一、背景
Disruptor是英國外匯交易公司LMAX開發的一個高性能隊列,研發的初衷是解決內部的內存隊列的延遲問題,而不是分布式隊列。基于Disruptor開發的系統單線程能支撐每秒600萬訂單,2010年在QCon演講后,獲得了業界關注。
據目前資料顯示:應用Disruptor的知名項目有如下的一些:Storm, Camel, Log4j2,還有目前的美團點評技術團隊也有很多不少的應用,或者說有一些借鑒了它的設計機制。
Disruptor是一個高性能的線程間異步通信的框架,即在同一個JVM進程中的多線程間消息傳遞。
二、傳統隊列問題
首先這里說的隊列也僅限于Java內部的消息隊列
| 隊列 | 有界性 | 鎖 | 結構 | 隊列類型 |
|---|---|---|---|---|
| ArrayBlockingQueue | 有界 | 加鎖 | 數組 | 阻塞 |
| LinkedBlockingQueue | 可選 | 加鎖 | 鏈表 | 阻塞 |
| ConcurrentLinkedQueue | 無界 | 無鎖 | 鏈表 | 非阻塞 |
| LinkedTransferQueue | 無界 | 無鎖 | 鏈表 | 阻塞 |
| PriorityBlockingQueue | 無界 | 加鎖 | 堆 | 阻塞 |
| DelayQueue | 無界 | 加鎖 | 堆 | 阻塞 |
隊列的底層數據結構一般分成三種:數組、鏈表和堆。其中,堆這里是為了實現帶有優先級特性的隊列,暫且不考慮。
在穩定性和性能要求特別高的系統中,為了防止生產者速度過快,導致內存溢出,只能選擇有界隊列;同時,為了減少Java的垃圾回收對系統性能的影響,會盡量選擇array/heap格式的數據結構。這樣篩選下來,符合條件的隊列就只有ArrayBlockingQueue。但是ArrayBlockingQueue是通過加鎖的方式保證線程安全,而且ArrayBlockingQueue還存在偽共享問題,這兩個問題嚴重影響了性能。
其中對于影響性能的兩種方式:加鎖和偽共享我們這里首先介紹下。加鎖方式和不加鎖的CAS方式這里不再進行介紹,我們這里首先對其中的偽共享問題講解下。
1.偽共享概念
共享
計算機早就支持多核,軟件也越來越多的支持多核運行,其實也可以叫做多處理運行。一個處理器對應一個物理插槽。其中一個插槽對應一個L3 Cache,一個槽包含多個cpu。一個cpu包含寄存器、L1 Cache、L2 Cache,如下圖所示: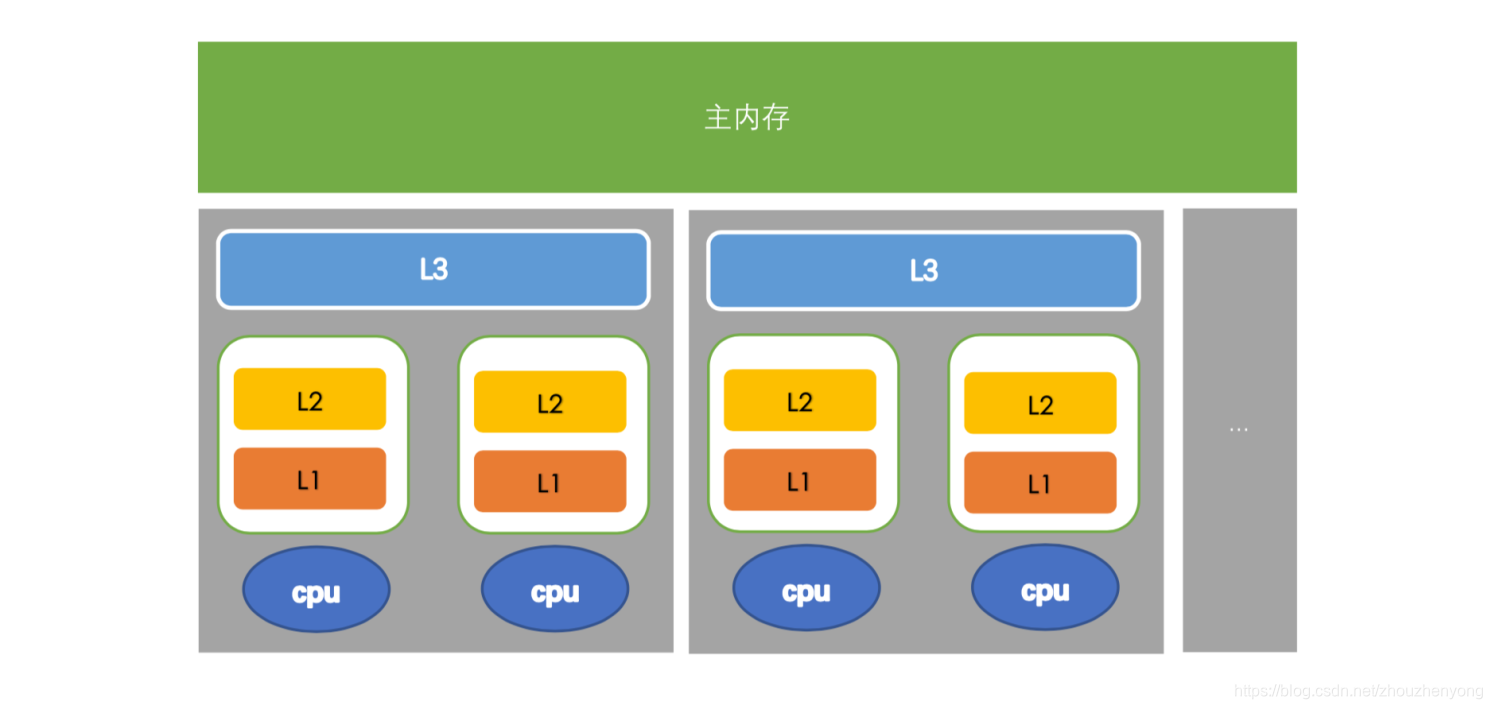
