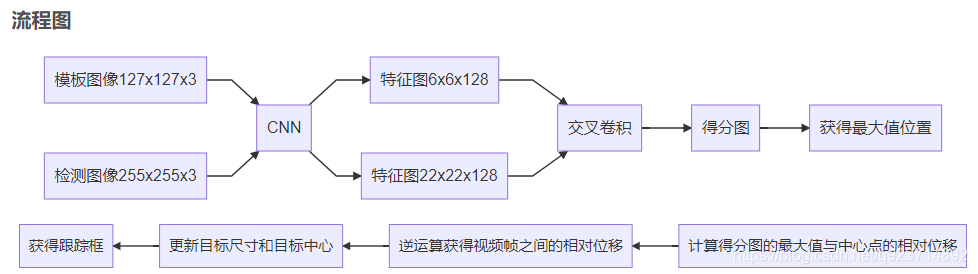
SiamFC完整的跟蹤過程
參考:SiamFC完整的跟蹤過程
-
準備兩路輸入圖像:模板圖像和檢測圖像。
-
設置模板圖像和檢測圖像的邊長,分別用z_sz和x_sz表示。
-
設置content,前后文信息

即
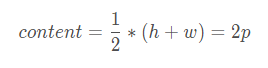
-
設置z_sz = sqrt(Az)

即
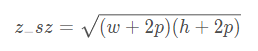
-
設置x_sz=sqrt(Ax)
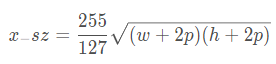
-
-
對模板圖像而言:在第一幀以z_sz為邊長,以目標中心為中心點,截取圖像補丁(如果超出第一幀的尺寸,用均值填充)。之后將其resize為127x127x3.成為模板圖像
-
對檢測圖像而言:在第二幀及以后,分別以x_sz*1.0375^{[-2,-0.5,1]}為邊長,以前一幀目標中心為中心點,截取圖像補丁(如果超出第一幀的尺寸,用均值填充)。之后將三個圖像補丁都resize為255x255x3.成為檢測圖像
-
-
將模板圖像和檢測圖像輸入CNN網絡中,分別得到6x6x128和22x22x128的特征圖。
-
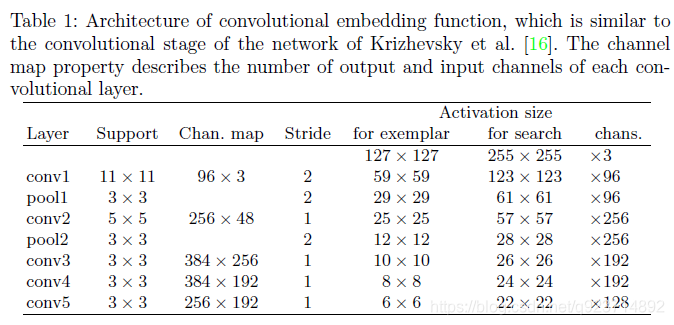
最后使用交叉相關,將模板圖像的特征圖當做卷積核,對檢測圖像的特征進行滑窗檢測,最后得到3x1x17x17的得分圖(三個尺度)。交叉函數如下所示:
f(x,z)=φ(z)?φ(x)+bi? -
使用雙三次線性插值生成277x277的圖像: 3x277x277.
-
獲得三個得分圖中最大值的位置(x,y)。
-
獲得最大值位置與上一幀目標中心的相對位移。
-
因為之前是crop,再resize得到檢測圖像,之后CNN(包含交叉卷積)得到得分圖,最后上采樣得到[3,277,277]。所以將第(6)步得到的相對位移進行逆運算,最終獲得視頻幀之間的相對位移。
-
根據相對位移更新目標的中心點。
-
獲得目標尺寸變換的比例(最大值所在的尺度(三個尺度中的一個)):
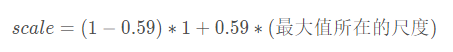
- 更新目標尺寸:target_sz*scale
- 更新x_sz:x_sz*scale
- 更新z_sz:z_sz*scale
-
畫出跟蹤框。
這是我詳細debug的記錄:里面也有對其的一些理解:

