引言
隨著網絡應用的不斷發展,在linux系統中對應用層網絡管控的需求也日益增加,而傳統的iptables、firewalld等工具難以針對應用層進行網絡管控。因此需要一種創新的解決方案來提升網絡應用的可管理性。
本文將探討如何使用eBPF技術構建一種應用層網絡管控解決方案,為linux系統上的網絡管控帶來一種新的可能。
相關技術介紹
eBPF
eBPF(Extended Berkeley Packet Filter)是一種在Linux內核中執行安全、可編程的字節碼的技術。它最初是作為傳統的Berkeley Packet Filter(BPF)的擴展而引入的,用于網絡數據包過濾和分析。然而,隨著時間的推移,eBPF已經演變成一種通用的可編程框架,不僅可以用于網絡管控,還可以應用于系統跟蹤、安全監控、性能分析等領域。
eBPF具有靈活性和可擴展性,通過編寫自定義的eBPF程序,開發人員可以根據特定的需求實現各種功能。同時,eBPF還支持動態加載和卸載,使得運行時可以根據需要加載不同的eBPF程序,而無需重新編譯內核。
eBPF的另一個重要特點,那就是它的安全性。eBPF的字節碼在內核中執行之前,會經過嚴格的驗證和限制,以確保它不會對系統的穩定性和安全性造成破壞。這種安全性保證了BPF的可編程性不會成為潛在的安全漏洞。
由于eBPF的這些特性,使其成為現在Linux系統上最炙手可熱的一項技術。例如,開源容器網絡方案Cilium、開源Linux動態跟蹤程序BCC、熟知的bpftrace等,都是基于eBPF技術實現的。換句話說,通過對eBPF字節碼進行驗證和限制,系統能夠保持穩定和安全,同時還能實現BPF的靈活編程能力。
下圖展示了eBPF所支持的所有追蹤點,可以發現eBPF可以探測幾乎所有的子系統:
KProbes
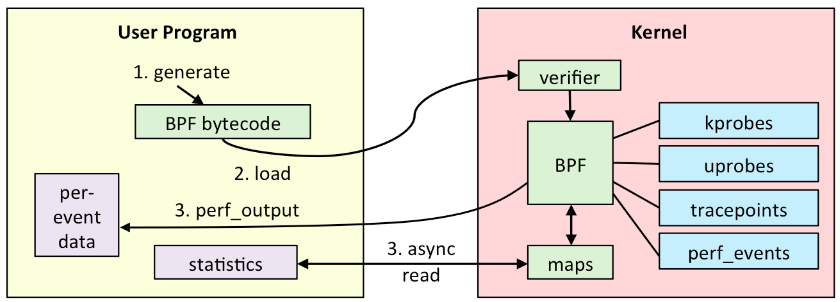
Kprobes是Linux內核中的一種動態跟蹤機制,它允許用戶在內核的關鍵代碼路徑上插入探針,以便在運行時捕獲和分析內核事件。Kprobes可以在內核函數的入口和出口處插入探針,以便觀察函數的調用和返回情況。通過在關鍵代碼路徑上插入探針,就可以收集各種內核事件的信息,如函數調用次數、參數值、返回值等。
eBPF程序可由Kprobes事件驅動,eBPF與Kprobes的結合可以實現內核級別的事件跟蹤和分析。
eBPF Maps
eBPF Maps是一種鍵值對數據結構,類似于傳統編程語言中的字典或哈希表。它由鍵(key)和值(value)組成,程序員可以根據需要定義鍵和值的類型,并在eBPF程序中進行讀取、寫入和更新操作。它可以在用戶空間和內核空間之間進行安全的數據傳輸,避免了傳統用戶空間和內核空間之間的數據拷貝和安全隱患。
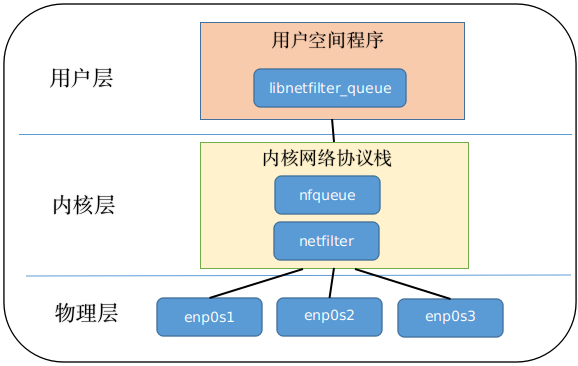
NFQUEUE
NFQUEUE利用Netfilter框架中的hook機制,將選定的網絡數據包從內核空間傳遞到用戶空間進行處理。具體的工作流程如下:
配置規則:使用iptables或nftables等工具配置規則,將特定的網絡流量匹配到NFQUEUE。
注冊隊列:在用戶態程序中,通過libnetfilter_queue庫注冊一個NFQUEUE隊列,并指定一個唯一的隊列ID。
數據包傳遞:當匹配到與規則相符的網絡數據包時,內核將其放入相應的NFQUEUE隊列,并將隊列ID與網絡數據包相關聯。
用戶態處理:用戶態程序通過監聽注冊的NFQUEUE隊列,可以接收到內核傳遞的網絡數據包。程序可以對網絡數據包進行處理、修改、過濾或記錄等操作。
決策:在用戶態處理完網絡數據包后,可以根據需要決定是否接受、丟棄、修改或重定向網絡數據包。
有固應用層網絡管控實現
