網頁視頻15分鐘自動暫停
什么是網頁抓取? (What is Web Scraping?)
Web scraping, also known as web data extraction, is the process of retrieving or “scraping” data from a website. This information is collected and then exported into a format that is more useful for the user and it can be a spreadsheet or an API. Although web scraping can be done manually, in most cases, automated tools are preferred when scraping web data as they can be less costly and work at a faster rate.
Web抓取,也稱為Web數據提取,是從網站檢索或“抓取”數據的過程。 收集此信息,然后將其導出為對用戶更有用的格式,可以是電子表格或API。 盡管可以手動進行Web抓取 ,但是在大多數情況下,抓取Web數據時首選自動化工具,因為它們的成本較低且工作速度更快。
網站搜刮合法嗎? (Is Web Scraping Legal?)
The simplest way is to check the robots.txt file of the website. You can find this file by appending “/robots.txt” to the URL that you want to scrape. It is usually at the website domain /robots.txt. If all the bots indicated by ‘user-agent: *’ are blocked/disallowed in the robots.txt file, then you’re not allowed to scrape. For this article, I am scraping the Flipkart website. So, to see the “robots.txt” file, the URL is www.flipkart.com/robots.txt.
最簡單的方法是檢查網站的robots.txt文件。 您可以通過將“ /robots.txt”附加到要抓取的URL來找到此文件。 它通常位于網站域/robots.txt中。 如果robots.txt文件中阻止/禁止了“用戶代理:*”指示的所有漫游器,則不允許您抓取。 對于本文,我將抓取Flipkart網站。 因此,要查看“ robots.txt”文件,URL為www.flipkart.com/robots.txt。
用于Web爬網的庫 (Libraries used for Web Scraping)
BeautifulSoup: BeautifulSoup is a Python library for pulling data out of HTML and XML files. It works with your favourite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree.
BeautifulSoup:BeautifulSoup是一個Python庫,用于從HTML和XML文件中提取數據。 它與您最喜歡的解析器一起使用,提供了導航,搜索和修改解析樹的慣用方式。
Pandas: Pandas is a fast, powerful, flexible, and easy to use open-source data analysis and manipulation tool, built on top of the Python programming language.
Pandas:Pandas是一種快速,強大,靈活且易于使用的開源數據分析和處理工具,建立在Python編程語言之上。
為什么選擇BeautifulSoup? (Why BeautifulSoup?)
It is an incredible tool for pulling out information from a webpage. You can use it to extract tables, lists, paragraphs and you can also put filters to extract information from web pages. For more info, you can refer to the BeautifulSoup documentation
它是從網頁中提取信息的不可思議的工具。 您可以使用它來提取表,列表,段落,還可以放置過濾器以從網頁中提取信息。 有關更多信息,您可以參考BeautifulSoup 文檔。
刮Flipkart網站 (Scraping Flipkart Website)
from bs4 import BeautifulSoup
import requests
import csv
import pandas as pdFirst, we import the BeautifulSoup and the requests library and these are very important libraries for web scraping.
首先,我們導入BeautifulSoup和請求庫,這些對于Web抓取是非常重要的庫。
requests: requests, is one of the packages in Python that made the language interesting. requests is based on Python’s urllib2 module.
請求:請求是Python中使該語言有趣的軟件包之一。 請求基于Python的urllib2模塊。
req = requests.get("https://www.flipkart.com/search?q=laptops&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off&page=1") # URL of the website which you want to scrape
content = req.content # Get the contentTo get the contents of the specified URL, submit a request using the requests library. This is the URL of the Flipkart website containing laptops.