論文的思考與優化
SiameseFC的優點:
1、實時性(>24幀/s):
SiamFC-3s FPS : 86幀/s
SiamFC-5s FPS : 58幀/s
該網絡把跟蹤任務轉換成一個模板匹配的問題而不是一個常見的二分類問題,整個跟蹤過程中不需要更新模板,使得算法的速度大幅度提高。這也是深度學習領域神經網絡在目標跟蹤一直以來難以到達的一個關鍵點,直到孿生網絡應用于目標跟蹤使得在跟蹤精度較高的條件下還達到了實時性,在深度學習領域不愧為重大的突破,繼此網絡后,基于此網絡為基本框架的目標跟蹤算法層出不盡并且精度、速度能達到一個兼顧,占據深度學習應用在目標跟蹤中的主流方向。
2、小范圍晃動
對于小范圍晃動,背景信息變化不大使得模板匹配的結果較好

3、運動模糊

4、短時局部遮擋
模板匹配對短暫性局部遮擋處理較好

SiameseFC的不足:(Siamese一直有魯棒性不好的問題)
SiameseFC是一個模板匹配的任務,在跟蹤過程中并不更新目標模板和網絡權值,這造成如下問題:
(1)當目標發生較大的形變時,會造成目標候選框與目標模板出現較大差異,從而導致跟蹤失敗。網絡權值不更新導致要使用同一套網絡結構和網絡參數適應所有的跟蹤場景,這是很難做到的。
(2)對于沒有處于復雜背景下的跟蹤來說,該算法能基本平衡實時性與準確性要求,但是跟蹤目標一旦發生遮擋、快速運動、相似外觀,搜索圖像的大小可能就覆蓋不了目標,通過最后的相似性度量函數得出來的結果就是錯誤的,隨著跟蹤過程中發生的錯誤累加,導致跟蹤不可恢復,所以孿生結構網絡的跟蹤性能在背景復雜的情況下會下降。



失敗原因:
-
目標特征不夠具體、突出、全面 (AlexNet提取特征不夠細致)
-
沒能利用好空間信息、運動信息 (運動模型不夠合理)
-
搜索域方法的局限性 (多尺度增加計算量,無法適應尺度變化)
-
匹配與分類的本質差別 (分類對背景前景區分較好)
解決思路:
-
加入在線更新的策略(增加目標信息,犧牲速度或者增強特征的提取)
-
需要對首幀標注圖像做處理(抑制背景信息,增加前景和背景的區分度)
SiamFC選用第一幀作為模板并不予更新,因此首幀目標信息為關鍵信息,而SiamFC模型中,最后采用相似度學習,如果不能降模板圖像中背景信息的干擾,則必然會對結果造成影響。 因此應當對標注圖像進行進一步的目標提取,并對背景信息進行抑制。 -
利用空間信息,估計運動模型
在存在較多相似目標的場景中,可能特征匹配難以準確地判斷哪個才是真正的目標。而人在這種場景下追蹤目標的策略往往是根據
(1)目標的空間信息,例如一隊人中的第幾個,或者目標周圍有哪些參照物。這一點可以通過對目標旁邊的背景進行建模實現。
(2)根據目標的運動軌跡進行預測,因為目標的變化(無論是位置還是外觀)在序列中往往是連續可微的。
論文代碼解讀
這里主要參考:siamfc-pytorch代碼講解(三):demo&track
更簡潔的請參考:【SOT】siameseFC論文和代碼解析講的也很棒~
訓練階段:
1.backbones.py分析
功能分析:
這個module主要實現了3個AlexNet版本作為backbone,開頭的__all__ = [‘AlexNetV1’, ‘AlexNetV2’, ‘AlexNetV3’]主要是為了讓別的module導入這個backbones.py的東西時,只能導入__all__后面的部分。
后面就是三個類AlexNetV1、AlexNetV2、AlexNetV3,他們都集成了類_AlexNet,所以他們都是使用同樣的forward函數,依次通過五個卷積層,每個卷積層使用nn.Sequential()堆疊,只是他們各自的total_stride和具體每層卷積層實現稍有不同(當然跟原本的AlexNet還是有些差別的,比如通道數上):
AlexNetV1和AlexNetV2:
共同點:conv2、conv4、conv5這幾層都用了groups=2的分組卷積,這跟原來的AlexNet會更接近一點
不同點:conv2中的MaxPool2d的stride不一樣大,conv5層的輸出通道數不一樣
AlexNetV1和AlexNetV3:前兩層的MaxPool2d是一樣的,但是中間層的卷積層輸入輸出通道都不一樣,最后的輸出通道也不一樣,AlexNetV3最后輸出經過了BN
AlexNetV2和AlexNetV3:conv2中的MaxPool2d的stride不一樣,AlexNetV2最后輸出通道數小很多。
其實感覺即使有這些區別,但是這并不是很重要,這一部分也是整體當中容易理解的,所以不必太去糾結為什么不一樣,最后作者用的是AlexNetV1,論文中是這樣的結構,其實也就是AlexNetV1:

代碼分析
1.def __init__(self, num_features, *args, **kwargs):中*args和**kwargs到底是什么
參考Python中*args、**args到底是什么、有啥區別、怎么用
*args的用法:當傳入的參數個數未知,且不需要知道參數名稱時。
**args的用法:當傳入的參數個數未知,但需要知道參數的名稱時(立馬想到了字典,即鍵值對)
也就是說**args在輸入的時候一般是鍵值對,而*args任意。
注意:這里的args不是必須的,也就是說可以換成kwargs等等,但是星號是必須的。
2.BatchNorm2d函數分析:
參考:BatchNorm2d原理、作用及其pytorch中BatchNorm2d函數的參數講解
例如BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- num_features:一般輸入參數為batch_sizenum_featuresheight*width,即為其中特征的數量,即為輸入BN層的通道數;
- eps:分母中添加的一個值,目的是為了計算的穩定性,默認為:1e-5,避免分母為0;
- momentum:一個用于運行過程中均值和方差的一個估計參數(我的理解是一個穩定系數,類似于SGD中的momentum的系數);
- affine:當設為true時,會給定可以學習的系數矩陣gamma和beta



3.nn.ReLU(inplace=True)代碼分析
參考:PyTorch------nn.ReLU(inplace = True)詳解
inplace = False 時,不會修改輸入對象的值,而是返回一個新創建的對象,所以打印出對象存儲地址不同,類似于C語言的值傳遞
inplace = True 時,會修改輸入對象的值,所以打印出對象存儲地址相同,類似于C語言的址傳遞
即當inplace = True 時,在原地改變值而不是賦予新值。
4.output stride = 4解析:
output stride為該矩陣經過多次卷積pooling操作后,尺寸縮小的值(這個還保留疑問)
5.__all__ = ['AlexNetV1', 'AlexNetV2', 'AlexNetV3']中__all__解析
參考:python中【all】的用法
__all__是一個字符串list,用來定義模塊中對于from XXX import 時要對外導出的符號,即要暴露的接口,但它只對import *起作用,對from XXX import XXX不起作用。
控制 from xxx import * 的行為
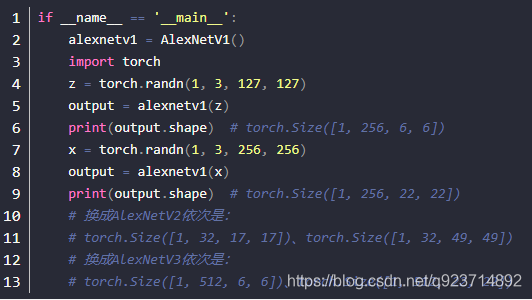
6.nn.Conv2d(384, 32, 3, 1, groups=2))這個groups=2
這個groups=2,是將卷積分為兩組:
2.heads.py分析
from __future__ import absolute_importimport torch.nn as nn
import torch.nn.functional as F__all__ = ['SiamFC']class SiamFC(nn.Module):def __init__(self, out_scale=0.001):super(SiamFC, self).__init__()self.out_scale = out_scaledef forward(self, z, x):return self._fast_xcorr(z, x) * self.out_scaledef _fast_xcorr(self, z, x):# fast cross correlation# x size 8,256,20,20# z size 8,256,6,6nz = z.size(0) #size(0)即取第一個shape值#nz = 8nx, c, h, w = x.size()#nx = 8,c = 256,h = 20,w = 20x = x.view(-1, nz * c, h, w)#x.shape = [1,2048,20,20]out = F.conv2d(x, z, groups=nz)# out.shape = [1,8,15,15]#輸入是4維,輸出也是4維,高層補1# print(out.size())out = out.view(nx, -1, out.size(-2), out.size(-1))# out.shape = [8,1,15,15]return out功能分析:
為什么這里會有個out_scale,根據作者說是因為, z zz和x xx互相關之后的值太大,經過sigmoid函數之后會使值處于梯度飽和的那塊,梯度太小,乘以out_scale就是為了避免這個。
重點:nn.conv2d和nn.function2d解析
_fast_xcorr函數中最關鍵的部分就是F.conv2d函數了,可以通過官網查詢到用法:
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1) → Tensor
input – input tensor of shape (\text{minibatch} , \text{in_channels} , iH , iW)(minibatch,in_channels,iH,iW)
weight – filters of shape (\text{out_channels} , \frac{\text{in_channels}}{\text{groups}} , kH , kW)(out_channels, groups in_channels ,kH,kW)
bias – optional bias tensor of shape (\text{out_channels})(out_channels). Default: None
stride – the stride of the convolving kernel. Can be a single number or a tuple (sH, sW). Default: 1
padding –implicit paddings on both sides of the input. Can be a string {‘valid’, ‘same’}, single number or a tuple (padH, padW). Default: 0 padding=‘valid’ is the same as no padding. padding=‘same’ pads the input so the output has the shape as the input. However, this mode doesn’t support any stride values other than 1.
這里nn.Con2d要與nn.function.conv2d區分開:
參考:pytorch中nn.Conv2d和nn.function.conv2d的區別
- nn.Conv2d
torch.nn.Conv2d(in_channels,out_channels,kernel_size,stride=1,padding=0,dilation=1,groups=1,bias=True,padding_mode=‘zeros’)
in_channels-----輸入通道數