其中越靠近cpu則,速度越快,容量則越小。其中L1和L2是只能給一個cpu進行共享,但是L3是可以給同一個槽內的cpu共享,而主內存,是可以給所有的cpu共享,這就是內存的共享。
其中cpu執行運算的流程是這樣:首先回去L1里面查找對應數據,如果沒有則去L2、L3,如果都沒有,則就會去主內存中去拿,走的路越長,則耗費時間越久,性能就會越低。
需要注意的是,當線程之間進行共享數據的,需要將數據寫回到主內存中,而另一個線程通過訪問主內存獲得新的數據。
有人就會問了,多個線程之間不是會有一些非主內存的緩存進行共享么,那么另外一個線程會不會直接訪問到修改之前的內存呢。答案是會的,但是有一點,就是這種數據我們可以通過設置緩存失效測試來進行保證緩存的最新,這個方式其實在cpu這里進行設置的,叫內存屏障(其實就是在cpu這里設置一條指令,這個指令就是禁止cpu重排序,這個屏障之前的不能出現在屏障之后,屏障之后的處理不能出現屏障之前,也就是屏障之后獲取到的數據是最新的),對應到應用層面就是一個關鍵字volatile,下面會有一些進行介紹。
緩存行
剛剛說的緩存失效其實指的是Cache line的失效,也就是緩存行,Cache是由很多個Cache line 組成的,每個緩存行大小是32~128字節(通常是64字節)。我們這里假設緩存行是64字節,而java的一個Long類型是8字節,這樣的話一個緩存行就可以存8個Long類型的變量,如下圖所示:
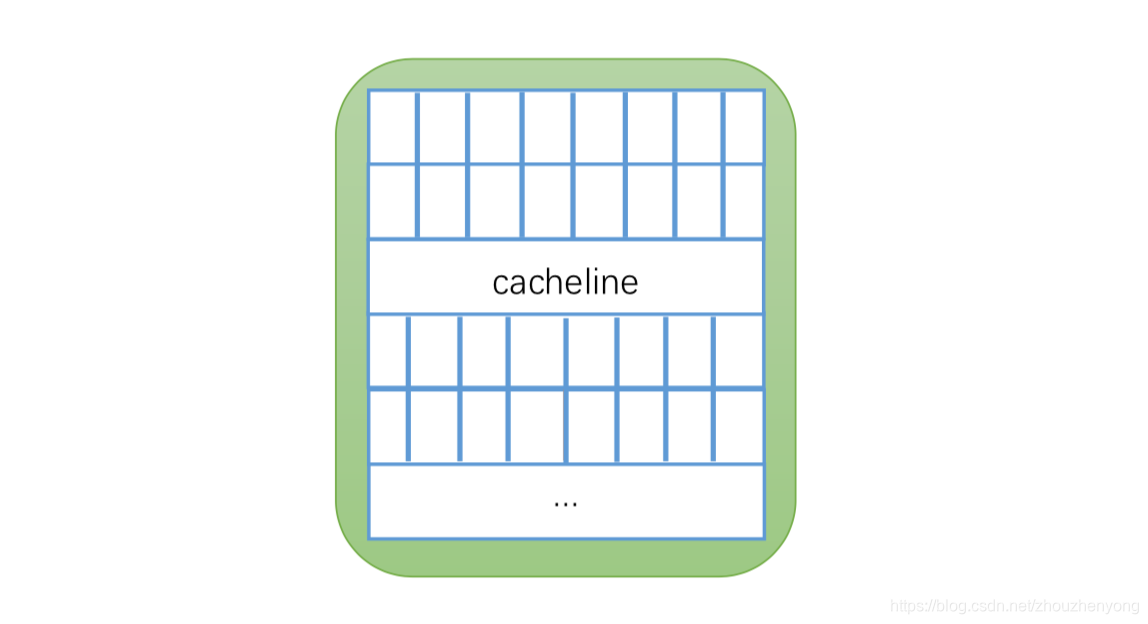
一個緩存對應的緩存行的結構圖
- 1
cpu 每次從主內存中獲取數據的時候都會將相鄰的數據存入到同一個緩存行中。假設我們訪問一個Long內存對應的數組的時候,如果其中一個被加載到內存中,那么對應的后面的7個數據也會被加載到對應的緩存行中,這樣就會非常快的訪問數據。
偽共享
剛我們說了緩存的失效其實就是緩存行的失效,緩存行失效的原理是什么,這里又涉及到一個MESI協議(緩存一致性協議),我們這里不介紹這個,感興趣的可以看下附錄部分,首先我們用Disruptor中很經典的講解偽共享的圖來講解下:
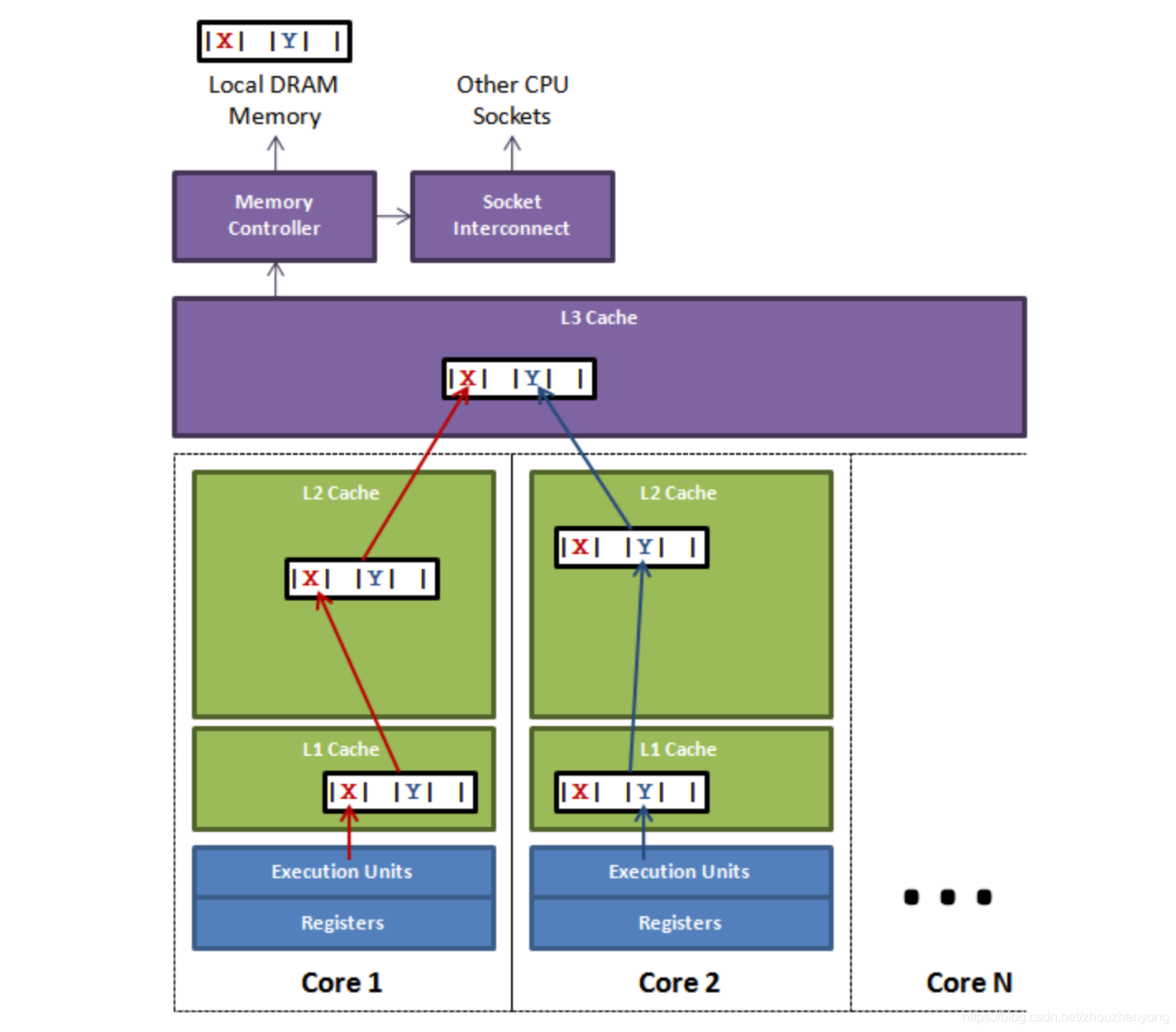
