Spouts
Spout是Stream的消息產生源,Spout組件的實現可以通過繼承BaseRichSpout類或者其他Spout類來完成,也可以通過實現IRichSpout接口來實現。
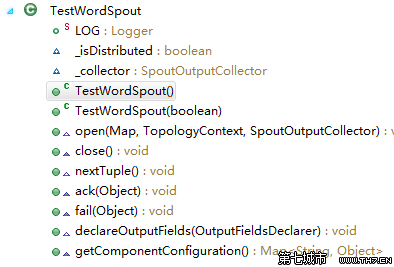
需要根據情況實現Spout類中重要的幾個方法有:
open方法
當一個Task被初始化的時候會調用此open方法。
一般都會在此方法中對發送Tuple的對象SpoutOutputCollector和配置對象TopologyContext初始化。
示例如下:
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {this._collector = collector;
}
此方法用于聲明針對當前組件的特殊的Configuration配置。
示例如下:
public Map<String, Object> getComponentConfiguration() { if(!_isDistributed) {Map<String, Object> ret = new HashMap<String, Object>(); ret.put(Config.TOPOLOGY_MAX_TASK_PARALLELISM, 3); return ret;10 11 } else {return null;}
}nextTuple方法
這是Spout類中最重要的一個方法。發射一個Tuple到Topology都是通過這個方法來實現的。
示例如下:
public void nextTuple() { Utils.sleep(100); final String[] words = new String[] {"twitter","facebook","google"}; final Random rand = new Random(); final String word = words[rand.nextInt(words.length)];collector.emit(new Values(word));
}
declareOutputFields方法
此方法用于聲明當前Spout的Tuple發送流。
Stream流的定義是通過OutputFieldsDeclare.declare方法完成的,其中的參數包括了發送的域Fields。
示例如下:
public void declareOutputFields(OutputFieldsDeclarer declarer) {declarer.declare(new Fields("word"));
}另外,除了上述幾個方法之外,還有ack、fail和close方法等;
Storm在監測到一個Tuple被成功處理之后會調用ack方法,處理失敗會調用fail方法;
這兩個方法在BaseRichSpout等類中已經被隱式的實現了。
——————————————————————————————————————————————
Bolts
Bolt類接收由Spout或者其他上游Bolt類發來的Tuple,對其進行處理。
Bolt組件的實現可以通過繼承BasicRichBolt類或者IRichBolt接口來完成。
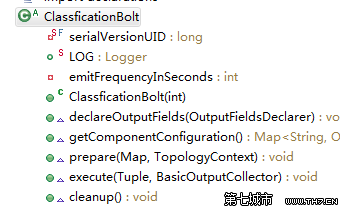
Bolt類需要實現的主要方法有:
prepare方法
此方法和Spout中的open方法類似,為Bolt提供了OutputCollector,用來從Bolt中發送Tuple。
Bolt中Tuple的發送可以在prepare方法中、execute方法中、cleanup等方法中進行,一般都是些在execute中。
示例如下:
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {this._collector = collector;
}
和Spout類一樣,在Bolt中也可以有getComponentConfiguration方法。
?示例如下:
public Map<String, Object> getComponentConfiguration() {Map<String, Object> conf = new HashMap<String, Object>();conf.put(Config.TOPOLOGY_TICK_TUPLE_FREQ_SECS, emitFrequencyInSeconds);return conf;
}
execute方法
這是Bolt中最關鍵的一個方法,對于Tuple的處理都可以放到此方法中進行。
具體的發送也是在execute中通過調用emit方法來完成的。
有兩種情況,一種是emit方法中有兩個參數,另一個種是有一個參數。
(1)emit有一個參數:此唯一的參數是發送到下游Bolt的Tuple,此時,由上游發來的舊的Tuple在此隔斷,新的Tuple和舊的Tuple不再屬于同一棵Tuple樹。新的Tuple另起一個新的Tuple樹。
