第四章 串
計算機上非數值處理的對象基本上是字符串數據。
在不同類型的應用中,字符串具有不同的特點,要有效的實現字符串的處理,必須選用合適的存儲結構。
?
4.1 串類型的定義
串 String?由零個或多個字符組成的有限序列。
s = 'a1a2a3...an' ??n >= 0
s 串名
用單引號擴起來的字符序列是串的值
n 串的長度
空串:零個字符的串
子串:串中任意個連續字符組成的子序列稱為該串的字串
位置:字符在序列中的序號稱為該字符在串中的位置
相等:當且僅當兩個串的值相等
?
串的邏輯結構與線性表極為相似,區別僅在于串的數據對象約束為字符集。
最小操作子集: 串賦值求串長 求子串 串比較 串連接
?
4.2 串的表示和實現
串的三種表示方法:
1、定長順序存儲表示
???用一組連續的存儲單元存儲串值的字符序列,此時串的最大長度被限定。
???兩種表示方法:
? ? ? ? 1以下標為0的數組分量存放串的實際長度 ?PASCAL
? ? ? ? 2在串值后面加一個不計入串長的結束標記字符,此時串長為隱含值 ?C語言中的'\0'
?
2、堆分配存儲表示
???在C語言中,存在一個稱之為“堆”的自由存儲區,由動態分配函數malloc()和free()管理。
???仍以一組連續的存儲單元存儲串值的字符序列,此時串的長度無限制。
???存儲空間在程序執行過程中動態分配。
?
3、塊鏈存儲表示
???塊大小的選擇
???頭指針 尾指針串長度
???設置尾指針的目的:聯結操作
?
4.3 串的模式匹配算法
串的模式匹配:字串的定位操作。
KMP算法: O(n+m)
改進:每當一趟的匹配過程中出現字符比較不等時,不需要回溯i指針,而是利用已經得到的“部分匹配”的結果將模式向右“滑動”盡可能遠的一段距離后,繼續進行比較。
?
匹配僅需從模式中第k個字符與主串中第i個字符繼續進行比較:此時模式中頭k-1個字符和主串中最后k-1個字符相同。
亦即 next[1, j-1] 這個串中,前后綴相同串的字符為 next[1, next[j] - 1],所以下一次比較的是next[j]個字符的不同。
next數組里存放的,相同前后綴子串,前子串位置的下一個位置坐標。
?
next[j] = k : 當模式中第j個字符失配時,重新進行比較的位置。
算法:
假設主串指針i = pos,模式串指針j = 1;
若si = pj,則i++, j++;
否則j = next[j], 繼續進行si 和pj 的比較。
如果 j = 0, 則 i++, j++, 繼續進行si和 pj的比較。
?
KMP算法的基礎是next函數值,僅和模式串本身有關。
求next[j + 1] 的方法:
next[1] = 0;
next[j] = k;
若 pk = pj,next[j + 1] = k +1;
若 pk!=pj,k = next[k],繼續進行pk和 pj的比較。若k = next[k] = 0,則next[j + 1] = 1。
?
?
i = 1;
next[1] = 0;
j = 0;
while (i < length)
{if (j == 0 || T[i] == T[j])i++; j++; next[i] = j;elsej = next[j];
}?
?
?
兩點說明:
1、簡單算法的時間復雜度雖然是O(n*m),但在一般情況下,其實際執行時間近似于O(n+m),因此至今仍被采用。
KMP算法僅當模式與主串之間存在許多“部分匹配”的情況下才顯得比簡單算法快得多。
KMP算法的最大特點:無需回溯,整個匹配過程,對主串僅需從頭至尾掃描一遍,這對處理從外設輸入的龐大文件很有效,可以邊讀入邊匹配,而無需回頭重讀。
2、next函數的修正算法 針對連續字符的改進
?
i = 1;
next[1] = 0;
j = 0;
while (i < length)
{if (j == 0 || T[i] == T[j])i++; j++;if (T[i] != T[j]) next[i] = j;else next[i ] = next[j];elsej = next[j];
}?
