13 集合
實現方法時,不同的數據結構會導致性能有很大差異。
?
13.1 集合接口
Java集合類庫將接口(interface)與實現(implementation)分離。
可以使用接口類型存放集合的應用,一旦改變了想法,可以輕松額使用另外一種不同的實現。
List<Integer> l = new ArrayList<>();
若想改為鏈表實現,只需上句為List<Integer> l = new LinkedList<>();
?
以Abstract開頭的類,如AbstractQueue,是為類庫實現者設計的。
如果想要實現自己的隊列類,會發現擴展AbstractQueue類要比實現Queue接口中的方法輕松的多。
?
集合類的基本接口是Collection接口
兩個基本方法:
public interface Collection<E>
{boolean add(E element);Iterator<E> iterator();
}iterator方法返回一個實現了Iterator接口的對象。
Iterator接口包含三個方法:
public interface Iterator<E>
{E next();boolean hasNext();void remove();
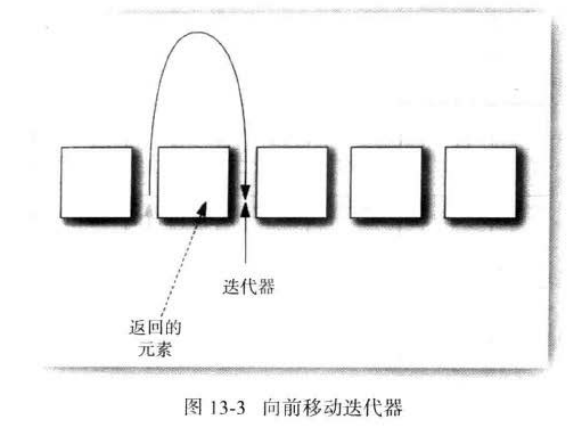
}Java迭代器被認為是在兩個元素之間的。
當調用next時,迭代器就越過下一個元素,并返回剛剛越過的那個元素的引用。
remove方法將會刪除上次調用next方法時返回的元素。
如果調用remove之前沒有調用next將是不合法的。
?
由于Collection與Iterator都是泛型接口,可以編寫任何集合類型實用方法。
?
?
?
?
?
?
13.2 具體的集合
Map結尾的類實現了Map接口;其他實現了Collection接口。
| ArrayList | 順序表 |
| LinkedList | 雙向鏈表 |
| ArrayDeque | 循環數組實現的雙端隊列 |
| HashSet | 沒有重復元素的無序集合 |
| TreeSet | 有序集 |
| EnumSet | 包含枚舉類型值的集 |
| LinkedHashSet | 可以記住元素插入順序的集 |
| PriorityQueue | 允許高效刪除最小元素的集合 |
| HashMap | ? |
| TreeMap | ? |
| EnumMap | 鍵值屬于枚舉類型 |
| LinkedHashMap | 可以記住K/V的添加次序 |
| WeakHashMap | 其值無用武之地后可以被垃圾回收器回收 |
| IdentityHashMap | 用==而不是equals比較鍵值的映射表 |
?
?
LinkedList:
interface ListIterator<E> extends Iterator<E>
{void add(E element);E previous();boolean hasPrevious();
}set方法用一個新元素取代調用next或previous方法返回的上一個元素。
ListIterator<String> iter = list.listIterator();
String oldValue = iter.next(); //returns first element
iter.set(newValue); //sets first element to newValue
?
當某個迭代器修改集合時,另一個迭代器對其進行遍歷,一定會出現混亂的狀況。
例如:一個迭代器指向另一個迭代器剛剛刪除的元素前面,現在這個迭代器就是無效的,并且不應該再使用。
鏈表迭代器的設計使它能夠檢測到這種修改。
如果迭代器發現它的集合被另一個迭代器修改了,或是被該集合自身的方法修改了,就會拋出一個ConcurrentModificationException。
例如:
ListIterator<String> iter1 = list.listIterator();
ListIterator<String> iter2 = list.listIterator();
iter1.next();
iter1.remove();
iter2.next(); //throws ConcurrentModificationException
?