(2)emit有兩個參數:第一個參數是舊的Tuple的輸入流,第二個參數是發往下游Bolt的新的Tuple流。此時,新的Tuple和舊的Tuple是仍然屬于同一棵Tuple樹,即,如果下游的Bolt處理Tuple失敗,則會向上傳遞到當前Bolt,當前Bolt根據舊的Tuple流繼續往上游傳遞,申請重發失敗的Tuple。保證Tuple處理的可靠性。
declareOutputFields方法
用于聲明當前Bolt發送的Tuple中包含的字段,和Spout中類似。
示例如下:
public void declareOutputFields(OutputFieldsDeclarer declarer) {declarer.declare(new Fields("obj","count","actualWindowLengthInSeconds"));
} ——————————————————————————————————————————————
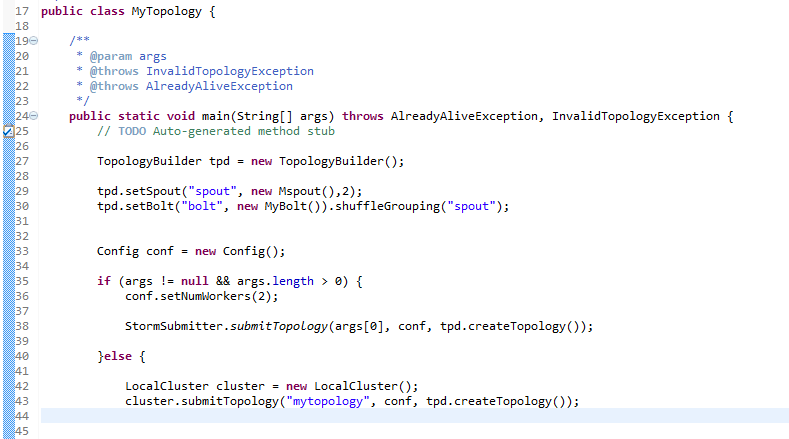
——————————————————————————————————————————————
(1)Storm提交后,會把代碼首先存放到Nimbus節點的inbox目錄下,之后,會把當前Storm運行的配置生成一個stormconf.ser文件放到Nimbus節點的stormdist目錄中,在此目錄中同時還有序列化之后的Topology代碼文件;
(2)在設定Topology所關聯的Spouts和Bolts時,可以同時設置當前Spout和Bolt的executor數目和task數目,默認情況下,一個Topology的task的總和是和executor的總和一致的。之后,系統根據worker的數目,盡量平均的分配這些task的執行。worker在哪個supervisor節點上運行是由storm本身決定的;
(3)任務分配好之后,Nimbes節點會將任務的信息提交到zookeeper集群,同時在zookeeper集群中會有workerbeats節點,這里存儲了當前Topology的所有worker進程的心跳信息;
(4)Supervisor節點會不斷的輪詢zookeeper集群,在zookeeper的assignments節點中保存了所有Topology的任務分配信息、代碼存儲目錄、任務之間的關聯關系等,Supervisor通過輪詢此節點的內容,來領取自己的任務,啟動worker進程運行;
(5)一個Topology運行之后,就會不斷的通過Spouts來發送Stream流,通過Bolts來不斷的處理接收到的Stream流,Stream流是無界的。
最后一步會不間斷的執行,除非手動結束Topology。
Topology中的Stream處理時的方法調用過程如下:
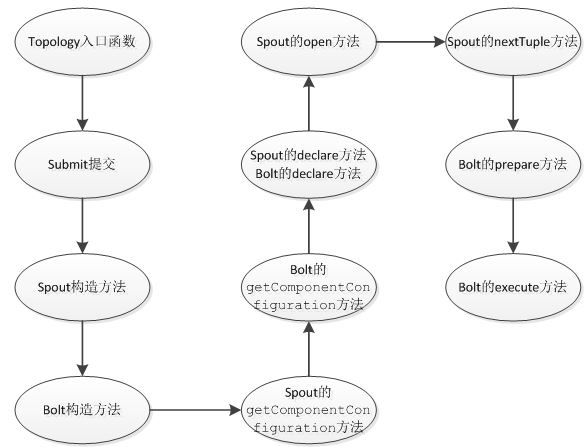
有幾點需要說明的地方:
(1)每個組件(Spout或者Bolt)的構造方法和declareOutputFields方法都只被調用一次。
(2)open方法、prepare方法的調用是多次的。入口函數中設定的setSpout或者setBolt里的并行度參數指的是executor的數目,是負責運行組件中的task的線程的數目,此數目是多少,上述的兩個方法就會被調用多少次,在每個executor運行的時候調用一次。相當于一個線程的構造方法。
(3)nextTuple方法、execute方法是一直被運行的,nextTuple方法不斷的發射Tuple,Bolt的execute不斷的接收Tuple進行處理。只有這樣不斷地運行,才會產生無界的Tuple流,體現實時性。相當于線程的run方法。
(4)在提交了一個topology之后,Storm就會創建spout/bolt實例并進行序列化。之后,將序列化的component發送給所有的任務所在的機器(即Supervisor節 點),在每一個任務上反序列化component。
(5)Spout和Bolt之間、Bolt和Bolt之間的通信,是通過zeroMQ的消息隊列實現的。
(6)上圖沒有列出ack方法和fail方法,在一個Tuple被成功處理之后,需要調用ack方法來標記成功,否則調用fail方法標記失敗,重新處理這個Tuple。
終止Topology
通過在Nimbus節點利用如下命令來終止一個Topology的運行:
bin/storm kill topologyName
kill之后,可以通過UI界面查看topology狀態,會首先變成KILLED狀態,在清理完本地目錄和zookeeper集群中的和當前Topology相關的信息之后,此Topology就會徹底消失


)
)








)

又稱為邏輯回歸分析,是分類和預測算法中的一種。通過歷史數據的表現對未來結果發生的概率進行預測。例如,我們可以將購買的概率設置為因變量,將用戶的)