上圖中顯示的是一個槽的情況,里面是多個cpu, 如果cpu1上面的線程更新了變量X,根據MESI協議,那么變量X對應的所有緩存行都會失效,這個時候如果cpu2中的線程進行讀取變量Y,發現緩存行失效,就會按照緩存查找策略,往上查找,如果cpu1對應的線程更新變量X后又訪問了變量X,那么左側的L1、L2和槽內的L3 緩存行都會得到生效。這個時候cpu2線程可以在L3 Cache 中得到生效的數據,否則的話(即cpu1對應的線程更新X后沒有訪問X)cpu2的線程就只能從主內存中獲取數據,對性能就會造成很大的影響,這就是偽共享。
表面上 X 和 Y 都是被獨立線程操作的,而且兩操作之間也沒有任何關系。只不過它們共享了一個緩存行,但所有競爭沖突都是來源于共享。
2.ArrayBlockingQueue 的偽共享問題
剛我們已經講了偽共享的問題,那么ArrayBlockingQueue的這個偽共享問題存在于哪里呢,分析下核心的部分源碼
public void put(E e) throws InterruptedException {checkNotNull(e);final ReentrantLock lock = this.lock;//獲取當前對象鎖lock.lockInterruptibly();try {while (count == items.length)//阻塞并釋放鎖,等待notFull.signal()通知notFull.await();//將數據放入數組enqueue(e);} finally {lock.unlock();}}
private void enqueue(E x) {final Object[] items = this.items;//putIndex 就是入隊的下標items[putIndex] = x;if (++putIndex == items.length)putIndex = 0;count++;notEmpty.signal();}
public E take() throws InterruptedException {final ReentrantLock lock = this.lock;//加鎖lock.lockInterruptibly();try {while (count == 0)//阻塞并釋放對象鎖,并等待notEmpty.signal()通知notEmpty.await();//在數據不為空的情況下return dequeue();} finally {lock.unlock();}}
