美國隊長3:內戰
There are plenty of reasons why one would want to find solitude in the wilderness, from the therapeutic effects of being immersed in nature, to not wanting to contribute to trail degradation and soil erosion on busier trails.
人們有很多理由想要在曠野找到孤獨,從沉浸在大自然中的治療效果到不想在繁忙的小徑上造成小徑的退化和土壤侵蝕。
Now more than ever the reprieve of the outdoors is greatly needed. But in a post-COVID 19 world, where it can be practically impossible to maintain proper social distancing measures when passing hikers on a narrow trail, it is especially important to find less frequented trails to hike.
現在比以往任何時候都更需要戶外緩刑。 但是在19后COVID的世界中,在狹窄的步道上經過遠足者時,幾乎不可能維持適當的社會疏遠措施,因此尋找不那么頻繁的遠足徑尤為重要。
I set out on a mission to use data science and machine learning to find the best little-known trails in America. You can check out the code on my github if you want to jump into the nitty gritty, or read on for analysis and a list of the hidden gems in your state!
我的任務是使用數據科學和機器學習來找到美國鮮為人知的最佳路徑。 您可以在我的github上簽出代碼,如果想跳入更多細節,或者繼續閱讀以進行分析以及您所在州的隱藏寶石清單!
該方法 (The Approach)
If you’re anything like me, before you go anywhere or buy anything, you’re going to read all the reviews. When looking for trails to hike, a popular medium for discovering where to go is AllTrails.com.
如果您像我一樣,在去任何地方或購買任何東西之前,您需要閱讀所有評論。 當您尋找遠足小徑時, AllTrails.com是找到目的地的一種流行媒介。
When I first approached this project, I wanted to answer the question, “What makes a trail good?” That is, what combination of features and statistics about a trail would lead to it having a high overall rating?
當我第一次接觸這個項目時,我想回答一個問題:“什么讓步道更好?” 就是說,特征和統計信息的組合如何才能使它具有較高的總體評價?
What I pretty quickly found out though, is that across the 35,000 trails I scraped and analyzed, basically all of them were rated “pretty good” — that is, with an average user rating of 4.2 out of 5 stars and standard deviation of less than 0.6, it was really hard to distinguish which trails were excellent, and which were just okay, from their 5-star rating alone.
不過,我很快發現,在我抓取和分析的35,000條路徑中,基本上所有路徑都被評為“相當好”,也就是說,平均用戶評分為5顆星中的4.2顆,標準偏差小于0.6,真的很難從它們的5星評級中區分出哪些是優秀的,哪些還可以。

What there was huge variation in across all the trails though, was their popularity as represented by the total number of reviews each trail had. While the vast majority of trails had only 100 or so reviews, a select few had several thousand! What was making these trails so popular?
但是,所有路徑之間的差異都很大,它們的受歡迎程度由每個路徑的評論總數表示。 雖然絕大多數足跡只有100條左右的評論,但很少的一條只有數千條! 是什么讓這些足跡如此受歡迎?

