并行計算或并行化是一種計算形式,其中許多計算同時進行,其原理是大問題通常可以分為較小的問題,然后并行解決(“并行”)。 從本質上講,如果可以將CPU密集型問題劃分為較小的獨立任務,則可以將這些任務分配給不同的處理器。
關于多線程和并發,Java非常有趣。 它從一開始就支持Thread,而在過去,您可以使用帶有interrupt , join , sleep方法的低級方法來操縱線程的執行。 此外,所有對象繼承的notify和wait方法也可能會有所幫助。
可以通過這種方式控制應用程序的執行,但是過程有些繁瑣。 然后是Java 1.5中的并發包 ,它提供了一個更高級別的框架,開發人員可以使用該框架以更簡單,更容易和更不易出錯的方式處理線程。 該程序包提供了一堆在并發編程中通常有用的實用程序類。
多年以來,對“啟用并發”程序的需求變得越來越大,因此該平臺采取了這一步驟,進一步引入了Java SE 7的新并發功能 。 功能之一是引入了Fork / Join框架,該框架原本打算包含在JDK 1.5版本中,但最終沒有成功。
Fork / Join框架旨在使分而治之算法易于并行化。 這種類型的算法非常適合可以分為兩個或多個相同類型的子問題的問題。 他們使用遞歸將問題分解為簡單的任務,直到這些任務變得足夠簡單以至于可以直接解決。 然后將子問題的解決方案合并以給出原始問題的解決方案。 關于Fork / Join方法的出色介紹是文章“ Java SE中的Fork-Join開發 ”。
您可能已經注意到,Fork / Join方法類似于MapReduce ,因為它們都是并行化任務的算法。 但是,一個區別是,只有在必要時(如果太大),Fork / Join任務才將自己細分為較小的任務,而MapReduce算法將其作為工作的第一步將所有工作分為幾部分。
Fork / Join Java框架起源于JSR-166,您可以在Doug Lea領導的并發JSR-166興趣站點中找到更多信息。 實際上,如果您希望使用該框架并且沒有JDK 7,則必須在這里進行操作。如站點中所述,我們可以使用JDK 1.5和1.6中的相關類,而不必安裝最新的JDK。 為此,我們必須下載jsr166 jar并使用-Xbootclasspath / p:jsr166.jar選項啟動JVM。 請注意,您可能需要在“ jsr166.jar”之前加上其完整文件路徑。 之所以必須這樣做,是因為JAR包含一些重寫核心Java類的類(例如java.util包下的類)。 不要忘記為JSR-166 API文檔添加書簽。
因此,讓我們看看如何使用該框架解決一個實際問題。 我們將創建一個程序來計算斐波納契數 (一個經典的教學問題),并查看如何使用新類使我們盡可能快。 Java Fork / Join + Groovy文章中也解決了此問題。
首先,我們創建一個表示問題的類,如下所示:
package com.javacodegeeks.concurrency.forkjoin;public class FibonacciProblem {public int n;public FibonacciProblem(int n) {this.n = n;}public long solve() {return fibonacci(n);}private long fibonacci(int n) {System.out.println("Thread: " +Thread.currentThread().getName() + " calculates " + n);if (n <= 1)return n;else return fibonacci(n-1) + fibonacci(n-2);}}如您所見,我們使用該解決方案的遞歸版本,這是一個典型的實現。 (請注意,此實現效率很高,因為它會一遍又一遍地計算相同的值。在實際情況下,已經緩存的計算值應在以后的執行中進行緩存和檢索)。 現在讓我們看一下單線程方法的外觀:
package com.javacodegeeks.concurrency.forkjoin;import org.perf4j.StopWatch;public class SillyWorker {public static void main(String[] args) throws Exception {int n = 10;StopWatch stopWatch = new StopWatch();FibonacciProblem bigProblem = new FibonacciProblem(n); long result = bigProblem.solve(); stopWatch.stop();System.out.println("Computing Fib number: " + n);System.out.println("Computed Result: " + result);System.out.println("Elapsed Time: " + stopWatch.getElapsedTime());}}我們只是創建一個新的FibonacciProblem并執行其solve方法,該方法將遞歸調用fibonacci方法。 