python交互式和文件式
In this tutorial, I will be creating an automated, interactive dashboard of Texas COVID-19 case count by county using python with the help of selenium, pandas, dash, and plotly. I am assuming the reader has some familiarity with python, pandas, and selenium. That’s all you’ll need to create amazing interactive dashboards after reading this tutorial!
在本教程中,我將在Selenium,熊貓,破折號和密謀的幫助下,使用python創建一個按州自動計數的德克薩斯州COVID-19案例的交互式儀表板。 我假設讀者對python,pandas和selenium有所了解。 閱讀本教程后,您僅需創建出色的交互式儀表板!
A general overview of the steps and what you will learn is as follows:
這些步驟的概述以及您將學到的內容如下:
- Downloading daily updated data from the web using selenium 使用Selenium從Web下載每日更新的數據
- Updating data directories using shutil, glob, and os python libraries 使用shutil,glob和os python庫更新數據目錄
- Simple cleaning of excel files with pandas 使用熊貓輕松清理Excel文件
- Formatting time series data frames to be input into plotly graphs 格式化時間序列數據幀以輸入到繪圖圖中
- Creating a local web page for your dashboard using dash 使用破折號為儀表板創建本地網頁
Before we get started, you will need to download the python libraries that will be used in this tutorial. This can be done with the following command on your terminal:
在開始之前,您需要下載將在本教程中使用的python庫。 可以在終端上使用以下命令來完成此操作:
pip install <package name># package names: selenium, pandas, webdriver_manager, shutil, glob, plotly,and dashOne thing to note is that I used Jupyter Notebooks for steps 1–4 and then Spyder for step 5. When I am explaining what a code block does it is usually the one right above the text. All of my code for this tutorial can be found on my GitHub under the Automate collecting of data notebooks file.
需要注意的一件事是,我在步驟1-4中使用了Jupyter Notebooks,然后在步驟5中使用了Spyder。當我解釋什么代碼塊時,通常是在文本上方。 在本教程的所有代碼都可以在GitHub上的“自動收集數據筆記本”文件中找到。
Ok, lets get started!
好的,讓我們開始吧!
Step 1: Downloading daily updated data from the web using selenium
步驟1:使用Selenium從網上下載每日更新的數據
# import packages
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
import shutil
import glob
import os
from unicodedata import *
import time# open a chrome browser using selenium
driver = webdriver.Chrome(ChromeDriverManager().install())# got to web page where excel file links are located
