A/B test on ads is the art of choosing the best advertisement that optimizes your goal (number of clicks, likes, etc). For example, if you change a simple thing like a filter in your pictures you will drive more traffic to your links.
廣告的A / B測試是一種選擇最佳廣告的藝術,該廣告可以優化您的目標(點擊次數,喜歡的次數等)。 例如,如果您更改圖片中的過濾器之類的簡單內容,則會為鏈接帶來更多流量。
In this post we will see how to do evaluate by yourself the efficacy of your own A/B test using Python and Bayesian Statistics.
在這篇文章中,我們將看到如何使用Python和貝葉斯統計自己評估自己的A / B測試的效率。
Article TL;DR for the Busy Data Scientist
Article TL; DR for the Busy Data Scientist
- I ran two twitter ads. The one with a cold filter outperformed the one with warm filter. 我投放了兩個Twitter廣告。 帶有冷濾網的濾網的性能優于帶暖濾網的濾網的性能。
Skip to section “The Code (starting from the end)” if you just want to copy and past some Python code to try your own A/B Test.
如果您只想復制并粘貼一些Python代碼來嘗試自己的A / B測試,請跳至“ 代碼(從末尾開始) ”部分。
Skip to the section “Putting all together” if you want to see my final result.
如果要查看我的最終結果,請跳至“ 全部放在一起 ”部分。
- Read it through if you want to learn how to do and why it works A/B Tests using Bayesian statistics. 如果您想學習使用貝葉斯統計信息的方法以及為什么要使用A / B測試,請通讀它。
問題 (The Problem)
Given two ads (A and B), which one has the highest Click-Through-Rate (CTR)? From a statistical point of view, the problem is to learn the unobservable TRUE CTR parameter from the observed data of impressions (ad views) and clicks. Just to avoid confusion, remember that CTR is calculated as the number of clicks divided by the number of impressions:
給定兩個廣告(A和B),哪個具有最高點擊率(CTR)? 從統計的角度來看,問題是要從所觀察到的印象(廣告視圖)和點擊數據中了解到不可觀察的TRUE CTR參數。 為避免混淆,請記住,點擊率的計算方法是點擊次數除以展示次數:
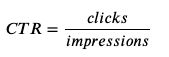
From this simple formula you might be thinking:
從這個簡單的公式中,您可能會想到:
“If the equation is really just a simple division the only thing I need to do is to get the data from the ad performance , do the simple division and the higher number is the best Ad. DONE!?”
“如果等式實際上只是一個簡單的除法運算,那么我唯一需要做的就是從廣告效果中獲取數據,然后進行簡單的除法運算,數值越大越好。 完成!?”
Well, not really.
好吧,不是真的。
Say you have only one impression and one click, that is a CTR of 100%, but you should not be assuming that your TRUE CTR is actually 100% from one single view/impression. It most likely is not 100%, by the way. To put it simply, the observed CTR alone cannot tell us the performance of an ad. We need more, we need more data and we still need some Bayesian statistics. But before let me setup our our ad campaign.
假設您只有一次展示和一次點擊,即100%的點擊率,但您不應假設您的TRUE CTR實際上是從單個視圖/展示獲得的100%。 順便說一句,它很可能不是100%。 簡而言之,僅觀察到的點擊率并不能告訴我們廣告的效果。 我們需要更多,我們需要更多數據,我們仍然需要一些貝葉斯統計數據。 但是在讓我設置廣告系列之前。
設置 (The Setup)
Let us explorer the problem a little bit further. For that matter, I ran two real ads in Twitter with real money (I spent $20 USD in case you are curious). The difference between both ads was only the filter in the images. One image had a cold filter and the other had a warm filter (default filters in my smart phone). The ad was for an Affiliate Amazon link to the book ‘Designing Data Intensive Applications ’(https://amzn.to/3iycLi6).
讓我們進一步探討該問題。 為此,我在Twitter上用真錢投放了兩個真實的廣告(如果您好奇的話,我花了20美元)。 這兩個廣告之間的區別只是圖片中的過濾器。 一個圖像有一個冷濾鏡,另一個圖像有一個暖濾鏡(我的智能手機中的默認濾鏡)。 該廣告是針對一個亞馬遜附屬機構的鏈接,該鏈接指向《 設計數據密集型應用程序 》( https://amzn.to/3iycLi6 )一書。
The question is ‘Which filter maximizes my the Click-Through-Rate?’, i.e., which image makes the Amazon link most likely to be clicked? Here are the ads side by side:
問題是“哪個過濾器會最大化我的點擊率?”,即哪個圖像使Amazon鏈接最有可能被點擊? 以下是這些廣告的并排:

After running both ads for a few hours I got the following impressions and clicks:
將兩個廣告都投放了幾個小時后,我得到了以下印象和點擊:
Ad A (cold filter): 190 impressions, 13 clicks, CTR 0.068 (6.8%)
廣告A(冷過濾器):190次展示,13次點擊,點擊率0.068(6.8%)
Ad B(warm filter): 143 impressions, 9 clicks, CTR 0.062 (6.0%)
廣告B(熱過濾器):143次展示,9次點擊,點擊率0.062(6.0%)
From the data, we can see that A’s observed CTR is higher than B’s observed CTR (6.8% > 6.0%). The remaining of this post we will answer the following two questions:
從數據中我們可以看到,A的觀察到的點擊率高于B的觀察到的點擊率 (6.8%> 6.0%)。 在本文的其余部分,我們將回答以下兩個問題:
- Can we conclude that A’s real CTR is higher than B’s real CTR? 我們是否可以得出結論,A的實際點擊率高于B的實際點擊率?
- If we were to accept it is (or it is not), what is the probability that we are right or wrong? 如果我們接受它是(或不是),那么我們是對是錯的概率是多少?
One way to stretch this question to the extreme would be the following hypothetical situation: Assume that ad A had 1 view and 0 clicks while ad B had 1 view and 1 click. Their observed CTR are 0% and 100%, but no one would say that ad B performs better than ad A just from these data points. Let’s see how to estimate our CTRs while our ad campaign is running.
將這個問題擴展到極端的一種方法是,在以下假設情況下進行:假設廣告A具有1個視圖和0次點擊,而廣告B具有1個視圖和1次點擊。 他們觀察到的點擊率分別為0%和100%,但沒有人會說從這些數據點來看,廣告B的效果要好于廣告A。 讓我們看看如何在廣告系列投放期間估算點擊率。
代碼(從頭開始) (The Code (starting from the end))
It will be easier to understand where we are going if we start at the end. So, let’s have a look at some code. Do not worry if you do not understand every line yet, the main point now is the plot the code produces, also I will walk you through the code later.
如果我們從頭開始,將會更容易理解我們的發展方向。 因此,讓我們看一些代碼。 如果您還不了解每一行,請不要擔心,現在的重點是代碼產生的圖形,稍后我將引導您完成代碼。
Running this code in your notebook, you should get the following plot:
在筆記本中運行此代碼,應該得到以下圖表:
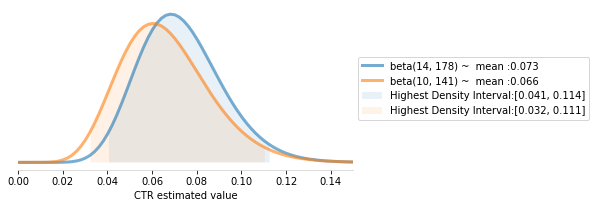
This plot shows the most likely values for each CTR given the observed data. Since the regions with the most likely values (the Highest Density intervals above) we cannot say that one ad is better than the other only, at least not with only this data. For comparison, see the same code if it were ran with the following FAKE data:
此圖顯示了給定觀察到的數據的每個點擊率的最可能值。 由于具有最可能值的區域(上述最高密度區間),我們不能說一個廣告僅比另一個廣告好,至少不能僅憑此數據。 為了進行比較,如果它與以下FAKE數據一起運行,請參見相同的代碼:
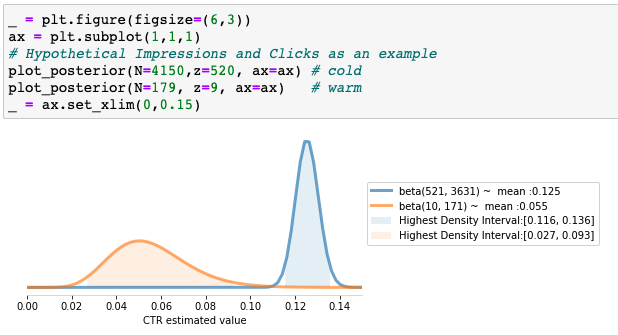
We will perform our A/B test in these 3 simple steps. We will:
我們將通過以下三個簡單步驟來執行A / B測試。 我們會:
- Gather the number of impressions and clicks of both ads; 收集兩個廣告的印象數和點擊數;
