熊貓分發
For those just starting out in data science, the Python programming language is a pre-requisite to learning data science so if you aren’t familiar with Python go make yourself familiar and then come back here to start on Pandas.
對于剛接觸數據科學的人來說,Python編程語言是學習數據科學的先決條件,因此,如果您不熟悉Python,請先熟悉一下,然后再回到這里開始學習Pandas。
You can start learning Python with a series of articles I just started called Minimal Python Required for Data Science.
您可以從我剛剛開始的一系列文章開始學習Python,這些文章稱為“數據科學所需的最小Python” 。
One of the most important tools in the toolbox when it comes to data science is pandas which is a data analytics library for Python developed by Wes McKinney during his tenure at a hedge fund.
關于數據科學,工具箱中最重要的工具之一是pandas,這是Wes McKinney在對沖基金任職期間開發的Python數據分析庫。
For this entire series of articles, we’re going to be using Anaconda which is a fancy Python package manager geared for data science and machine learning. If you aren’t familiar with what I just talked about go ahead and check out this video which will teach you about Anaconda and Jupyter Notebook which is central to data science work.
在整個系列文章中,我們將使用Anaconda ,這是一款專為數據科學和機器學習而設計的Python軟件包管理器。 如果您不熟悉我剛才所說的內容,請觀看此視頻,該視頻將教您有關Anaconda和Jupyter Notebook的知識,這對數據科學工作至關重要。
You can activate your conda environment (virtual environment) with:
您可以使用以下方法激活conda環境( 虛擬環境 ):
$ conda activate [name of environment]# my environment is named `datascience` so$ conda activate datascienceOnce you activate your conda virtual environment you should see this on your Terminal:
激活conda虛擬環境后,您應該在終端上看到以下內容:
(datascience)$Assuming you have miniconda or anaconda installed on your system you can easily install pandas with:
假設您的系統上安裝了miniconda或anaconda,則可以使用以下方法輕松安裝熊貓:
$ conda install pandasWe’re also going to be using Jupyter Notebook to do our coding so go ahead and
我們還將使用Jupyter Notebook進行編碼,因此繼續
$ And startup your Jupyter Notebook with:
然后使用以下命令啟動Jupyter Notebook:
$ jupyter notebook熊貓是將所有元素粘合在一起的粘合劑 (Pandas is the glue that holds it all together)

Pandas gets more important as we venture higher up the hierarchy of data science into the fields of machine learning as it allows data to be “cleaned” and “wrangled” before getting fed to algorithms like Random Forest and Neural Networks. If ML algorithms are Doc, then pandas is Marty.
隨著我們冒險將數據科學的層次結構帶入機器學習領域,Pandas變得越來越重要,因為它允許在將數據饋入隨機森林和神經網絡等算法之前先對其進行“清理”和“整理”。 如果ML算法是Doc,則熊貓是Marty。
導游巴士之旅 (A Guided Bus Tour)

One of my favorite places to visit even since childhood is the San Diego Zoo. And one thing I always do is to take the guided bus tour while drinking a Blue Moon.
即使從小我最喜歡去的地方之一是圣地亞哥動物園。 我一直要做的一件事就是在喝著“藍月亮”的同時進行有導游的游覽。
We’re going to do something similar in that I’m going to give a brief tour of just some of the things you can do with Pandas. You’re on your own with the Blue Moon.
我們將做類似的事情,簡要介紹一下您可以使用Pandas進行的一些操作。 藍月亮讓你自己。
Both the data and the inspiration for this medium series come from Ted Petrou’s excellent courses on Dunder Data.
該媒體系列的數據和靈感均來自Ted Petrou的Dunder Data精品課程。
Pandas essentially deals with tabular data: rows and columns. In this respect it’s very much like an Excel spreadsheet.
熊貓本質上處理表格數據:行和列。 在這方面,它非常類似于Excel電子表格。
The two primary objects you’ll interface with in pandas is the Series and the DataFrame. A DataFrame is two-dimensional data complete with rows and columns.
您將在熊貓中使用的兩個主要對象是Series和DataFrame 。 DataFrame是具有行和列的二維數據。
It’s okay if you don’t know what the below code does we will go over it later in detail. The data that we use here concerns bicycle riders in the city of Chicago, Illnoise.
沒關系,如果您不知道下面的代碼是什么,我們稍后將詳細介紹它。 我們在此使用的數據與伊利諾伊斯州芝加哥市的自行車騎手有關。