要獲取指定URL的內容,請使用請求庫提交請求。 這是包含筆記本電腦的Flipkart網站的URL。
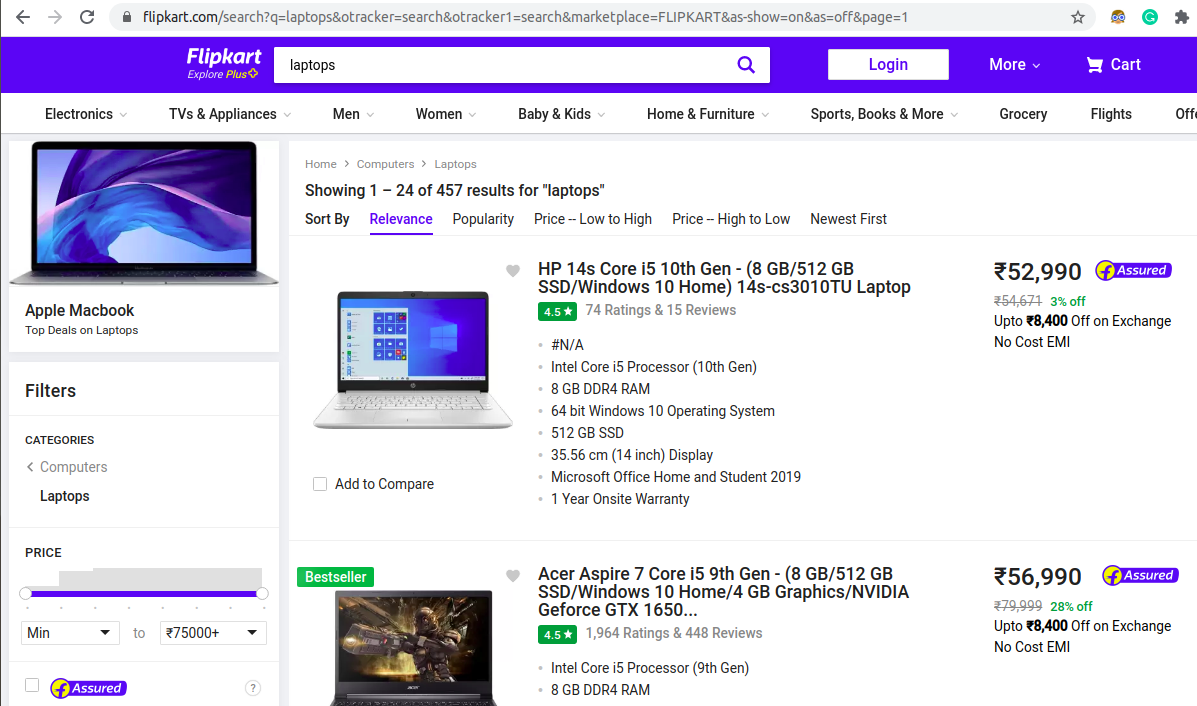
This is the Flipkart website comprising of different laptops. This page contains the details of 24 laptops. So now looking at this, we try to extract the different features of the laptops such as the description of the laptop (model name along with the specification of the laptop), Processor (Intel/AMD, i3/i5/i7/Ryzen3Ryzen5/Ryzen7), RAM (4/8/16 GB), Operating System (Windows/Mac), Disk Drive Storage (SSD/HDD,256/512/1TB storage), Display (13.3/14/15.6 inches), Warranty(Onsite/Limited Hardware/International), Rating(4.1–5), Price (Rupees).
這是由不同筆記本電腦組成的Flipkart網站。 此頁面包含24臺筆記本電腦的詳細信息。 因此,現在著眼于此,我們嘗試提取筆記本電腦的不同功能,例如筆記本電腦的描述(型號名稱以及筆記本電腦的規格),處理器(Intel / AMD,i3 / i5 / i7 / Ryzen3Ryzen5 / Ryzen7) ),RAM(4/8/16 GB),操作系統(Windows / Mac),磁盤驅動器存儲(SSD / HDD,256/512 / 1TB存儲),顯示器(13.3 / 14 / 15.6英寸),保修(現場/硬件/國際限量版),評分(4.1–5),價格 (盧比)。
soup = BeautifulSoup(content,'html.parser')
print(soup.prettify())<!DOCTYPE html>
<html lang="en">
<head>
<link href="https://rukminim1.flixcart.com" rel="dns-prefetch"/>
<link href="https://img1a.flixcart.com" rel="dns-prefetch"/>
<link href="//img1a.flixcart.com/www/linchpin/fk-cp-zion/css/app.chunk.21be2e.css" rel="stylesheet"/>
<link as="image" href="//img1a.flixcart.com/www/linchpin/fk-cp-zion/img/fk-logo_9fddff.png" rel="preload"/>
<meta content="text/html; charset=utf-8" http-equiv="Content-type"/>
<meta content="IE=Edge" http-equiv="X-UA-Compatible"/>
<meta content="102988293558" property="fb:page_id"/>
<meta content="658873552,624500995,100000233612389" property="fb:admins"/>
<meta content="noodp" name="robots"/>
<link href="https://img1a.flixcart.com/www/promos/new/20150528-140547-favicon-retina.ico" rel="shortcut icon">
....
