第五章 數組 和 廣義表
數組和廣義表可以看成是線性表在下述含義上的擴展:表中的數據元素本身也是一個數據結構。
?
5.1 數組的定義
n維數組中每個元素都受著n個關系的約束,每個元素都有一個直接后繼元素。
可以把二維數組看成是這樣一個定長線性表:它的每個數據元素也是一個定長線性表。
數組一旦定義,它的維數和維界就不再改變。因此,除了結構的初始化和銷毀之外,數組只能有存取元素和修改元素值的操作。
?
5.2 數組的順序表示和實現
次序約定:
1、列序為主序 column major order ?FORTRAN
2、行序為主序 row major order ????C
?
假設每個數據元素占L個存儲單元,則二維數組A中的任一元素aij的存儲位置可由下式確定:
LOC(i,j) = LOC(0,0) + (b2?* i + j)*L
LOC(i,j)是存儲位置 ?LOC(0,0)稱為基地址或基址
?
n維數組定位公式
Array[b1][b2]...[bn]
LOC(j1,j2,...,jn) = LOC(0,0,...,0) + (jn?+jn-1*bn+jn-2*bn-1*bn?+ ... +j2*b3*...*bn?+j1*b2*...*bn)*L
?
數組元素的存儲位置是其下標的線性函數。
由于計算各個元素存儲位置的時間相等,所以存取數組中任一元素的時間也相等,稱具有這一特點的存儲結構為隨機存儲結構。
? ??
5.3 矩陣的壓縮
如何存儲矩陣的元,使矩陣的各種運算能有效的進行。
二維數組可以存儲矩陣的元。
有的程序設計語言中還提供了各種矩陣運算。
?
壓縮存儲:為多個值相同的元只分配一個存儲空間;對零元不分配空間。
應用壓縮的兩種情況:
1、特殊矩陣:值相同的元素或者零元素在矩陣中的分布有一定規律;
2、稀疏矩陣。
?
對稱矩陣:aij= aji ?1 <= i,j <= n 稱為n階對稱矩陣
可以為每一對對稱元分配一個存儲空間,即將n2個元壓縮存儲到n(n+1)/2個元空間中
以行序為主序,存儲其下三角。
以一維數組sa[n(n+1)/2]作為n階對稱矩陣A的存儲結構,則sa[k]和矩陣元aij之間存在一一對應的關系:
K =?
i(i - 1)/2 - 1 + j ?當i>=j
j(j - 1)/2 - 1 + i ?當i < j ?//下標誰大誰除2,一維大是下三角內容,二維大是上三角內容
以上存法同樣適用于三角矩陣。
?
三角矩陣:上/下三角中的元均為常數c或0的n階矩陣(不含對角線)。
除了和對稱矩陣一樣,只存儲其上/下三角中的元之外,再加一個存儲常數c的存儲空間即可。
對角矩陣:所有非零元集中在以主對角線為中心的帶狀區域中。即除了主對角線上和直接在對角線上、下方若干條對角線上的元之外,所有其他的元皆為零。
?
以上特殊矩陣,非零元的分布都有一個明顯的規律,從而可以將其壓縮存儲到一維數組中,并找到每個非零元在一維數組中的對應關系。
?
稀疏矩陣:非零元較零元少,而且分布沒有一定規律。
稀疏因子:矩陣中非零元個數與全部個數之比。
通常認為稀疏因子小于等于0.05時稱為稀疏矩陣。
按照壓縮存儲的概念,只存儲稀疏矩陣的非零元。
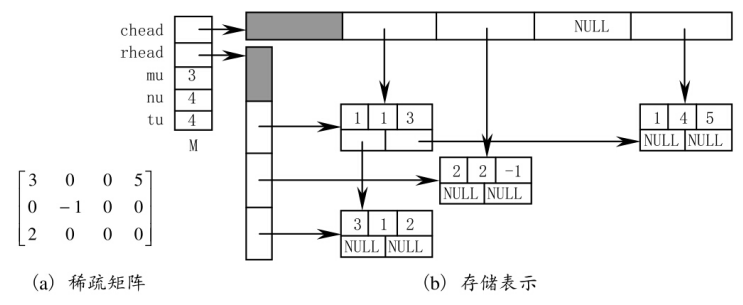
稀疏矩陣可由表示非零元的三元組?及其行列數唯一確定。
?
三種數據結構:三元組順序表、行邏輯鏈接的順序表、十字鏈表
1、三元組順序表:以行序為主序順序排列。
轉置算法:
1、將矩陣的行列值相互交換;
2、將每個三元組中的i和j相互調換;
3、重排三元組之間的次序;
方法一:找到原矩陣的列序來進行轉置。為了找到M的每一列中所有的非零元素,需要對其三元組表從第一行起整個掃描一遍。O(列數*非零元數)
方法二:先求出原矩陣每一列中非零元的個數,進而求得每一列第一個非零元在轉置矩陣中應有的位置。 O(列數+ 非零元數)
三元組順序表,又稱為有序的雙下標法。
特點:非零元在表中按行序有序存儲,便于進行依行順序處理的矩陣運算。
若需按行號存取某一行的非零元,則需從頭開始進行查找。
2、行邏輯鏈接的順序表:
在三元組順序表的基礎上,加入指示各行第一個非零元的順序表。
3、十字鏈表:
可以按任意順序輸入非零元素。
鏈式存儲結構,每個非零元用一個含5個域的結點表示,其中i、j、e分別表示該非零元所在的行、列和非零元的值,向右域right鏈接同一行中下一個非零元,向下域down鏈接同一列中下一個非零元。
同一行的非零元通過right域鏈接成一個線性鏈表,
同一列的非零元通過down域鏈接成一個線性鏈表,
每個非零元即是某個行鏈表中的一個結點,又是某個列鏈表中的一個結點整個矩陣構成一個十字交叉的鏈表。
用兩個分別存儲行鏈表的頭指針和列鏈表的頭指針的一維數組表示十字鏈表。
?
