軟件工程方法學要素含義
According to Wikipedia, feature engineering refers to the process of using domain knowledge to extract features from raw data via data mining techniques. These features can then be used to improve the performance of machine learning algorithms.
一個 ccording百川,有特色的工程是指使用領域知識通過數據挖掘技術,從原始數據提取特征的過程。 然后,可以使用這些功能來提高機器學習算法的性能。
Feature engineering does not necessarily have to be fancy. One simple, yet prevalent, use case of feature engineering is in time-series data. The importance of feature engineering in this realm is due to the fact that (raw) time-series data usually only contains one single column to represent the time attribute, namely date-time (or timestamp).
功能設計不一定被看中。 特征工程的一種簡單但普遍的用例是時序數據。 在這一領域中,要素工程的重要性是由于以下事實:(原始)時間序列數據通常僅包含一個列來表示時間屬性,即日期時間(或時間戳記)。
Regarding this date-time data, feature engineering can be seen as extracting useful information from such data as standalone (distinct) features. For example, from a date-time data of “2020–07–01 10:21:05”, we might want to extract the following features from it:
關于此日期時間數據, 可以將特征工程視為從諸如獨立(獨特)特征之類的數據中提取有用的信息 。 例如,從日期時間數據“ 2020-07-01 01 10:21:05”,我們可能要從中提取以下功能:
- Month: 7 月:7
- Day of month: 1 一個月中的某天:1
- Day name: Wednesday (2020–07–01 was Wednesday) 日期名稱:星期三(2020-07-01是星期三)
- Hour: 10 時間:10
Extracting such kinds of features from date-time data is precisely the objective of the current article. Afterwards, we will incorporate our engineered features as predictors of a gradient boosting regression model. Specifically, we will forecast metro interstate traffic volume.
從日期時間數據中提取此類特征正是本文的目的。 此后,我們將把我們的工程功能納入梯度提升回歸模型的預測變量中。 具體來說,我們將預測地鐵州際交通量。
快速總結 (Quick summary)
This article will cover the following.
本文將介紹以下內容。
A step-by-step guide to extract the below features from a date-time column.
從日期時間列中提取以下功能的分步指南。
- Month 月
- Day of month 一個月中的某天
- Day name 日名
- Hour 小時
- Daypart (morning, afternoon, etc) 時段(早上,下午等)
- Weekend flag (1 if weekend, else 0) 周末標志(如果周末則為1,否則為0)
How to incorporate those features in a Gradient Boosting regression model to forecast metro interstate traffic volume.
如何將這些功能整合到Gradient Boosting回歸模型中以預測地鐵州際交通量。
數據 (The data)
Throughout the article, we use Metro Interstate Traffic Volume Data Set, which can be found in the UCI Machine Learning Repository here.
在整篇文章中,我們使用Metro Interstate Traffic Volume Data Set,該數據集可在此處的UCI機器學習存儲庫中找到 。
Citing its abstract, the data is about hourly Minneapolis-St Paul, MN traffic volume for westbound I-94, which includes weather and holiday features from 2012–2018. This 48204 rows data contains the following attributes.
引用其摘要,該數據大約是明尼阿波利斯-圣保羅,明尼蘇達州I-94西行的每小時交通量,其中包括2012-2018年的天氣和假日特征。 該48204行數據包含以下屬性。
holiday: Categorical US National holidays plus regional holiday, Minnesota State Fairholiday:美國國定假日加區域性假日,明尼蘇達州博覽會temp: Numeric Average temp in kelvintemp:數值平均開氏溫度rain_1h: Numeric Amount in mm of rain that occurred in the hourrain_1h:小時內發生的以毫米為單位的數值雨量snow_1h: Numeric Amount in mm of snow that occurred in the hoursnow_1h:每小時發生的雪的數值(以毫米為單位)clouds_all: Numeric Percentage of cloud coverclouds_all:云量的數值百分比weather_main: Categorical Short textual description of the current weatherweather_main:類別當前天氣的簡短文字說明weather_description: Categorical Longer textual description of the current weatherweather_description:類別當前天氣的較長文字描述date_time: DateTime Hour of the data collected in local CST timedate_time:DateTime在本地CST時間中收集的數據的小時數traffic_volume:Numeric Hourly I-94 ATR 301 reported westbound traffic volume (the target)traffic_volume:每小時I-94 ATR 301數字報告的西行流量(目標)