I thus pivoted to try to predict not the rating of a trail, but instead determine, via a data-driven model, the relationship between the various features of a given trail and its popularity. In finding commonalities, I could then apply that model to unpopular trails, to find which ones check all the same boxes and are likely to be great, even though they haven’t been discovered yet.
因此,我轉而嘗試不預測路線的等級,而是通過數據驅動模型確定給定路線的各種特征與其受歡迎程度之間的關系。 在尋找共性時,我可以將該模型應用于不受歡迎的線索,以找出哪些會選中所有相同的框,即使它們尚未被發現,也可能很棒。
方法 (Methodology)
- ) With Selenium and Beautiful Soup, scrape AllTrails.com to obtain trail data about 35,000 trails in the United States. This included information about the length of the hike, its elevation gain, its location, and a list of all of the natural features (such as waterfall, wild flowers, paving) the trail had. )使用Selenium和Beautiful Soup,抓取AllTrails.com以獲取有關美國35,000條路徑的路徑數據。 其中包括有關遠足時間,海拔提升,位置以及所有自然特征(例如瀑布,野花,鋪路)的列表的信息。
- ) Clean this data and create a Pandas DataFrame. This included one-hot encoding dummy variables for all of categorical feature columns. )清理此數據并創建一個Pandas DataFrame。 其中包括所有分類要素列的一鍵編碼偽變量。
