第九章?查找
另一種在實際應用中大量使用的數據結構--查找表。
所謂查找,即為在一個含有眾多的數據元素的查找表中找出某個“特定的”數據元素。
?
查找表 search table?是由同一類型的數據元素構成的集合。集合中的數據元素之間存在著完全松散的關系,故查找表非常靈便。
?
對查找表經常進行的操作:
>查詢某個元素是否在查找表中;
>檢索某個元素的各種屬性;
>插入
>刪除
?
靜態查找表 static search table:只包含查詢和檢索。
動態查找表 dynamic search table:包含查詢、檢索、插入、刪除。
?
關鍵字 Key 用于標識數據元素。
>主關鍵字 primary key:唯一的標識一個記錄。
>次關鍵字 secondary key:識別若干記錄。
?
查找 searching:
根據給定的某個值,在查找表中確定一個其關鍵字等于給定值的記錄。
?
由于表中數據元素之間僅存在“同屬一個集合”的松散關系,需在數據元素之間人為的加上一些關系,以便按某種規則進行查找,即以另一種數據結構來表示查找表。
>靜態查找表
>動態查找表
?
9.1 靜態查找表
靜態查找表有不同的表示方法,在不同的表示方法中,實現查找操作的方法也不同。
?
9.1.1 順序表的查找
以順序表或線性鏈表表示靜態查找表,則可用順序查找來實現。
順序查找 sequential search:
從表中最后一個記錄開始,逐個進行記錄關鍵字和給定值的比較,若相等,則查找成功;反之,直到第一個記錄都不相等,則表明表中沒有要查找的記錄,查找不成功。
?
Tip:在查找尾端設置哨兵,而免去每一步都要檢測整個表是否查找完畢,可節約一半的時間。哨兵的值等于所查找的關鍵字。
?
查找表性能度量:平均查找長度(Average Search Length)ASL

?
對記錄的查找概率不相等的查找表,若能預先得知每個記錄的查找概率,則應先對記錄的查找概率進行排序,使表中記錄按查找概率由小到大重新排列,以便提高查找效率。
在一般情況下,記錄的查找概率預先無法測定。
為了提高查找效率,可以在每個記錄中附設一個訪問頻度域,并使順序表中的記錄保持按訪問頻度非遞減有序排列,使得查找概率大的記錄在查找過程中不斷后移,以便在以后的逐次查找中減少比較次數。
或者在每次查找之后都將剛查找到的記錄直接移至表尾。
?
順序查找:
缺點:平均查找長度較長,當n很大時,查找效率低。
優點:簡單且適應面廣,對表結構無任何要求,無論記錄是否按關鍵字有序均可應用。
?
?
?
9.1.2 有序表的查找
?
折半查找 binary search:
先確定待查記錄所在的范圍(區間),然后逐步縮小范圍直到找到或找不到該記錄為止。
?
折半查找性能:
對任意的n,當n>50時,有下列近似結果
?
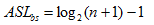
折半查找只適用于有序表,且限于順序存儲結構,對線性鏈表無法有效地進行折半查找。
?
?
Fibonacci查找:
根據Fibonacci序列的特點對表進行分割。
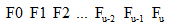
開始時,表中記錄個數比某個Fibonacci數小1,即
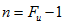

?
Fibonacci查找的平均性能比折半查找好,但最壞情況下的性能(雖然仍是O(logn))比折半查找差。
另一個優點,分割時只需進行加減運算。
?
插值查找:
根據給定值key來確定進行比較的關鍵字位置i的查找方案。
公式:
?
其中,high和low為最大關鍵字和最小關鍵字的下標。
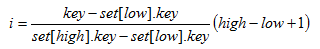
插值查找只適合于關鍵字均勻分布的表。在這種情況下,對表長較大的順序表,其平均性能比折半查找好。
?
9.1.3 靜態樹表的查找
當有序表中各記錄的查找概率不等時,折半查找性能未必最優。
描述查找過程的判定樹為何類二叉樹時,其查找性能最佳?
如果只考慮查找成功的情況,則查找性能最佳的判定樹是其帶權內路徑長度之和PH值取最小值的二叉樹。

稱PH值最小的二叉樹為靜態最優查找樹(Static Optimal Search Tree)。
構造靜態最優查找樹花費的時間代價高。
?