鏈表不支持隨機訪問,但支持get(int index)。
get方法的小優化:如果index > size() / 2 就從列表尾端開始搜索元素。
for (int i = 0; i < list.size(); ++i)do something with list.get(i);//效率極低。出現此代碼說明用錯數據結構。nextIndex() ?previousIndex() ?返回索引值
list.listIterator(n)返回一個迭代器,這個迭代器指向索引為n的元素前面的位置。
?
?
ArrayList:
適用于get和set方法。
Vector類的所有方法都是同步的,如果由一個線程訪問Vector,代碼要在同步操作上耗費大量的時間。
ArrayList方法不是同步的。
?
散列集:
散列表(hash table)
散列表為每個對象計算一個整數,稱為散列碼(hash code)。
散列碼是由對象的實例域產生的一個整數。具有不同數據域的對象將產生不同的散列碼。
散列碼要能夠快速的計算出來。
?
在Java中,散列表用鏈表數組實現。每個列表被稱為桶(bucket)。
?
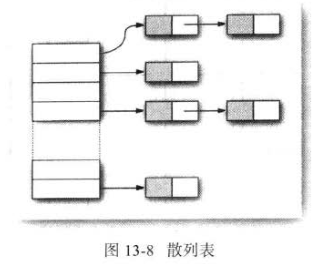
散列碼與桶數的余數是元素的桶的索引。
?
散列沖突(hash collision)
?
將桶數設置為預計元素個數的75%~150%,最好將桶數設置為一個素數,以防鍵的聚集。
標準庫使用的桶數是2的冪,默認值為16。為表大小提供的任何值都將被自動的轉換為2的下一個冪。
?
如果散列表太滿,就需要再散列(rehashed)。
創建一個雙倍桶數的表,將所有元素插入到這個新表中,然后丟棄原來的表。
裝填因子(load factor)決定何時對散列表進行再散列。
對大多數應用程序來說,裝填因子為0.75是比較合理的。
?
散列集迭代器依此訪問所有的桶,所以訪問順序是隨機的。
HashSet
?
樹集:
有序集合(sorted collection)
紅黑樹(red-black tree)
迭代器以排好序的順序訪問每個元素
?
添加元素到樹中要比添加到散列表中慢,但是,與將元素添加到數組或鏈表中相比還是快很多的。
TreeSet
?
對象的比較:
默認情況下,樹集假定插入的元素實現了Comparable接口。
public interface Comparable<T>
{int compareTo(T other);
}
a.compareTo(b); //相等返回0;a在前返回負值;b在前返回正值。使用Comparable接口定義排序有局限性。
對于一個給定的類,只能夠實現這個接口一次。
如果在一個集合中需要按照部件編號進行排序,在另一個集合中卻要按照描述信息進行排序,該如何?
如果一個類沒有實現Comparable接口,又該如何?
可通過將Comparator對象傳遞給TreeSet構造器來告訴樹集使用不同的比較方法。
pubic interface Comparator<T>
{int compare(T a, T b);
}如:
class ItemComparator implements Comparator<Item>
{public int compare(Item a, Item b){ return a.getDescription().compareTo(b.getDescription()); }
}
ItemComparator comp = new ItemComparator();
SortedSet<Item> sortByDescription = new TreeSet<>(comp);?
比較器是比較方法的持有器,不含數據,將這種對象稱為函數對象(function object)。
函數對象通常動態定義,即定義為匿名內部類的實例。
SortedSet<Item> sortByDescription = new TreeSet<>(new
Comparator<Item>()
{public int compare(Item a, Item b)return a.getDescription().compareTo(b.getDescription());
}?
?
隊列與雙端隊列:
ArrayDeque
?
優先級隊列:
priority queue
可以按照任意的順序插入,卻總是按照排序的順序進行檢索。
即,無論何時調用remove方法,總會獲得當前優先級隊列中最小的元素。
優先級隊列使用的是堆(heap)。
?
映射表:
Map key/value
HashMap ?TreeMap
三種視圖:
Set<K> keySet()
Collection<K> values()
Set<Map.Entry<K, V>> entrySet()
?
弱散列映射表:
WeakHashMap
如果一個值,對應鍵的唯一引用來自散列表條目時,這一數據結構將與垃圾回收器協同工作一起刪除鍵/值對。
?
連接散列集和連接映射表:
LinkedHashSet ?LinkedHashMap 用來記住插入元素項的順序。
?
