數據湖 data lake
GOAL: This post discusses SQL “UPDATE” statement equivalent for a data lake (object) storage using Apache Spark execution engine. To further clarify consider this, when you need to perform conditional updates to a massive table in a relations data warehouse… you will do something like
目標 :這篇文章討論了等效于使用Apache Spark執行引擎的數據湖(對象)存儲SQL“ UPDATE”語句。 為了進一步闡明這一點,當您需要對關系數據倉庫中的大型表執行條件更新時,您將執行以下操作
UPDATE <table name>
SET <column> = <value>
WHERE <primary_key> IN (val1, val2, val3, val4)How would you do the same when your data is stored as parquet files in an object storage (S3, ADLS Gen2, etc.)?
當數據作為拼合文件存儲在對象存儲中(S3,ADLS Gen2等)時,您將如何做?
CONTEXT: Consider a massive table about 15TB in size that gets 40–50 GB (~ 1B rows) of new data every day. This new data contains fresh records to be inserted and updates to older records as well. These updates to older records can go as far back as 18 months and are the root of all complications. When processing new data every day the pipeline has to remove duplicates for all records that received updates.
上下文 :考慮一個約15TB的大型表,每天可獲取40–50 GB(?1B行)的新數據。 此新數據包含要插入的新記錄,以及對舊記錄的更新。 這些對較早記錄的更新可以追溯到18個月,并且是所有并發癥的根源。 每天處理新數據時,管道必須刪除所有收到更新的記錄的重復項。
Sample business context, consider an online sports store that discounts prices based on number of goods purchased… so, a pair-of-shoes and a pair-of-shorts individually might cost $10 and $5 respectively, but when the purchases are grouped together they cost $13. Now, to further complicate things… imagine if the buyer could group her/his purchases at a later time after making the purchases individually. So, let’s say I purchased a pair-of-shoes on Jan 1st, 2020 for $10 and then on Jul 7th, 2020 I decide to purchase a pair-of-shorts, which is $5 by itself. But, at this point I can group my recent purchase of shorts with my older purchase of shoes made on Jan 1st… doing this reduces my total expense on shoes + shorts to $13 instead of $15. On the backend, this transaction doesn’t just reduce the price of shorts, but it reduces the price of both shorts and shoes proportionally. So, the transaction that holds original selling price of the shoes needs to be updated from $10 to $8.7 (taking out percentage 2/15 = 0.133). In light of above business case, let’s see the three major components of this problem
以業務環境為例,請考慮一家在線體育商店,該商店根據購買的商品數量來打折價格……因此,一雙鞋和一雙短褲可能分別花費10美元和5美元,但是當將購買組合在一起時,花費$ 13。 現在,要進一步使事情復雜化……想象一下購買者是否可以在單獨進行購買后稍后將其購買分組。 因此,假設我在2020年1月1日以10美元的價格購買了一雙鞋 ,然后在2020年7月7日,我決定購買一條5美元的短褲 。 但是,在這一點上,我可以將我最近購買的短褲與1月1日以前購買的舊鞋歸為一類……這樣做可以將我的鞋子+短褲的總支出減少到13美元,而不是15美元。 在后端,此交易不僅降低了短褲的價格,而且還成比例地降低了短褲和鞋子的價格。 因此,保持鞋子原始銷售價格的交易需要從10美元更新為8.7美元(扣除2/15百分比= 0.133)。 根據上述業務案例,讓我們看一下這個問題的三個主要組成部分
- The massive table we spoke of earlier is the sales table that holds all transactions, 我們之前提到的龐大表是保存所有交易的銷售表,
- The data coming into the system every day are all transactions for that day (new and updates to older records) 每天進入系統的數據是當天的所有交易(新記錄和舊記錄的更新)
- The pipeline code that consumes incoming data, processes it, and updates the sales table 消耗傳入數據,對其進行處理并更新銷售表的管道代碼
Complications with this scenario,
這種情況下的并發癥
1. Volume of data in transit — About 1 billion(40 GB) transactions flowing into the system every day
1. 傳輸中的數據量-每天大約有10億(40 GB)交易流入系統
2. Volume of data at rest — sales table is massive (~15TB). This table is partitioned on transaction date and each partition (i.e. transaction date folder) contains a billion rows
2. 靜態數據量-銷售表非常大(約15TB)。 該表按交易日期分區,每個分區(即交易日期文件夾)包含十億行
3. Updates to historical data — Every day the incoming transactions can update historical data up to past 18 months (545 days) which mean ~545 billion rows
3. 更新歷史數據 -過去18個月(545天)內,每天傳入的交易每天都可以更新歷史數據,這意味著約5,450億行
4. The data is stored in a data lake (S3, ADLS Gen2, etc.) and not in a relational data warehouse… which mean there are no SQL like indices or UPDATE statements to take advantage of.
4.數據存儲在數據湖(S3,ADLS Gen2等)中, 而不存儲在關系數據倉庫中 ……這意味著沒有SQL之類的索引或UPDATE語句可以利用。