private E dequeue() {final Object[] items = this.items;//takeIndex 是出隊的下標E x = (E) items[takeIndex];items[takeIndex] = null;if (++takeIndex == items.length)takeIndex = 0;count--;if (itrs != null)itrs.elementDequeued();notFull.signal();return x;
}
其中最核心的三個成員變量為
putIndex:入隊下標
takeIndex:出隊下標
count:隊列中元素的數量
而三個成員的位置如下:
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳
這三個變量很容易放到同一個緩存行中,為此專門用一個偽共享檢測工具進行檢測,目前檢測偽共享的工具只有Intel的Intel Vtune 目前剛發現有mac os 版本,但是經過測試發現,該工具無法分析macOs 的處理器配置,用的時候發現如下錯誤“無法檢測到支持的處理器配置”,這個可以遺留給其他同學,工具的安裝和使用方式,可以查看附錄中的另外的一個連接。
三、高性能原理
剛說了上面隊列的兩個性能問題:一個是加鎖,一個是偽共享,那么disruptor是怎么解決這兩個問題的,以及除了解決這兩個問題之外,還引入了其他什么先進的東西提升性能的。
這里簡單列舉下:
- 引入環形的數組結構:數組元素不會被回收,避免頻繁的GC,
- 無鎖的設計:采用CAS無鎖方式,保證線程的安全性
- 屬性填充:通過添加額外的無用信息,避免偽共享問題
- 元素位置的定位:采用跟一致性哈希一樣的方式,一個索引,進行自增
1.環形數組結構
環形數組結構是整個Disruptor的核心所在。
首先因為是數組,所以要比鏈表快,而且根據我們對上面緩存行的解釋知道,數組中的一個元素加載,相鄰的數組元素也是會被預加載的,因此在這樣的結構中,cpu無需時不時去主存加載數組中的下一個元素。而且,你可以為數組預先分配內存,使得數組對象一直存在(除非程序終止)。這就意味著不需要花大量的時間用于垃圾回收。此外,不像鏈表那樣,需要為每一個添加到其上面的對象創造節點對象—對應的,當刪除節點時,需要執行相應的內存清理操作。環形數組中的元素采用覆蓋方式,避免了jvm的GC。
