本文整理了網上幾位大牛的博客,詳細地講解了CNN的基礎結構與核心思想,歡迎交流
[1]Deep learning簡介
[2]Deep Learning訓練過程
[3]Deep Learning模型之:CNN卷積神經網絡推導和實現
[4]Deep Learning模型之:CNN的反向求導及練習
[5]Deep Learning模型之:CNN卷積神經網絡(一)深度解析CNN
[6]Deep Learning模型之:CNN卷積神經網絡(二)文字識別系統LeNet-5
[7]Deep Learning模型之:CNN卷積神經網絡(三)CNN常見問題總結
1.?概述
? ?卷積神經網絡是一種特殊的深層的神經網絡模型,它的特殊性體現在兩個方面,一方面它的神經元間的連接是非全連接的,?另一方面同一層中某些神經元之間的連接的權重是共享的(即相同的)。它的非全連接和權值共享的網絡結構使之更類似于生物?神經網絡,降低了網絡模型的復雜度(對于很難學習的深層結構來說,這是非常重要的),減少了權值的數量。
? ? ?回想一下BP神經網絡。BP網絡每一層節點是一個線性的一維排列狀態,層與層的網絡節點之間是全連接的。這樣設想一下,如果BP網絡中層與層之間的節點連接不再是全連接,而是局部連接的。這樣,就是一種最簡單的一維卷積網絡。如果我們把上述這個思路擴展到二維,這就是我們在大多數參考資料上看到的卷積神經網絡。具體參看下圖:
?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
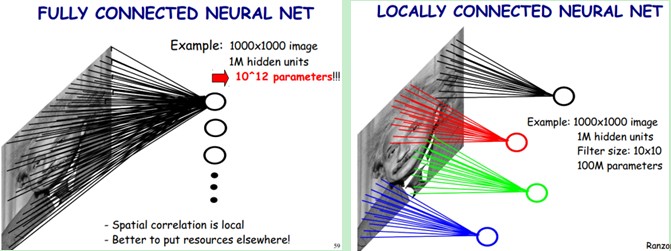
? ? ???上圖左:全連接網絡。如果我們有1000x1000像素的圖像,有1百萬個隱層神經元,每個隱層神經元都連接圖像的每一個像素點,就有1000x1000x1000000=10^12個連接,也就是10^12個權值參數。
? ? ? ?上圖右:局部連接網絡,每一個節點與上層節點同位置附件10x10的窗口相連接,則1百萬個隱層神經元就只有100w乘以100,即10^8個參數。其權值連接個數比原來減少了四個數量級。
? ? ? 根據BP網絡信號前向傳遞過程,我們可以很容易計算網絡節點的輸出。例如,對于上圖中被標注為紅色節點的凈輸入,就等于所有與紅線相連接的上一層神經元節點值與紅色線表示的權值之積的累加。這樣的計算過程,很多書上稱其為卷積。
? ? ? ?事實上,對于數字濾波而言,其濾波器的系數通常是對稱的。否則,卷積的計算需要先反向對折,然后進行乘累加的計算。上述神經網絡權值滿足對稱嗎?我想答案是否定的!所以,上述稱其為卷積運算,顯然是有失偏頗的。但這并不重要,僅僅是一個名詞稱謂而已。只是,搞信號處理的人,在初次接觸卷積神經網絡的時候,帶來了一些理解上的誤區。
?
