為什么需要AtomicInteger原子操作類?
對于Java中的運算操作,例如自增或自減,若沒有進行額外的同步操作,在多線程環境下就是線程不安全的。num++解析為num=num+1,明顯,這個操作不具備原子性,多線程并發共享這個變量時必然會出現問題。測試代碼如下:
public class AtomicIntegerTest {private static final int THREADS_CONUT = 20;public static int count = 0;public static void increase() {count++;}public static void main(String[] args) {Thread[] threads = new Thread[THREADS_CONUT];for (int i = 0; i < THREADS_CONUT; i++) {threads[i] = new Thread(new Runnable() {@Overridepublic void run() {for (int i = 0; i < 1000; i++) {increase();}}});threads[i].start();}while (Thread.activeCount() > 1) {Thread.yield();}System.out.println(count);}}這里運行了20個線程,每個線程對count變量進行1000此自增操作,如果上面這段代碼能夠正常并發的話,最后的結果應該是20000才對,但實際結果卻發現每次運行的結果都不相同,都是一個小于20000的數字。這是為什么呢?
要是換成volatile修飾count變量呢?
順帶說下volatile關鍵字很重要的兩個特性:
1、保證變量在線程間可見,對volatile變量所有的寫操作都能立即反應到其他線程中,換句話說,volatile變量在各個線程中是一致的(得益于java內存模型—"先行發生原則");
2、禁止指令的重排序優化;
那么換成volatile修飾count變量后,會有什么效果呢? 試一試:
public class AtomicIntegerTest {private static final int THREADS_CONUT = 20;public static volatile int count = 0;public static void increase() {count++;}public static void main(String[] args) {Thread[] threads = new Thread[THREADS_CONUT];for (int i = 0; i < THREADS_CONUT; i++) {threads[i] = new Thread(new Runnable() {@Overridepublic void run() {for (int i = 0; i < 1000; i++) {increase();}}});threads[i].start();}while (Thread.activeCount() > 1) {Thread.yield();}System.out.println(count);}}結果似乎又失望了,測試結果和上面的一致,每次都是輸出小于20000的數字。這又是為什么么? 上面的論據是正確的,也就是上面標紅的內容,但是這個論據并不能得出"基于volatile變量的運算在并發下是安全的"這個結論,因為核心點在于java里的運算(比如自增)并不是原子性的。
用了AtomicInteger類后會變成什么樣子呢?
把上面的代碼改造成AtomicInteger原子類型,先看看效果
import java.util.concurrent.atomic.AtomicInteger;public class AtomicIntegerTest {private static final int THREADS_CONUT = 20;public static AtomicInteger count = new AtomicInteger(0);public static void increase() {count.incrementAndGet();}public static void main(String[] args) {Thread[] threads = new Thread[THREADS_CONUT];for (int i = 0; i < THREADS_CONUT; i++) {threads[i] = new Thread(new Runnable() {@Overridepublic void run() {for (int i = 0; i < 1000; i++) {increase();}}});threads[i].start();}while (Thread.activeCount() > 1) {Thread.yield();}System.out.println(count);}}結果每次都輸出20000,程序輸出了正確的結果,這都歸功于AtomicInteger.incrementAndGet()方法的原子性。
非阻塞同步
同步:多線程并發訪問共享數據時,保證共享數據再同一時刻只被一個或一些線程使用。
我們知道,阻塞同步和非阻塞同步都是實現線程安全的兩個保障手段,非阻塞同步對于阻塞同步而言主要解決了阻塞同步中線程阻塞和喚醒帶來的性能問題,那什么叫做非阻塞同步呢?在并發環境下,某個線程對共享變量先進行操作,如果沒有其他線程爭用共享數據那操作就成功;如果存在數據的爭用沖突,那就才去補償措施,比如不斷的重試機制,直到成功為止,因為這種樂觀的并發策略不需要把線程掛起,也就把這種同步操作稱為非阻塞同步(操作和沖突檢測具備原子性)。在硬件指令集的發展驅動下,使得 "操作和沖突檢測" 這種看起來需要多次操作的行為只需要一條處理器指令便可以完成,這些指令中就包括非常著名的CAS指令(Compare-And-Swap比較并交換)。《深入理解Java虛擬機第二版.周志明》第十三章中這樣描述關于CAS機制:

圖取自《深入理解Java虛擬機第二版.周志明》13.2.2
所以再返回來看AtomicInteger.incrementAndGet()方法,它的時間也比較簡單
-
/*** Atomically increments by one the current value.** @return the updated value*/public final int incrementAndGet() {for (;;) {int current = get();int next = current + 1;if (compareAndSet(current, next))return next;}}?
- ?