driver.get("https://www.dshs.texas.gov/coronavirus/additionaldata/")# these options allow selenium to download files
options = Options()
options.add_experimental_option("browser.download.folderList",2)
options.add_experimental_option("browser.download.manager.showWhenStarting", False)
options.add_experimental_option("browser.helperApps.neverAsk.saveToDisk", "application/octet-stream,application/vnd.ms-excel")So this first code block is pretty self explanatory but some things to note. I am installing a selenium chrome web driver, so I don’t have to always re-download the new chrome driver when it gets updated. This driver is used to download the excel file I want online. It will open up a new google chrome window on your computer and go to the web page that provides the daily updated Texas COVID-19 case counts for each county. The standard options of selenium do not allow for downloading files from the web so these options need to be changed to allow that.
因此,這第一個代碼塊很容易說明,但需要注意一些事項。 我正在安裝Selenium chrome網絡驅動程序,因此更新時無需總是重新下載新的chrome驅動程序。 該驅動程序用于下載我要在線的Excel文件。 它將在您的計算機上打開一個新的Google Chrome瀏覽器窗口,然后轉到該網頁 ,其中提供了每個縣的每日更新的德克薩斯州COVID-19案件計數。 Selenium的標準選項不允許從Web下載文件,因此需要更改這些選項以允許這樣做。
# initialize an object to the location on the web page and click on it to download
link = driver.find_element_by_xpath('/html/body/form/div[4]/div/div[3]/div[2]/div/div/ul[1]/li[1]/a')
link.click()# Wait for 15 seconds to allow chrome to download file
time.sleep(15)This block of code clicks on the link to the excel file using a full Xpath. This can be found by right clicking on a page, inspecting it, and right clicking on the link you want to click on, and copying the full Xpath. Then the driver clicks on the link and waits 15 seconds for it to be downloaded which is crucial for the next code block to not give you an error.
此代碼塊使用完整的Xpath單擊指向excel文件的鏈接。 可以通過以下方法找到:右鍵單擊頁面,檢查頁面,然后右鍵單擊要單擊的鏈接,然后復制完整的Xpath。 然后,驅動程序單擊鏈接,等待15秒鐘下載鏈接,這對于下一個代碼塊不給您錯誤是至關重要的。
2. Updating data directories using shutil, glob, and os python libraries
2.使用shutil,glob和os python庫更新數據目錄
Before reading onward: If you are following at home, you will need to change the paths that I use for both the download directory from ‘/Users/tsbloxsom/Downloads/*.xlsx’ to ‘/Users/<your_username>/Downloads/*.xlsx’