? ? ? ? 卷積神經網絡另外一個特性是權值共享。例如,就上面右邊那幅圖來說,權值共享,也就是說所有的紅色線標注的連接權值相同。這一點,初學者容易產生誤解。
? ? ? ? 上面描述的只是單層網絡結構,前A&T?Shannon Lab?? 的? Yann LeCun等人據此提出了基于卷積神經網絡的一個文字識別系統 LeNet-5。該系統90年代就被用于銀行手寫數字的識別。
2、 CNN的結構
卷積網絡是為識別二維形狀而特殊設計的一個多層感知器,這種網絡結構對平移、比例縮放、傾斜或者共他形式的變形具有高度不變性。?這些良好的性能是網絡在有監督方式下學會的,網絡的結構主要有稀疏連接和權值共享兩個特點,包括如下形式的約束:
1、?特征提取。每一個神經元從上一層的局部接受域得到突觸輸人,因而迫使它提取局部特征。一旦一個特征被提取出來,?只要它相對于其他特征的位置被近似地保留下來,它的精確位置就變得沒有那么重要了。
2 、特征映射。網絡的每一個計算層都是由多個特征映射組成的,每個特征映射都是平面形式的。平面中單獨的神經元在約束下共享?相同的突觸權值集,這種結構形式具有如下的有益效果:a.平移不變性。b.自由參數數量的縮減(通過權值共享實現)。
3、子抽樣。每個卷積層后面跟著一個實現局部平均和子抽樣的計算層,由此特征映射的分辨率降低。這種操作具有使特征映射的輸出對平移和其他?形式的變形的敏感度下降的作用。
卷積神經網絡是一個多層的神經網絡,每層由多個二維平面組成,而每個平面由多個獨立神經元組成。
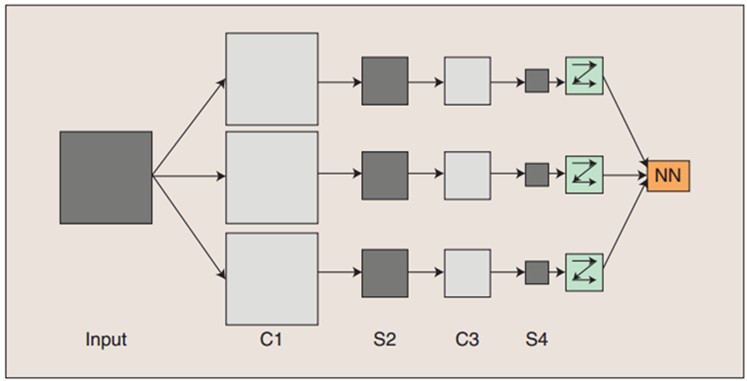
?????? 圖:卷積神經網絡的概念示范:輸入圖像通過和三個可訓練的濾波器和可加偏置進行卷積,卷積后在C1層產生三個特征映射圖,然后特征映射圖中每組的四個像素再進行求和,加權值,加偏置,通過一個Sigmoid函數得到三個S2層的特征映射圖。這些映射圖再進過濾波得到C3層。這個層級結構再和S2一樣產生S4。最終,這些像素值被光柵化,并連接成一個向量輸入到傳統的神經網絡,得到輸出。
?????? 一般地,C層為特征提取層,每個神經元的輸入與前一層的局部感受野相連,并提取該局部的特征,一旦該局部特征被提取后,它與其他特征間的位置關系也隨之確定下來;S層是特征映射層,網絡的每個計算層由多個特征映射組成,每個特征映射為一個平面,平面上所有神經元的權值相等。特征映射結構采用影響函數核小的sigmoid函數作為卷積網絡的激活函數,使得特征映射具有位移不變性。
?????? 此外,由于一個映射面上的神經元共享權值,因而減少了網絡自由參數的個數,降低了網絡參數選擇的復雜度。卷積神經網絡中的每一個特征提取層(C-層)都緊跟著一個用來求局部平均與二次提取的計算層(S-層),這種特有的兩次特征提取結構使網絡在識別時對輸入樣本有較高的畸變容忍能力。
2.1?稀疏連接(Sparse?Connectivity)
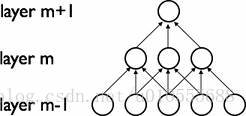
卷積網絡通過在相鄰兩層之間強制使用局部連接模式來利用圖像的空間局部特性,在第m層的隱層單元只與第m-1層的輸入單元的局部區域有連接,第m-1層的這些局部?區域被稱為空間連續的接受域。我們可以將這種結構描述如下:
設第m-1層為視網膜輸入層,第m層的接受域的寬度為3,也就是說該層的每個單元與且僅與輸入層的3個相鄰的神經元相連,第m層與第m+1層具有類似的鏈接規則,如下圖所示。
?
?
? ? 可以看到m+1層的神經元相對于第m層的接受域的寬度也為3,但相對于輸入層的接受域為5,這種結構將學習到的過濾器(對應于輸入信號中被最大激活的單元)限制在局部空間?模式(因為每個單元對它接受域外的variation不做反應)。從上圖也可以看出,多個這樣的層堆疊起來后,會使得過濾器(不再是線性的)逐漸成為全局的(也就是覆蓋到了更?大的視覺區域)。例如上圖中第m+1層的神經元可以對寬度為5的輸入進行一個非線性的特征編碼。
?