我還使用漂亮的Perf4J庫來跟蹤經過的時間。 輸出將是這樣的(我隔離了最后幾行): …線程:main計算1線程:main計算0計算Fib數:10計算結果:55經過的時間:8如預期的那樣,所有工作都已完成只有一個線程(主線程)。 讓我們看看如何使用Fork / Join框架重寫它。 請注意,在Fibonacci解決方案中,將發生以下情況: fibonacci(n-1)+ fibonacci(n-2)因此,我們可以將這兩個任務中的每一個分配給一個新的工作程序(即新線程),然后工人已經完成處決,我們將加入結果。 考慮到這一點,我們引入了FibonacciTask類,該類本質上是將較大的Fibonacci問題劃分為較小的問題的一種方法。
package com.javacodegeeks.concurrency.forkjoin;import java.util.concurrent.RecursiveTask;public class FibonacciTask extends RecursiveTask<Long> {private static final long serialVersionUID = 6136927121059165206L;private static final int THRESHOLD = 5;private FibonacciProblem problem;public long result;public FibonacciTask(FibonacciProblem problem) {this.problem = problem;}@Overridepublic Long compute() {if (problem.n < THRESHOLD) { // easy problem, don't bother with parallelismresult = problem.solve();}else {FibonacciTask worker1 = new FibonacciTask(new FibonacciProblem(problem.n-1));FibonacciTask worker2 = new FibonacciTask(new FibonacciProblem(problem.n-2));worker1.fork();result = worker2.compute() + worker1.join();}return result;}}注意:如果您沒有使用JDK 7,而是手動包含了JSR-166庫,則必須覆蓋默認的Java核心類。 否則,您將遇到以下錯誤: java.lang.SecurityException:禁止的程序包名稱:java.util.concurrent為避免這種情況,請使用以下參數將JVM設置為覆蓋類: -Xbootclasspath / p:lib / jsr166.jar我使用了“ lib / jsr166.jar”值,因為該JAR駐留在我的Eclipse項目中一個名為“ lib”的文件夾中。 配置如下所示:
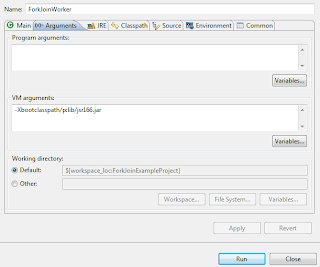
我們的任務擴展了RecursiveTask類,該類是遞歸結果的ForkJoinTask 。 我們將覆蓋處理此任務執行的主要計算的計算方法。 在該方法中,我們首先檢查是否必須使用并行性(通過與閾值進行比較)。 如果這是一個易于執行的任務,我們將直接調用solve方法,否則我們將創建兩個較小的任務,然后分別執行每個任務。 執行發生在不同的線程中,然后將其結果合并。 這可以通過使用fork和join方法來實現。 讓我們測試一下實現:
package com.javacodegeeks.concurrency.forkjoin;import java.util.concurrent.ForkJoinPool;import org.perf4j.StopWatch;public class ForkJoinWorker {public static void main(String[] args) {// Check the number of available processorsint processors = Runtime.getRuntime().availableProcessors();System.out.println("No of processors: " + processors);int n = 10;StopWatch stopWatch = new StopWatch(); FibonacciProblem bigProblem = new FibonacciProblem(n);FibonacciTask task = new FibonacciTask(bigProblem);ForkJoinPool pool = new ForkJoinPool(processors);pool.invoke(task);long result = task.result;System.out.println("Computed Result: " + result);stopWatch.stop();System.out.println("Elapsed Time: " + stopWatch.getElapsedTime());}}我們首先檢查系統中可用的處理器數量,然后創建具有相應并行度的新ForkJoinPool 。 我們使用invoke方法分配并執行任務。 這是輸出(我已經隔離了第一個和最后一個方法): 處理器數量:8線程:ForkJoinPool-1-worker-7計算4線程:ForkJoinPool-1-worker-6計算4線程:ForkJoinPool-1-worker- 4計算4…線程:ForkJoinPool-1-worker-2計算1線程:ForkJoinPool-1-worker-2計算0計算結果:55經過的時間:16請注意,現在將計算委托給多個工作線程,每個工作線程其中的一項任務比原來的任務要小。 您可能已經注意到,經過的時間大于上一個。 之所以發生這種矛盾,是因為我們使用了較低的閾值(5)和較低的n值(10)。 由于創建了大量線程,因此引入了不必要的延遲。 對于較大的閾值(大約20)和較高的n(40和更高),框架的真正力量將變得顯而易見。 我對n> 40的值進行了一些快速壓力測試,下面是帶有結果的圖表:
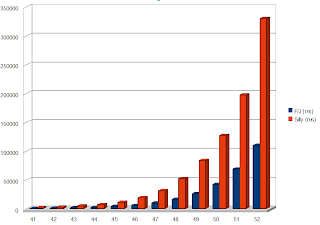 顯然,Fork / Join框架的伸縮性比單線程方法好得多,并且可以在更短的時間內執行計算。 (如果您希望自己進行一些壓力測試,請不要忘記刪除FibonacciProblem類中的System.out調用。)查看Windows 7計算機( i7- 720QM(具有4個內核和超線程 ),同時使用了每種方法。
顯然,Fork / Join框架的伸縮性比單線程方法好得多,并且可以在更短的時間內執行計算。 (如果您希望自己進行一些壓力測試,請不要忘記刪除FibonacciProblem類中的System.out調用。)查看Windows 7計算機( i7- 720QM(具有4個內核和超線程 ),同時使用了每種方法。
單線程: 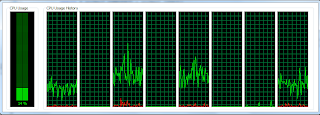 在執行過程中,CPU的總使用率仍然很低(從未超過16%)。 如您所見,當單線程應用程序難以執行所有計算時,CPU利用率不足。
在執行過程中,CPU的總使用率仍然很低(從未超過16%)。 如您所見,當單線程應用程序難以執行所有計算時,CPU利用率不足。
多線程:
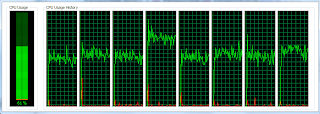 CPU利用率要好得多,所有處理器都有助于進行總計算。 在Java中介紹Fork / Join框架時,我們已經結束了。 請注意,這里我只是做些表面介紹,還存在許多其他功能,它們隨時可以幫助我們利用多核CPU。 一個新的時代正在出現,因此開發人員應該熟悉這些概念。 與往常一樣,您可以在這里找到為本文生成的源代碼。 別忘了分享!
CPU利用率要好得多,所有處理器都有助于進行總計算。 在Java中介紹Fork / Join框架時,我們已經結束了。 請注意,這里我只是做些表面介紹,還存在許多其他功能,它們隨時可以幫助我們利用多核CPU。 一個新的時代正在出現,因此開發人員應該熟悉這些概念。 與往常一樣,您可以在這里找到為本文生成的源代碼。 別忘了分享!
- 正確記錄應用程序的10個技巧
- 每個程序員都應該知道的事情
- Java最佳實踐–多線程環境中的DateFormat
- Java最佳實踐–隊列之戰和鏈接的ConcurrentHashMap
- Java最佳實踐–高性能序列化
- 更一般的等待/通知機制的CountDownLatch示例
- 受限連接池的阻塞隊列示例
- 任務運行器的重入鎖示例
- 可重入ReadWriteLock值計算器示例
翻譯自: https://www.javacodegeeks.com/2011/02/java-forkjoin-parallel-programming.html















![[團隊項目3.0]Scrum團隊成立](http://pic.xiahunao.cn/[團隊項目3.0]Scrum團隊成立)

判斷ch是否為字母或數字)