靜態樹表是把有序的靜態查找表根據數據被查找的概率生成一棵二叉樹。
?
介紹一種構造近似最優查找樹的有效算法。
次優查找樹(Nearly Optimal Search Tree):帶權內路徑長度PH值在所有具有同樣權值的二叉樹中近似為最小。
方法:選取第i個記錄作為根結點,然后分別對左右序列構造兩個次優查找樹作為i的左右子樹。
i滿足的條件:左序列權值和與右序列權值之和差值的絕對值最小。
?
由于在構造次優查找樹的過程中,沒有考察單個關鍵字的相應權值,則有可能出現被選為根的關鍵字的權值比與它相鄰的關鍵字的權值小。此時應作適當調整:選取鄰近的權值較大的關鍵字作次優查找樹的根結點。
例:關鍵字 A ?B ??C ?D ?E
????權值 ??1 ?30 ?2 ?29 ?3
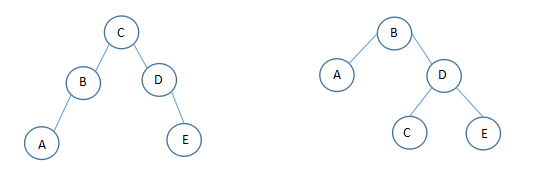
大量的實驗研究表明,次優查找樹和最優查找樹的查找性能之差僅為1%~2%,很少超過3%。
且構造次優查找樹的算法的時間復雜度為O(nlogn)。
?
?
9.1.4 索引順序表
有點像Skip List。
分塊查找又稱索引順序查找,這是順序查找的一種改進方法。
除表本身外,還需建立一個“索引表”。
索引表按關鍵字有序,表或者有序或者分塊有序。
分塊查找過程需分兩步進行:先確定待查記錄所在的塊(子表),然后在塊中順序查找。
?
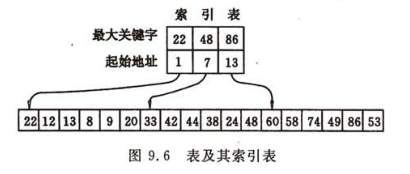
由于索引表按關鍵字有序,則確定塊的查找可以用順序查找,亦可用折半查找。而塊中記錄是任意排列的,則在塊中只能是順序查找。
分塊查找是順序查找和折半查找的簡單結合。
若都用順序,
?
9.2 動態查找表
表結構支持插入和刪除操作。
9.2.1 二叉排序樹和平衡二叉樹
二叉排序樹(Binary Sort Tree)或者是一棵空樹,或者是具有下列性質的二叉樹:
(1)若左子樹不空,則左子樹上所有結點均小于根結點;
(2)若右子樹不空,則右子樹上所有結點均大于根結點;
(3)左右子樹均為二叉排序樹。
?
?
二叉排序樹又稱二叉查找樹。
中序遍歷二叉排序樹可得到一個關鍵字的有序序列。
即一個無序序列可以通過構造一棵二叉排序樹而變成一個有序序列,構造樹的過程即為對無序序列進行排序的過程。
?
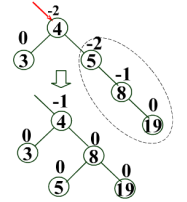
插入:每次插入的新結點都是二叉排序樹上新的葉子結點。
刪除: ?
- 若刪除點無孩子結點,直接刪除;
- 若刪除點只有一個孩子,則將其孩子替代其位置;
- 若刪除點有兩個孩子,兩種方法:
a)?鏈上左孩子,右孩子為左孩子的最右;或鏈上右孩子,左孩子為右孩子最左;
b)?用直接前驅替代,然后刪掉直接前驅;或用直接后繼替代,然后刪掉直接后繼。
?
?
平衡二叉樹(Balanced Binary Tree 或 Height-Balanced Tree)或者是一棵空樹,或者是具有如下性質的二叉樹:
它的左右子樹都是平衡二叉樹,且左右子樹的深度之差的絕對值不超過1。
?