....
</script>
<script async="" defer="" id="omni_script" nonce="7596241618870897262" src="//img1a.flixcart.com/www/linchpin/batman-returns/omni/omni16.js">
</script>
</body>
</html>Here we need to specify the content variable and the parser, which is the HTML parser. So now soup is a variable of the BeautifulSoup object of our parsed HTML. soup.prettify() displays the entire code of the webpage.
在這里,我們需要指定內容變量和解析器,即HTML解析器。 因此,湯是我們已解析HTML的BeautifulSoup對象的變量。 soup.prettify()顯示網頁的整個代碼。
Extracting the Descriptions
提取描述
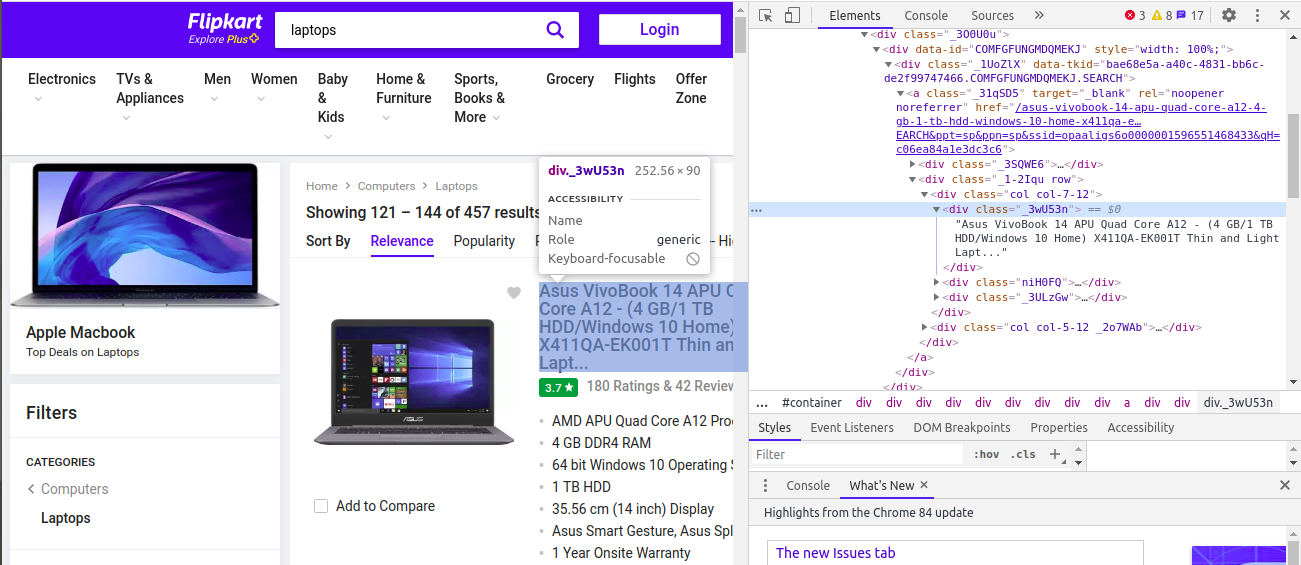
When you click on the “Inspect” tab, you will see a “Browser Inspector Box” open. We observe that the class name of the descriptions is ‘_3wU53n’ so we use the find method to extract the descriptions of the laptops.
當您單擊“檢查”選項卡時,將看到“瀏覽器檢查器框”打開。 我們觀察到描述的類名是'_3wU53n',因此我們使用find方法提取筆記本電腦的描述。
desc = soup.find_all('div' , class_='_3wU53n')[<div class="_3wU53n">HP 14s Core i5 10th Gen - (8 GB/512 GB SSD/Windows 10 Home) 14s-cs3010TU Laptop</div>,
<div class="_3wU53n">HP 14q Core i3 8th Gen - (8 GB/256 GB SSD/Windows 10 Home) 14q-cs0029TU Thin and Light Laptop</div>,
<div class="_3wU53n">Asus VivoBook 15 Ryzen 3 Dual Core - (4 GB/1 TB HDD/Windows 10 Home) M509DA-EJ741T Laptop</div>,
<div class="_3wU53n">Acer Aspire 7 Core i5 9th Gen - (8 GB/512 GB SSD/Windows 10 Home/4 GB Graphics/NVIDIA Geforce GTX 1650...</div>,
....
