1.基本概念
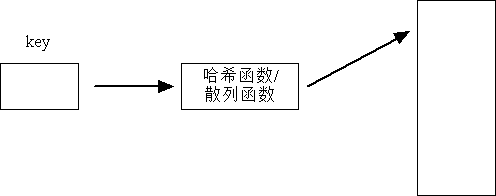
哈希表(散列表):提高數據的查找效率
哈希存儲:將要存儲的數據的關鍵字和存儲位置之間,建立起對應的關系,
這個關系稱之為哈希函數。存儲數據時,通過對應的哈希函數可以將數據映射到指定的存儲位置;查找時,仍可通過該函數找到數據的存儲位置。
哈希沖突/哈希矛盾:?
key1 != key2
f(key1) == f(key2)
處理哈希沖突的方法:
1)開放地址法:
思想:當發生哈希沖突時,通過探測序列在哈希表中尋找下一個可用的空槽位,直到找到合適的位置插入元素。所有元素都存儲在哈希表本身中(無額外數據結構)。
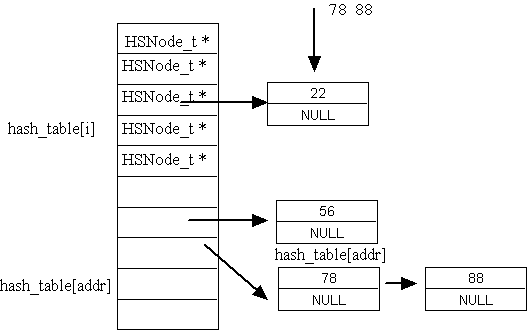
2)鏈地址法
思想:將哈希表的每個槽位作為鏈表頭節點,沖突的元素直接插入對應槽位的鏈表中。哈希表本身只存儲鏈表的引用。


2.基本操作
(1)哈希函數
int hash_function(char key)
{if (key >= 'a' && key <= 'z'){return key-'a';}else if (key >= 'A' && key <= 'Z'){return key-'A';}else{return HASH_TABLE_MAX_SIZE-1;}
}(2)創建一個哈希表
HSNode_t *hash_table[HASH_TABLE_MAX_SIZE] = {NULL};(3)插入(有序)
int insert_hash_table(HSNode_t **hash_table, Data_type_t data)
{int addr = hash_function(data.name[0]);//申請結點保存數據//頭插//hash_table[addr]; //---->pheadHSNode_t *pnode = malloc(sizeof(HSNode_t));if (NULL == pnode){printf("malloc error\n");return -1;}pnode->data = data;pnode->pnext = NULL;if (NULL == hash_table[addr]){hash_table[addr] = pnode;}else{if (strcmp(pnode->data.name, hash_table[addr]->data.name) <= 0){pnode->pnext = hash_table[addr];hash_table[addr] = pnode;}else{HSNode_t *p = hash_table[addr];while (p->pnext != NULL && (p->pnext->data.name, pnode->data.name) < 0){p = p->pnext;}pnode->pnext = p->pnext;p->pnext = pnode;}}return 0;
}(4)遍歷
void hash_for_each(HSNode_t **hash_table)
{for (int i = 0; i < HASH_TABLE_MAX_SIZE; ++i){HSNode_t *ptmp = hash_table[i];while (ptmp){printf("%s : %s\n", ptmp->data.name, ptmp->data.tel);ptmp = ptmp->pnext;}printf("\n");}
}(5)查找
HSNode_t *find_hash_table(HSNode_t **hash_table, char *name)
{int addr = hash_function(name[0]);HSNode_t *ptmp = hash_table[addr];while (ptmp){if (0 == strncmp(ptmp->data.name, name, strlen(name))){return ptmp;}ptmp = ptmp->pnext;}return NULL;
}(6)銷毀
void destroy_hash_table(HSNode_t **hash_table)
{for (int i = 0;i < HASH_TABLE_MAX_SIZE; i++){HSNode_t *pdel = hash_table[i];while (hash_table[i] != NULL){hash_table[i] = pdel->pnext;free(pdel);pdel = hash_table[i];}}
}


本地部署詳細教程)
的軟件包(含依賴))

![[linux] Linux:一條指令更新DDNS](http://pic.xiahunao.cn/[linux] Linux:一條指令更新DDNS)
![[激光原理與應用-182]:測量儀器 - 光束型 - 光束質量分析儀](http://pic.xiahunao.cn/[激光原理與應用-182]:測量儀器 - 光束型 - 光束質量分析儀)