平衡因子BF(Balance Factor):該結點左子樹的深度減去右子樹的深度。
平衡二叉樹所有結點的平衡因子只可能是-1,0,1。
只要二叉樹上有一個結點平衡因子的絕對值大于1,則該二叉樹就是不平衡的。
?
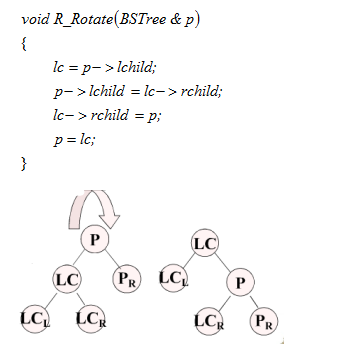
在平衡二叉排序樹BBST上插入一個新的數據元素e的遞歸算法如下:
- 若BBST為空樹,則插入一個數據元素為e的新結點作為BBST的根結點,樹的深度增1;
- 若e的關鍵字和BBST的根結點的關鍵字相等,則不進行插入;
- 若e的關鍵字小于BBST的根結點的關鍵字,而且在BBST的左子樹中不存在和e有相同關鍵字的結點,則將e插入在BBST的左子樹上,并且當插入之后的左子樹深度加1時,分別就下列不同情況處理之:
a)?BBST的根結點的平衡因子為-1,則將根結點的平衡因子更改為0,BBST的深度不變;?
b)?BBST的根結點的平衡因子為0,則將根結點的平衡因子更改為1,BBST的深度增1;
c)?BBST的根結點的平衡因子為1:
? ? ? ??若BBST的左子樹根結點的平衡因子為1,則需進行單向右旋平衡處理,并且在右旋處理之后,將根結點和其右子樹根結點的平衡因子更改為0,樹的深度不變;
? ? ? ??若BBST的左子樹根結點的平衡因子為-1,則需進行先向左、后向右的雙向旋轉平衡處理,并且在旋轉處理之后,修改根結點和其左右子樹根結點的平衡因子,樹的深度不變;
? - 若e的關鍵字大于BBST的根結點的關鍵字,而且在BBST的右子樹中不存在和e有相同關鍵字的結點,則將e插入在BBST的右子樹上,并且當插入之后的右子樹深度增加1時,分別就不同情況處理之。其處理操作和步驟3中所述相對稱。
??
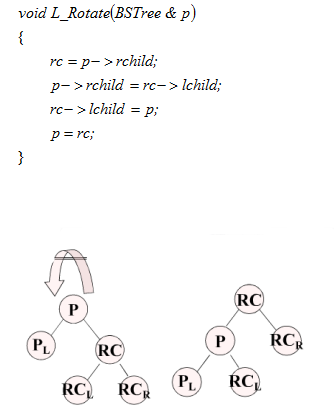
LL型:新結點Y插入到A的左子樹的左子樹上 ??左左->右
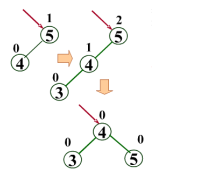
?
RR型:新結點Y插入到A的右子樹的右子樹上 ??右右->左
?