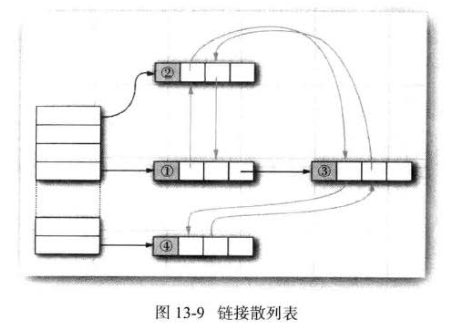
鏈接散列映射表將用訪問順序而不是插入順序,對映射表條目進行迭代。
?
標識散列映射表:
IdentityHashMap
鍵的散列不是用hashCode函數來計算的,而是用System.identityHashCode方法計算。
根據對象的內存地址來計算散列碼。
兩個對象進行比較時,IdentityHashMap使用的是”==”。
在實現對象遍歷算法(如對象序列化)時,這個類非常有用,可以用來跟蹤每個對象的遍歷狀況。
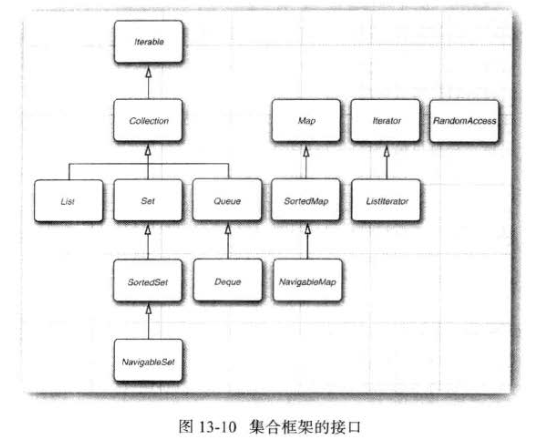
13.3 集合框架
框架(framework)是一個類的集,它奠定了創建高級功能的基礎。
框架包含很多超類,這些超類擁有非常有用的功能、策略和機制。
框架使用者創建的子類可以擴展超類的功能,而不必重新創建這些基本的機制。
例如Swing就是一種用戶界面的機制。
Java集合類庫構成了集合類的框架,它為集合的實現定義了大量的接口和抽象類,并且對其中的某些機制給予了描述,例如,迭代協議。
?
如果想要實現用于多種集合類型的泛型算法,或者想要增加新的集合類型,必須了解框架。
?
集合有兩個基本接口:Collection和Map
List是一個有序集合(ordered collection)
標記接口RandomAccess,檢測一個特定的集合是否支持隨機檢索。
?
集合接口有大量地方法,這些方法可以通過更基本的方法加以實現。
抽象類提供了許多這樣的例行實現。
如果實現了自己的集合類,就可能要擴展上面某個類,以便可以選擇例行操作的實現。
Java類庫支持下面幾種具體類:
?
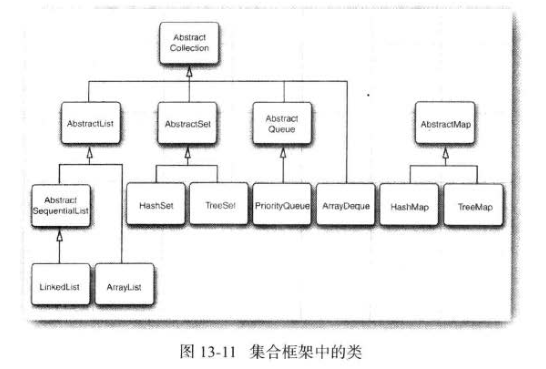
?
視圖與包裝器:
keySet方法返回一個實現Set接口的類對象,這個類的方法對原映射表進行操作。
這種集合稱為視圖。
?
1、輕量級包裝器
Arrays類的靜態方法asList將返回一個包裝了普通Java數組的List包裝器。
Card[] cardDeck = new Card[52];
List<Card> cardList = Arrays.asList(cardDeck);
改變數組大小的所有方法都會拋出一個UnsupportedOperationException異常。
?
List<String> names = Arrays.asList(“Amy”, “Bob”, “Carl”);
這個方法調用Collections.nCopies(n, anObject)方法。
?