?
?
?
?
4.4 串操作應用舉例:
文本編輯
文本編輯程序是一個面向用戶的系統服務程序,文本編輯的實質是修改字符數據的形式或格式。
雖然各文本編輯程序的功能強弱不同,但基本操作是一致的,一般包括串的查找、插入、刪除等。
可以利用換頁符和換行符把文本劃分為若干頁,每頁有若干行。
把文本看成是一個字符串,稱為文本串。頁是文本串的子串,行是頁的子串。
?
為了管理文本的頁和行,在進入文本編輯的時候,編輯程序先為文本串建立相應的頁表和行表,即建立各子串的存儲映像。
頁表的每一項給出頁號和該頁的起始行號。
行表的每一項指示行號、起始地址和該字串的長度。
設立頁指針、行指針、字符指針,分別指向當前操作的頁、行、字符。
頁表和行表是遞增順序存儲的,對行表進行的插入或刪除運算需移動操作位置以后的全部表項。
Tip:由于訪問是以頁表和行表作為索引的,所以在作行和頁的刪除操作時,可以只對行表和頁表作相應的修改,不必刪除所涉及的字符,這樣可以節省時間。
?
?
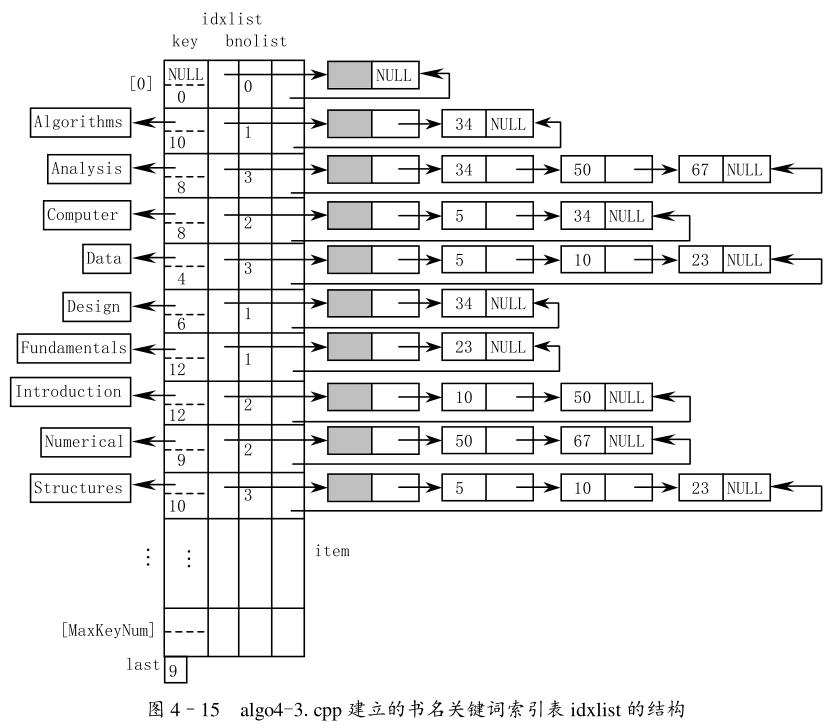
建立詞索引表
信息檢索。
可設定此索引表為按字典有序的線性表。
?
重復下列操作直至文件末尾:
1、從書目文件中讀取一個書目串;
2、從書目串中提取所有關鍵詞插入詞表;
3、對詞表中的每一個關鍵詞,在索引表中進行查找并作相應的插入操作。
?
需要一張常用詞表,不在常用詞表中的字符串為關鍵字。
索引表雖是動態生成,在生成過程中需頻繁進行插入操作,但考慮索引表主要為查找用,為了提高查找效率,宜采用順序存儲結構。
索引表內容:關鍵詞 + 書號索引。
書號索引采用鏈式存儲結構。
?











![[Objective-C語言教程]結構體(17)](http://pic.xiahunao.cn/[Objective-C語言教程]結構體(17))







——單例模式)