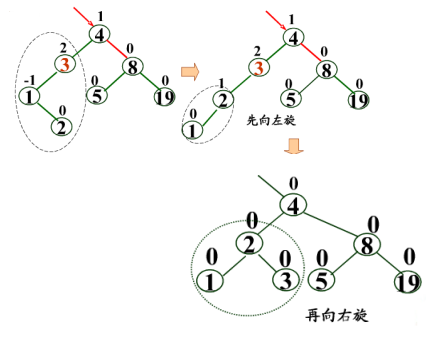
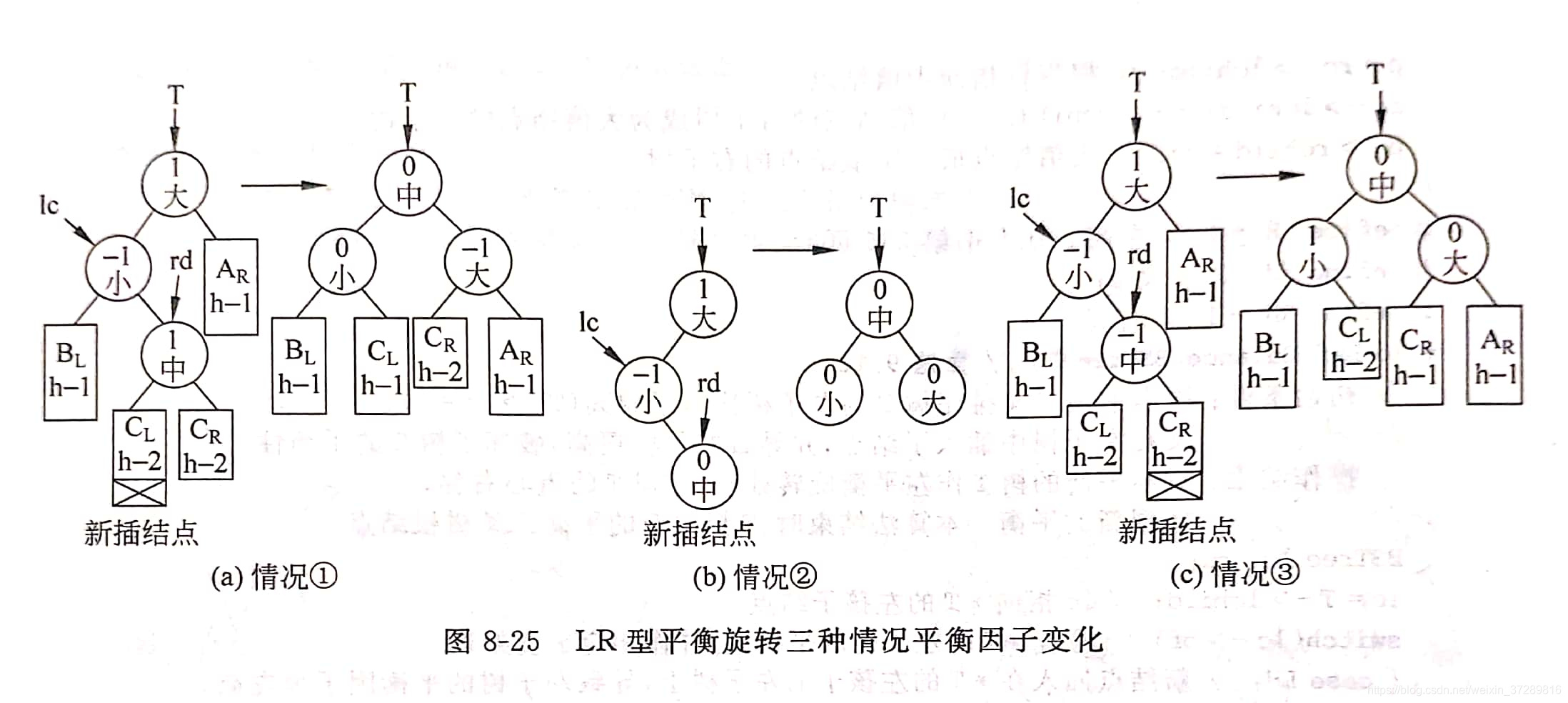
LR型:新結點Y插入到A的左子樹的右子樹上 ??左右->左右
????????????????????????
?