2、子范圍視圖
subList方法
List group2 = staff.subList(10, 20); //含首不含尾
可以將任何操作應用于子范圍。
?
對于有序集和映射表,可以使用排序順序建立子范圍。
SortedSet接口聲明了3個方法:
SortedSet<E> subSet(E from, E to);
SortedSet<E> headSet(E to);
SortedSet<E> tailSet(E from);
?
SortedMap<K, V> subSet(K from, K to);
SortedMap<K, V> headSet(K to);
SortedMap<K, V> tailSet(K from);
?
3、不可修改視圖
Collections.unmodiffiableCollection
Collections.unmodifiableList
Collections.unmodifiableSet
Collections.unmodifiableSortedSet
Collections.unmodifiableMap
Collections.unmodifiableSortedMap
?
每個方法都定義于一個接口。
這些視圖對現有集合增加了一個運行時的檢查。
如果發現試圖對集合進行修改,就拋出一個異常。
?
4、同步視圖
如果由多個線程訪問集合,就必須確保集不會被意外的破壞。
類庫的設計者使用視圖機制來確保常規集合的線程安全,而不是實現線程安全的集合類。
Map<String, Employee> map = Collections.synchronizedMap(new HashMap<String, Employee>());
?
5、檢查視圖
List<String> sateStrings = Collections.checkedList(strings, String.class);
視圖的add方法將檢測插入的對象是否屬于給定的類。如果不是,則拋出ClassCastException。
?
?
批操作:
bulk operation
result.retainAll(a); //保存了交集
result.removeAll(b);
result.addAll(b);
?
集合與數組之間的轉換:
數組->集合:Arrays.asList包裝器
集合->數組:toArray()方法
staff.toArray();//返回的是Object數組,不能強制類型轉換;
staff.toArray(new String[0]);//返回的是String數組;
staff.toArray(new String[staff.size()]); //將元素一次復制到新數組中,并返回新數組
?
13.4 算法
泛型集合接口有一個很大的優點,即算法只需要實現一次。
?
排序:
Collections類中的sort方法。
這個方法假定元素實現了Comparable接口。
如果想采用其他方式對列表進行排序,可將Comparator對象作為第二個參數傳遞給sort方法。
降序:Collections.reverseOrder()方法
?
Java直接將所有元素轉入一個數組,并使用歸并排序的變體對數組進行排序,然后將排序后的序列復制回列表。
集合類庫中使用的歸并排序算法比快速排序要慢,快速排序是通用排序算法的傳統選擇。
歸并排序的優點,穩定,即不需要交換相同的元素。
?
排序的列表必須是可修改的,但不必是可以改變大小的。
·如果列表支持set,則是可修改的;
·如果列表支持add和remove方法,則是可改變大小的。
?
混亂:
Collections的shuffle算法,隨機的混排列表中元素的順序。
如果沒有實現RandomAccess接口,shuffle方法將元素復制到數組中,然后打亂數組元素的順序,最后再將打亂順序后的元素復制回列表。
?
二分查找:
i = Collections.binarySearch(c, element);
i = Collections.binarySearch(c, element, comparator);
?
二分查找對順序表有意義,如果對鏈表采用二分查找,則自動變為順序查找。
?
編寫自己的算法:
如果編寫自己的算法,應該盡可能的使用接口,而不要使用具體的實現。
?
13.5 遺留的集合
Java程序設計語言自問世以來就存在的集合:Hashtable ?Properties ?Vector ?Stack ?BitSet
?
Hashtable:
與HashMap類的作用一樣,擁有相同的接口。
Hashtable的方法也是同步的。
?
枚舉:
使用Enumeration接口對元素序列進行遍歷。
兩個方法:hasMoreElements和nextElement。
靜態方法Collections.enumeration將產生一個枚舉對象,枚舉集合中的元素。
?
屬性映射表:
property map
·鍵和值都是字符串;
·表可以保存到一個文件中,也可以從文件中加載
·使用一個默認的輔助表。
實現屬性映射表的類稱為Properties。
通常用于程序的特殊配置選項。
?
棧:
stack
?
位集:
BitSet類提供了一個便于讀取、設置或清除各個位的接口。
與C++中的bitset功能一樣。
?
?
?
?












)
)