在繼續閱讀之前 :如果您在家中,則需要將我用于下載目錄的路徑從'/Users/tsbloxsom/Downloads/*.xlsx'更改為'/ Users / <您的用戶名> / Downloads / * .xlsx'
You will also need to change the directory where you want to store your data and python notebooks in from what I use: ‘/Users/tsbloxsom/Documents/GitHub/Texas-census-county-data-project/Automate collecting of data notebooks/*.xlsx’ to ‘/Users/<your_username>/bla/bla/*.xlsx’
您還需要從我使用的位置更改要用于存儲數據和python筆記本的目錄:'/ Users / tsbloxsom / Documents / GitHub / Texas-census-county-data-project /自動收集數據筆記本/ * .xlsx'到'/ Users / <您的用戶名> / bla / bla / *。xlsx'
# locating most recent .xlsx downloaded file
list_of_files = glob.glob('/Users/tsbloxsom/Downloads/*.xlsx')
latest_file = max(list_of_files, key=os.path.getmtime)# replace "\" with "/" so file path can be located by python
latest_file = latest_file.replace("\\", "/")
latest_file# we need to locate the old .xlsx file(s) in the dir we want to store the new xlsx file in
list_of_files = glob.glob('/Users/tsbloxsom/Documents/GitHub/Texas-census-county-data-project/Automate collecting of data notebooks/*.xlsx') # need to delete old xlsx file(s) so if we download new xlsx file with same name we do not get an error while moving it
for file in list_of_files:
print("deleting old xlsx file:", file)
os.remove(file)# Move the new file from the download dir to the github dir
shutil.move(latest_file,'/Users/tsbloxsom/Documents/GitHub/Texas-census-county-data-project/Automate collecting of data notebooks/')This code block is where a lot of the automation happens. It finds the excel file I just downloaded using the glob and os.path.getmtime functions, deletes any old excel file(s) (maybe from the previous day) in the directory I want to store the new excel file in, then moves the new excel file into the GitHub directory. The os.path.getmtime() function returns the time of last modification of the path, so with the max() function, you can find the most recently downloaded excel file.
此代碼塊是許多自動化發生的地方。 它會使用glob和os.path.getmtime函數找到我剛剛下載的excel文件,并刪除我想在其中存儲新excel文件的目錄中的所有舊excel文件(也許是前一天)。新的excel文件進??入GitHub目錄。 os.path.getmtime()函數返回路徑的最后修改時間,因此使用max()函數,您可以找到最近下載的excel文件。
Step 3: Simple cleaning of excel files with pandas
步驟3:使用熊貓輕松清理excel文件