Let’s load the data.
讓我們加載數據。
# import libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# load the data
raw = pd.read_csv('Metro_Interstate_Traffic_Volume.csv')# display first five rows
raw.head()# display details for each column
raw.info()
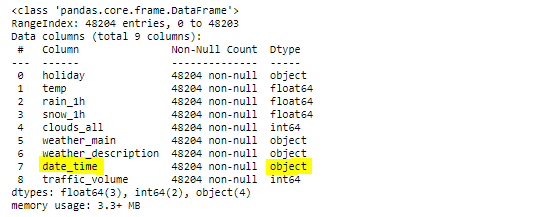
From the output of the info method in the above, we know the date_time column is still in object type. So we need to convert it to datetime type.
從上面的info方法的輸出中,我們知道date_time列仍然是object類型。 因此,我們需要將其轉換為datetime類型。
# convert date_time column to datetime type
raw.date_time = pd.to_datetime(raw.date_time)開始特征工程 (Start feature engineering)
From the output of info method in the above, we know there are categorical features other than the date_time column. But due to the main topic of this article, we will focus on feature engineering our date_time column.
從上面的info方法的輸出中,我們知道date_time列以外還有其他分類功能。 但是由于本文的主題,我們將在date_time列上著重進行功能設計。
Month
月
It turns out that Pandas has many handy methods to work with datetime typed data. To extract time/date components, all we need to do is calling pd.Series.dt attributes family. pd.Series.dt.month is the one we need to extract the month component. This will yield a Series of the digit of the month component (e.g. 1 for January, 10 for October) in int64 format.
事實證明,Pandas有許多方便的方法可以處理datetime類型的數據。 要提取時間/日期成分,我們需要做的就是調用pd.Series.dt屬性族。 pd.Series.dt.month是我們提取月份組件所需要的。 這將產生int64格式的系列月份數字部分(例如1表示1月,10表示10月)。
# extract month feature
months = raw.date_time.dt.monthDay of month
一個月中的某天
Quite similar as before, we just need to call pd.Series.dt.day. For example, a date-time of 2012–10–27 09:00:00 would be resulted in 27 using this attribute.
與以前非常相似,我們只需要調用pd.Series.dt.day 。 例如,使用該屬性將導致2012年10月27日09:00:00的日期時間為27。
# extract day of month feature
day_of_months = raw.date_time.dt.dayHour
小時
This one is also trivial. The attribute pd.Series.dt.hour will result in a Series of hour digits, ranging from 0 to 23.
這也是微不足道的。 屬性pd.Series.dt.hour將產生一系列小時數字,范圍從0到23。
# extract hour feature
hours = raw.date_time.dt.hourDay name
日名
This one is getting interesting. Our goal is to extract the day name for each date-time in the raw.date_time Series. It consists of two steps. First is to extract the day name literal using pd.Series.dt.day_name() method. Afterwards, we need to one-hot encode the results from the first step using pd.get_dummies() method.
這變得越來越有趣。 我們的目標是為raw.date_time系列中的每個日期時間提取日期名稱。 它包括兩個步驟。 首先是使用pd.Series.dt.day_name()方法提取日期名稱文字。 然后,我們需要使用pd.get_dummies()方法對第一步的結果進行一次熱編碼。
# first: extract the day name literal
to_one_hot = raw.date_time.dt.day_name()# second: one hot encode to 7 columns
days = pd.get_dummies(to_one_hot)#display data
days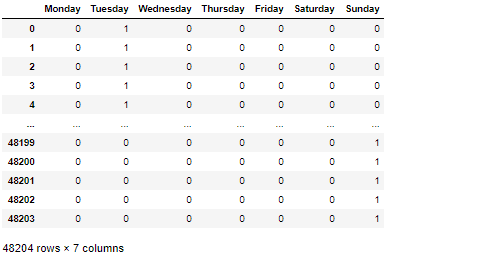