2.2?權值共享(Shared?Weights)
在卷積網絡中,每個稀疏過濾器hi通過共享權值都會覆蓋整個可視域,這些共享權值的單元構成一個特征映射,如下圖所示。
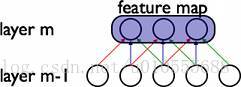
? ??在圖中,有3個隱層單元,他們屬于同一個特征映射。同種顏色的鏈接的權值是相同的,我們仍然可以使用梯度下降的方法來學習這些權值,只需要對原始算法做一些小的改動,?這里共享權值的梯度是所有共享參數的梯度的總和。我們不禁會問為什么要權重共享呢?一方面,重復單元能夠對特征進行識別,而不考慮它在可視域中的位置。另一方面,權值?共享使得我們能更有效的進行特征抽取,因為它極大的減少了需要學習的自由變量的個數。通過控制模型的規模,卷積網絡對視覺問題可以具有很好的泛化能力。
?
舉例講解:???
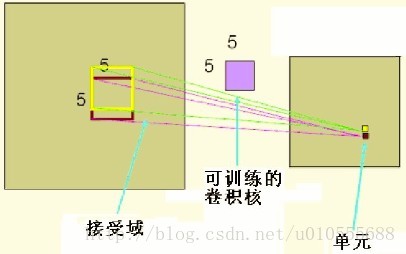
? ? ?上面聊到,好像CNN一個牛逼的地方就在于通過感受野和權值共享減少了神經網絡需要訓練的參數的個數。那究竟是啥的呢?
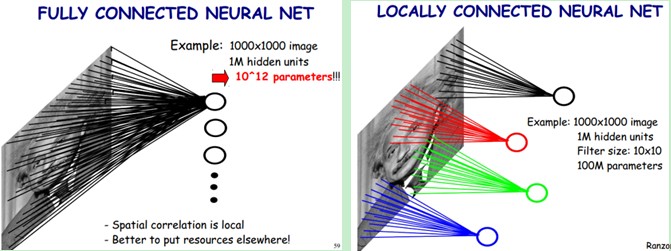
? ? ?下圖左:如果我們有1000x1000像素的圖像,有1百萬個隱層神經元,那么他們全連接的話(每個隱層神經元都連接圖像的每一個像素點),就有1000x1000x1000000=10^12個連接,也就是10^12個權值參數。然而圖像的空間聯系是局部的,就像人是通過一個局部的感受野去感受外界圖像一樣,每一個神經元都不需要對全局圖像做感受,每個神經元只感受局部的圖像區域,然后在更高層,將這些感受不同局部的神經元綜合起來就可以得到全局的信息了。這樣,我們就可以減少連接的數目,也就是減少神經網絡需要訓練的權值參數的個數了。如下圖右:假如局部感受野是10x10,隱層每個感受野只需要和這10x10的局部圖像相連接,所以1百萬個隱層神經元就只有一億個連接,即10^8個參數。比原來減少了四個0(數量級),這樣訓練起來就沒那么費力了,但還是感覺很多的啊,那還有啥辦法沒?
?
?????? 我們知道,隱含層的每一個神經元都連接10x10個圖像區域,也就是說每一個神經元存在10x10=100個連接權值參數。那如果我們每個神經元這100個參數是相同的呢?也就是說每個神經元用的是同一個卷積核去卷積圖像。這樣我們就只有多少個參數??只有100個參數啊!!!親!不管你隱層的神經元個數有多少,兩層間的連接我只有100個參數啊!親!這就是權值共享啊!親!這就是卷積神經網絡的主打賣點啊!親!(有點煩了,呵呵)也許你會問,這樣做靠譜嗎?為什么可行呢?這個……共同學習。
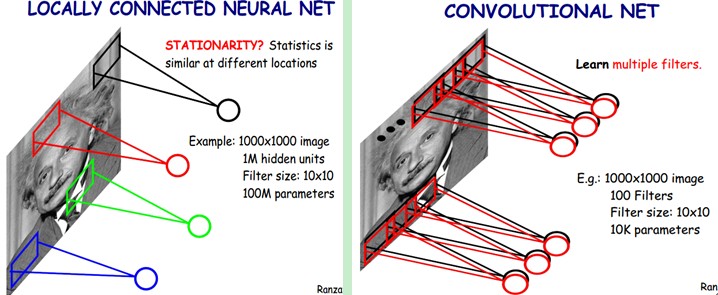
?????? 好了,你就會想,這樣提取特征也忒不靠譜吧,這樣你只提取了一種特征啊?對了,真聰明,我們需要提取多種特征對不?假如一種濾波器,也就是一種卷積核就是提出圖像的一種特征,例如某個方向的邊緣。那么我們需要提取不同的特征,怎么辦,加多幾種濾波器不就行了嗎?對了。所以假設我們加到100種濾波器,每種濾波器的參數不一樣,表示它提出輸入圖像的不同特征,例如不同的邊緣。這樣每種濾波器去卷積圖像就得到對圖像的不同特征的放映,我們稱之為Feature Map。所以100種卷積核就有100個Feature Map。這100個Feature Map就組成了一層神經元。到這個時候明了了吧。我們這一層有多少個參數了?100種卷積核x每種卷積核共享100個參數=100x100=10K,也就是1萬個參數。才1萬個參數啊!親!(又來了,受不了了!)見下圖右:不同的顏色表達不同的濾波器。
?