Now that we have the up-to-date COVID-19 data in the directory we want, there is some cleaning we need to do before it can be plotted.
現在,我們在所需的目錄中擁有最新的COVID-19數據,我們需要進行一些清理才能繪制它們。
import pandas as pd
import repd.set_option('display.max_rows', 500)
pd.options.display.max_colwidth = 150# again we need to locate the .xlsx file
list_of_files = glob.glob('/Users/tsbloxsom/Documents/GitHub/Texas-census-county-data-project/Automate collecting of data notebooks/*.xlsx')
latest_file = max(list_of_files, key=os.path.getctime)
print(latest_file.split("\\")[-1])df = pd.read_excel("{}".format(latest_file),header=None)df.head()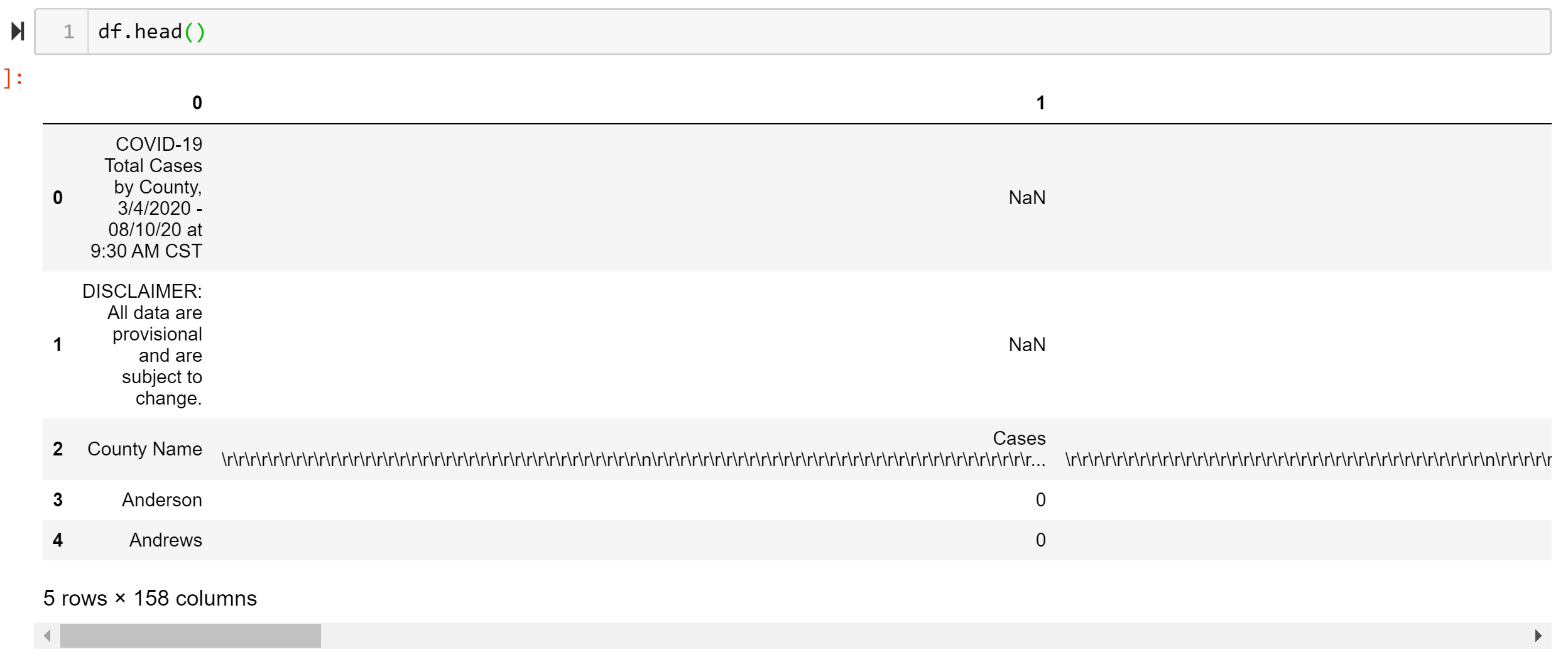
So we read the excel file and convert it to a pandas data frame (df)… and we got some cleaning to do. Lets deal with the first and last few rows of the file.
因此,我們讀取了excel文件并將其轉換為熊貓數據框(df)…,然后進行了一些清潔工作。 讓我們處理文件的前幾行和最后幾行。
# print out latest COVID data datetime and notes
date = re.findall("- [0-9]+/[0-9]+/[0-9]+ .+", df.iloc[0, 0])
print("COVID cases latest update:", date[0][2:])
print(df.iloc[1, 0])
print(str(df.iloc[262:266, 0]).lstrip().rstrip())#drop non-data rows
df2 = df.drop([0, 1, 258, 260, 261, 262, 263, 264, 265, 266, 267])First, I want to print out relevant information about the data which is in the first two rows and last few rows, then I want to drop these rows from the df.
首先,我想打印出前兩行和最后幾行中有關數據的相關信息,然后我要從df中刪除這些行。
# clean column names
df2.iloc[0,:] = df2.iloc[0,:].apply(lambda x: x.replace("\r", ""))
df2.iloc[0,:] = df2.iloc[0,:].apply(lambda x: x.replace("\n", ""))
df2.columns = df2.iloc[0]
clean_df = df2.drop(df2.index[0])
clean_df = clean_df.set_index("County Name")# convert clean_df to a .csv file
clean_df.to_csv("Texas county COVID cases data clean.csv")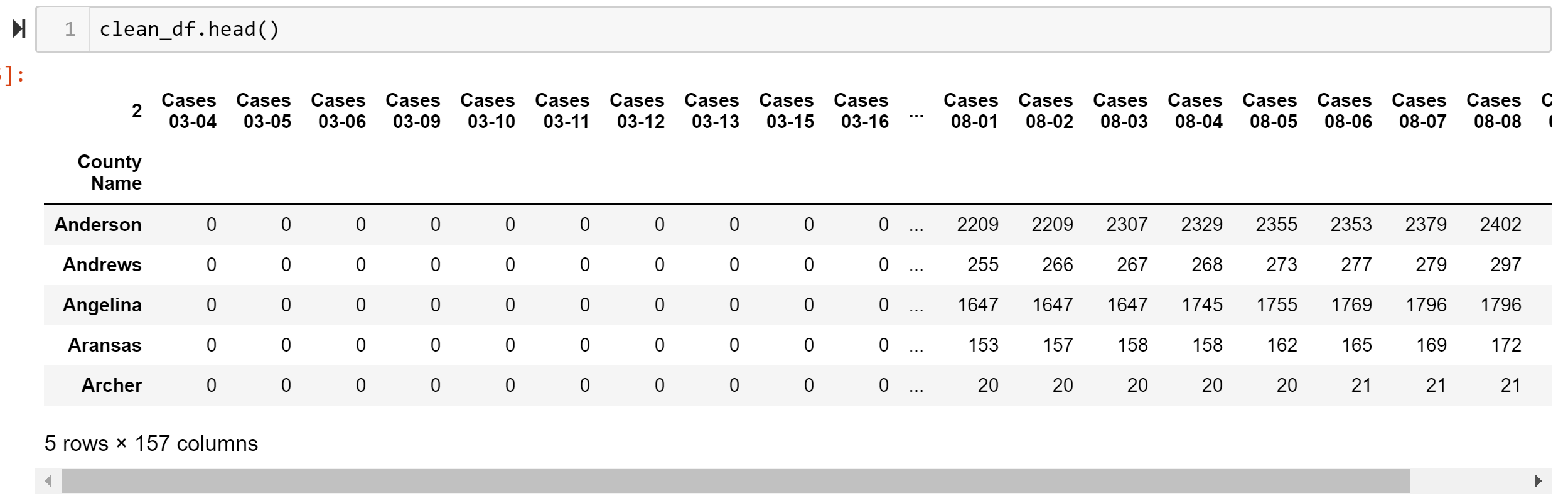
In the above code block, I clean the row for each date where many of these dates had new line, <\n>, and carriage return, <\r>, characters inside the cells. I then make the date row the column names and drop the original date row. We finally have a clean df where the rows are each county in Texas and each column represents number of cases for each date. Finally, I want to convert the df to a .csv file for the next step.