Daypart
時段
In this part, we will create a grouping based on the hour digits. On a high level, we want to have six groups representing each daypart. They are Dawn (02.00 — 05.59), Morning (06.00 —09.59), Noon (10.00–13.59), Afternoon (14.00–17.59), Evening (18.00–21.59), and Midnight (22.00–01.59 on Day+1).
在這一部分中,我們將基于小時數字創建分組。 總體而言,我們希望每個時段有六個小組代表。 它們是黎明(02.00 — 05.59),早晨(06.00 —09.59),中午(10.00–13.59),下午(14.00–17.59),晚上(18.00–21.59)和午夜(第1天的22.00–01.59)。
To this end, we create an identifying function that we later use to feed an apply method of a Series. Afterwards, we perform one-hot encoding on the resulted dayparts.
為此,我們創建了一個標識函數,以后將其apply提供Series的apply方法。 之后,我們對結果時段進行一次熱編碼。
# daypart function
def daypart(hour):
if hour in [2,3,4,5]:
return "dawn"
elif hour in [6,7,8,9]:
return "morning"
elif hour in [10,11,12,13]:
return "noon"
elif hour in [14,15,16,17]:
return "afternoon"
elif hour in [18,19,20,21]:
return "evening"
else: return "midnight"# utilize it along with apply method
raw_dayparts = hours.apply(daypart)# one hot encoding
dayparts = pd.get_dummies(raw_dayparts)# re-arrange columns for convenience
dayparts = dayparts[['dawn','morning','noon','afternoon','evening','midnight']]#display data
dayparts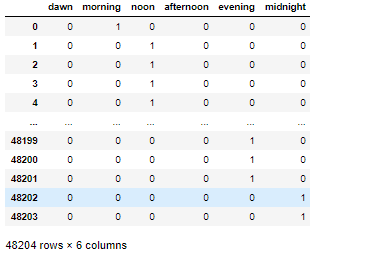
Weekend flag
周末標志
The final feature we engineer from the date_time column is is_weekend. This column indicates whether the given date-time is in the weekend (Saturday or Sunday) or not. To proceed with this objective, we will make use of our previous pd.Series.dt.day_name() method and apply a simple lambda function on top of it.
我們在date_time列中設計的最終功能是is_weekend 。 此列指示給定的日期時間是否在周末(星期六或星期日)。 為了實現此目標,我們將使用之前的pd.Series.dt.day_name()方法,并在其之上應用一個簡單的lambda函數。
# is_weekend flag
day_names = raw.date_time.dt.day_name()
is_weekend = day_names.apply(lambda x : 1 if x in ['Saturday','Sunday'] else 0)Holiday flag & weather
假日標志和天氣
Lucky on us, the data also contains public holiday information. The information is granular since it mentions the name of each public holiday. Nevertheless, I assumed that there is no significant gain for encoding each of these holidays. Therefore, let’s just create a binary feature indicating whether or not the corresponding date is a holiday.
幸運的是,該數據還包含公共假期信息。 該信息非常詳盡,因為它提到了每個公共假期的名稱。 不過,我假設對這些假期中的每一個進行編碼都沒有明顯的好處。 因此,讓我們創建一個二進制功能,指示相應的日期是否是假期。
# is_holiday flag
is_holiday = raw.holiday.apply(lambda x : 0 if x == "None" else 1)The last categorical feature we need to take care of is the weather column (my assumption strikes again here, I do not include weather_description feature). As you might guess, we just one-hot encode the feature as follows.
我們需要處理的最后一個分類功能是weather列(我的假設再次出現在這里,我不包括weather_description功能)。 您可能會猜到,我們僅對該功能進行一次熱編碼,如下所示。
# one-hot encode weather
weathers = pd.get_dummies(raw.weather_main)#display data
weathers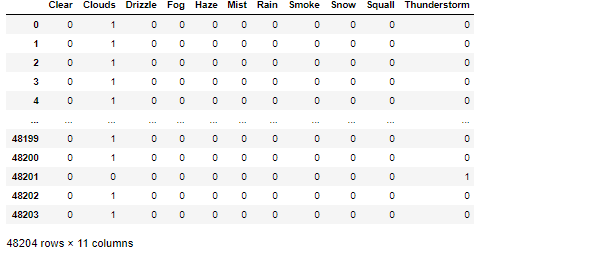
The final data
最終數據
Hurray! We finally have our final — ready-to-train — data!
歡呼! 我們終于有了最終的準備好訓練的數據!
# features table
features = pd.DataFrame({
'temp' : raw.temp,
'rain_1h' : raw.rain_1h,
'snow_1h' : raw.snow_1h,
'clouds_all' : raw.clouds_all,