TECHNICAL DETAILS: This approach assumes data is stored in an object storage i.e. S3, ADLS Gen2 etc. and the processing is done using Apache Spark based execution layer.
技術細節 :此方法假定數據存儲在對象存儲中,即S3,ADLS Gen2等,并且使用基于Apache Spark的執行層進行處理。
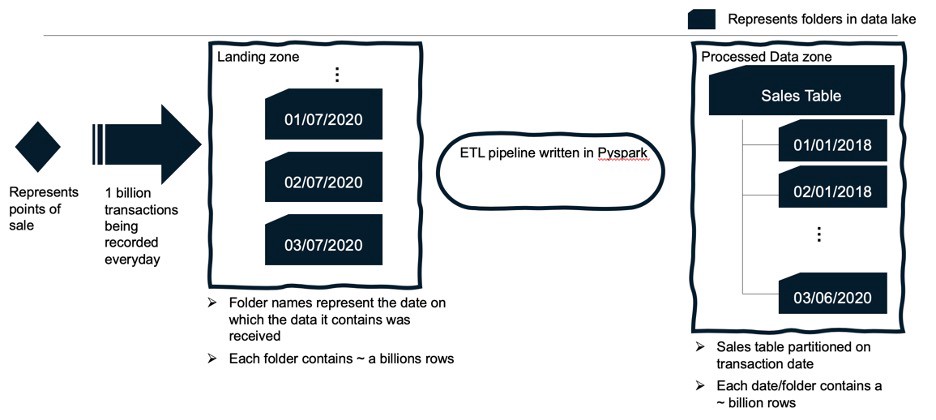
- Data is stored in an object storage (S3, ADLS Gen2, etc.) as parquet files and is partitioned by transaction date. So, in above example, the record representing shoe purchase dated Jan 1st, 2020 will be within a folder titled Jan 1st, 2020 數據作為實木復合地板文件存儲在對象存儲(S3,ADLS Gen2等)中,并按交易日期進行分區。 因此,在上述示例中,代表日期為2020年1月1日的鞋子購買的記錄將位于標題為2020年1月1日的文件夾中
- Each record flowing into the data lake is appended with a column called “record_timestamp”. This holds timestamp value of when a particular record was received. This is crucial for identifying latest records in case of multiple duplicates 每個流入數據湖的記錄都附加一個稱為“ record_timestamp”的列。 這保留接收到特定記錄的時間戳值。 這對于在多次重復的情況下識別最新記錄至關重要
The object storage (refer schematic above) is divided in to two sections:
對象存儲(請參見上面的示意圖)分為兩個部分:
a.
一個。
Landing zone — where the incoming data is stored in folders. Refer “landing zone” in above schematic, each folder is named with a date, this date signifies when the data contained in the folder was received. So, all of data received on 01/07/2020 will reside in folder name = “01/07/2020”
著陸區 -傳入數據存儲在文件夾中的區域。 請參閱上面示意圖中的“著陸區”,每個文件夾都有一個日期命名,該日期表示何時接收到該文件夾??中包含的數據。 因此,2020年1月7日收到的所有數據都將駐留在文件夾名稱=“ 01/07/2020”中
b.
b。
Processed data zone — where the final view of sales table resides i.e. every transaction has its latest adjusted value. Refer “Processed Data Zone” in above schematic, folders in this zone are also named with a date… this date is “transaction_date”. So, if on 03/07/2020… we receive an update to a transaction which was initially made on 01/01/2020… this new record will be stored in folder titled “03/07/2020” in “Landing Zone” and in folder titled “01/01/2020” in “Processed Data Zone”. A dataset can be stored like this by a simple command such as
已處理數據區 -銷售表的最終視圖所在的位置,即每筆交易都有其最新調整后的價值。 請參閱上面示意圖中的“已處理數據區域”,該區域中的文件夾也被命名為日期,該日期為“ transaction_date”。 因此,如果在03/07/2020…我們收到的交易更新最初是在2020年1月1日……此新記錄將存儲在“著陸區”中名為“ 03/07/2020”的文件夾中,并且在“已處理數據區域”中名為“ 01/01/2020”的文件夾中。 數據集可以通過一個簡單的命令像這樣存儲
dataframe_name.write.partitionBy(“transaction_date”).parquet(<location>)Note: As the transaction date is used for partitioning, it will not appear in the data within the folders titled with transaction date
注意:由于交易日期用于分區,因此它不會出現在以交易日期為標題的文件夾中的數據中
4. For processing the data, we use PySpark on databricks (approach stays same for other spark distributions)
4.為了處理數據,我們在數據塊上使用PySpark(方法對于其他火花分布保持不變)
FINALLY, THE APPROACH: Assume the pipeline runs every night at 2 am to process data for the previous day. In current example let’s assume it’s 2 am on July 8th (i.e. 07/08/2020) and the pipeline will be processing data for 07/07/2020. The approach to update data is primarily two phases:
最后,方法:假設管道每天晚上2點運行,以處理前一天的數據。 在當前示例中,我們假設它是7月8日凌晨2點(即07/08/2020),并且管道將處理07/07/2020的數據。 更新數據的方法主要分為兩個階段:
First phase has three sub-steps
第一階段包含三個子步驟
1. read in the new data from Landing Zone,
1.從著陸區讀取新數據,
2
2
. append it to existing data in “Processed Data Zone” in the respective folders as per transaction date,
。 根據交易日期將其附加到相應文件夾中“已處理數據區域”中的現有數據,
3. store names (i.e. dates) of all folders that received updates in a list so that in next step we can use it
3.將收到更新的所有文件夾的名稱(即日期)存儲在列表中,以便在下一步中可以使用它
First sub-step is self-explanatory. Let me explain the second sub-step in a bit detail with an example, consider our old purchases of a pair of shoes on Jan 1st 2020 and then a pair of shorts on Jul 07th 2020, now this transaction on Jul 7th 2020 will lead to an update to selling price of shoes from $10 to $8.7 because of grouping discount. This will be reflected in the data lake as below:
第一步是不言自明的。 讓我用一個示例來詳細解釋第二個子步驟,考慮我們在2020年1月1日購買的一雙鞋,然后在2020年7月7日購買的一雙短褲,現在在2020年7月7日的交易將導致由于分組折扣,鞋子的售價從10美元更新為8.7美元。 這將反映在數據湖中,如下所示:
On Jan 1st 2020, the data in folder corresponding to this date will look like… only shoes purchased
2020年1月1日,與此日期對應的文件夾中的數據如下所示:僅購買了鞋子