在上面的代碼塊中,我為每個日期清除了行,其中許多日期在單元格內都有換行符<\ n>和回車符<\ r>。 然后,使日期行成為列名,并刪除原始日期行。 我們終于有了一個干凈的df,其中的行是德克薩斯州的每個縣,每列代表每個日期的案件數。 最后,我想將df轉換為.csv文件,以進行下一步。
Step 4: Formatting time series data frames to be input into plotly graphs
步驟4:格式化要輸入到繪圖圖中的時間序列數據幀
import plotly.express as pxlist_of_files = glob.glob('/Users/tsbloxsom/Documents/GitHub/Texas-census-county-data-project/Automate collecting of data notebooks/*.csv')
latest_file = max(list_of_files, key=os.path.getmtime)
latest_file.split("\\")[-1]df = pd.read_csv(latest_file.split("\\")[-1])Again we are using the glob and os.path.getmtime functions to find the most recent .csv file which is our “Texas county COVID cases data clean.csv”.
再次,我們使用glob和os.path.getmtime函數來查找最新的.csv文件,這就是我們的“德克薩斯州COVID病例數據clean.csv”。
# convert df into time series where rows are each date and clean up
df_t = df.T
df_t.columns = df_t.iloc[0]
df_t = df_t.iloc[1:]
df_t = df_t.iloc[:,:-2]# next lets convert the index to a date time, must clean up dates first
def clean_index(s):
s = s.replace("*","")
s = s[-5:]
s = s + "-2020"
#print(s)
return sdf_t.index = df_t.index.map(clean_index)df_t.index = pd.to_datetime(df_t.index)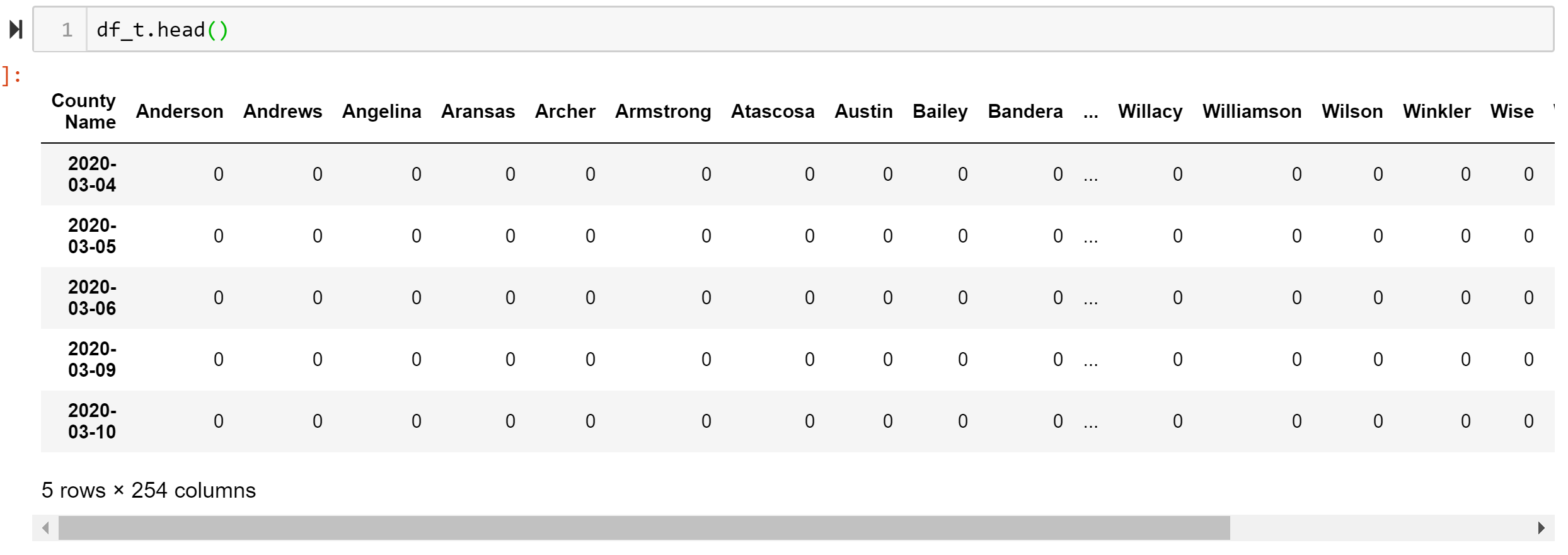
In the above code block, I am converting the data frame into a time series df where the rows are now the dates and the columns are counties. I am also dropping a couple columns that have total cases and number of counties reporting cases. Finally, I am converting the date column into a usable format that can be converted to pandas date_time object which I use the function clean_index for. But we are not done yet.
在上面的代碼塊中,我將數據幀轉換為時間序列df,其中行現在是日期,而列是縣。 我還要刪除幾列,其中包含總病例數和報告病例數的縣。 最后,我將date列轉換為可用格式,該格式可以轉換為使用函數clean_index的pandas date_time對象。 但是我們還沒有完成。
# initalize df with three columns: Date, Case Count, and County
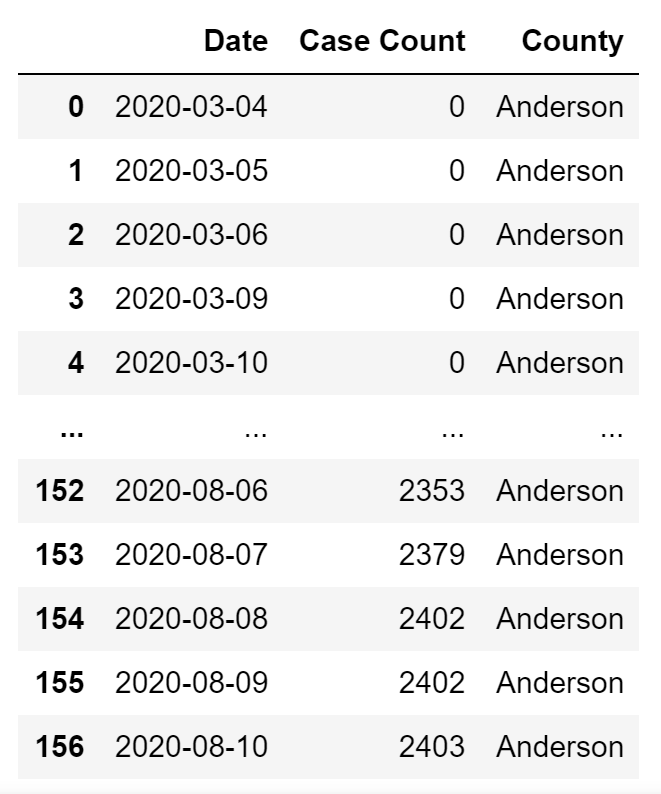
anderson = df_t.T.iloc[0,:]ts = anderson.to_frame().reset_index()ts["County"] = "Anderson"
ts = ts.rename(columns = {"Anderson": "Case Count", "index": "Date"})Our plotly function will take 3 columns as input: Date, Case Count, and County. So we need to convert our wide df into a long df essentially. To do this I first initialize a long df with three columns: a date column, the case count for Anderson County, and a county column with the name of the county in it. Which looks like this:
我們的plotly函數將以3列作為輸入:日期,病例數和縣。 因此,我們實際上需要將寬df轉換為長df。 為此,我首先用三列初始化一個長df:日期列,安德森縣的案子計數以及其中包含縣名的縣列。 看起來像這樣:
# This while loop adds all counties to the above ts so we can input it into plotly
x = 1
while x < 254:
new_ts = df_t.T.iloc[x,:]
new_ts = new_ts.to_frame().reset_index()
new_ts["County"] = new_ts.columns[1]
new_ts = new_ts.rename(columns = {new_ts.columns[1]: "Case Count", "index": "Date"})
ts = pd.concat([ts, new_ts])
x += 1#save long form df for dash app
ts.to_csv("time_series_plotly.csv")The comment of the above code block says it all but we now just loop through the entire wide df and create new_ts long df’s for each county that look like the one for Anderson. Then we concat each long df together and wallah we have ourselves the long df that can be input into plotly and later our dash app show below!
上面的代碼塊的注釋說明了所有內容,但是我們現在僅遍歷整個寬df,并為每個縣創建new_ts長df,看起來像安德森的那個。 然后,我們將每個長df連接在一起,而Wallah則擁有可以輸入到繪圖中的長df,隨后在下面的破折號應用程序中顯示!
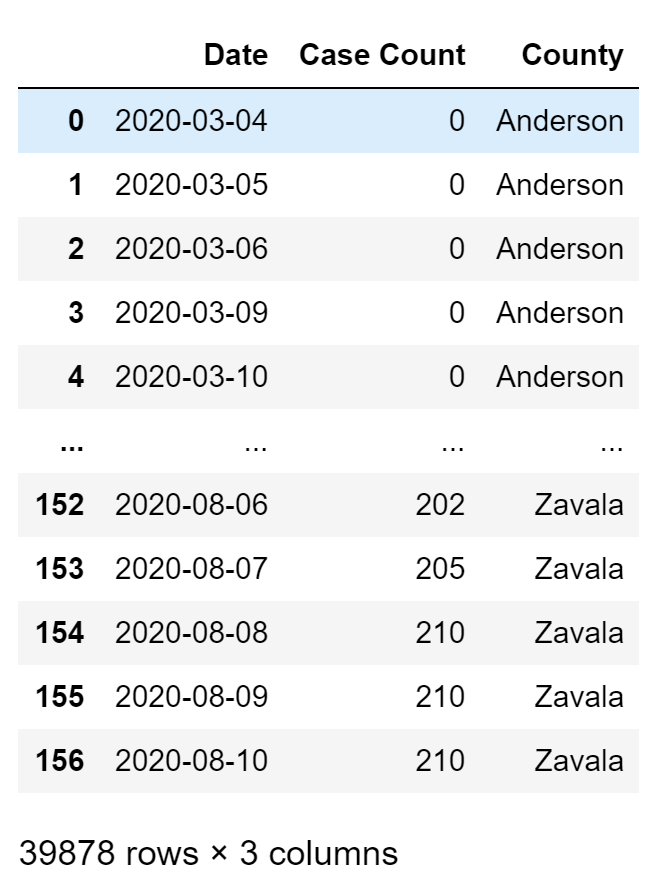
fig = px.scatter(ts, x='Date', y='Case Count', color='County')
fig.update_traces(mode='markers+lines')
#fig.update_traces(mode='lines')
fig.show()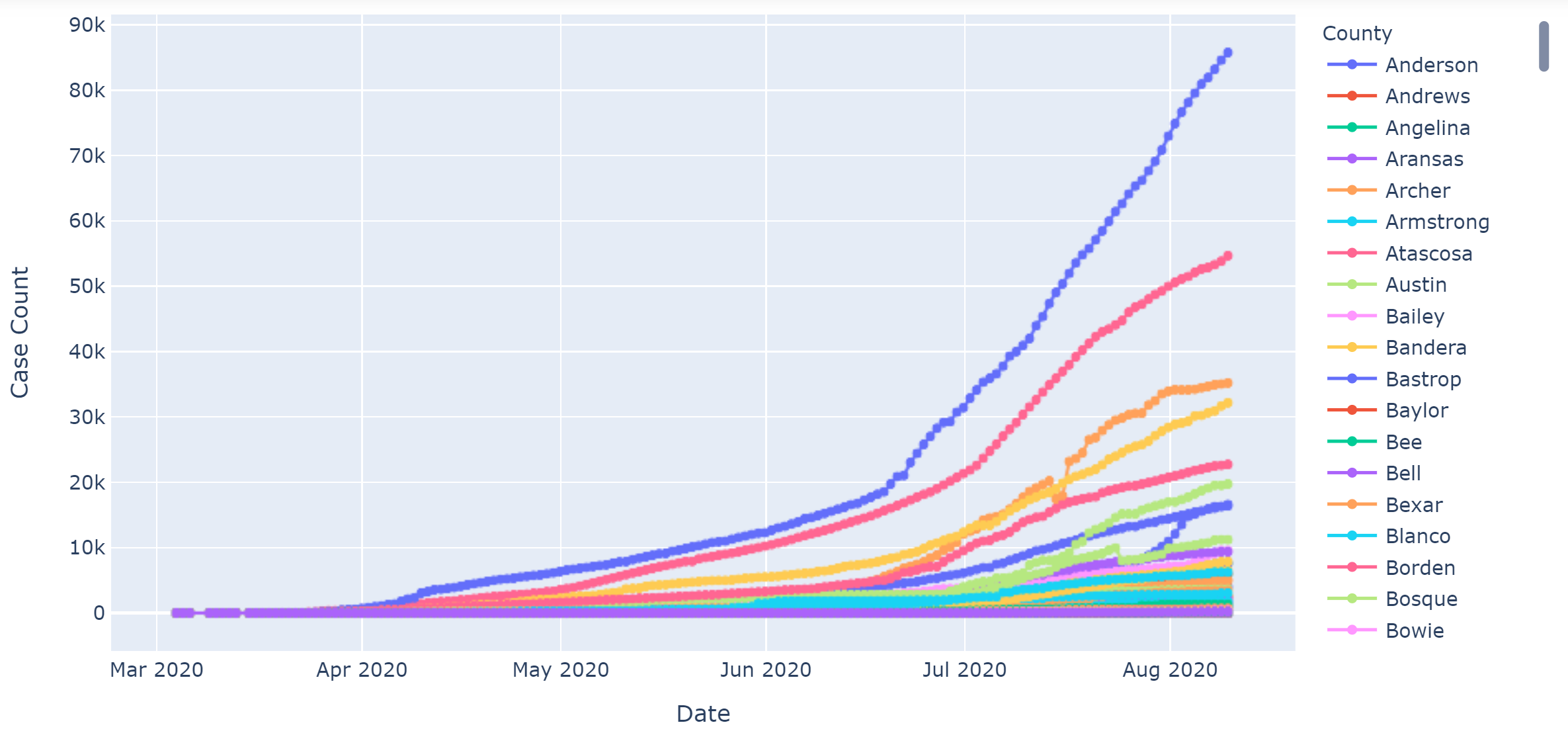
We can finally plot our data as a plotly scatter plot using just three simple lines of code! I used the markers+lines option which I think looks more pleasing and is easier to interact with than just the lines. I have fallen in love with plotly because unlike seaborn or matplotlib, the graphs are interactive and soooooo simple to code. Plotly also has outstanding documentation which can be found here.
最后,我們只需使用三行簡單的代碼就可以將數據繪制為散點圖! 我使用了markers + lines選項,我認為它比線條更令人愉悅,并且更易于交互。 我愛上了plotly,因為與seaborn或matplotlib不同,這些圖是交互式的,非常易于編碼。 Plotly也有出色的文檔,可以在這里找到。
Step 5: Creating a local web page for your dashboard using dash
步驟5:使用破折號為儀表板創建本地網頁
This is the step that might get tricky for some people if they do not have any software development experience. I didn’t have any about a month ago so I will got through this step slowly and keep it as simple as possible. First we want to create a virtual environment in the directory we have our notebooks/data. To do this we must go to our command line or Anaconda prompt and cd to that directory. Something like this:
如果某些人沒有任何軟件開發經驗,那么此步驟可能會很棘手。 大約一個月前我沒有任何信息,所以我將逐步完成此步驟,并使其盡可能簡單。 首先,我們要在我們的筆記本/數據目錄中創建一個虛擬環境。 為此,我們必須轉到命令行或Anaconda提示符,并cd到該目錄。 像這樣:
C:\Users\tsbloxsom>cd C:\Users\tsbloxsom\Documents\GitHub\Texas-census-county-data-project\Automate collecting of data notebooksThen we create the virtual environment:
然后我們創建虛擬環境:
python3 -m venv venvThen we activate the virtual environment:
然后,我們激活虛擬環境:
venv\Scripts\activateLets get to the dash program now. Here is a link for anyone new to dash. Dash is made by the people from plotly so you get great documentation and great products. I learned how to make this app for the time series dashboard in under 2 hours, not trying to brag, its just that simple. Below is the code for the app. I used a combination of dash’s basic app templates found in this tutorial on their website. So open up your favorite code editor like Spyder and save the below code as app.py in the same directory as your new venv folder and .csv file(s).
現在讓我們進入破折號程序。 這是任何新手的鏈接 。 Dash是由人們精心策劃的,因此您可以獲得出色的文檔和出色的產品。 我學會了如何在2小時內使該應用程序用于時間序列儀表板,而不是吹牛,它就這么簡單。 以下是該應用程序的代碼。 我在其網站上使用了本指南中的dash的基本應用程序模板的組合。 因此,打開您喜歡的代碼編輯器(如Spyder),并將以下代碼另存為app.py,與新的venv文件夾和.csv文件位于同一目錄中。
import dash
import dash_core_components as dcc
import dash_html_components as html
import plotly.express as px
import pandas as pdexternal_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css']app = dash.Dash(__name__, external_stylesheets=external_stylesheets)colors = {
'background': '#F0F8FF',
'text': '#00008B'
}# assume you have a "long-form" data frame
# see https://plotly.com/python/px-arguments/ for more options
df = pd.read_csv("time_series_plotly.csv")fig = px.scatter(df, x='Date', y='Case Count', color='County')fig.update_layout(
plot_bgcolor=colors['background'],
paper_bgcolor=colors['background'],
font_color=colors['text']
)markdown_text = '''
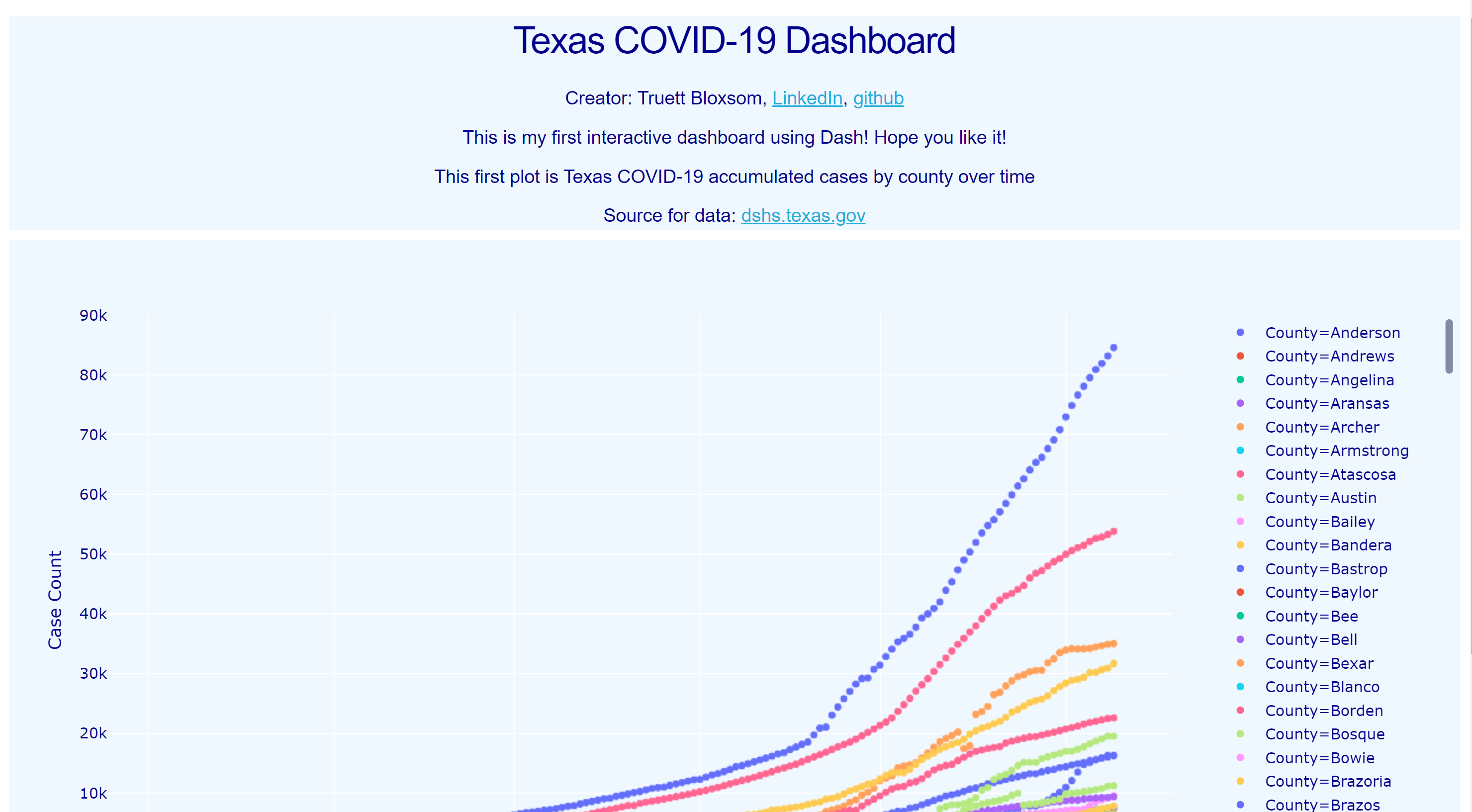