'month' : months,
'day_of_month' : day_of_months,
'hour' : hours,
'is_holiday' : is_holiday,
'is_weekend' : is_weekend
})features = pd.concat([features, days, dayparts, weathers], axis = 1)# target column
target = raw.traffic_volumeBefore we feed the data to our model, we need to split the data (training and test data).
在將數據提供給模型之前,我們需要拆分數據(訓練和測試數據)。
#split data into training and test data
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.1, shuffle = False)造型零件 (Modelling parts)
Now we are ready to build our model to forecast metro interstate traffic volume. In this work, we will use the Gradient Boosting regression model.
現在,我們準備建立模型來預測地鐵州際交通量。 在這項工作中,我們將使用Gradient Boosting回歸模型。
The details of the model are beyond the scope of this article but on a high level, the gradient boosting model belongs to ensemble model family which employs gradient descent algorithm to minimize errors in sequential (additive) weak learner models (decision trees).
該模型的詳細信息不在本文討論范圍之內,但從較高的角度來看,梯度提升模型屬于集成模型家族,該家族采用梯度下降算法來最大程度地減少順序(加性)弱學習者模型(決策樹)中的錯誤。
Model training
模型訓練
Let’s instantiate and train the model on the training data!
讓我們在訓練數據上實例化并訓練模型!
from sklearn import datasets, ensemble# define the model parameters
params = {'n_estimators': 500,
'max_depth': 4,
'min_samples_split': 5,
'learning_rate': 0.01,
'loss': 'ls'}# instantiate and train the model
gb_reg = ensemble.GradientBoostingRegressor(**params)
gb_reg.fit(X_train, y_train)Just wait a little while until the training converged.
稍等片刻,直到培訓結束。
Model evaluation
模型評估
To evaluate the model, we use two metrics: MAPE (mean absolute percentage error) and R2 score. We will compute these metrics on the test data.
為了評估模型,我們使用兩個指標:MAPE(平均絕對百分比誤差)和R2得分。 我們將在測試數據上計算這些指標。
# define MAPE function
def mape(true, predicted):
inside_sum = np.abs(predicted - true) / true
return round(100 * np.sum(inside_sum ) / inside_sum.size,2)# import r2 score
from sklearn.metrics import r2_score# evaluate the metrics
y_true = y_test
y_pred = gb_reg.predict(X_test)#print(f"GB model MSE is {round(mean_squared_error(y_true, y_pred),2)}")
print(f"GB model MAPE is {mape(y_true, y_pred)} %")
print(f"GB model R2 is {round(r2_score(y_true, y_pred)* 100 , 2)} %")
We can see that our model is quite decent in performance. Our MAPE is less than 15%, while R2 score is a little over 95%.
我們可以看到我們的模型在性能上相當不錯。 我們的MAPE低于15%,而R2得分略高于95%。
Graphical results
圖形結果
To comprehend our model performance visually, let’s have some plot!
為了直觀地了解我們的模型性能,讓我們來做些圖!
Due to the length of our test data (4820 data points), we just plot the actual vs model-predicted values on the last 100 data points. Moreover, we also include another model (called gb_reg_lite in the plotting code below) which does not incorporate date-time engineered features as its predictors (it only contains non-date-time column as features, including temp, weather, etc).
由于測試數據的長度(4820個數據點),我們僅在最后100個數據點上繪制實際值與模型預測值之間的關系。 此外,我們還包括另一個模型(在下面的繪圖代碼中稱為gb_reg_lite ,該模型未將日期時間工程特征作為其預測變量(它僅包含非日期時間列作為特征,包括temp , weather等)。
fig, ax = plt.subplots(figsize = (12,6))index_ordered = raw.date_time.astype('str').tolist()[-len(X_test):][-100:]ax.set_xlabel('Date')