… on Jul 07th 2020, with a purchase of a pair of shorts being grouped with the earlier transaction. The data in folder dated Jan 1st 2020 will look like this
…于2020年7月7日,購買了一條與早期交易組合在一起的短褲。 文件夾中日期為2020年1月1日的數據將如下所示

Note: This is possible because when an update is made to an existing transaction, the update preserves the original transaction date and ID in addition to recording its own creation date. The transaction for a pair of shorts will reflect in folder dated Jul 07th 2020 because this is the original transaction for purchase of shorts.
注意:之所以可行,是因為在對現有交易進行更新時,該更新除了記錄其自己的創建日期之外,還保留了原始交易日期和ID。 一對短褲的交易將反映在2020年7月7日的文件夾中,因為這是購買短褲的原始交易。
The third sub-steps of this phase help us create a list of folder names that received updates in sub-step two and now contain duplicate records. Make sure you store this list in a temporary location.
此階段的第三個子步驟可幫助我們創建一個文件夾名稱列表,該文件夾名稱在第二步中已接收更新,現在包含重復記錄。 確保將此列表存儲在一個臨時位置。
Second phase is about removing duplicates from all folders updated by second sub-step in last phase. This is accomplished by leveraging the list of folder names created in third sub-step of last phase. In worst case scenario, this list will have 545 values (i.e. one entry per day for last 18 months). Let’s see how we will handle this case… Each of these 545 folders contain about a billion records and there are multiple ways to remove duplicates from all of these folders… I believe the easiest one to visualize is using a loop. Granted this is not most efficient but it does help get the idea across. So, let’s go through sub-steps of this phase
第二階段是從上一個階段的第二個子步驟更新的所有文件夾中刪除重復項。 這是通過利用在上一個階段的第三子步驟中創建的文件夾名稱列表來完成的。 在最壞的情況下,此列表將具有545個值(即,過去18個月中每天有一個條目)。 讓我們看看我們將如何處理這種情況……這545個文件夾中的每個文件夾都包含約10億條記錄,并且有多種方法可以從所有這些文件夾中刪除重復項……我相信最容易看到的是使用循環。 當然,這不是最有效的方法,但確實有助于將想法傳播出去。 因此,讓我們來看一下該階段的子步驟
1. Read in the list of folder names which contain duplicate transactions,
1.讀入包含重復交易的文件夾名稱列表,
2. Loop through this list and perform following
2.遍歷此列表并執行以下操作
a. Read the data from the folder specified by loop counter,
一個。 從循環計數器指定的文件夾中讀取數據,
b. Remove duplicates(defined as per candidate key columns) from this data frame, and
b。 從此數據框中刪除重復項(按候選關鍵字列定義),然后
Import pyspark.sql.functions sfdf_duplicates_removed = (df_with_duplicates
.withColumn('rn',sf.row_number()
.over(Window().partitionBy(<primary_key>)
.orderBy(sf.col(order_by_col).desc())))
.where((sf.col("rn") == 1))
)c. Write refreshed dataset back to its original location
C。 將刷新的數據集寫回到其原始位置
For parallelizing “duplicates removal” step, you can use serverless execution such as AWS Lambda functions in addition to a queue store for folders names that need to be refreshed.
為了并行化“重復項刪除”步驟,除了可以存儲需要刷新的文件夾名稱的隊列存儲之外,還可以使用無服務器執行(例如AWS Lambda函數)。
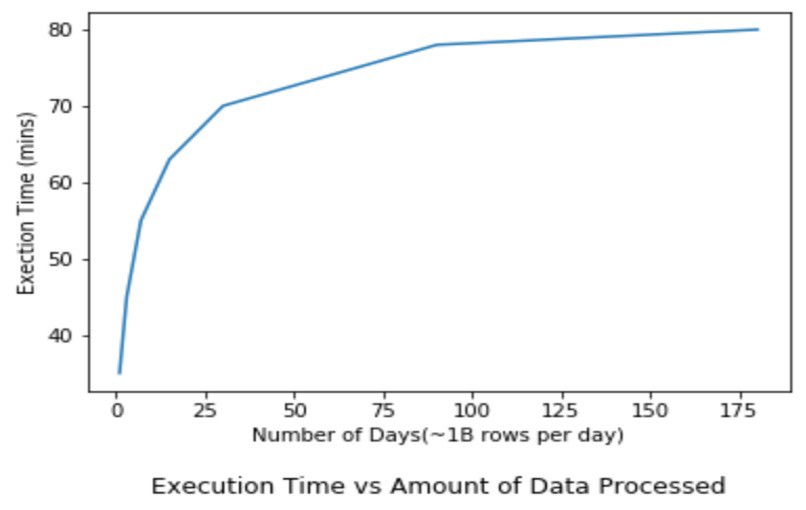
CONCLUSION: This approach seems to work very nicely with large datasets, and it scales gracefully as processing needs grow. In other words, the curve of execution time (y-axis) vs data size (x-axis) begins to flatten as the data size grows… this is primarily because the second phase of processing allows for massive parallelization.
結論 :這種方法似乎適用于大型數據集,并且可以隨著處理需求的增長而適當擴展。 換句話說,執行時間(y軸)對數據大小(x軸)的曲線隨著數據大小的增長而開始趨于平坦……這主要是因為處理的第二階段允許大規模并行化。
Although, the fictitious business example used here pertains to sales, this pattern can be leveraged in any scenario with need for big data processing such as — IOT, log streams analysis, etc. Thanks for reading!
盡管此處使用的虛擬業務示例與銷售有關,但是可以在需要大數據處理的任何情況下利用此模式,例如IOT,日志流分析等。感謝您的閱讀!
翻譯自: https://medium.com/@ashishverma_93245/pattern-to-efficiently-update-terabytes-of-data-in-a-data-lake-1f4981b1861
數據湖 data lake
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389091.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389091.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389091.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章