其次結構作為環形,數組的大小為2的n次方,這樣元素定位可以通過位運算效率會更高,這個跟一致性哈希中的環形策略有點像。在disruptor中,這個牛逼的環形結構就是RingBuffer,既然是數組,那么就有大小,而且這個大小必須是2的n次方,結構如下: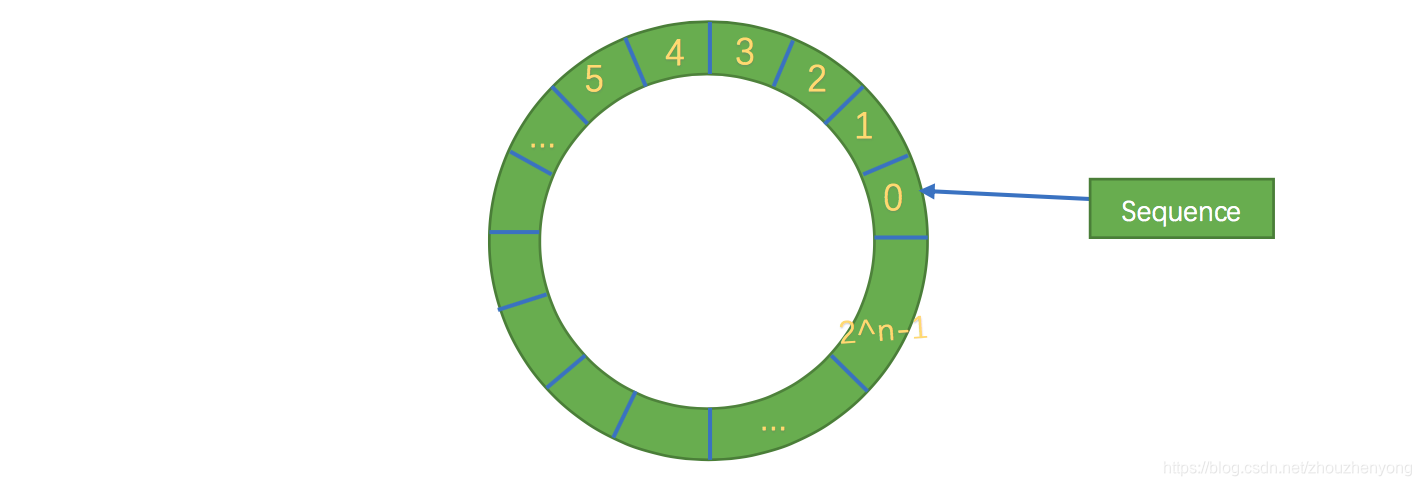
其實質只是一個普通的數組,只是當放置數據填充滿隊列(即到達2^n-1位置)之后,再填充數據,就會從0開始,覆蓋之前的數據,于是就相當于一個環。
2.生產和消費模式
根據上面的環形結構,我們來具體分析一下Disruptor的工作原理。
Disruptor 不像傳統的隊列,分為一個隊頭指針和一個隊尾指針,而是只有一個角標(上面的seq),那么這個是如何保證生產的消息不會覆蓋沒有消費掉的消息呢。
在Disruptor中生產者分為單生產者和多生產者,而消費者并沒有區分。單生產者情況下,就是普通的生產者向RingBuffer中放置數據,消費者獲取最大可消費的位置,并進行消費。而多生產者時候,又多出了一個跟RingBuffer同樣大小的Buffer,稱為AvailableBuffer。在多生產者中,每個生產者首先通過CAS競爭獲取可以寫的空間,然后再進行慢慢往里放數據,如果正好這個時候消費者要消費數據,那么每個消費者都需要獲取最大可消費的下標,這個下標是在AvailableBuffer進行獲取得到的最長連續的序列下標。
假設現在又兩個生產者,開始寫數據,通過CAS競爭,w1得到的34的空間,w2得到了78的空間,其中6是代表已被寫入或者沒有被消費的數據。
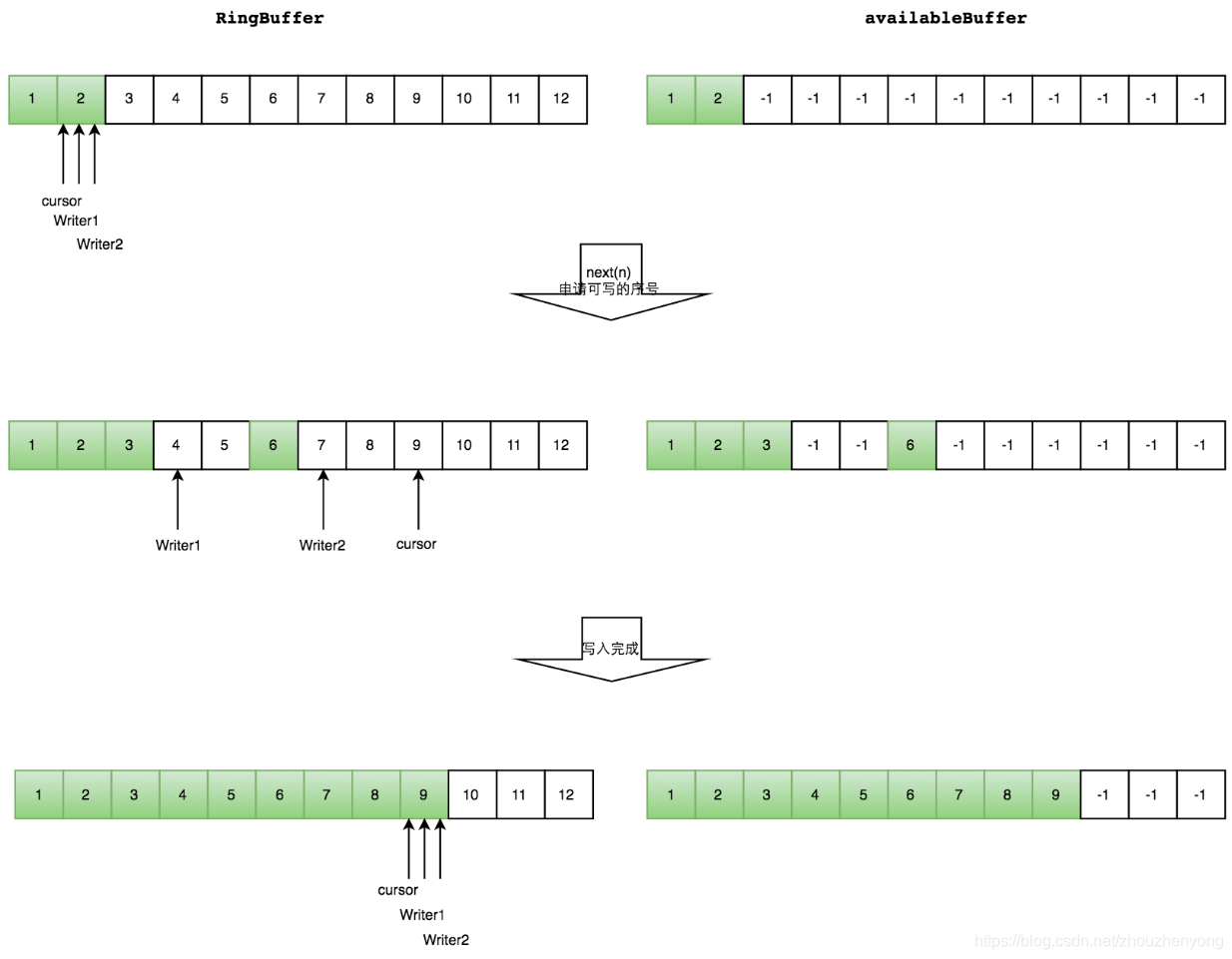
綠色代表已經寫OK的數據
- 1
假設三個生產者在寫中,還沒有置位AvailableBuffer,那么消費者可獲取的消費下標只能獲取到6,然后等生產者都寫OK后,通知到消費者,消費者繼續重復上面的步驟。如下圖
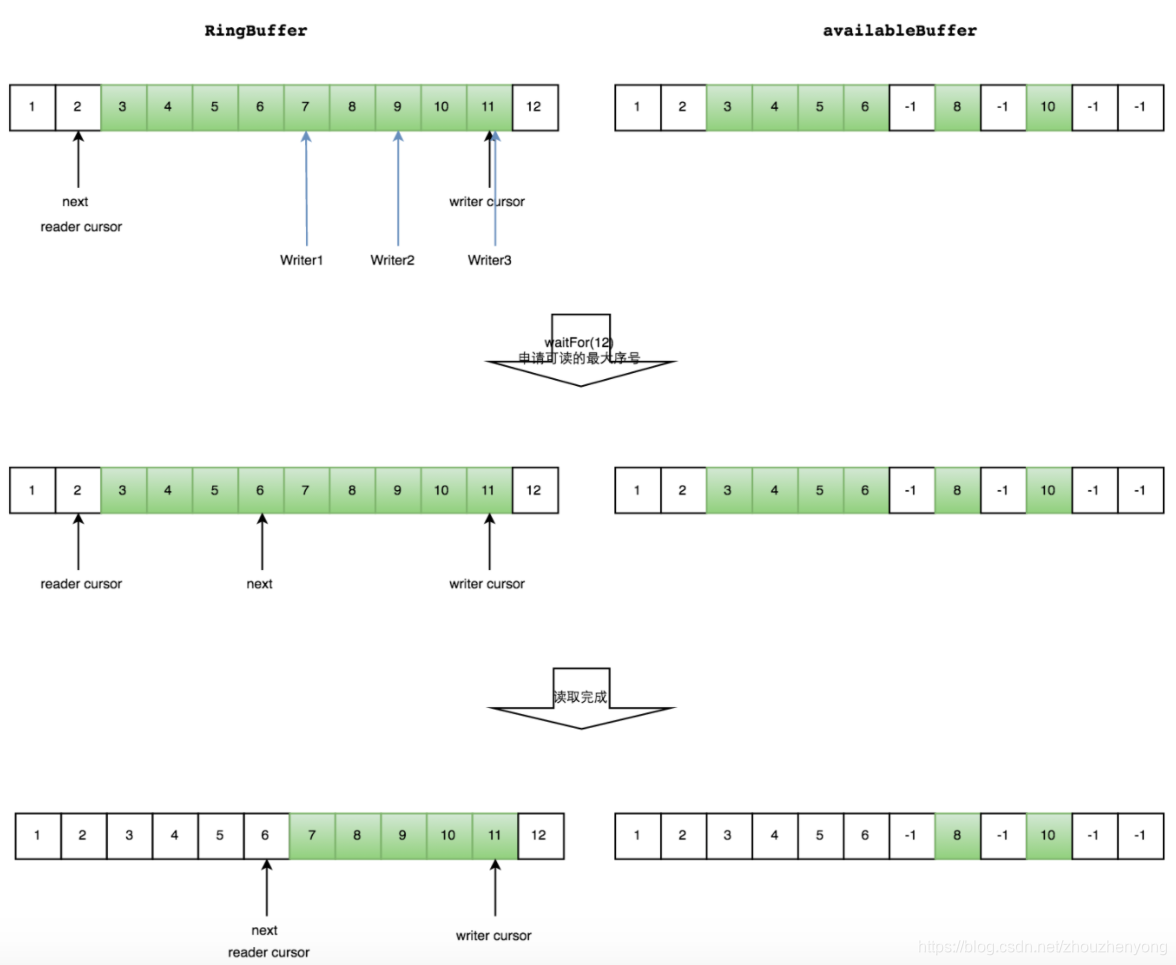
BusySpinWaitStrategy: 自旋等待,類似Linux Kernel使用的自旋鎖。低延遲但同時對CPU資源的占用也多。
BlockingWaitStrategy: 使用鎖和條件變量。CPU資源的占用少,延遲大,默認等待策略。