Series is one-dimensional data or a single column of data with respect to a DataFrame:
系列是相對于DataFrame的一維數據或單列數據:
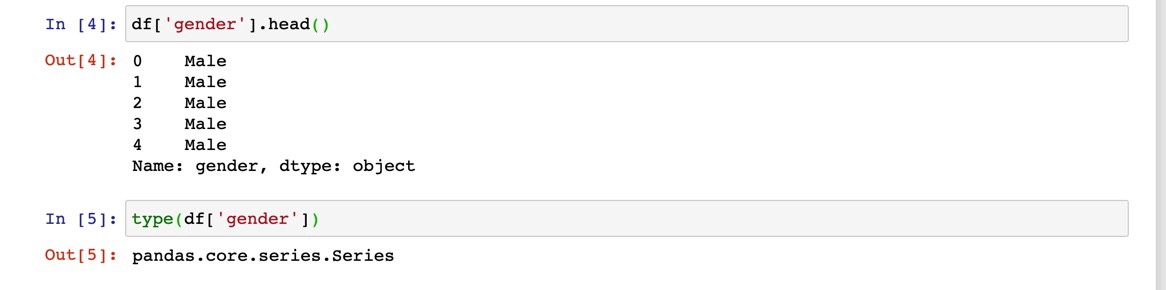
As shown above one of the highlights of pandas is that it allows data to be loaded into a Jupyter Notebook session from whatever the source file is whether it’s a CSV (comma delimited), XLSX(Excel), SQL, or JSON.
如上所示,pandas的亮點之一是它允許將數據從任何源文件加載到Jupyter Notebook會話中,無論源文件是CSV(逗號分隔),XLSX(Excel),SQL還是JSON。
One of the first things we always do is take a peek at the dataset we’re studying by using the head method. By default head will present the first five rows of the data. We can pass an integer to control how many rows we want to see:
我們經常要做的第一件事就是使用head方法窺視我們正在研究的數據集。 默認情況下, head將顯示數據的前五行。 我們可以傳遞一個整數來控制我們要查看的行數:
df.head(7)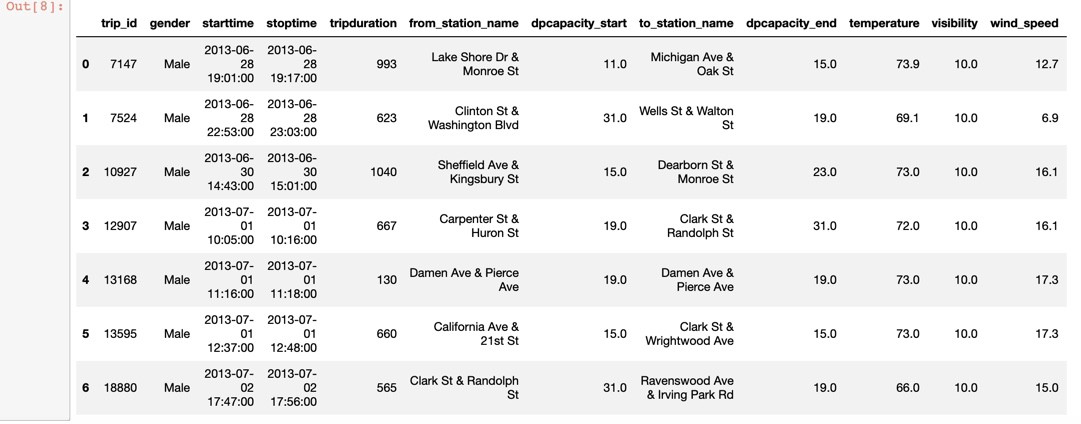
If we want to see the last five rows:
如果要查看最后五行:
df.tail()讀入數據 (Read In Data)
We use the read_csv function to load CSV formatted data.