out_channels-------輸出通道數
kernel_size--------卷積核大小
stride-------------步長
padding---------是否對輸入數據填充0 - nn.function.conv2d
torch.nn.functional.conv2d(input,weight,bias=None,stride=1,padding=0,dilation=1,groups=1)
input-------輸入tensor大小(minibatch,in_channels,iH, iW)
weight------權重大小(out_channels, in_channels/groups, kH, kW)
注意:權重參數中,第一個卷積核的輸出通道數,第二個是輸入通道數
這里針對nn.function.conv2d討論
例如:torch.nn.functional.conv2d(self, input, weight, bias=None, stride=1, padding=0, dilation=1, groups=2)
input:
minibatch:batch中的樣例個數
in_channels:每個樣例數據的通道數
iH:每個樣例的高(行數)
iW:每個樣例的寬(列數)
weight(就是filter):
out_channels:卷積核的個數
in_channels/groups:每個卷積核的通道數
kH:每個卷積核的高(行數)
kW:每個卷積核的寬(列數)
groups作用:對input中的每個樣例數據,將通道分為groups等份,即每個樣例數據被分成了groups個大小為(in_channel/groups, iH, iW)的子數據。對于這每個子數據來說,卷積核的大小為(in_channel/groups, kH, kW)。這一整個樣例數據的計算結果為各個子數據的卷積結果拼接所得。
舉例:
import torch.nn.functional as F
inputs = torch.arange(1, 21).reshape(1, 2, 2, 5)
filters = torch.arange(1, 7).reshape(2, 1, 1, 3)
print(inputs)
print(filters)
res = F.conv2d(input=inputs, weight=filters, stride=(1, 1), groups=2)
print(res)
輸出如下:
tensor([[[[ 1, 2, 3, 4, 5],[ 6, 7, 8, 9, 10]],[[11, 12, 13, 14, 15],[16, 17, 18, 19, 20]]]])tensor([[[[1, 2, 3]]],[[[4, 5, 6]]]])tensor([[[[ 14, 20, 26],[ 44, 50, 56]],[[182, 197, 212],[257, 272, 287]]]])
樣例數據:
[ [ [ 1, 2, 3, 4, 5],[ 6, 7, 8, 9, 10] ],[ [11, 12, 13, 14, 15],[16, 17, 18, 19, 20] ] ]
被分成:
[ [ [ 1, 2, 3, 4, 5], [ [ [11, 12, 13, 14, 15],[ 6, 7, 8, 9, 10] ] ] 和 [16, 17, 18, 19, 20] ] ]
卷積核:
[ [ [ [ 1, 2, 3 ] ] ],[ [ [ 4, 5, 6 ] ] ] ]
被分成:
[ [ [1, 2, 3] ] ] 和 [ [4, 5, 6] ] ]
結果中:
[ [ 14, 20, 26],[ 44, 50, 56] ]
是
[ [ [ 1, 2, 3, 4, 5],[ 6, 7, 8, 9, 10] ] ] 和 [ [ [ 1, 2, 3 ] ] ] 卷積所得。
3.train.py分析
作者使用了GOT-10k這個工具箱,train.py代碼非常少
具體可以參考官方文檔:Downloads - GOT-10k
4.transforms.py分析
順著代碼流看到調用了siamfc.py中類TrackerSiamFC的train_over方法,在這個類里面就是進行數據增強,構造和加載,然后進行訓練,這里先討論transforms:
SiamFCTransforms是transforms.py里面的一個類,主要是對輸入的groung truth的z, x, bbox_z, bbox_x進行一系列變換,構成孿生網絡的輸入,這其中就包括了:
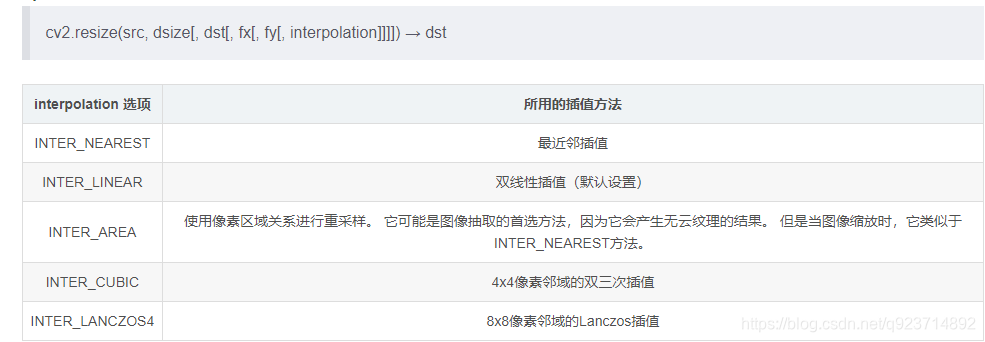
RandomStretch:主要是隨機的resize圖片的大小,其中要注意cv2.resize()的一點用法,可以參考這篇博客:cv2.resize()的一點小坑
CenterCrop:從img中間摳一塊(size, size)大小的patch,如果不夠大,以圖片均值進行pad之后再crop
RandomCrop:用法類似CenterCrop,只不過從隨機的位置摳,沒有pad的考慮
Compose:就是把一系列的transforms串起來
ToTensor: 就是字面意思,把np.ndarray轉化成torch tensor類型
代碼分析:
torch.from_numpy(img).float().permute((2, 0, 1))中permute(2,0,1)分析
參考:Pytorch之permute函數
permute(dims):將tensor的維度換位。
>>> x = torch.randn(2, 3, 5)
>>> x.size()
torch.Size([2, 3, 5])
>>> x.permute(2, 0, 1).size()
torch.Size([5, 2, 3])
if isinstance(size, numbers.Number):中isinstance分析
參考Python isinstance() 函數
isinstance() 函數來判斷一個對象是否是一個已知的類型,類似 type()。
isinstance() 與 type() 區別:
type() 不會認為子類是一種父類類型,不考慮繼承關系。
isinstance() 會認為子類是一種父類類型,考慮繼承關系。
如果要判斷兩個類型是否相同推薦使用 isinstance()。
在這里,isinstance是判斷size是否為正常數。np.random.choice
參考:理解python中的random.choice()
random模塊在python中起到的是生成隨機數的作用,random模塊中choice()可以從序列中獲取一個隨機元素,并返回一個(列表,元組或字符串中的)隨機項。- 圖像處理: 五種插值法
參考:圖像處理: 五種 插值法
下面具體講里面的_crop函數:
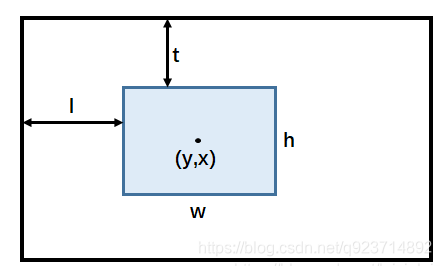
因為GOT-10k里面對于目標的bbox是以ltwh(即left, top, weight, height)形式給出的,上述代碼一開始就先把輸入的box變成center based,坐標形式變為[y, x, h, w],結合下面這幅圖就非常好理解: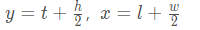
5.ops.py分析(train相關部分)
crop_and_resize