SleepingWaitStrategy: 在多次循環嘗試不成功后,選擇讓出CPU,等待下次調度,多次調度后仍不成功,嘗試前睡眠一個納秒級別的時間再嘗試。這種策略平衡了延遲和CPU資源占用,但延遲不均勻。
YieldingWaitStrategy: 在多次循環嘗試不成功后,選擇讓出CPU,等待下次調。平衡了延遲和CPU資源占用,但延遲也比較均勻。
PhasedBackoffWaitStrategy: 上面多種策略的綜合,CPU資源的占用少,延遲大
3.牛逼的下標指針
RingBuffer的指針(Sequence)屬于一個volatile變量,同時也是我們能夠不用鎖操作就能實現Disruptor的原因之一,而且通過緩存行補充,避免偽共享問題。 該所謂指針是通過一直自增的方式來獲取下一個可寫或者可讀數據,該數據是Long類型,不用擔心會爆掉。有人計算過:?long的范圍最大可以達到9223372036854775807,一年365 * 24 * 60 * 60 = 31536000秒,每秒產生1W條數據,也可以使用292年。
class LhsPadding{//緩存行補齊, 提升cache緩存命中率protected long p1, p2, p3, p4, p5, p6, p7;
}class Value extends LhsPadding{protected volatile long value;
}class RhsPadding extends Value{//緩存行補齊, 提升cache緩存命中率protected long p9, p10, p11, p12, p13, p14, p15;
}public class Sequence extends RhsPadding{...
}
四、用法
用法很簡單,一共三個角色:生產者,消費者,disruptor對象
1.簡單用法
disruptor 就兩個構造方法
public Disruptor(final EventFactory<T> eventFactory, // 數據實體構造工廠final int ringBufferSize, // 隊列大小,必須是2的次方final ThreadFactory threadFactory, // 線程工廠final ProducerType producerType, // 生產者類型,單個生產者還是多個final WaitStrategy waitStrategy){ // 消費者等待策略...