....
<div class="_3wU53n">MSI GP65 Leopard Core i7 10th Gen - (32 GB/1 TB HDD/512 GB SSD/Windows 10 Home/8 GB Graphics/NVIDIA Ge...</div>,
<div class="_3wU53n">Asus Core i5 10th Gen - (8 GB/512 GB SSD/Windows 10 Home/2 GB Graphics) X509JB-EJ591T Laptop</div>]Extracting the descriptions from the website using the find method-grabbing the div tag which has the class name ‘ _3wU53n’. This returns all the div tags with the class name of ‘ _3wU53n’. As class is a special keyword in python, we have to use the class_ keyword and pass the arguments here.
使用find方法從網站中提取描述-抓取div標簽,該標簽的類名為“ _3wU53n”。 這將返回所有類名稱為“ _3wU53n”的div標簽。 由于class是python中的特殊關鍵字,因此我們必須使用class_關鍵字并在此處傳遞參數。
descriptions = [] # Create a list to store the descriptions
for i in range(len(desc)):
descriptions.append(desc[i].text)
len(descriptions)24 # Number of laptops
['HP 14s Core i5 10th Gen - (8 GB/512 GB SSD/Windows 10 Home) 14s-cs3010TU Laptop',
'HP 14q Core i3 8th Gen - (8 GB/256 GB SSD/Windows 10 Home) 14q-cs0029TU Thin and Light Laptop',
'Asus VivoBook 15 Ryzen 3 Dual Core - (4 GB/1 TB HDD/Windows 10 Home) M509DA-EJ741T Laptop',
'Acer Aspire 7 Core i5 9th Gen - (8 GB/512 GB SSD/Windows 10 Home/4 GB Graphics/NVIDIA Geforce GTX 1650...',
....
....
'MSI GP65 Leopard Core i7 10th Gen - (32 GB/1 TB HDD/512 GB SSD/Windows 10 Home/8 GB Graphics/NVIDIA Ge...',
'Asus Core i5 10th Gen - (8 GB/512 GB SSD/Windows 10 Home/2 GB Graphics) X509JB-EJ591T Laptop']Create an empty list to store the descriptions of all the laptops. We can even access the child tags with dot access. So now iterate through all the tags and then use the .text method to extract only the text content from the tags. In every iteration append the text to the descriptions list. So after iterating through all the tags, the descriptions list will have the text content of all the laptops (which is the description of the laptop-model name along with specifications).
創建一個空列表來存儲所有筆記本電腦的描述。 我們甚至可以通過點訪問來訪問子標簽。 因此,現在遍歷所有標簽,然后使用.text方法僅從標簽中提取文本內容。 在每次迭代中,將文本添加到描述列表中。 因此,在遍歷所有標簽之后,描述列表將包含所有便攜式計算機的文本內容(這是便攜式計算機型號名稱的描述以及規格)。
Similarly, we apply the same approach to extract all the other features.