incrementAndGet()方法在一個無限循環體內,不斷嘗試將一個比當前值大1的新值賦給自己,如果失敗則說明在執行"獲取-設置"操作的時已經被其它線程修改過了,于是便再次進入循環下一次操作,直到成功為止。這個便是AtomicInteger原子性的"訣竅"了,繼續進源碼看它的compareAndSet方法:
/*** Atomically sets the value to the given updated value* if the current value {@code ==} the expected value.** @param expect the expected value* @param update the new value* @return true if successful. False return indicates that* the actual value was not equal to the expected value.*/public final boolean compareAndSet(int expect, int update) {return unsafe.compareAndSwapInt(this, valueOffset, expect, update);}可以看到,compareAndSet()調用的就是Unsafe.compareAndSwapInt()方法,即Unsafe類的CAS操作。
使用示例如下圖,用于標識程序執行過程中是否發生了異常,使用quartz實現高級定制化定時任務(包含管理界面)實現中:

2020-02-12補充如下內容:
- 原子類相比于普通的鎖,粒度更細、效率更高(除了高度競爭的情況下)
- 如果對于上面的示例代碼中使用了thread.yield()之類的方法不清晰的,可以直接看下面的代碼壓測:
public class AtomicIntegerTest implements Runnable {static AtomicInteger atomicInteger = new AtomicInteger(0);static int commonInteger = 0;public void addAtomicInteger() {atomicInteger.getAndIncrement();}public void addCommonInteger() {commonInteger++;}@Overridepublic void run() {//可以調大10000看效果更明顯for (int i = 0; i < 10000; i++) {addAtomicInteger();addCommonInteger();}}public static void main(String[] args) throws InterruptedException {AtomicIntegerTest atomicIntegerTest = new AtomicIntegerTest();Thread thread1 = new Thread(atomicIntegerTest);Thread thread2 = new Thread(atomicIntegerTest);thread1.start();thread2.start();//join()方法是為了讓main主線程等待thread1、thread2兩個子線程執行完畢thread1.join();thread2.join();System.out.println("AtomicInteger add result = " + atomicInteger.get());System.out.println("CommonInteger add result = " + commonInteger);}}- 原子類一覽圖參考如下:
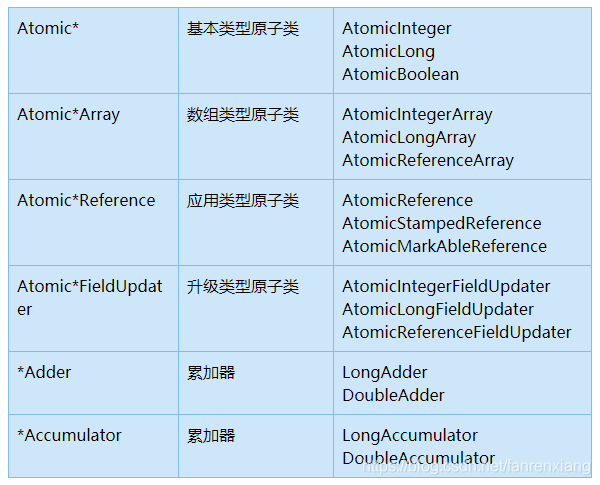
- 如何把普通變量升級為原子變量?主要是AtomicIntegerFieldUpdater<T>類,參考如下代碼:
-
/*** @description 將普通變量升級為原子變量**/public class AtomicIntegerFieldUpdaterTest implements Runnable {static Goods phone;static Goods computer;AtomicIntegerFieldUpdater<Goods> atomicIntegerFieldUpdater =AtomicIntegerFieldUpdater.newUpdater(Goods.class, "price");@Overridepublic void run() {for (int i = 0; i < 10000; i++) {phone.price++;atomicIntegerFieldUpdater.getAndIncrement(computer);}}static class Goods {//商品定價volatile int price;}public static void main(String[] args) throws InterruptedException {phone = new Goods();computer = new Goods();AtomicIntegerFieldUpdaterTest atomicIntegerFieldUpdaterTest = new AtomicIntegerFieldUpdaterTest();Thread thread1 = new Thread(atomicIntegerFieldUpdaterTest);Thread thread2 = new Thread(atomicIntegerFieldUpdaterTest);thread1.start();thread2.start();//join()方法是為了讓main主線程等待thread1、thread2兩個子線程執行完畢thread1.join();thread2.join();System.out.println("CommonInteger price = " + phone.price);System.out.println("AtomicInteger price = " + computer.price);}}?
- 在高并發情況下,LongAdder(累加器)比AtomicLong原子操作效率更高,LongAdder累加器是java8新加入的,參考以下壓測代碼:
-
/*** @description 壓測AtomicLong的原子操作性能**/public class AtomicLongTest implements Runnable {private static AtomicLong atomicLong = new AtomicLong(0);@Overridepublic void run() {for (int i = 0; i < 10000; i++) {atomicLong.incrementAndGet();}}public static void main(String[] args) {ExecutorService es = Executors.newFixedThreadPool(30);long start = System.currentTimeMillis();for (int i = 0; i < 10000; i++) {es.submit(new AtomicLongTest());}es.shutdown();//保證任務全部執行完while (!es.isTerminated()) { }long end = System.currentTimeMillis();System.out.println("AtomicLong add 耗時=" + (end - start));System.out.println("AtomicLong add result=" + atomicLong.get());}}/*** @description 壓測LongAdder的原子操作性能**/public class LongAdderTest implements Runnable {private static LongAdder longAdder = new LongAdder();@Overridepublic void run() {for (int i = 0; i < 10000; i++) {longAdder.increment();}}public static void main(String[] args) {ExecutorService es = Executors.newFixedThreadPool(30);long start = System.currentTimeMillis();for (int i = 0; i < 10000; i++) {es.submit(new LongAdderTest());}es.shutdown();//保證任務全部執行完while (!es.isTerminated()) {}long end = System.currentTimeMillis();System.out.println("LongAdder add 耗時=" + (end - start));System.out.println("LongAdder add result=" + longAdder.sum());}}?
-
?
在高度并發競爭情形下,AtomicLong每次進行add都需要flush和refresh(這一塊涉及到java內存模型中的工作內存和主內存的,所有變量操作只能在工作內存中進行,然后寫回主內存,其它線程再次讀取新值),每次add()都需要同步,在高并發時會有比較多沖突,比較耗時導致效率低;而LongAdder中每個線程會維護自己的一個計數器,在最后執行LongAdder.sum()方法時候才需要同步,把所有計數器全部加起來,不需要flush和refresh操作。



