}public Disruptor(final EventFactory<T> eventFactory, final int ringBufferSize, final ThreadFactory threadFactory){...
}
生產者這里沒有固定的對象,只是需要獲取放置數據的位置,然后進行publish
public void send(String data){RingBuffer<MsgEvent> ringBuffer = this.disruptor.getRingBuffer();//獲取下一個放置數據的位置long next = ringBuffer.next();try{MsgEvent event = ringBuffer.get(next);event.setValue(data);}finally {//發布事件ringBuffer.publish(next);}
}
消費處理可以有如下幾種
- 1
public EventHandlerGroup<T> handleEventsWith(final EventHandler<? super T>... handlers){...
}
public EventHandlerGroup<T> handleEventsWith(final EventProcessor... processors){...
}
public EventHandlerGroup<T> handleEventsWith(final EventProcessorFactory<T>... eventProcessorFactories){...
}
public EventHandlerGroup<T> handleEventsWithWorkerPool(final WorkHandler<T>... workHandlers){...
}
//消費者
public class MsgConsumer implements EventHandler<MsgEvent>{private String name;public MsgConsumer(String name){this.name = name;}@Overridepublic void onEvent(MsgEvent msgEvent, long l, boolean b) throws Exception {System.out.println(this.name+" -> 接收到信息: "+msgEvent.getValue());}
}//生產者處理
public class MsgProducer {private Disruptor disruptor;public MsgProducer(Disruptor disruptor){this.disruptor = disruptor;}public void send(String data){RingBuffer<MsgEvent> ringBuffer = this.disruptor.getRingBuffer();long next = ringBuffer.next();try{MsgEvent event = ringBuffer.get(next);event.setValue(data);}finally {ringBuffer.publish(next);}}public void send(List<String> dataList){dataList.stream().forEach(data -> this.send(data));}
}//觸發測試
public class DisruptorDemo {@Testpublic void test(){Disruptor<MsgEvent> disruptor = new Disruptor<>(MsgEvent::new, 1024, Executors.defaultThreadFactory());//定義消費者MsgConsumer msg1 = new MsgConsumer("1");MsgConsumer msg2 = new MsgConsumer("2");MsgConsumer msg3 = new MsgConsumer("3");//綁定配置關系disruptor.handleEventsWith(msg1, msg2, msg3);disruptor.start();// 定義要發送的數據MsgProducer msgProducer = new MsgProducer(disruptor);msgProducer.send(Arrays.asList("nihao","hah"));}
}
輸出(消費沒有固定順序):
1 -> 接收到信息: nihao
3 -> 接收到信息: nihao
3 -> 接收到信息: hah
2 -> 接收到信息: nihao
2 -> 接收到信息: hah
1 -> 接收到信息: hah
2.其他用法
上面主要介紹了多消費統一消費,但是在生產者模型中是有很多種,如下,一對一,一對多,多對多,多對一
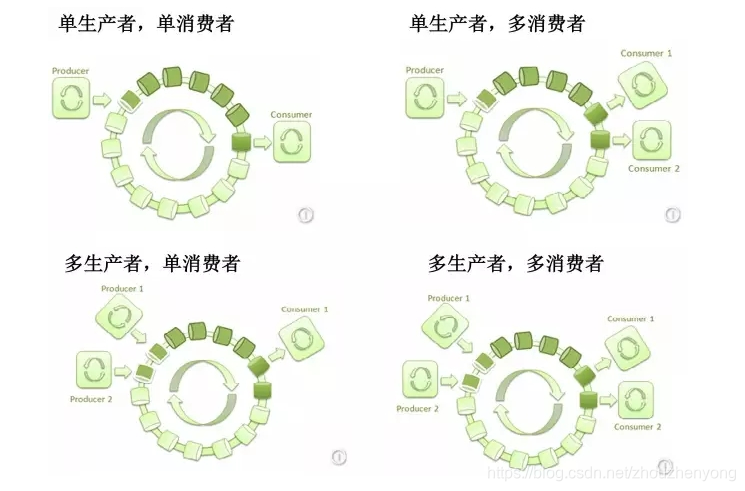
1.單生產者生產數據,單消費者消費數據,一般用在后臺處理的業務邏輯中。
2.單生產者生產數據,多個消費者消費數據(這里面有兩種情況:同一個消息,可以被多個消費者分別消費。或者多個消費者組成一個組,一個消費者消費一個數據)。
3.多個生產者生產數據,單個消費者消費數據,可以用在限流或者排隊等候單一資源處理的場景中。
4.多個生產者分別生產數據,多個消費者消費數據(這里面有兩種情況:同一個消息,可以被多個消費者分別消費。或者多個消費者組成一個組,一個消費者消費一個數據)。
生產者配置
其中生產模式中的單生產者模式和多生產模式,這里主要是通過一個枚舉:ProduceType來區分,建議,多個生產者用多生產者模式,性能會好點。
消費者配置
消費者模式這里分為兩種:
統一消費:每個消費者都消費一份生產者生產的數據
分組消費:每個生產這生產的數據只被消費一次
統一消費像上面簡單用法中運用即可,對于分組消費,用函數 handleEventsWithWorkerPool 即可
/*** 分組處理 handleEventWithWorkerPool*/
@Test
public void test1(){Disruptor<MsgEvent> disruptor = new Disruptor(MsgEvent::new, 1024, Executors.defaultThreadFactory());disruptor.handleEventsWithWorkerPool(new MyWorkHandler("work1"), new MyWorkHandler("work2"));disruptor.start();MsgProducer msgProducer = new MsgProducer(disruptor);msgProducer.send(Arrays.asList("aaa","bbb"));
}
輸出:
work1 : MsgEvent(value=bbb)
work2 : MsgEvent(value=aaa)
work1 : MsgEvent(value=cc)
work2 : MsgEvent(value=dd)
消費順序配置
在消費配置中,這里可以有很多種消費方式,比如:
/*** 測試順序消費* 每一條消息的消費者1和3消費完畢后,消費者2再進行消費*/
@Test
public void test2(){MsgConsumer msg1 = new MsgConsumer("1");MsgConsumer msg2 = new MsgConsumer("2");MsgConsumer msg3 = new MsgConsumer("3");Disruptor<MsgEvent> disruptor = new Disruptor(MsgEvent::new, 1024, Executors.defaultThreadFactory());disruptor.handleEventsWith(msg1, msg3).then(msg2);disruptor.start();MsgProducer msgProducer = new MsgProducer(disruptor);msgProducer.send(Arrays.asList("aaa", "bbb", "ccc", "ddd"));
}
- ?