同樣,我們采用相同的方法提取所有其他功能。
Extracting the specifications
提取規格
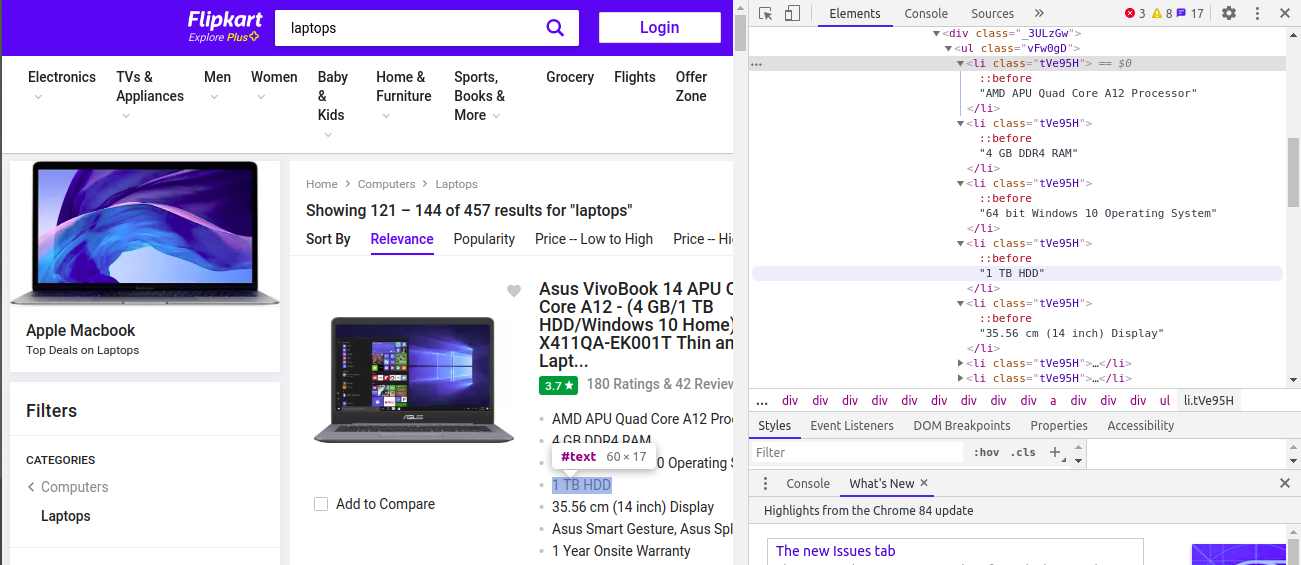
We observe that the various specifications are under the same div and the class names are the same for all those 5 features (Processor, RAM, Disk Drive, Display, Warranty).
我們注意到,所有這5個功能(處理器,RAM,磁盤驅動器,顯示,保修)的各種規格都在同一div下,并且類名相同。
All the features are inside the ‘li’ tag and the class name is the same for all which is ‘tVe95H’ so we need to apply some technique to extract the distinct features.
所有功能都在'li'標記內,并且所有類的名稱都相同'tVe95H',因此我們需要應用某種技術來提取不同的功能。
# Create empty lists for the features
processors=[]
ram=[]
os=[]
storage=[]
inches=[]
warranty=[]for i in range(0,len(commonclass)):
p=commonclass[i].text # Extracting the text from the tags
if("Core" in p):
processors.append(p)
elif("RAM" in p):
ram.append(p)
# If RAM is present in the text then append it to the ram list. Similarly do this for the other features as well elif("HDD" in p or "SSD" in p):
storage.append(p)
elif("Operating" in p):
os.append(p)
elif("Display" in p):
inches.append(p)
elif("Warranty" in p):
warranty.append(p)The .text method is used to extract the text information from the tags so this gives us the values of Processor, RAM, Disk Drive, Display, Warranty. So in the same way, we apply this approach to the remaining features as well.
.text方法用于從標記中提取文本信息,因此可以為我們提供處理器,RAM,磁盤驅動器,顯示,保修的值。 因此,以同樣的方式,我們也將這種方法應用于其余功能。
print(len(processors))
print(len(warranty))
print(len(os))
print(len(ram))
print(len(inches))24
24
24
24
24Extracting the price
提取價格
price = soup.find_all(‘div’,class_=’_1vC4OE _2rQ-NK’)
# Extracting price of each laptop from the website
prices = []
for i in range(len(price)):
prices.append(price[i].text)
len(prices)
prices24
['?52,990',
'?34,990',
'?29,990',
'?56,990',
'?54,990',
....
....
'?78,990',
'?1,59,990',
'?52,990']In the same manner, we extract the price of each laptop and add all the prices to the prices list.
以相同的方式,我們提取每臺筆記本電腦的價格,并將所有價格添加到價格列表中。
rating = soup.find_all('div',class_='hGSR34')
Extracting the ratings of each laptop from the website
ratings = []
for i in range(len(rating)):
ratings.append(rating[i].text)
len(ratings)
ratings37
['4.4',
'4.5',
'4.4',
'4.4',
'4.2',
'4.5',
'4.4',
'4.5',
'4.4',
'4.2',
....