- Plot the distribution of the most likely values for A and B’s CTR; 繪制A和B點閱率最可能值的分布;
- Compare their highest density intervals and decide depending on the intervals’ overlap. 比較它們的最高密度間隔,并根據間隔的重疊進行確定。
If you paid attention to the Python code above (no judgement if you did not), you saw that we used a few keywords, most importantly prior, posterior and beta. In the next section we will jump to the math and explain why the previous Python code works. So buckle up, enter the Bayesian statistics.
如果您注意上面的Python代碼(如果沒有,則無法判斷),您會看到我們使用了一些關鍵字,最重要的是before,posterior和beta。 在下一節中,我們將跳至數學并解釋為什么以前的Python代碼可以工作。 系好安全帶,輸入貝葉斯統計數據。
A / B測試背后的數學 (The Math behind A/B Test)
先驗 (The Prior)
The goal here is to estimate the real CTR for an ad given the observed data. Since seeing the REAL CTR would imply serving an ad to every single user of Twitter, it is monetarily (and often practically) impossible to do that. So we will need to make our 20 bucks worth it. The estimation will come with an uncertainty that we will be able to quantify, that is also important for our decision making when it comes to stop an ad and increase the budget on others.
這里的目標是根據觀察到的數據估算廣告的實際點擊率。 由于看到REAL CTR意味著向Twitter的每個用戶投放廣告,因此從金錢上(通常實際上)是不可能做到的。 因此,我們需要使我們的20美元值得。 估算將帶有我們可以量化的不確定性,這對于我們停止廣告并增加其他廣告的預算時的決策也很重要。
Let’s call θ the parameter we want to estimate (in this case the CTR of an ad) and p(θ) the probability distribution for θ. In a previous article, I talked about p(θ) being discrete or sometimes uniform, but here we will see that using the beta distribution to describe p(θ) makes sense and it convenient for computation.
我們將θ稱為我們要估算的參數(在這種情況下,是廣告的點擊率),而將p(θ)稱為θ的概率分布。 在上一篇文章中 ,我談到了p(θ)是離散的或有時是均勻的,但是在這里我們將看到使用beta 分布來描述p(θ)是有意義的,并且便于計算。
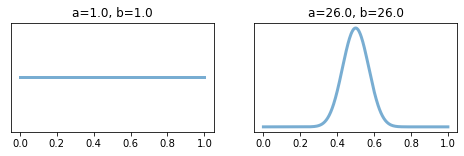
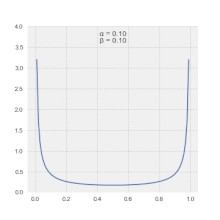
One way to think about p(θ) is to think as if it is our belief on the possible values of θ. For example, say we are talking about a problem that we have no prior knowledge, and all possible values of θ are equally likely. In this case, note that beta(1,1) describes our knowledge (or lack of) for possible values of θ. By the same token, if we were to use θ to describe our prior belief on the probability of a coin flip to be be heads, the distribution beta(25,25) would be a good candidate, as it is centered around 50% , but we would still allow some room for small biases (HDI spans within 0.4~0.6). See figure below:
思考p(θ)的一種方法是,認為它似乎是我們對θ可能值的信念。 例如,假設我們正在談論的是一個我們沒有先驗知識的問題,并且所有可能的θ值都是同等可能。 在這種情況下,請注意beta(1,1)描述了我們對θ可能值的認識(或缺乏)。 出于同樣的原因,如果我們使用θ來描述我們對硬幣翻轉為正面概率的先前信念,則分布beta(25,25)將是一個很好的候選者,因為它的中心在50%左右,但是我們仍然會留出一些小的偏差空間(HDI范圍在0.4?0.6之間)。 參見下圖:
The parameters a and b can seem a little artificial, but away to describe a particular prior of a problem is via the prior mean m and the number of events n observed in the past. With m and n one can find the parameters a and b as follows:
參數a和b看起來有些虛假,但是描述問題的特定先驗條件是通過先驗均值m和過去觀察到的事件數n來描述。 使用m和n可以找到參數a和b ,如下所示:
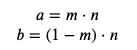
It is important to note that a beta distribution might not be the best fit for the problem, for that we could use model selection via Bayes Factor, a topic way beyond this article. Historically, the beta distribution is used because it is very easy to compute, specially when we use it with the bayesian rule given some new data. Let’s have a look on that next.
需要注意的是AB 埃塔分布可能不是問題的最佳契合,對于我們可以通過貝葉斯因子,一個主題的方式這篇文章以后使用模式的選擇是很重要的。 從歷史上看,使用beta分布是因為它非常易于計算,尤其是當我們將貝葉斯規則與給定一些新數據一起使用時。 接下來讓我們看一下。
后部 (The Posterior)
The way we will do our A/B test will be assuming the prior distribution for our parameter θ (the real click-through-rate of the ad) to be beta(1,1), i.e., we will assume total lack of prior knowledge and set any possible value of θ to be equally likely. Then, we will update our p(θ) given our observed data, for that we use bayes rule (For an introduction to the Bayes’ Rule see my previous Article here):
我們進行A / B測試的方式將假設參數θ(廣告的實際點擊率)的先驗分布為beta(1,1) ,即,我們將假設完全沒有先驗分布知道并將任何可能的θ值設置為同等可能。 然后,我們將給予我們的觀測數據來更新我們的P(θ),對于我們使用貝葉斯法則(對于一個介紹貝葉斯法則看我以前的文章在這里 ):
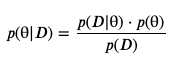
Our goal will be to calculate the posterior distribution p(θ|D) for our advertisement given the number of impressions and clicks the ad received.
我們的目標是給定印象數和點擊數,計算出廣告的后驗分布p(θ| D)。
First, note that we are assuming that given an ad, the probably of clicking it when it is seen is equal to θ and the probability of not being clicked is equal to 1-θ, that is what we call a Bernoulli distribution.
首先,請注意,我們假設給定一個廣告,看到它時點擊它的可能性等于θ,未被點擊的可能性等于1-θ,這就是我們所說的伯努利分布。
Result: After N impressions and z clicks, if the probability of the data (N, z) is a Bernoulli distribution, and if the prior distribution of θ is a beta(a,b) distribution, then the following holds to be true:
結果:在N次展示和z次點擊之后,如果數據( N,z )的概率是伯努利分布,并且如果θ的先前分布是beta(a,b)分布,則以下條件成立:
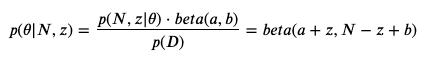