輸出(里面的是根據每一條消息的消費者順序):
1 -> 接收到信息: aaa
3 -> 接收到信息: aaa
1 -> 接收到信息: bbb
1 -> 接收到信息: ccc
2 -> 接收到信息: aaa
3 -> 接收到信息: bbb
3 -> 接收到信息: ccc
3 -> 接收到信息: ddd
1 -> 接收到信息: ddd
2 -> 接收到信息: bbb
2 -> 接收到信息: ccc
2 -> 接收到信息: ddd
/*** 測試多支線消費* 消費者1和消費者3一個支線,消費者2和消費者4一個支線,消費者3和消費者4消費完畢后,消費者5再進行消費*/
@Test
public void test3(){MsgConsumer msg1 = new MsgConsumer("1");MsgConsumer msg2 = new MsgConsumer("2");MsgConsumer msg3 = new MsgConsumer("3");MsgConsumer msg4 = new MsgConsumer("4");MsgConsumer msg5 = new MsgConsumer("5");//支線:消費者1和消費者3disruptor.handleEventsWith(msg1, msg3);//支線:消費者2和消費者4disruptor.handleEventsWith(msg2, msg4);//消費者3和消費者4執行完之后,指向消費者5disruptor.after(msg3, msg4).handleEventsWith(msg5);disruptor.start();MsgProducer msgProducer = new MsgProducer(disruptor);msgProducer.send(Arrays.asList("aaa", "bbb", "ccc", "ddd"));
}
1 -> 接收到信息: aaa
2 -> 接收到信息: aaa
2 -> 接收到信息: bbb
3 -> 接收到信息: aaa
3 -> 接收到信息: bbb
4 -> 接收到信息: aaa
4 -> 接收到信息: bbb
5 -> 接收到信息: aaa
1 -> 接收到信息: bbb
5 -> 接收到信息: bbb
五、常見問題
下面介紹下一些常見問題。
disruptor原本就是事件驅動的設計,其整個架構跟普通的多線程很不一樣。比如一種用法,將disruptor作為業務處理,中間帶I/O處理,這種玩法比多線程還慢;相反,如果將disruptor做業務處理,需要I/O時采用nio異步調用,不阻塞disruptor消費者線程,等到I/O異步調用回來后在回調方法中將后續處理重新塞到disruptor隊列中,可以看出來,這是典型的事件處理架構,確實能在時間上占據優勢,加上ringBuffer固有的幾項性能優化,能讓disruptor發揮最大功效。
一種是把buffer變大,另一種是從源頭解決producer和consumer速度差異太大問題,比如試著把producer分流,或者用多個disruptor,使每個disruptor的load變小。
如果對延遲的需求很高,可以考慮使用。
六、參考:
官方git
https://github.com/LMAX-Exchange/disruptor
https://lmax-exchange.github.io/disruptor/
偽共享:
https://mechanical-sympathy.blogspot.com/2011/07/false-sharing.html
內存屏障:
http://in355hz.iteye.com/blog/1797829
MESI(緩存一致性協議)
https://www.cnblogs.com/cyfonly/p/5800758.html
ArrayBlockingQueue 偽共享問題
https://www.jianshu.com/p/71c9bc3bfe1a
jdk 本身針對偽共享做的處理
https://www.cnblogs.com/Binhua-Liu/p/5620339.html
intel vtune 分析偽共享案例
https://software.intel.com/zh-cn/vtune-amplifier-cookbook-false-sharing
RingBuffer工作原理
https://www.jianshu.com/p/71c9bc3bfe1a
http://wiki.jikexueyuan.com/project/disruptor-getting-started/the-framework.html
https://www.jianshu.com/p/d6375295fad4
http://colobu.com/2014/12/22/why-is-disruptor-faster-than-ArrayBlockingQueue/
https://blog.csdn.net/kobejayandy/article/details/18329583
https://blog.csdn.net/u014313492/article/details/42556341
Disruptor 是如何工作的
http://in355hz.iteye.com/blog/1797829
隊列的各種場景
http://www.uml.org.cn/zjjs/2016060310.asp
消費順序
http://357029540.iteye.com/blog/2395677



