....
'?1,59,990',
'?52,990']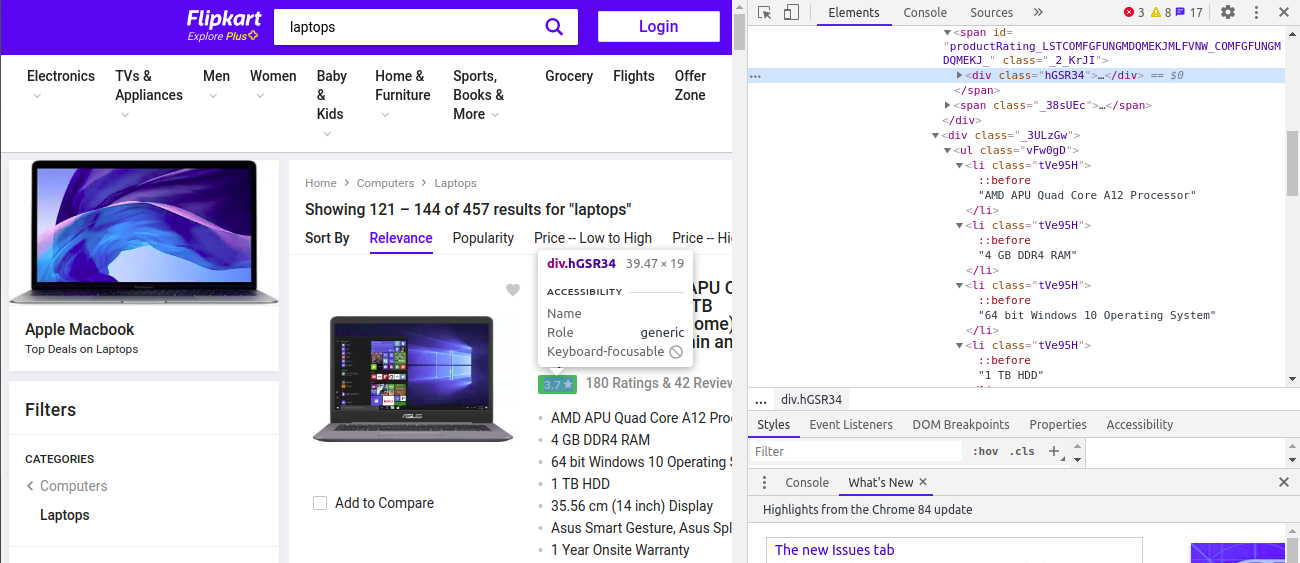
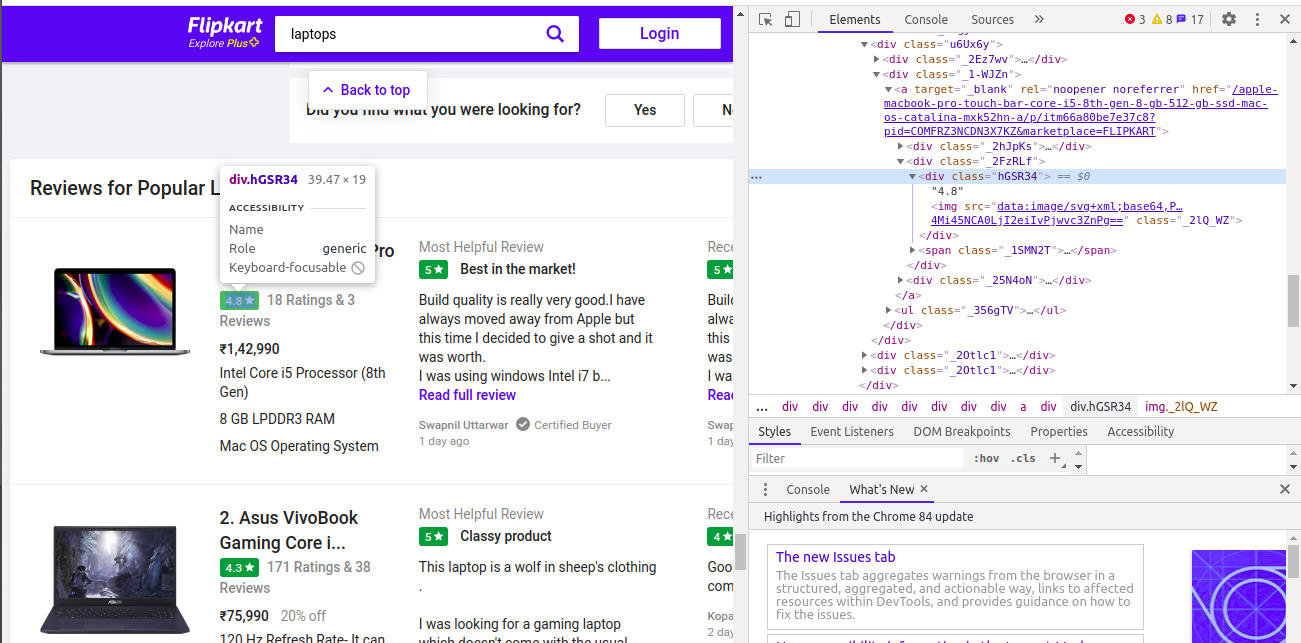
Here we are getting the length of the ratings to be 37. But what’s the reason behind it?