矩陣加法:4種情況:
(1)aij+?bij?
(2)aij??插入元素
(3)bij???插入元素
(4)aij+?bij = 0 刪除元素
?
從一個結點看,進行比較、修改指針所需的時間是一個常數;
整個運算過程是對A和B的十字鏈表逐行掃描,其循環次數主要取決于A和B矩陣中非零元素的個數ta和tb,由此算法時間復雜度為O(ta + tb)。
?
5.4廣義表
廣義表是線性表的推廣,列表 lists
廣泛地用于人工智能等領域的表處理語言LISP語言,把廣義表作為基本的數據結構,就連程序也表示為一系列的廣義表。
廣義表一般記作
LS = (a1,a2,...,an?)
LS是廣義表的名稱,n是它的長度。
廣義表中的元素可以是單個元素,也可以是廣義表,分別稱為廣義表的原子和子表。
廣義表的定義是一個遞歸的定義。
當廣義表非空時,稱第一個元素為LS的表頭(Head),其余元素組成的表是LS的表尾(Tail)。
任何非空列表其表頭可能是原子,也可能是列表,但其表尾必定為列表。
?
5.5 廣義表的存儲結構
由于廣義表的數據元素可以是原子,也可以是列表,因此難以用順序存儲結構表示,通常采用鏈式存儲結構,每個數據元素可用一個結點表示。
?
需要兩種結構的結點:
一種是表結點,用以表示列表;
標志域 + 表頭指針域 + 表尾指針域
一種是原子結點,用以表示結點。
標志域 + 值域
兩種方式:
?
enum ElemTag {ATOM,LIST};
typedef struct GLNode
{elemTag tag;union{AtomType atom;struct{GLNode *hp, *tp;}ptr;};
}*GList;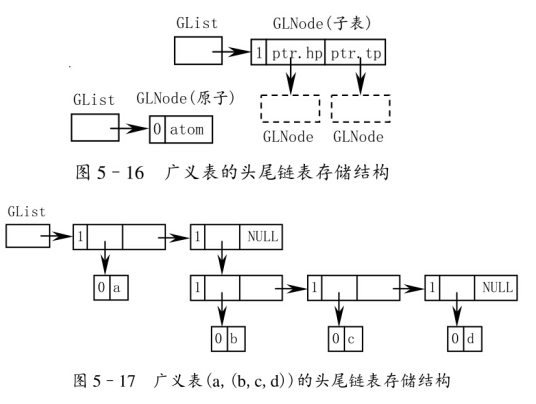
?
?
enum ElemTag {ATOM,LIST};
typedef struct GLNode1
{elemTag tag;union{AtomType atom;GLNode1 *hp;};GLNode1 *tp;
}*GList;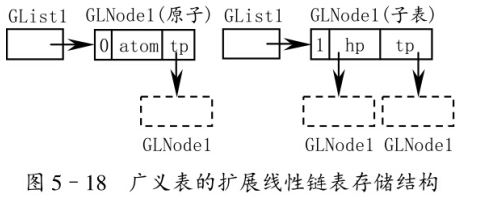
?
?
?
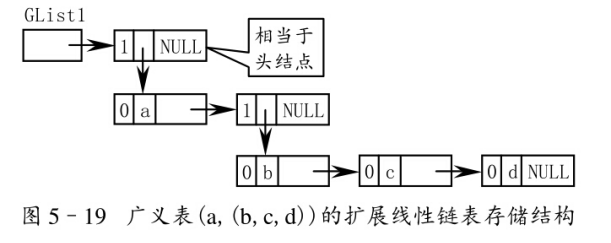
第一種結構:一個列表由表頭和表尾組成,表頭是一個表,表尾是另一個表。
第一種結構不直觀,建議采用第二種結構!
第二種結構:一個列表由表頭和表尾組成,表頭是原子或列表,表尾是原子或列表。
?
5.7 廣義表的遞歸算法
在對問題進行分解、求解過程中得到的是和原問題性質相同的子問題。
分治法(Divide and Conquer)進行遞歸算法的設計。
遞歸定義由基本項和歸納項兩部分組成。
基本項:描述一個或幾個遞歸過程的終結狀態。
歸納項:描述了如何實現從當前狀態到終結狀態的變化。
?
在設計遞歸函數時
(1)首先應書寫函數的首部和規格說明,嚴格定義函數的功能和接口;
(2)對函數中的每一個遞歸調用都看成是一個簡單的操作,只要接口一致,必能實現規格說明中定義的功能,切忌想的太深太遠。
?
?








![[Objective-C語言教程]結構體(17)](http://pic.xiahunao.cn/[Objective-C語言教程]結構體(17))







——單例模式)