上面介紹了eBPF和NFQUEUE的基本概念,可以發現,eBPF和NFQUEUE都可以將內核中網絡協議棧的網絡數據包轉發到用戶態,下面說明在UOS系統有固中網絡管控方案的具體實現步驟:
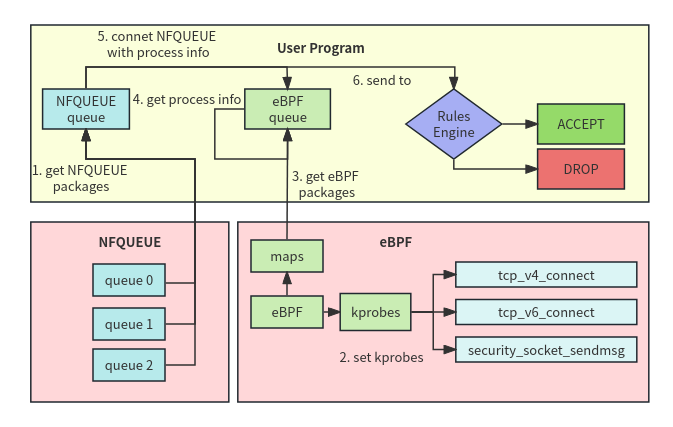
使用iptables配置NFQUEUE規則,將系統中的網絡數據包轉發到NFQUEUE隊列,用戶態程序從隊列中獲取數據包,并對這些數據包進行研判,是ACCEPT 還是DROP。但是NFQUEUE隊列中的數據包并不包含應用層信息,無法針對應用層信息進行研判,那么就需要將每個網絡數據包與具體的應用關聯起來。
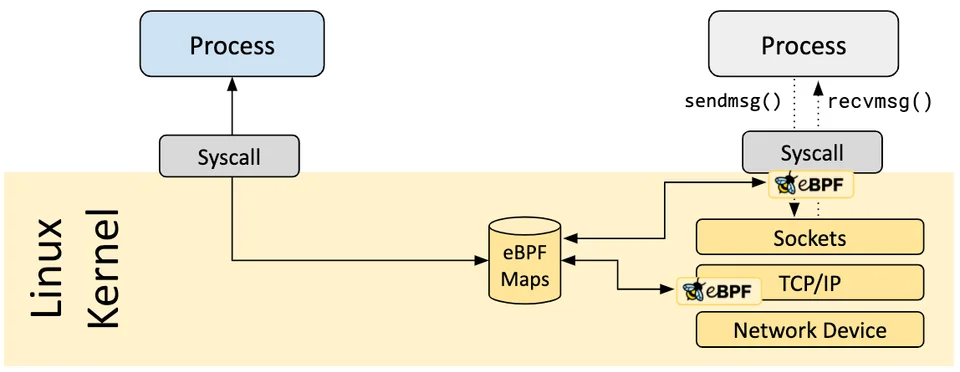
通過eBPF程序在內核網絡協議棧相關函數的入口和出口處插入Kprobes探針,這里將hook點設為tcp_v4_connect、tcp_v6_connect、security_socket_sendmsg。
每當系統中有網絡流量產生的時候,就可以截獲其中的網絡數據包送入eBPF程序處理。eBPF程序同時可以獲取此時的進程ID(PID),并將PID與數據包進行綁定,在之后處理數據包的時候就可以清晰的知道每個數據包是由哪個進程產生的了。通過eBPF Maps將綁定好PID的網絡流量包送入用戶空間,至此,eBPF程序完成了它的一次任務。當然,對于監控的每個數據包,eBPF程序都需要進行一次這樣的處理。
在用戶空間中,通過PID可以獲取到進程的相關信息,例如啟動時間、文件路徑、進程狀態等,將這些信息收集起來保存供后續使用。
用戶態程序通過數據包的 IP、端口、協議類型等信息將NFQUEUE隊列中的數據包與eBPF模塊捕獲的數據包關聯起來,這樣就知道NFQUEUE隊列中每個數據包對應的進程信息。
將NFQUEUE隊列中的數據包送入規則引擎,對比配置好的流量規則,對數據包作出研判。
優勢
傳統的linux網絡管控方案如iptables、firewalld等都只能工作在網絡層和傳輸層,而該網絡方案可以將網絡管控擴展到應用層。對比firewalld的XML模版,該方案在真正意義上實現了對應用層的網絡管控。
規則配置、網絡管控方式更加靈活,該方案可以針對單個應用進行規則配置,由于最后的處理過程是在應用態,而非內核中的netfilter,所以可以實現定制化的管控方式。
不足
由于NFQUEUE會將數據包轉發到用戶態處理,這犧牲了一部分的性能。
在linux的網絡協議棧中,并非所有的網絡流量都可以通過eBPF獲取到對應的進程信息,當前測試比較穩定的是應用程序的出口流量。
展望
eBPF是一項創新且強大技術,在過去的 eBPF summit 2022中,《The future of eBPF in the Linux Kernel》展望了 eBPF 的發展方向,其中包括:
更完備的編程能力:當前 eBPF 的編程能力存在一些局限性(比如不支持變量邊界的循環,指令數量受限等),演進目標提供圖靈完備的編程能力。
更強的安全性:支持類型安全,增強運行時 Verifier,演進目標是提供媲美 Rust 的安全編程能力。
更廣泛的移植能力:增強 CO-RE,加強 Helper 接口可移植能力,實現跨體系、平臺的移植能力。
更強的可編程能力:支持訪問/修改內核任意參數、返回值,實現更強的內核編程能力。
結合以上eBPF即將會實現的新特性,應用層的網絡管控可以在eBPF模塊中直接實現,這樣一來在降低性能開銷的同時,也提升了網絡管控的靈活性。未來,可以期待更多基于eBPF的應用層網絡管控方案出現,用于實現強大的應用層流量分析、智能的流量調度、自動化的安全防御和靈活的網絡管控。這將為網絡管理人員和開發人員提供更多的工具和技術,以應對不斷增長的網絡挑戰和需求。
)

)








—— 循環結構程序設計(1):for 循環)





導數與微分)