ax.set_ylabel('Traffic Volume') # the actual values
ax.plot(index_ordered, y_test[-100:].to_numpy(), color='k', ls='-', label = 'actual')# predictions of model with engineered features
ax.plot(index_ordered, gb_reg.predict(X_test)[-100:], color='b', ls='--', label = 'predicted; with date-time features')# predictions of model without engineered features
ax.plot(index_ordered, gb_reg_lite.predict(X_test_lite)[-100:], color='r', ls='--', label = 'predicted; w/o date-time features')every_nth = 5
for n, label in enumerate(ax.xaxis.get_ticklabels()):
if n % every_nth != 0:
label.set_visible(False)ax.tick_params(axis='x', labelrotation= 90)plt.legend()
plt.title('Actual vs predicted on the last 100 data points')
plt.draw()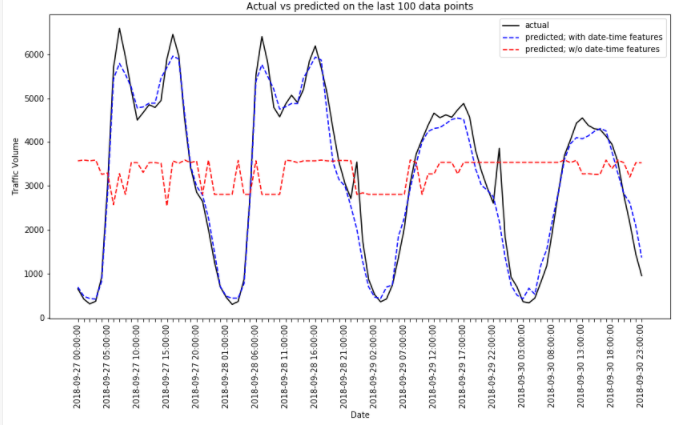
The figure supports our previous findings on good evaluation metrics the model attained, as the blue dashed line approximates the with the black solid line closely. That is, our gradient boosting model can forecast the metro traffic decently.
該圖支持我們先前關于模型獲得的良好評估指標的發現,因為藍色虛線與黑色實線非常接近。 也就是說,我們的梯度提升模型可以合理地預測地鐵流量。
Meanwhile, we see that the model which does not use the date-time engineered features falls apart in performance (red dashed line). Why this occurs? Because the target (transportation traffic) would indeed depend on the features we just created. Transportation traffic tends to lower in weekend days, but spikes during rush hours. Thus, we would miss these sound predictors if we do not perform feature engineering on the date-time column!
同時,我們看到不使用日期時間工程特征的模型在性能上有所區別(紅色虛線)。 為什么會這樣? 因為目標(運輸流量)確實取決于我們剛剛創建的功能。 周末交通運輸量趨于下降,但高峰時段交通高峰。 因此,如果不在日期時間列上執行特征工程,我們將錯過這些聲音預測器!
你走之前 (Before you go)
Congratulations for you who have managed reading this far!
恭喜您成功閱讀了本文!
Now for a short recap. In this article, we learned how to perform feature engineering on date-time data. Afterwards, we incorporated the engineered features to build a powerful gradient boosting regression model, to forecast metro traffic volume.
現在簡要回顧一下。 在本文中,我們學習了如何對日期時間數據執行特征工程。 之后,我們結合了工程化功能以構建強大的梯度提升回歸模型,以預測地鐵交通量。
Finally, thanks for reading and let’s connect with me on LinkedIn!
最后,感謝您的閱讀,讓我們在LinkedIn上與我聯系!
翻譯自: https://towardsdatascience.com/feature-engineering-on-date-time-data-90f6e954e6b8
軟件工程方法學要素含義
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389101.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389101.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389101.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
)
洛谷P1605:迷宮(DFS)

vue圖片壓縮不失真_圖片壓縮會失真?快試試這幾個無損壓縮神器。

remoteing2

android 線程池

datatable轉化泛型
...)
【躍遷之路】【651天】程序員高效學習方法論探索系列(實驗階段408-2018.11.24)...

更換mysql_Docker搭建MySQL主從復制

dll文件的c++制作dll文件的c++制作

理解ConstraintLayout 對性能的好處

數據湖 data lake_在Data Lake中高效更新TB級數據的模式


advanced installer更換程序id_好程序員web前端培訓分享kbone高級-事件系統

ai對話機器人實現方案_顯然地引入了AI —無代碼機器學習解決方案


透明狀態欄導致windowSoftInputMode:adjustResize失效問題
![[TimLinux] JavaScript 元素動態顯示](http://pic.xiahunao.cn/[TimLinux] JavaScript 元素動態顯示)
[TimLinux] JavaScript 元素動態顯示


圖片中的暖色或冷色濾色片是否會帶來更多點擊? —機器學習A / B測試

3d制作中需要注意的問題_淺談線路板制作時需要注意的問題