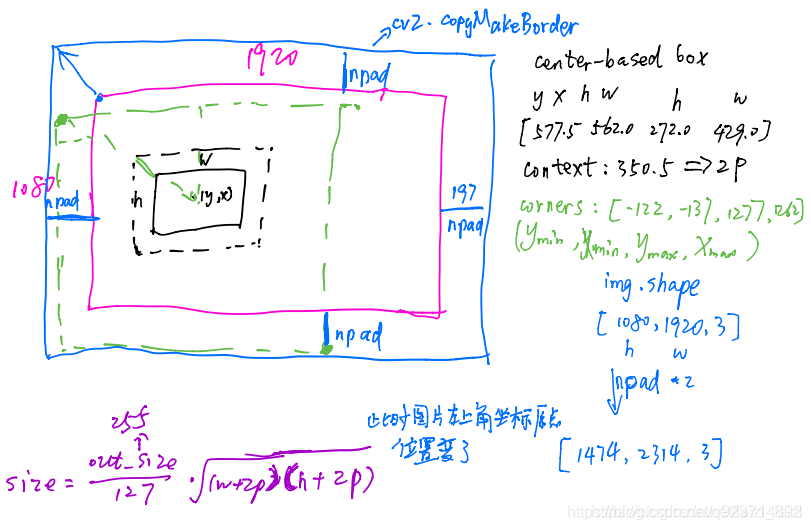
代碼分析:
img = cv2.copyMakeBorder(img, npad, npad, npad,npad,border_type,value=border_value)
參考:OpenCV-Python: cv2.copyMakeBorder()函數詳解