我們使用read_csv函數加載CSV格式的數據。
We pass the path to the file containing our data as a string to the read_csv method of pandas. In my case, I’m using the url of my GitHub Repo which holds all the data that I will be using. I highly recommend reading the documentation regarding pandas read_csv function as it’s one of the most important and dynamic functions within the whole library.
我們將包含數據的文件的路徑作為字符串傳遞給read_csv方法。 就我而言,我使用的是GitHub Repo的網址,該網址包含我將要使用的所有數據。 我強烈建議閱讀有關pandas read_csv函數的文檔 ,因為它是整個庫中最重要且最動態的函數之一。
篩選資料 (Filter Data)
We can filter rows of a pandas DataFrame with conditional logic. For programmers familiar with SQL this would be like using the WHERE clause.
我們可以使用條件邏輯過濾熊貓DataFrame的行。 對于熟悉SQL的程序員,這就像使用WHERE子句。
To retrieve only the rows where wind_speed is greater than 42.0 we can do this:
要僅檢索wind_speed大于42.0的行,我們可以這樣做:
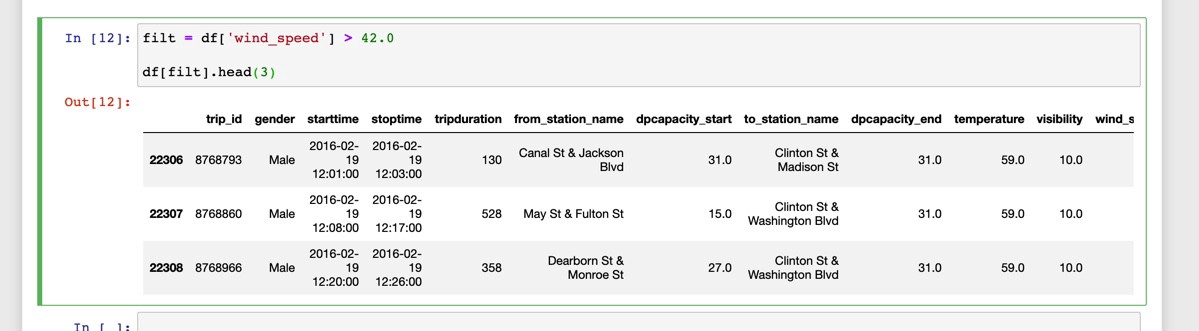
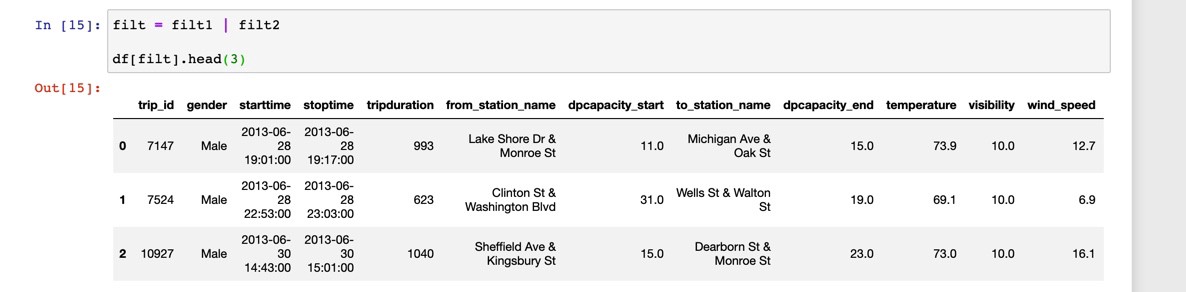
We can filter for more than one condition like this:
我們可以過濾多個條件,例如:

Here we filter for the condition where the wind speed is greater than 42.0 (I’m assuming miles per hour) and where the gender of the bicyclist is female. As we can see it returns an empty dataset.
在這里,我們篩選出風速大于42.0(我假設每小時英里)并且騎自行車的性別是女性的情況。 如我們所見,它返回一個空的數據集。
We can verify that we’re not committing some kind of error that results in an empty query by trying out the same multiple filters but for male riders.
我們可以通過嘗試相同的多個過濾器(但針對男性騎手)來驗證是否未犯導致空查詢的錯誤。
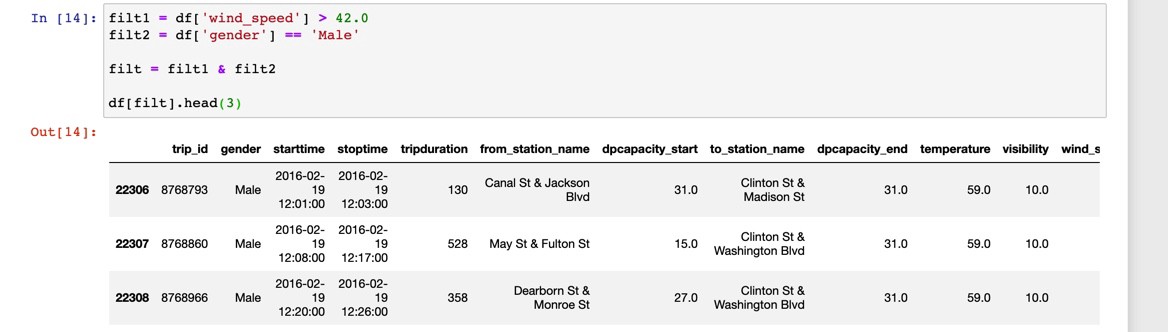
We can also do something like this:
我們還可以這樣做:
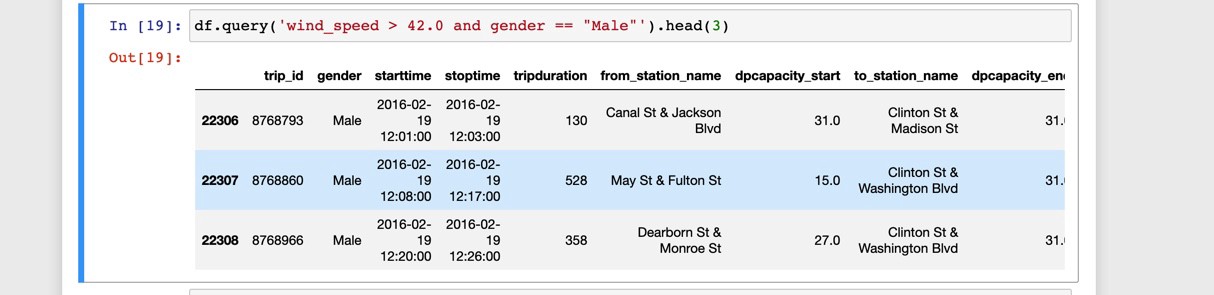
查詢:過濾的一種更簡單的選擇 (Query: A Simpler Alternative to Filtering)
Pandas also has a query method which is somewhat limited in its abilities, but allows for simpler and more readable code. Just as before, programmers familiar with SQL should feel comfortable with this method.
熊貓還具有一種query方法,該query方法的功能受到一定程度的限制,但允許使用更簡單和更具可讀性的代碼。 和以前一樣,熟悉SQL的程序員應該對此方法感到滿意。
未完待續 (To Be Continued)
Pandas for Newbies is meant to be a Medium series so watch for the next upcoming tutorial Pandas for Newbies: An Introduction Part II which will be posted soon.
《 Pandas for Newbies》是一個中級系列,因此請關注下一個即將發布的教程《 Pandas for Newbies:Introduction Part II》 。
我做的事 (What I do)
I help people find Mentors, Code in Python, and Write about Life. If you’re thinking about switching careers into the tech industry or just want to talk you can sign up for my Slack Channel via VegasBlu.
我幫助人們找到導師,Python代碼并撰寫關于生活的文章。 如果您正在考慮將職業轉向科技行業,或者只是想談談,可以通過VegasBlu注冊我的Slack頻道。
翻譯自: https://towardsdatascience.com/pandas-for-newbies-an-introduction-part-i-8246f14efcca
熊貓分發
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389198.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389198.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389198.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

多線程 進度條 C# .net

window 10 多版本激活工具

android 動畫總結筆記 一

《Linux內核原理與分析》第六周作業

使用C#調用外部Ping命令獲取網絡連接情況

Codeforces Round 493

android動畫筆記二

回歸分析檢驗_回歸分析

是什么樣的騷操作讓應用上線節省90%的時間


Ubuntu 18.04 下如何配置mysql 及 配置遠程連接

數據科學與大數據技術的案例_主數據科學案例研究,招聘經理的觀點

導致View樹遍歷的時機

什么是Hyperledger?Linux如何圍繞英特爾的區塊鏈項目構建開放平臺?

隊列的鏈式存儲結構及其實現_了解隊列數據結構及其實現


cad2016珊瑚_預測有馬的硬珊瑚覆蓋率
)
EChart中使用地圖方式總結(轉載)

android mvp模式
)