- ) Utilize the VADER Sentiment Analysis module to analyze the text reviews via simple Natural Language Processing for each trail and determine a mean composite score. )利用VADER情緒分析模塊通過簡單的自然語言處理對每條線索進行文本評論分析,并確定平均綜合得分。
- ) Use linear regression modeling methodologies including Statsmodels OLS to determine the relationship between a trail’s features and its’ popularity. )使用包括Statsmodels OLS在內的線性回歸建模方法來確定路徑特征與其受歡迎程度之間的關系。
- ) Perform feature engineering and regularization via LassoCV to remove multicollinearity amongst those features and optimize the model. )通過LassoCV執行特征工程和正則化,以消除這些特征之間的多重共線性并優化模型。
- ) Apply that model to trails that are described as “lightly trafficked”, to find trails which would be expected to be popular based on their combination of features, but just haven’t been discovered yet. )將該模型應用于描述為“輕度販運”的路徑,以根據其功能組合查找預期會流行的路徑,但尚未發現。
發現 (Findings)
A linear regression model was fit to the trail’s stats with the number of reviews (and hence, popularity) serving as the target variable. The model yielded a list of the most influential features on a trail on it being popular. These included there being a fee, having a high sentiment analysis score, it being rocky, and having a scramble and no shade, amongst others.
線性回歸模型適合于線索的統計數據,其中評論數(因此受歡迎程度)用作目標變量。 該模型列出了受歡迎的路徑上最有影響力的功能。 這些包括收費 , 情感分析得分高 , 不算困難 , 爭奪和沒有陰影 ,等等。