### Texas COVID-19 DashboardCreator: Truett Bloxsom, [LinkedIn](https://www.linkedin.com/in/truett-bloxsom/), [github](https://github.com/tsbloxsom)This is my first interactive dashboard using Dash! Hope you like it!This first plot is Texas COVID-19 accumulated cases by county over timeSource for data: [dshs.texas.gov](https://www.dshs.texas.gov/coronavirus/additionaldata/)'''app.layout = html.Div([
dcc.Markdown(children=markdown_text,
style={
'backgroundColor': colors['background'],
'textAlign': 'center',
'color': colors['text']
}),
dcc.Graph(
id='example-graph',
figure=fig
)
])if __name__ == '__main__':
app.run_server(debug=True)Now go back to the activated environment and download dash, plotly, and pandas:
現在回到激活的環境并下載破折號,密謀和熊貓:
pip install <package_name>Then you can run your app by running this command:
然后,您可以通過運行以下命令來運行您的應用程序:
python3 app.pyIt should look something like this:
它看起來應該像這樣:
Now just copy the http link and paste it into chrome and boom! It should look like this:
現在,只需復制http鏈接并將其粘貼到chrome和boom中即可! 它看起來應該像這樣:
I went a step further and followed this tutorial by Elsa Scola on how to deploy your dash app for free. If you just want to play around with my interactive dashboard you can here!
我走得更遠,并跟隨Elsa Scola的本教程講解如何免費部署儀表板應用程序。 如果您只想使用我的交互式儀表板,可以在這里 !
Thanks for following my tutorial and feel free to connect with me on linkedin. I am always trying to get feedback and strengthen my data science skills, so if there was anything I could improve coding wise or explain something in greater detail please let me know in the comments.
感謝您關注我的教程,并隨時在linkedin上與我聯系。 我一直在努力獲得反饋,并加強我的數據科學技能,因此,如果有什么我可以提高編碼水平或更詳細地解釋某些內容的話,請在評論中告訴我。
翻譯自: https://towardsdatascience.com/creating-and-automating-an-interactive-dashboard-using-python-5d9dfa170206
python交互式和文件式
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389215.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389215.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389215.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

不可不說的Java“鎖”事

數據可視化 信息可視化_可視化數據以幫助清理數據
)
VS2005 ASP.NET2.0安裝項目的制作(包括數據庫創建、站點創建、IIS屬性修改、Web.Config文件修改)

docker的基本命令

seaborn添加數據標簽_常見Seaborn圖的數據標簽快速指南

使用python pandas dataframe學習數據分析

實現TcpIp簡單傳送

SQLServer之函數簡介

無向圖g的鄰接矩陣一定是_矩陣是圖

移動pc常用Meta標簽

前端繪制繪制圖表_繪制我的文學風景


android 字符串特殊字符轉義

如何描繪一個vue的項目_描繪了一個被忽視的幽默來源

數據存儲加密和傳輸加密_將時間存儲網絡應用于加密預測


熊貓分發_熊貓新手:第一部分

多線程 進度條 C# .net

window 10 多版本激活工具