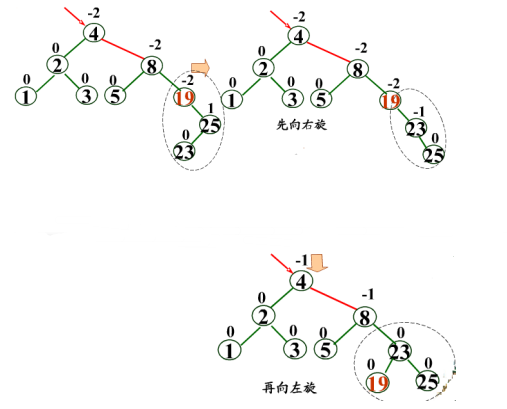
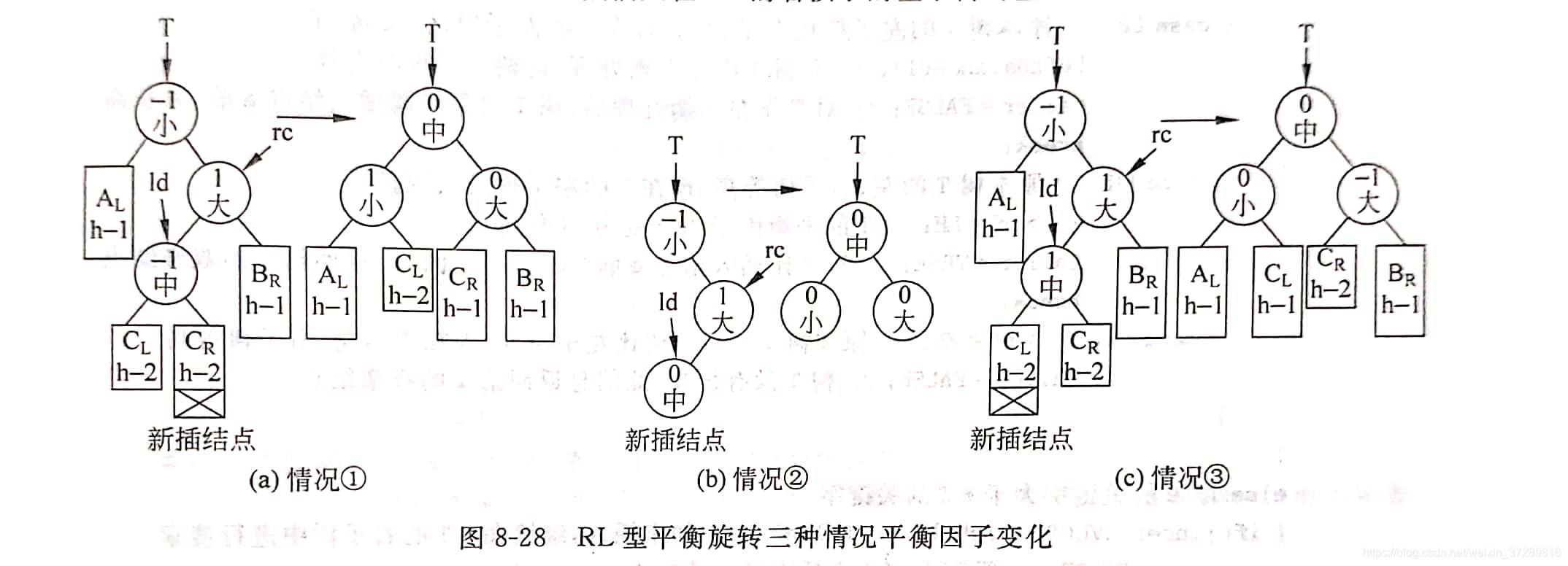
RL型:新結點Y插入到A的右子樹的左子樹上 ??右左->右左
?
?????????????????????????????
AVL樹的平衡化處理:通過調換根結點,使左右子樹的深度相等。
在一棵AVL樹上插入結點可能會破壞樹的平衡性,需要平衡化處理恢復平衡,且保持BST的結構性質。
若用Y表示新插入的結點,A表示離新插入結點Y最近的,且平衡因子變為2的祖先結點。
可用4種旋轉進行平衡化處理:
>LL型:新結點Y插入到A的左子樹的左子樹上 ??左左->右
>RR型:新結點Y插入到A的右子樹的右子樹上 ??右右->左
>LR型:新結點Y插入到A的左子樹的右子樹上 ??左右->左右
>RL型:新結點Y插入到A的右子樹的左子樹上 ??右左->右左
?
4種不平衡情況經調整都有如下特性:
- 成為A型,調整前的中值結點成為新的根結點,其平衡因子為0,其左、右孩子分別是小值、大值結點;
- 調整后,樹的深度和插入結點前一樣。
特性2說明,如果插入一個結點導致平衡二叉樹失衡,則只需在通向根結點的路徑上進行一次平衡調整。
?

?