I interpret those important features like this:
我將解釋以下重要特征:
A fee: If the most popular trails have a fee to use, this indicates they are likely located inside National Parks. As many National Parks are closed due to COVID, or may be very busy, it is even more important to find alternatives.
收費 :如果最受歡迎的步道需要付費,則表明它們可能位于國家公園內。 由于許多國家公園因COVID而關閉,或者可能非常繁忙,因此尋找替代方案顯得尤為重要。
Sentiment analysis score: Since all trails have roughly the same score out of 5 stars, its hard to gather a lot of reliable information about their quality from this rating alone. By using natural language processing to analyze the written text reviews themselves, I was able to gain an actual useful metric in determining how people actually feel about the trail. The higher the score (on a scale of -1=very negative to +1=very positive), the stronger people felt positively toward the trail, which was super useful in finding hidden gems.
情感分析得分 :由于所有足跡在5星中的得分大致相同,因此僅憑此評分就很難收集有關其質量的大量可靠信息。 通過使用自然語言處理本身來分析書面評論,我能夠獲得一個實際有用的指標來確定人們對這條路的實際感覺。 分數越高(從-1 =非常負到+1 =非常正),人們對步道的感覺越強,這對于發現隱藏的寶石非常有用。
Rocky/scramble/no shade: What this says to me is that the very popular trails take place above tree line! It’s on those more difficult hikes with higher elevation gain that you encounter these features. And with higher elevation, you’ll likely get better views! As it turns out, people love these tougher trails.
崎//無序/無陰影 :這對我說的是,非常受歡迎的步道發生在林線上方! 在遇到這些功能的情況下,就是那些具有更高仰角增益的較困難的遠足。 隨著海拔的升高,您可能會獲得更好的視野! 事實證明,人們喜歡這些艱難的路。
The R2 of this model was optimized to 0.19. Though this isn’t a very high score, you can see below that this is because the relationship between trail features and popularity simply isn’t linear. The residuals plot below showing the difference between the predicted popularity values and actual values demonstrates this pretty clearly (if this were linearly dependent, residuals would all fall in a fairly horizontal bar around 0!) So what’s actually determining a trail’s popularity if not it having all the right features of a popular trail?
該模型的R2優化為0.19。 盡管這并不是一個很高的分數,但是您可以在下面看到這是因為足跡特征和受歡迎程度之間的關系不是線性的。 下面的殘差圖顯示了預測的流行度值與實際值之間的差異,很清楚地證明了這一點(如果線性相關,則殘差都將落在0附近的相當水平的條形中!)流行路線的所有正確功能?
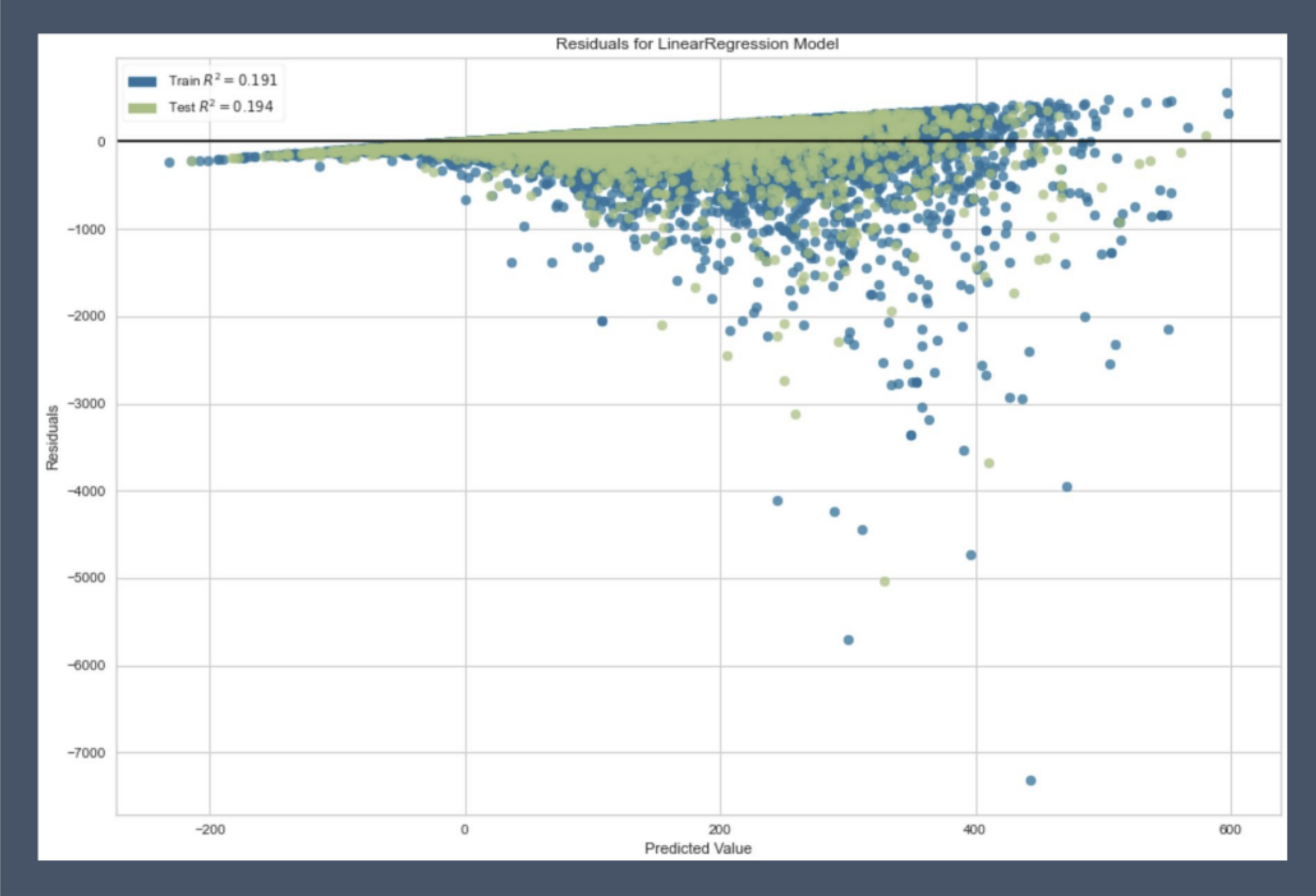
My key finding was that AllTrail’s algorithm shows the trails with the most reviews first and foremost, which leads to a form of recursive confirmation bias. If all trails have roughly the same rating, users