在這里,我們得到的評級長度為37。但是背后的原因是什么呢?
We observe that the class name for the recommended laptops is also the same as the featured laptops, so that’s why it’s extracting the ratings of recommended laptops as well.This is leading to an increase in the number of ratings. It has to be 24 but now it's 37!
我們發現推薦筆記本電腦的類別名稱也與特色筆記本電腦相同,這就是為什么它也提取推薦筆記本電腦的等級的原因,這導致等級數量增加。 它必須是24,但現在是37!
Last but not the least, merge all the features into a single data frame and store the data in the required format!
最后但并非最不重要的一點是,將所有功能合并到一個數據框中,并以所需的格式存儲數據!
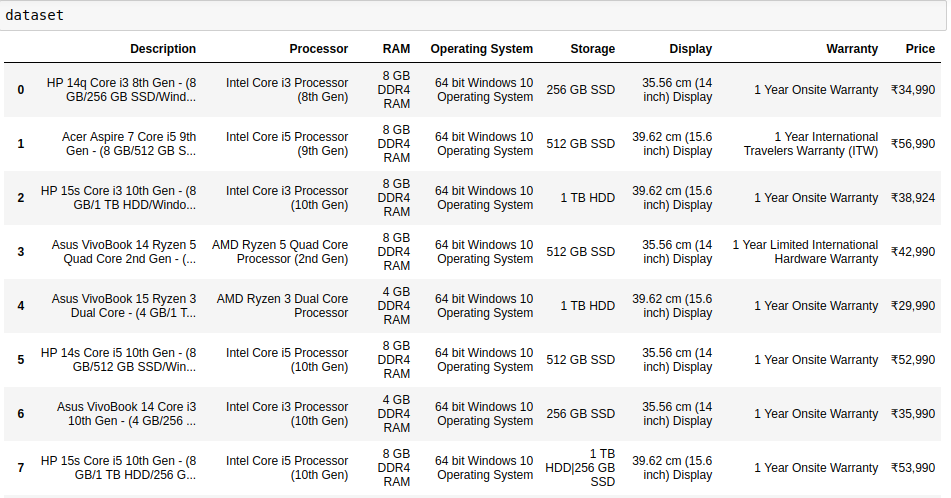
df = {'Description':descriptions,'Processor':processors,'RAM':ram,'Operating System':os,'Storage':storage,'Display':inches,'Warranty':warranty,'Price':prices}
dataset = pd.DataFrame(data = d) The final dataset
最終數據集
Saving the dataset to a CSV file
將數據集保存到CSV文件
dataset.to_csv('laptops.csv')Now we get the whole dataset into a CSV file.