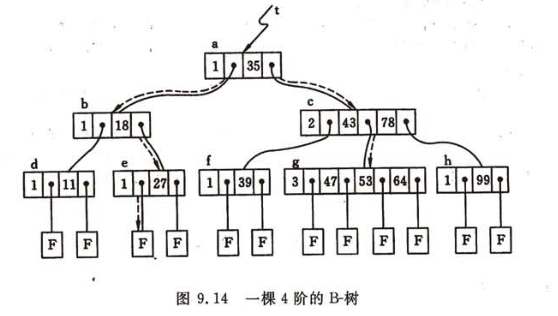
9.2.2 B-樹和B+樹

?
?
?
高為h的B-樹的最大結點數:
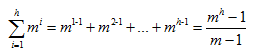
?
?
設m階B-樹的高為h,失敗結點位于h+1層,則關鍵字個數N最少到達多少?
1層1結點
2層2結點
3層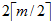
h層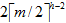
若樹中關鍵字有N個,則失敗結點數為N+1。

即:
給定m和N可以求出最大高度:m=199,N=1,999,999,可得h<=4;
給定m和h可以求出最少關鍵字數:m=3,h=4,N>=15。
?
m的選擇:查找關鍵字所用時間最少。
兩部分時間:從磁盤讀入結點所需時間,在結點中查找關鍵字所需時間。
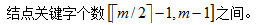
在B-樹上進行查找的過程是一個順指針查找結點和在結點的關鍵字中進行查找交叉進行的過程。
?
?
在含有N個關鍵字的B-樹上進行查找時,從根節點到關鍵字所在結點的路徑上涉及的結點數不超過
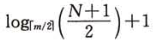
?
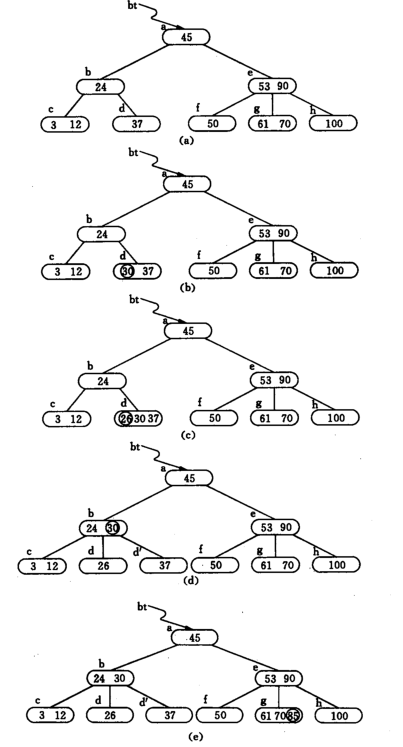
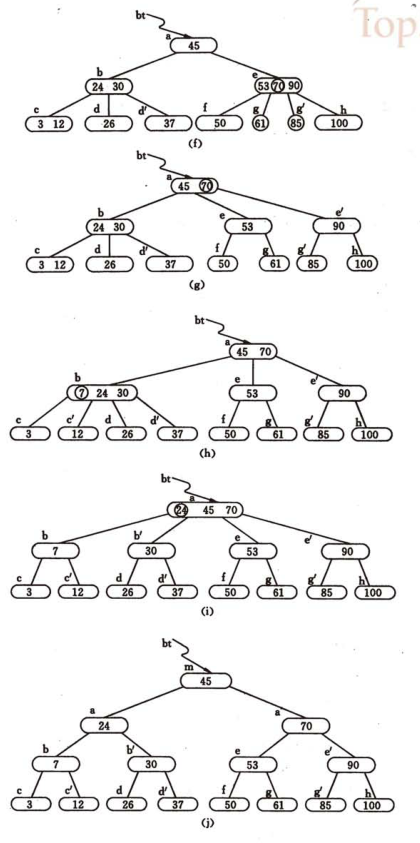
插入過程為自底向上分裂結點。
每次插入首先在最低層的某個非終端結點中添加一個關鍵字,如果該結點的關鍵字個數不超過m-1,則插入完成;否則分裂。
B樹索引,關鍵字后跟的是文件地址信息。

?
刪除,若不是最后一層非終端結點,則將其用左子樹的最右或者右子樹的最左來替換。然后刪除用于替換的結點。
否則分4種情況:
1、最后一層非終端結點,且為根結點,直接刪;
2、最后一層非終端結點,不為根結點。

?