will turn to the reviews to determine whether a trail is good, will choose to do one with a lot of reviews, hence feeding in to the loop of making the very few busiest trails even busier. Meanwhile, other similar trails may have plenty of opportunity but go neglected.
我的主要發現是,AllTrail的算法首先顯示了具有最多評論的路徑,這導致了遞歸確認偏差的形式。 如果所有路徑的評分大致相同,則用戶將轉向評論來確定一條路徑是否良好,并選擇對一條路徑進行大量評論,從而進入使最繁忙的路徑變得更加繁忙的循環。 同時,其他類似的路線可能有很多機會,但被忽略了。
那么,什么使小道受歡迎呢? (So What Makes a Trail Popular?)
There are tens of thousands of hikes listed on AllTrails.com, but their search algorithm always offers viewers the most popular hikes first. Trails with the most reviews get the most hikes, and hence even more reviews; while lesser known trails may be just a good, but are harder to find on the website, and hard to know for sure whether they’ll be a good trail if they have so few ratings.
AllTrails.com上列出了數以萬計的遠足,但他們的搜索算法始終始終為觀眾提供最受歡迎的遠足。 評論最多的步道獲得最多的加息,因此獲得更多評論; 雖然鮮為人知的足跡可能只是一個好選擇,但很難在網站上找到,并且如果它們的評分太少,很難確定它們是否會是一個好的足跡。
So what makes a trail popular? Ultimately, AllTrails does.
那么,什么使小道受歡迎呢? 最終, AllTrails做到了。
It’s time we break out of that feedback loop, and find some amazing alternative hikes where we can avoid the crowds. But how will you know if a trail is going to be worth your time? Well, I used Machine Learning to do that work for you.
