
模型評估工具
TDgpt 在企業版中提供預測分析模型和異常檢測模型有效性評估工具 analytics_compare,該工具能夠使用 TDengine 中的時序數據作為
回測依據,評估不同預測模型或訓練模型的有效性。
該工具在開源版本中不可用
使用評估工具,需要在其相關的配置文件 taosanode.ini 中設置正確的參數,包括選取評估的數據范圍、結果輸出時間、參與評估的模型、模型的參數、是否生成預測結果圖等配置。
在具備完備的 Python 庫的運行環境中,通過 shell 調用 TDgpt 安裝路徑下的 misc 中 analytics_compare 的命令即可。
可按照如下方式體驗模型有效性評估工具:
在配置文件 analytics.ini 配置文件中設置 taosd 服務的連接信息,包括 主機地址、配置文件路徑、用戶名、登錄密碼等信息。
[taosd]
# taosd 服務主機名
host = 127.0.0.1
# 登錄用戶名
user = root# 登錄密碼
password = taosdata# 配置文件路徑
conf = /etc/taos/taos.cfg[input_data]# 用于預測評估的數據庫名稱
db_name = test# 讀取數據的表名稱
table_name = passengers# 讀取列名稱
column_name = val, _c0
評估預測分析模型
- 準備數據
在 TDgpt 安裝目錄下的 resource 文件夾中準備了樣例數據 sample-fc.sql, 執行以下命令即可將示例數據寫入數據庫,用于執行評估
taos -f sample-fc.sql
- 設置參數
[forecast]
# 評估用數據每個周期包含的數據點數量
period = 12# 預測生成結果的數據點數量
rows = 10# 評估用數據起始時間
start_time = 1949-01-01T00:00:00# 評估用數據結束時間
end_time = 1960-12-01T00:00:00# 返回結果的時間戳起始值
res_start_time = 1730000000000# 是否繪制預測結果
gen_figure = true[forecast.algos]
# 評估用的模型及參數
holtwinters={"trend":"add", "seasonal":"add"}
arima={"time_step": 3600000, "start_p": 0, "max_p": 5, "start_q": 0, "max_q": 5}
- 調用評估工具
python3 ./analytics_compare.py forecast
需確保激活虛擬環境并調用該虛擬環境的 Python,否則啟動的時候 Python 會提示找不到所需要的依賴庫。
- 檢查結果
在程序目錄下生成 fc_result.xlsx 文件,此文件即為模型評估的結果文件。預測有效性的評估使用 MSE 指標作為依據,后續還將增加 MAPE 和 MAE 指標。
該文件中第一個卡片是模型運行結果(如下表所示),分別是模型名稱、執行調用參數、均方誤差、執行時間 4 個指標。
| algorithm | params | MSE | elapsed_time(ms.) |
|---|---|---|---|
| holtwinters | {"trend":"add", "seasonal":"add"} | 351.622 | 125.1721 |
| arima | {"time_step":3600000, "start_p":0, "max_p":10, "start_q":0, "max_q":10} | 433.709 | 45577.9187 |
如果配置文件 analytics.ini 中設置 gen_figure 為 true,分析結果文件中的后續卡片中在針對每個模型繪制分析預測結果圖(如下圖)。
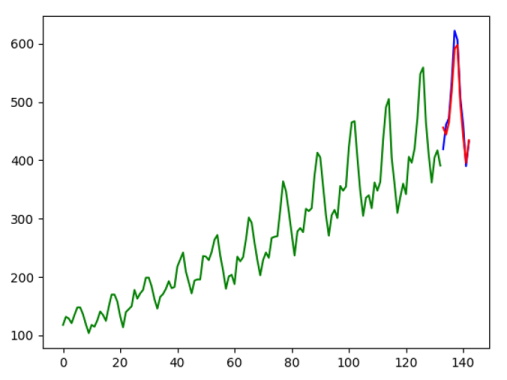
評估異常檢測模型
針對異常檢測模型提供查全率(recall)和查準率(precision)兩個指標衡量模型有效性。
通過在配置文件中analysis.ini設置以下的選項可以調用需要使用的異常檢測模型,異常檢測模型測試用數據的時間范圍、是否生成標注結果的圖片、調用的異常檢測模型以及相應的參數。
- 準備數據
在 TDgpt 安裝目錄下的 resource 文件夾中準備了樣例數據 sample-ad.sql, 執行以下命令即可將示例數據寫入數據庫
taos -f sample-ad.sql
- 設置參數
[ad]
# 數據集起始時間戳
start_time = 2021-01-01T01:01:01# 數據集結束時間戳
end_time = 2021-01-01T01:01:11# 是否繪制檢測結果
gen_figure = true# 標注異常檢測結果
anno_res = [9]# 用于比較的模型及相關參數設置
[ad.algos]
ksigma={"k": 2}
iqr={}
grubbs={}
lof={"algorithm":"auto", "n_neighbor": 3}
-
標注異常檢測結果
調用異常檢測模型比較之前,需要人工標注異常監測數據集結果,即在 [anno_res] 選項下標注異常點在測試數組中的位置。
例如:在 sample-ad 測試數據集中第 9 個點是異常點。需要在 [anno_res] 下異常標注 [9]。如果第 0 個點和第 9 個點是異常點,則
設置為 [0, 9] -
調用評估工具
python3 ./analytics_compare.py anomaly-detection
- 檢查結果
對比程序執行完成以后,會自動生成名稱為 ad_result.xlsx 的文件,第一個卡片是模型運行結果(如下表所示),分別是模型名稱、執行調用參數、查全率、查準率、執行時間 5 個指標。
| algorithm | params | precision(%) | recall(%) | elapsed_time(ms.) |
|---|---|---|---|---|
| ksigma | {"k":2} | 100 | 100 | 0.453 |
| iqr | {} | 100 | 100 | 2.727 |
| grubbs | {} | 100 | 100 | 2.811 |
| lof | {"algorithm":"auto", "n_neighbor":3} | 0 | 0 | 4.660 |
如果設置了 gen_figure 為 true,比較程序會自動將每個參與比較的模型分析結果采用圖片方式呈現出來(如下圖所示為 ksigma 的異常檢測結果標注)。
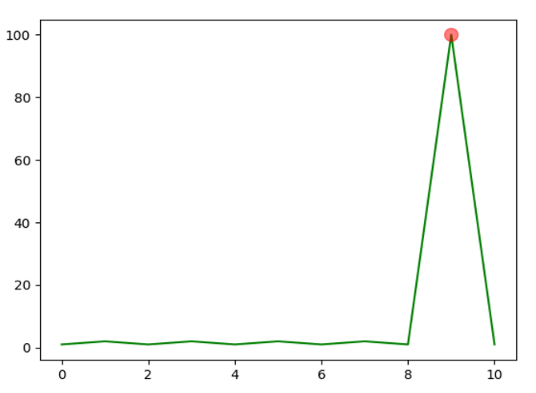

、Eden區和Survivor區概念介紹)






)


:vi/vim)






:PWM(脈沖寬度調制))
)