6.datasets.py
現在繼續回到train_over方法,里面構造dataset的時候用了Pair類,所以從代碼角度具體來看一下,因為繼承了Dataset類,所以要overwrite __getitem__和__len__方法:
getitem:分析代碼,這個方法就是通過index索引返回item = (z, x, box_z, box_x),然后經過transforms返回一對pair(z, x),就需要像論文里面說的:The images are extracted from two frames of a video that both contain the object and are at most T frames apart 。
_filter:通過該函數篩選符合條件的有效索引val_indices,這里不詳細分析,因為我也不知道為什么會有這樣的filter condition。
_sample_pair:如果有效索引大于2個的話,就從中隨機挑選兩個索引,這里取的間隔不超過T=100
len:這里定義的長度就是被索引到的視頻序列幀數×每個序列提供的對數
7.siamfc.py分析(重點:train相關部分)
train_step
現在來到siamfc.py里面最后一個關鍵的地方,數據準備好了,經過變換和加載進來就可以訓練了,下面代碼是常規操作,具體在train_step里面實現了訓練和反向傳播:
而train_step里面難度又是在于理解_create_labels,具體的一些tensor的shape可以看我的注釋,我好奇就把他打印出來了,看來本來__getitem__返回一對pair(z, x),經過dataloader的加載,還是z堆疊一起,x堆疊一起,并不是(z, x)綁定堆疊一起
而且criterion使用的BalancedLoss,是調用F.binary_cross_entropy_with_logits,進行一個element-wise的交叉熵計算,所以創建出來的labels的shape其實就是和responses的shape是一樣的:
創建標簽,論文里是這么說的:
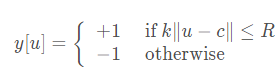
因為我們的exemplar image z zz 和search image x xx都是以目標為中心的,所以labels的中心為1,中心以外為0。
對于np.tile、np.meshgrid、np.where函數的使用:
參考:np.tile、np.meshgrid、np.where學習總結
最后出來的一個batch下某一個通道下的label就是下面這樣的:

還有train_over部分,就是保存模型,沒什么說的。
tracking部分:
現在就來看一下類TrackerSiamFC下的track方法。這個函數的作用就是傳入video sequence和first frame中的ground truth bbox,然后通過模型,得到后續幀的目標位置,可以看到主要有兩個函數實現:init和update,這也是繼承Tracker需要重寫的兩個方法:
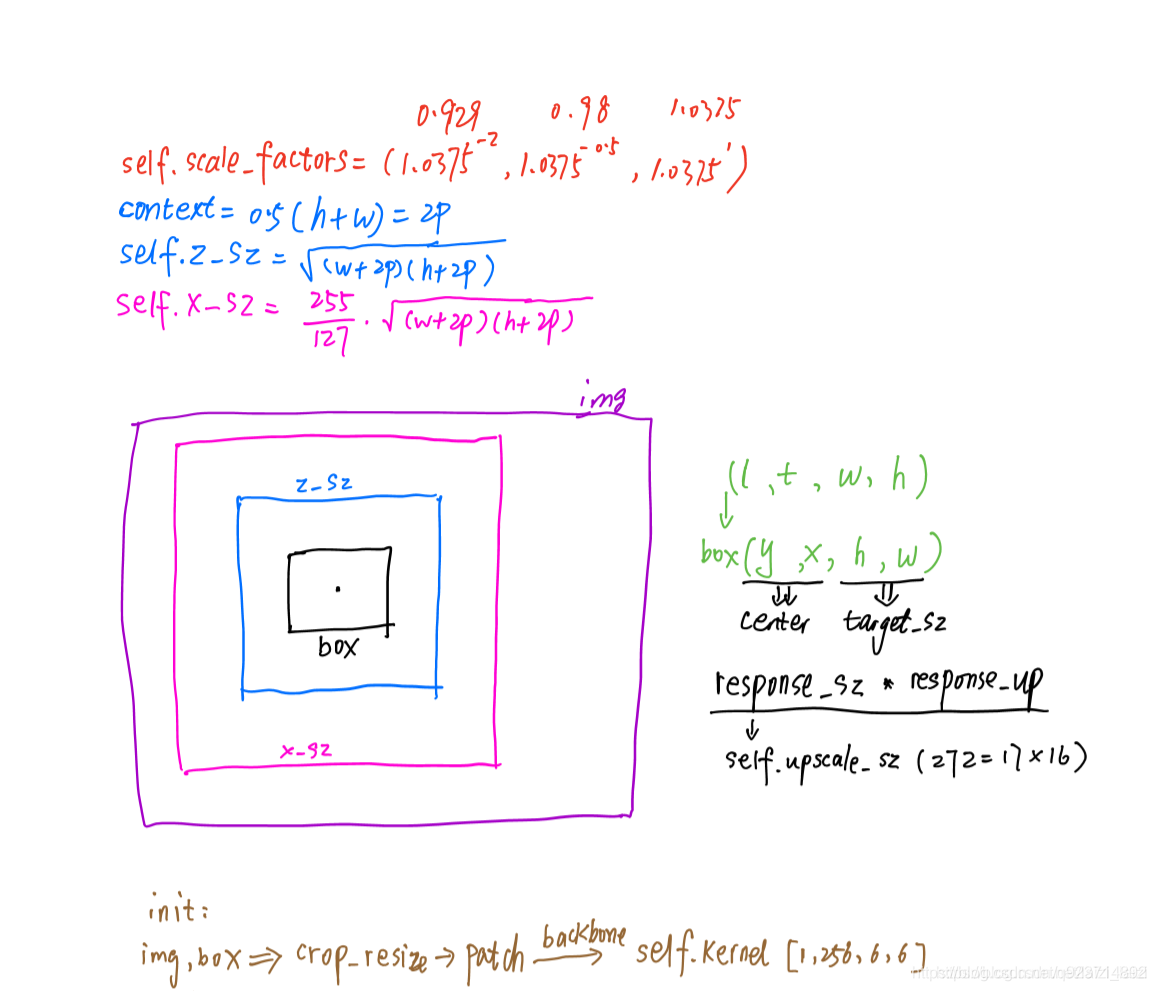
siamfc.py(tracking部分)
init(self, img, box):
init:就是傳入第一幀的標簽和圖片,初始化一些參數,計算一些之后搜索區域的中心等等

update:
update:就是傳入后續幀,然后根據SiamFC網絡返回目標的box坐標,之后就是根據這些坐標來show,起到一個demo的效果。

補充一些函數:
1.getatter():
參考:Python getatter() 通過方法名字符串調用方法
getattr()這個方法最主要的作用是實現反射機制。也就是說可以通過字符串獲取方法實例。
獲取函數/屬性/從模塊獲取類
2.enumerate()
參考:python中enumerate()函數的用法
enumerate(sequence, start=0),返回一個枚舉對象。sequence必須是序列或迭代器iterator,或者支持迭代的對象。enumerate()返回對象的每個元素都是一個元組,每個元組包括兩個值,一個是計數,一個是sequence的值,計數是從start開始的,start默認為0。
論文翻譯+解讀
Abstract