現在,我們將整個數據集放入一個CSV文件中。
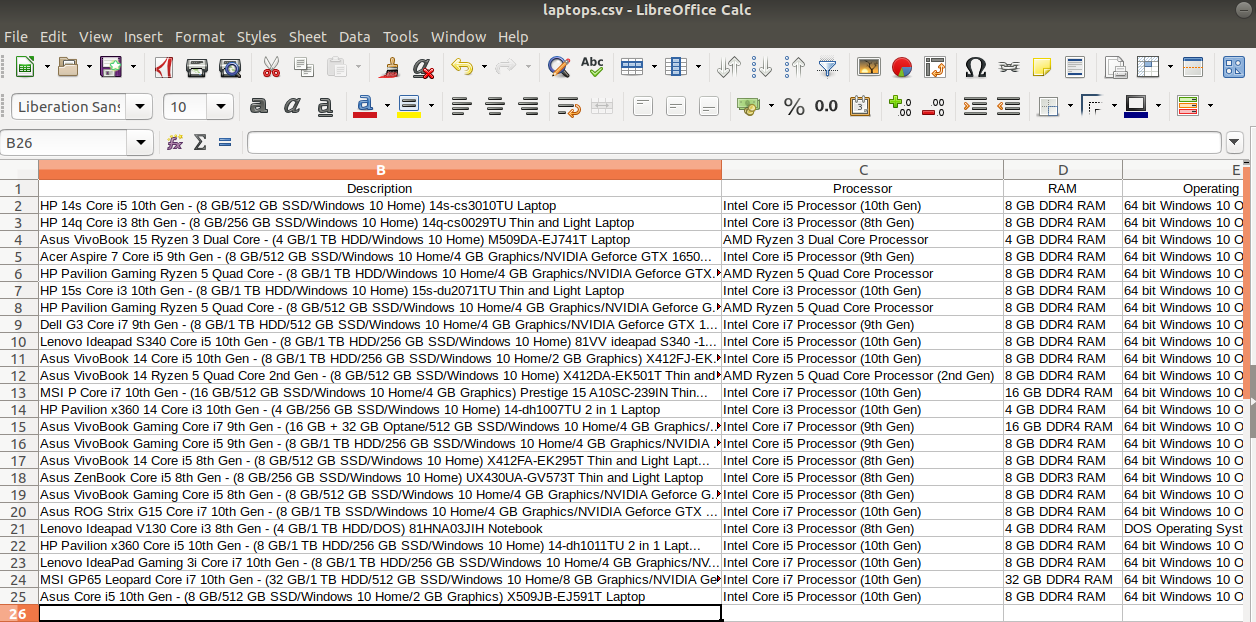
To verify it again, we read the downloaded CSV file in Jupyter Notebook.
為了再次驗證,我們在Jupyter Notebook中讀取了下載的CSV文件。
df = pd.read_csv('laptops.csv')
df.shape(24, 9)As this is a dynamic website, the content keeps on changing!
由于這是一個動態的網站,因此內容不斷變化!
You can always refer to my GitHub Repository for the entire code.
您可以始終參考我的GitHub存儲庫以獲取完整代碼。
Connect with me on LinkedIn here
在此處通過LinkedIn與我聯系
“For every $20 you spend on web analytics tools, you should spend $80 on the brains to make sense of the data.” — Jeff Sauer
“您每花20美元在網絡分析工具上,就應該花80美元在大腦上以理解數據。” —杰夫·索爾
I hope you found the article insightful. I would love to hear feedback to improvise it and come back with better content.
我希望您發現這篇文章很有見地。 我很想聽聽反饋以即興創作,并以更好的內容回來。
Thank you so much for reading!
非常感謝您的閱讀!
翻譯自: https://towardsdatascience.com/learn-web-scraping-in-15-minutes-27e5ebb1c28e
網頁視頻15分鐘自動暫停
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388234.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388234.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388234.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

Unity3D面試ABC

前嗅ForeSpider教程:創建模板

2.PHP利用PDO連接方式連接mysql數據庫

django 性能優化_優化Django管理員

3D場景中選取場景中的物體。
方法)
xpath之string(.)方法


canva怎么使用_使用Canva進行數據可視化項目的4個主要好處

如何利用Shader來渲染游戲中的3D角色



ai驅動數據安全治理_JupyterLab中的AI驅動的代碼完成

【Android】Retrofit 2.0 的使用

一個透明的shader
)
Mysql常用命令(二)

python中定義數據結構_Python中的數據結構—簡介

1206封裝電容在物料可靠性設計比較低

Java開發中 Double 和 float 不能直接運算

Unity3D 場景與C# Control進行結合