advanced installer更換程序id_好程序員web前端培訓分享kbone高級-事件系統

ai對話機器人實現方案_顯然地引入了AI —無代碼機器學習解決方案


透明狀態欄導致windowSoftInputMode:adjustResize失效問題
![[TimLinux] JavaScript 元素動態顯示](http://pic.xiahunao.cn/[TimLinux] JavaScript 元素動態顯示)
[TimLinux] JavaScript 元素動態顯示


圖片中的暖色或冷色濾色片是否會帶來更多點擊? —機器學習A / B測試

3d制作中需要注意的問題_淺談線路板制作時需要注意的問題

冷啟動、熱啟動時間性能優化

python:lambda、filter、map、reduce


Myeclipes連接Mysql數據庫配置
...)
cnn圖像二分類 python_人工智能Keras圖像分類器(CNN卷積神經網絡的圖片識別篇)...

圖卷積 節點分類_在節點分類任務上訓練圖卷積網絡
![[微信小程序] 當動畫(animation)遇上延時執行函數(setTimeout)出現的問題](http://pic.xiahunao.cn/[微信小程序] 當動畫(animation)遇上延時執行函數(setTimeout)出現的問題)
[微信小程序] 當動畫(animation)遇上延時執行函數(setTimeout)出現的問題

關于使用pdf.js預覽pdf的一些問題

SqlHelper改造版本

回歸分析預測_使用回歸分析預測心臟病。