1 Introduction

2 Deep Similarity Learning for Tracking
全卷積在我另一篇文章有一個簡單的分析:FCN全卷積網絡隨筆
2.1 Fully-Convolutional Siamese Architecture

這里講解一下:
The position of the maximum score relative to the centre of the score map, multiplied by the stride of the network, gives the displacemen of the target from frame to frame.
我們假設有三個幀,第二幀的中心截取是按照第一幀的目標位置來截取的,如果要進行第三幀的中心截取,那我們需要按照第二幀對于第一幀的相對位移,來獲取第三幀的截取位置–也就是幀與幀之間的位移.網絡步長是指縮小的倍數.再經過一系列的卷積層之后,圖像縮小了一定的倍數,這個倍數就是網絡步長.當我們得到第二幀的map中目標點位置時,要與網絡步長相乘,就能知道第二幀目標相對第一幀的目標位移,第三幀就通過這個位移來進行中心截取.
2.2 Training with Large Search Images

2.3 ImageNet Video for Tracking

2.4 Practical Considerations

這里來講解一下這個公式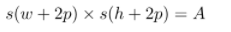
實際上,s是縮小的倍數,(h,w)是指長寬,而p是指邊框厚度,其結果A就是面積

3 Related Work

4 Experiments
4.1 Implementation Details

雙三插值的理解請看這個:插值(五)Bicubic interpolation(雙三次插值)
4.2 Evaluation

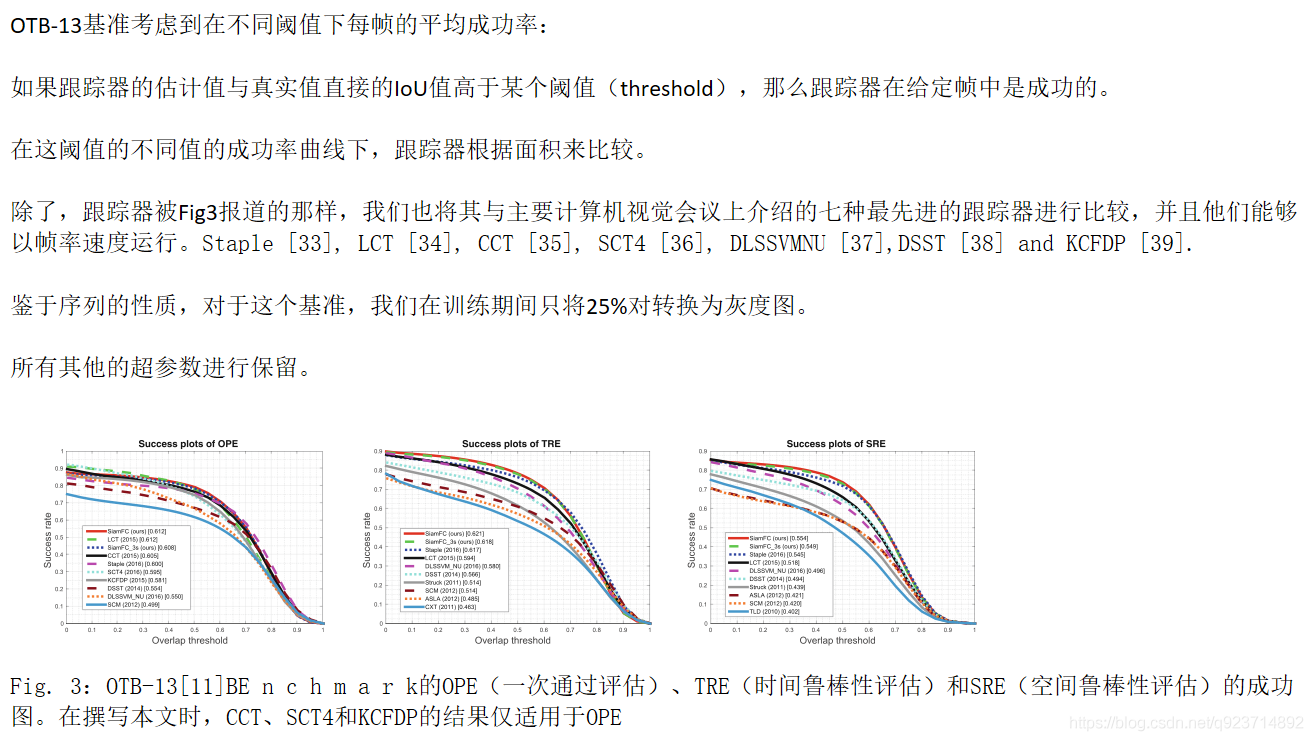
4.3 The OTB-13 Benchmark
4.4 The VOT Benchmarks

4.5 Dataset Size

5 Conclusion


)












 :解析)