For a detailed proof of this result I suggest John Kruschke’s “Doing Bayesian Data Analysis” (https://amzn.to/345ouR2), or ask me in Twitter (@solvingthehuman).
有關此結果的詳細證明,我建議約翰·克魯施克(John Kruschke)的“做貝葉斯數據分析”( https://amzn.to/345ouR2 ),或在Twitter(@solvingthehuman)上問我。
放在一起 (Putting all together)
With the equation from last section we can say that after N impressions and z clicks in an ad, the updated distribution of the ad’s CTR (the θ parameter) is given by:
使用上一節中的公式,我們可以說,在廣告中獲得N次展示和z次點擊后,廣告CTR的更新分布(θ參數)由下式給出:
beta(1+z, N-z+1)
beta(1 + z,N-z + 1)
Let’s see how this look like with some real data along with the complete Python code so you can do your own A/B tests:
讓我們看看一些真實數據以及完整的Python代碼的樣子,以便您可以進行自己的A / B測試:
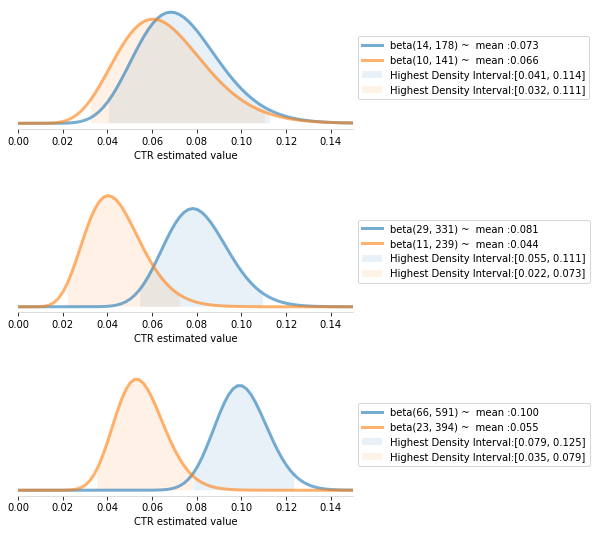
結論 (Conclusion)
In this article we saw how to use the beta distribution and Python to quickly decide which ad is performing better in an A/B test campaign.
在本文中,我們了解了如何使用Beta發行版和Python快速確定哪個廣告在A / B測試廣告系列中的效果更好。
Also, we saw that if you are planning to sell data science book on Twitter you might be better off using the cold filter for your pictures. I am very curious to know if this result holds up to other people.
此外,我們看到,如果您打算在Twitter上出售數據科學書籍,那么最好使用冷濾器來處理圖片。 我很想知道這個結果是否能勝任其他人。
Let me know of your own A/B tests! Did you have similar results as mine? I am in Twitter @solvingthehuman.
讓我知道您自己的A / B測試! 您有和我類似的結果嗎? 我在Twitter @solvingthehuman。
更多? (More?)
If you want to read:
如果您想閱讀:
An introduction about Bayesian Rule — Go here
關于貝葉斯規則的介紹-轉到此處
The advantages of Bayesian over other methods — Go here
圍棋^ h -貝葉斯優于其他方法的優點ERE
翻譯自: https://medium.com/solving-the-human-problem/do-warm-or-cold-filters-in-your-pictures-drive-more-clicks-a-machine-learning-python-a-b-testing-ccf5bdd89d4c
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389083.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389083.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389083.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

3d制作中需要注意的問題_淺談線路板制作時需要注意的問題

冷啟動、熱啟動時間性能優化

python:lambda、filter、map、reduce


Myeclipes連接Mysql數據庫配置
...)
cnn圖像二分類 python_人工智能Keras圖像分類器(CNN卷積神經網絡的圖片識別篇)...

圖卷積 節點分類_在節點分類任務上訓練圖卷積網絡
![[微信小程序] 當動畫(animation)遇上延時執行函數(setTimeout)出現的問題](http://pic.xiahunao.cn/[微信小程序] 當動畫(animation)遇上延時執行函數(setTimeout)出現的問題)
[微信小程序] 當動畫(animation)遇上延時執行函數(setTimeout)出現的問題

關于使用pdf.js預覽pdf的一些問題

SqlHelper改造版本

回歸分析預測_使用回歸分析預測心臟病。

)

UDP打洞程序包的源碼

NLPPython筆記——WordNet

crc16的c語言函數 計算ccitt_C語言為何如此重要

毫米波雷達與激光雷達的初探

aws spark_使用Spark構建AWS數據湖時的一些問題以及如何處理這些問題

沖刺第三天 11.27 TUE