現在該是我們打破這種反饋循環的時候了,找到一些令人驚奇的替代遠足方案,我們可以避開人群。 但是,您怎么知道一條小路是否值得您花時間呢? 好吧,我使用機器學習為您完成了這項工作。
I fit the best model on a subset of trails which were designated as being “lightly trafficked”, and the R2 for these trails was 0.08. This was actually encouraging, considering that these are specifically a selection of trails which aren’t popular, but according to this, given their features, should be.
我將最佳模型應用于被指定為“輕度販運”的部分路徑,這些路徑的R2為0.08。 這實際上是令人鼓舞的,考慮到這是專門選擇的路徑不屬于流行的,但根據這一點,由于其特點,應該是。
A potential area of future work for this project could be fitting a polynomial features model instead of a linear one. Early exploration into this method yielded a promising R2 improvement to 0.26, but did induce some feature collinearity by duplicating features, that would need to be feature engineered out. I’m looking forward to continuing this work once I have more machine learning tools at my disposal! But I’m absolutely thrilled to present you with this list of the best lesser-known trails in America as my very first end-to-end data science project.
該項目未來工作的潛在領域可能是擬合多項式特征模型而不是線性模型。 對該方法的早期探索使R2改善到了0.26,但確實通過復制特征引起了某些特征共線性,這需要進行特征設計。 一旦我擁有更多可用的機器學習工具,我期待繼續這項工作! 但是,作為我的第一個端到端數據科學項目,我非常高興向您介紹這份美國鮮為人知的最佳路徑。