B-樹主要用作文件的索引,因此它的查找涉及外存的存取。
查找包括兩步:1、在B-樹中找結點(磁盤);2、在結點中找關鍵字(內存)。
即,在磁盤上找到結點后,將其讀入內存,再在內存中進行關鍵字的查找。
?
?
?
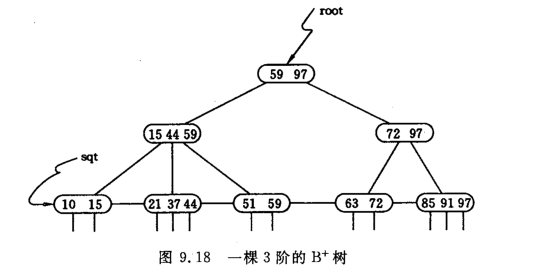
B+樹:B-樹的一種變形。
差異:
1、含k個關鍵字的結點必有k個子樹;
2、非終端結點僅具有索引作用,與記錄有關的信息均存放在葉結點中;
3、葉結點依關鍵字自小而大順序鏈接。
?
兩個頭指針:一個指向根結點,另一個指向關鍵字最小的葉子結點。
兩種查找方式:
1、沿著根結點隨機查找;
2、從最小關鍵字結點順序查找。
?
9.2.3 鍵樹
鍵樹又稱數字查找樹(Digital Search Tree):
它是一棵度大于等于2的樹,樹中的每個結點只含有組成關鍵字的符號。
若關鍵字是數值,則結點中只包含一個數位;若關鍵字是單詞,則結點中只包含一個字母字符。
?
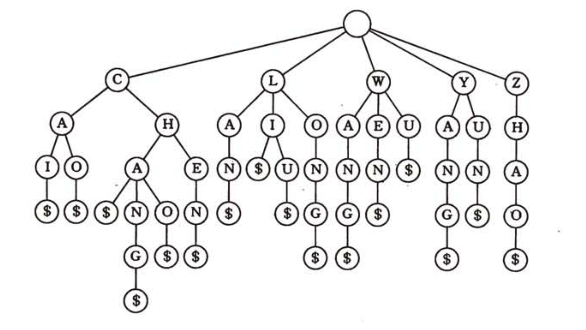
兩種存儲方式:1、孩子兄弟鏈;2、多重鏈表。
?
9.3 哈希表
9.3.1 什么是哈希表
前述查找結構中,關鍵字和相對存儲位置是隨機的,在查找過程中需要進行比較,是建立在比較基礎上。
沖突(collision):哈希值相同。
同義詞(synonym):哈希值沖突的關鍵字。
一般情況下,沖突只能盡可能減少,而不能完全避免。
?
哈希表:根據設定的哈希函數H(key)和處理沖突的方法將一組關鍵字映像到一個有限的連續的地址集(區間)上,并以關鍵字在地址集中的像作為記錄在表中的存儲位置,這種表便稱為哈希表。
這一映像過程稱為散列,所得存儲位置稱為哈希地址或散列地址。
?
9.3.2 哈希函數的構造方法
好的哈希函數:對于關鍵字集合,經哈希函數映像到地址集合中任何一個地址的概率是相等的,則稱此類哈希函數為均勻的(Uniform)哈希函數。
即使關鍵字經過哈希函數得到一個“隨機的地址”,以便使一組關鍵字的哈希地址均勻分布在整個地址區間中,從而減少沖突。
1、直接定址法
取關鍵字或關鍵字的某個線性函數值為哈希地址:
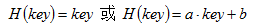
?
2、除留余數法
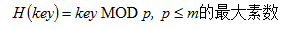
?
9.3.3 處理沖突的方法
1、開放定址法

?
2、再哈希法
對沖突的關鍵字用另一個哈希函數計算地址,直至不再沖突。
?
3、鏈地址法
?
4、建立一個公共溢出區
將沖突的關鍵字全部加入這個緩沖區中。

![[Objective-C語言教程]結構體(17)](http://pic.xiahunao.cn/[Objective-C語言教程]結構體(17))







——單例模式)









)