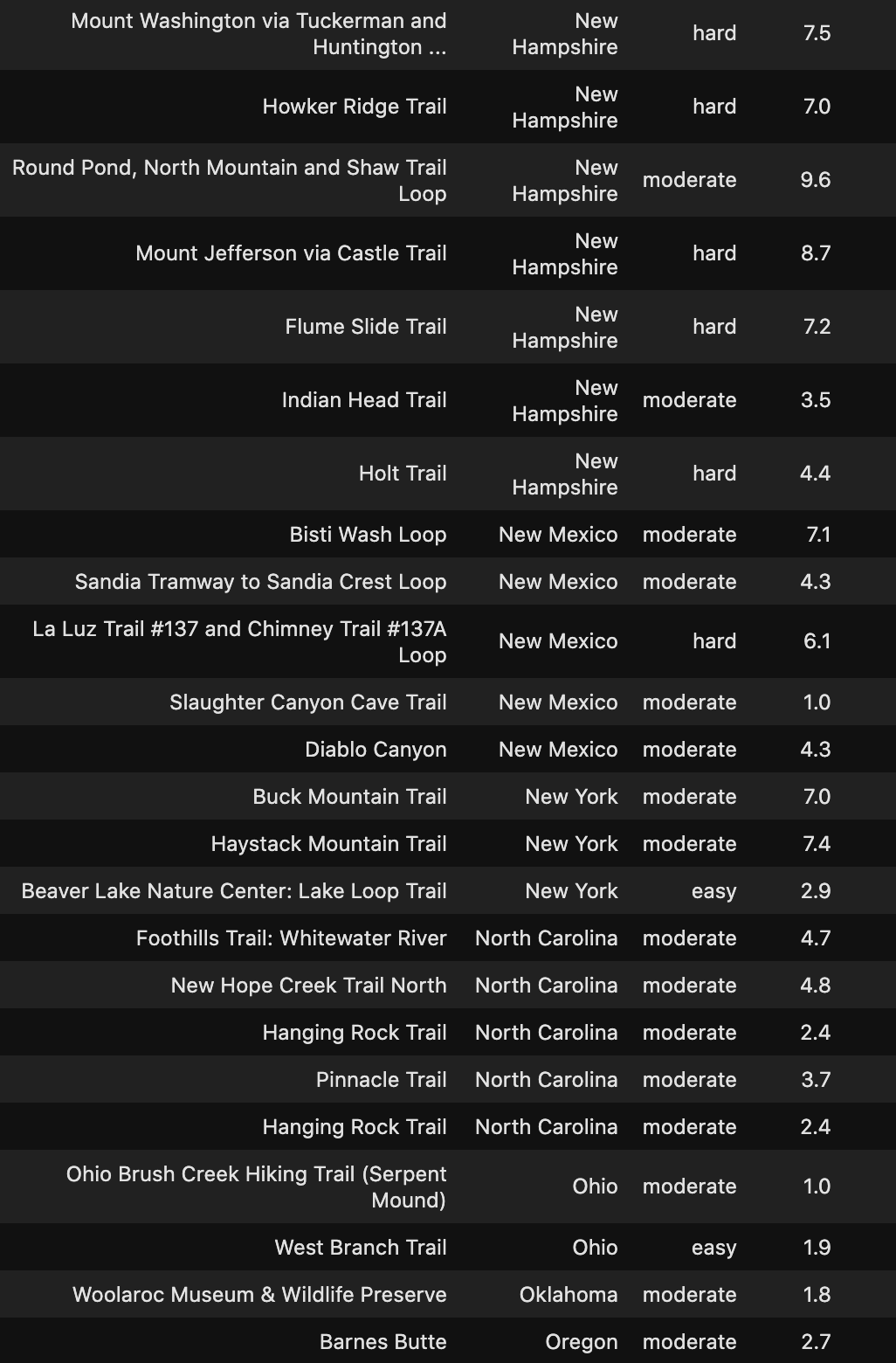
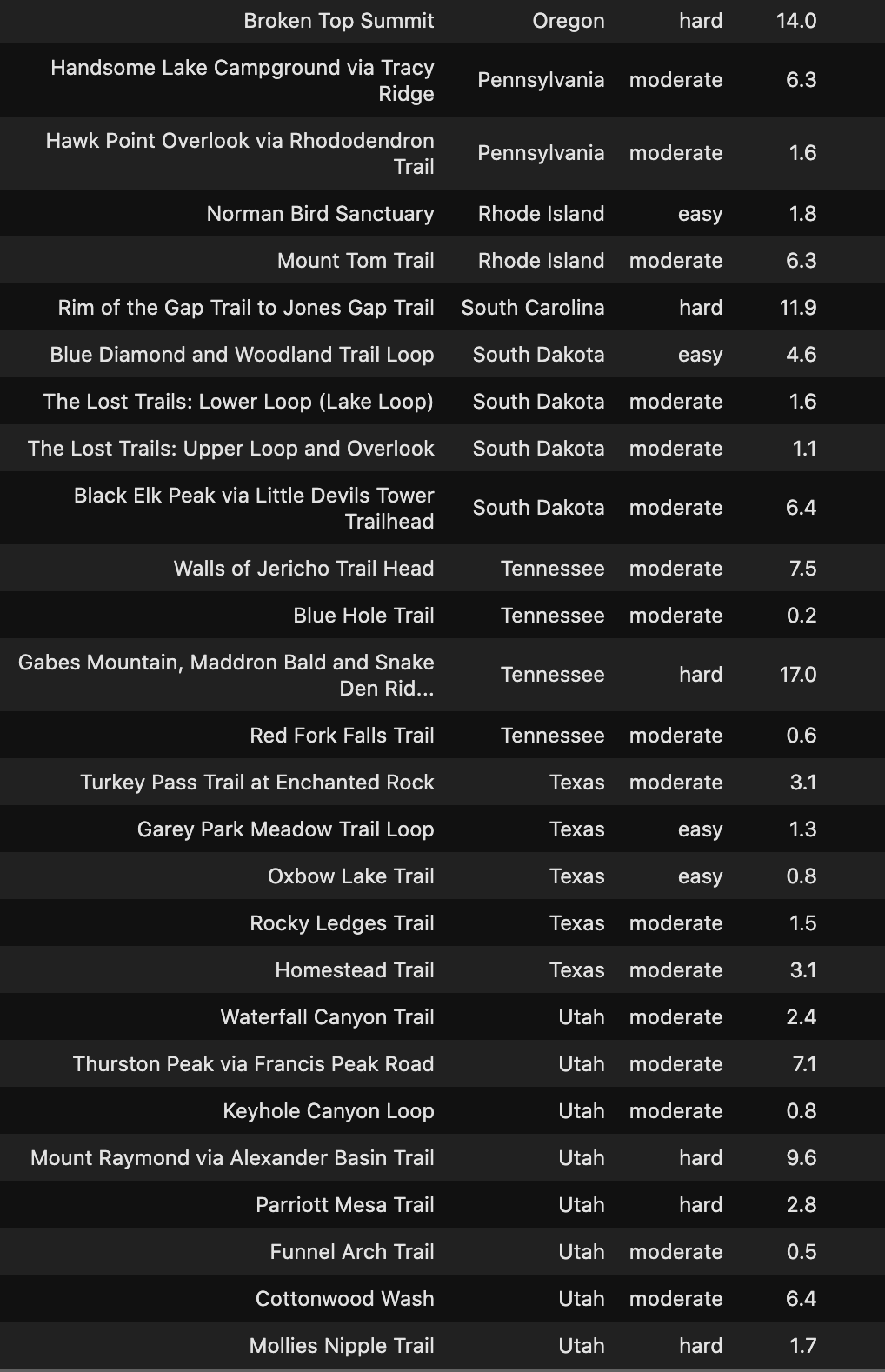
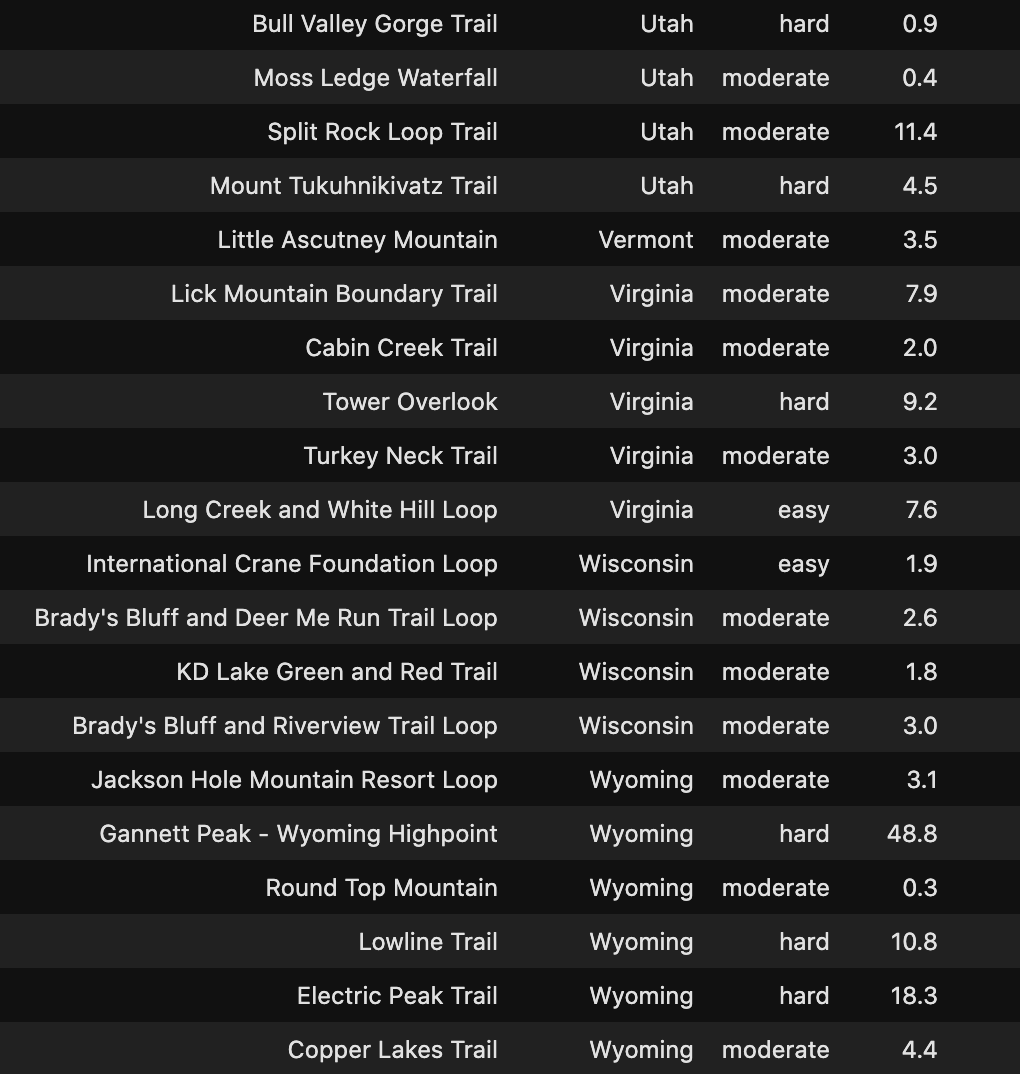
遠足徑 (Hike The Trails)
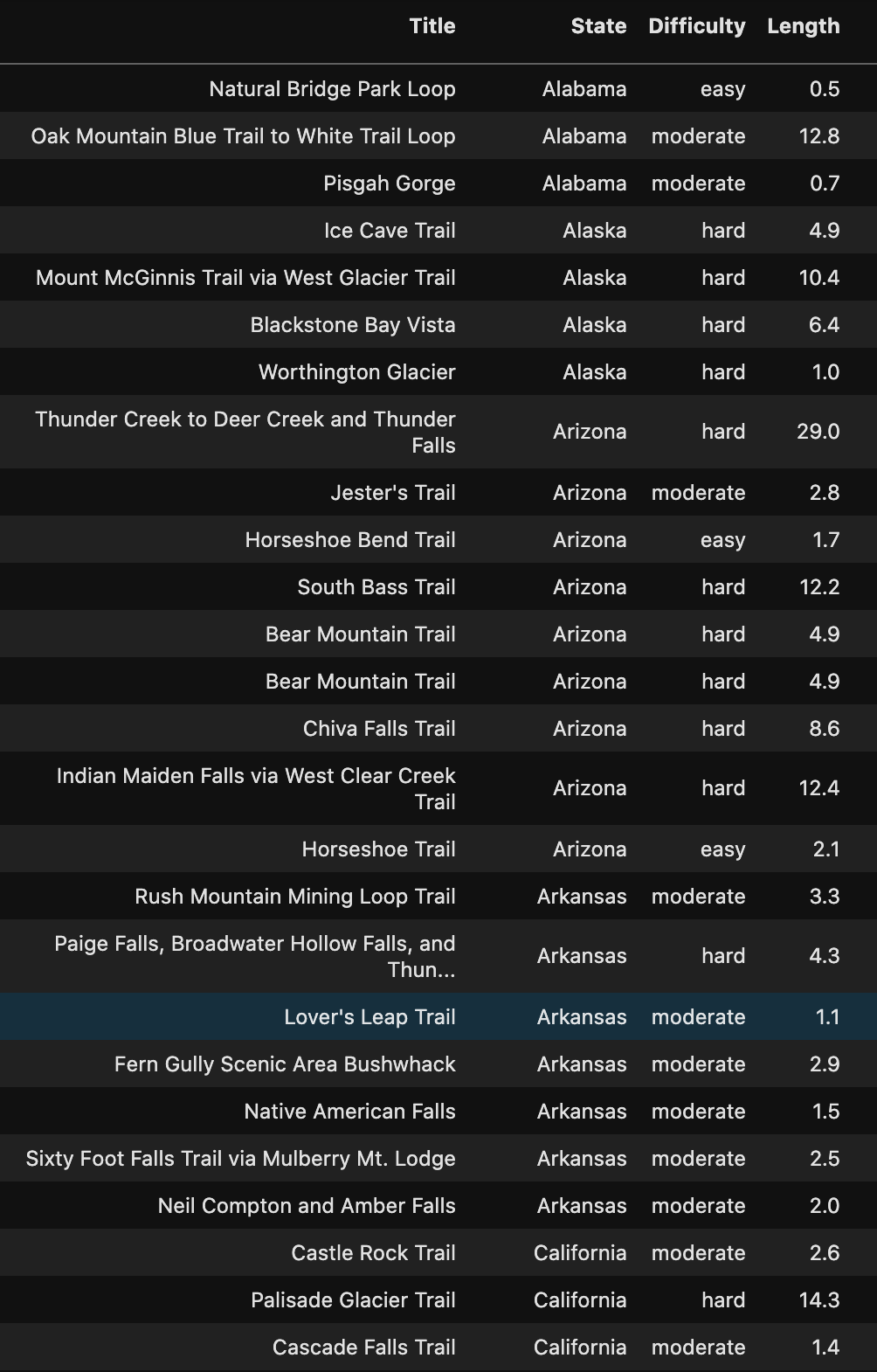
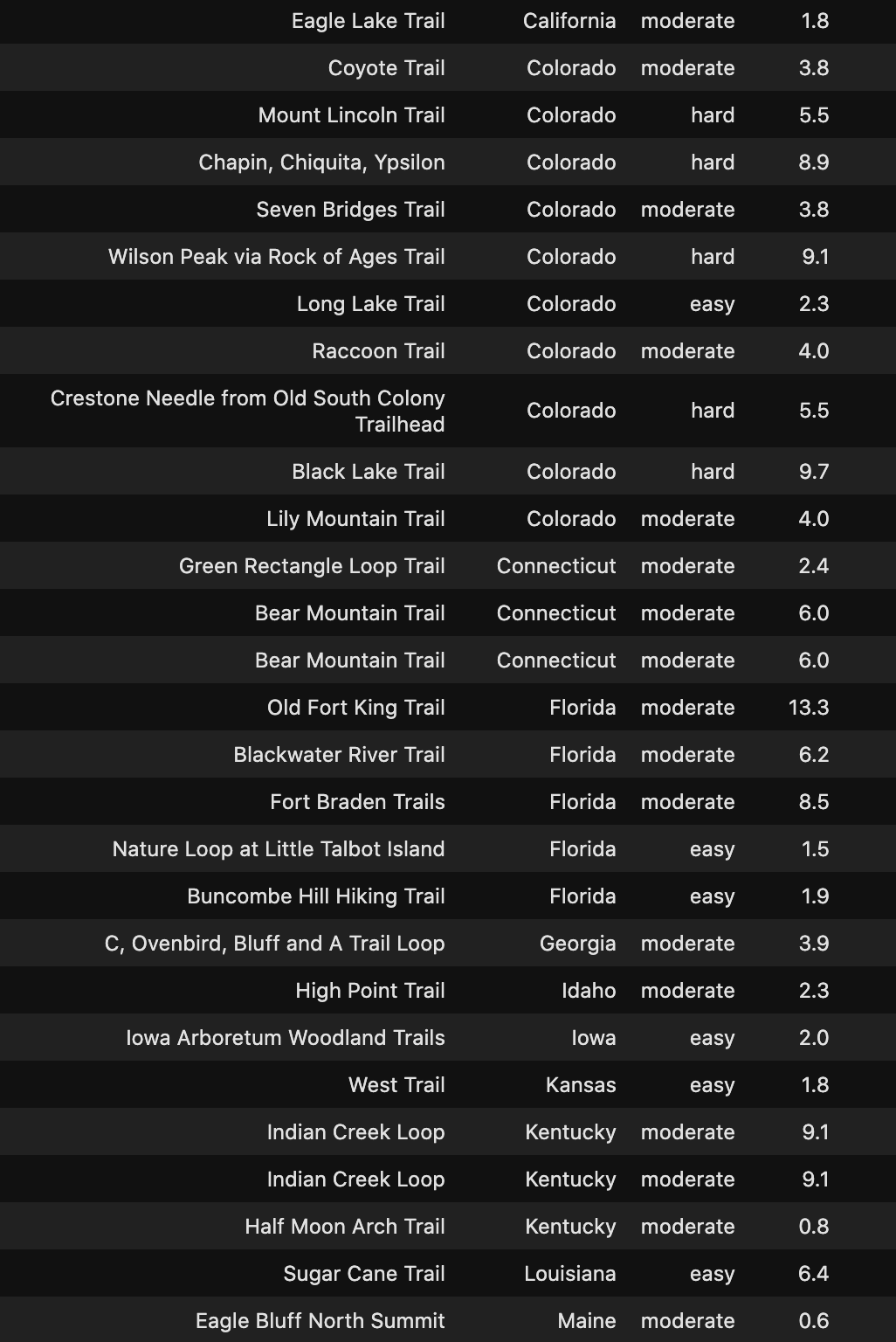
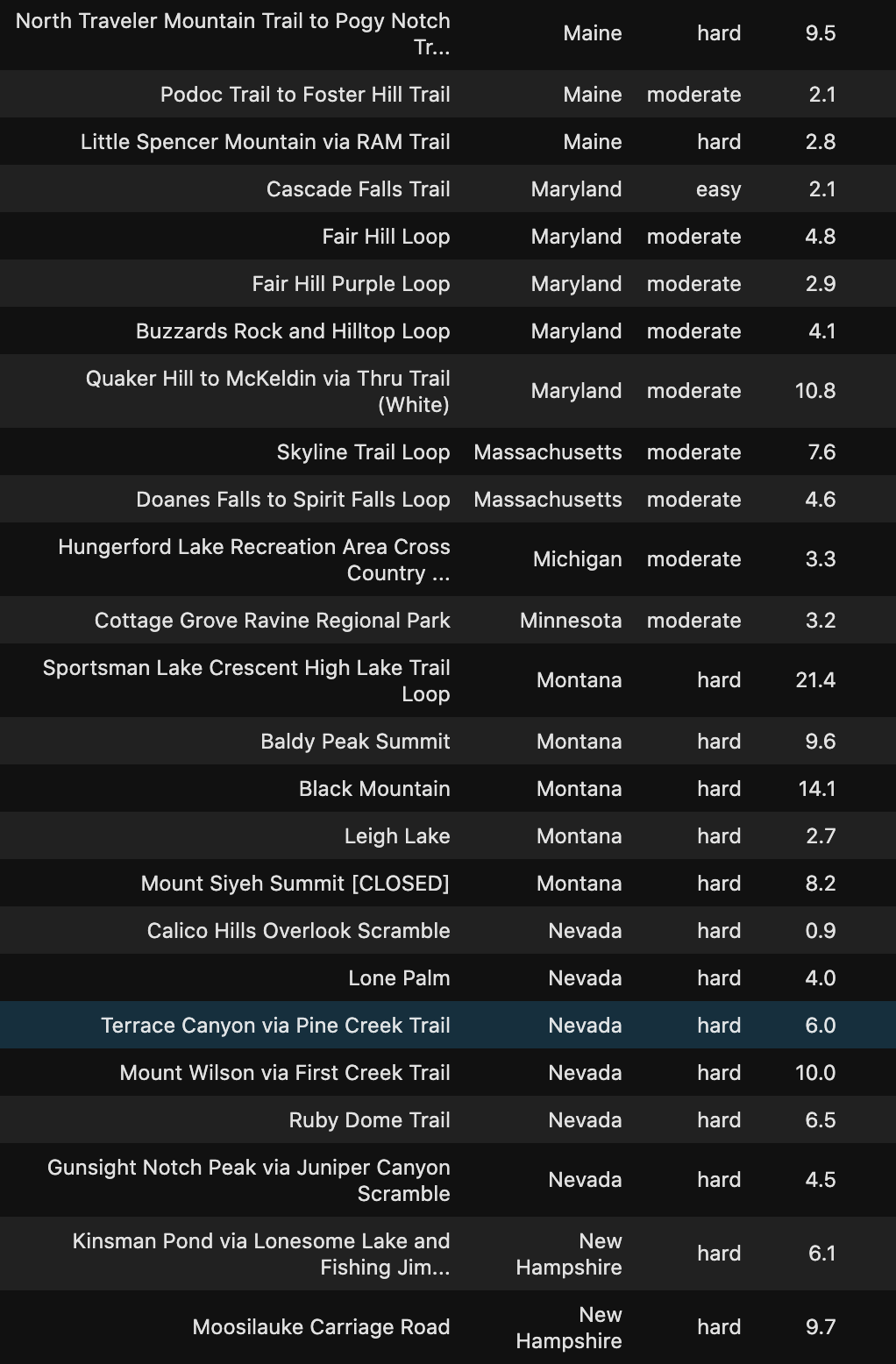
Check out the Hidden Gems in your State below!
在下面查看您所在州的隱藏寶石!
翻譯自: https://towardsdatascience.com/hidden-gems-finding-the-best-secret-trails-in-america-d9203e8ad073
美國隊長3:內戰
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388251.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388251.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388251.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
:MapHashMap)
Java入門第三季——Java中的集合框架(中):MapHashMap
)
【譯】 WebSocket 協議第八章——錯誤處理(Error Handling)

升級xcode5.1 iOS 6.0后以前的橫屏項目 變為了豎屏


Wait Event SQL*Net more data to client

1.3求根之牛頓迭代法

libzbar.a armv7

Alex Hanna博士:Google道德AI小組研究員

三位對我影響最深的老師

安全開發 | 如何讓Django框架中的CSRF_Token的值每次請求都不一樣

UNITY3D 腦袋頂血頂名

一個項目的整個測試流程

python度量學習_Python的差異度量

多個攝像機之間的切換

Kubernetes的共享GPU集群調度

django-celery定時任務以及異步任務and服務器部署并且運行全部過程

網頁視頻15分鐘自動暫停_在15分鐘內學習網頁爬取

Unity3D面試ABC

前嗅ForeSpider教程:創建模板