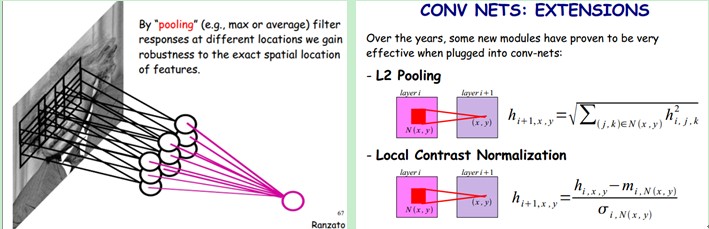
?????? 嘿喲,遺漏一個問題了。剛才說隱層的參數個數和隱層的神經元個數無關,只和濾波器的大小和濾波器種類的多少有關。那么隱層的神經元個數怎么確定呢?它和原圖像,也就是輸入的大小(神經元個數)、濾波器的大小和濾波器在圖像中的滑動步長都有關!例如,我的圖像是1000x1000像素,而濾波器大小是10x10,假設濾波器沒有重疊,也就是步長為10,這樣隱層的神經元個數就是(1000x1000 )/ (10x10)=100x100個神經元了,假設步長是8,也就是卷積核會重疊兩個像素,那么……我就不算了,思想懂了就好。注意了,這只是一種濾波器,也就是一個Feature Map的神經元個數哦,如果100個Feature Map就是100倍了。由此可見,圖像越大,神經元個數和需要訓練的權值參數個數的貧富差距就越大。
?
??????需要注意的一點是,上面的討論都沒有考慮每個神經元的偏置部分。所以權值個數需要加1 。這個也是同一種濾波器共享的。
????? 總之,卷積網絡的核心思想是將:局部感受野、權值共享(或者權值復制)以及時間或空間亞采樣這三種結構思想結合起來獲得了某種程度的位移、尺度、形變不變性。
2.3?The?Full?Model
? ??? ? 卷積神經網絡是一個多層的神經網絡,每層由多個二維平面組成,而每個平面由多個獨立神經元組成。網絡中包含一些簡單元和復雜元,分別記為S-元?和C-元。S-元聚合在一起組成S-面,S-面聚合在一起組成S-層,用Us表示。C-元、C-面和C-層(Us)之間存在類似的關系。網絡的任一中間級由S-層與C-層?串接而成,而輸入級只含一層,它直接接受二維視覺模式,樣本特征提取步驟已嵌入到卷積神經網絡模型的互聯結構中。
一般地,Us為特征提取層(子采樣層),每個神經元的輸入與前一層的局部感受野相連,并提取該局部的特征,一旦該局部特征被提取后,它與其他特征間的位置關系?也隨之確定下來;
Uc是特征映射層(卷積層),網絡的每個計算層由多個特征映射組成,每個特征映射為一個平面,平面上所有神經元的權值相等。特征映射結構采用?影響函數核小的sigmoid函數作為卷積網絡的激活函數,使得特征映射具有位移不變性。此外,由于?一個映射面上的神經元共享權值,因而減少了網絡自由參數的個數,降低了網絡參數選擇的復雜度。卷積神經網絡中的每一個特征提取層(S-層)都緊跟著一個?用來求局部平均與二次提取的計算層(C-層),這種特有的兩次特征提取結構使網絡在識別時對輸入樣本有較高的畸變容忍能力。
下圖是一個卷積網絡的實例,在博文”Deep Learning模型之:CNN卷積神經網絡(二)?文字識別系統LeNet-5?“中有詳細講解:
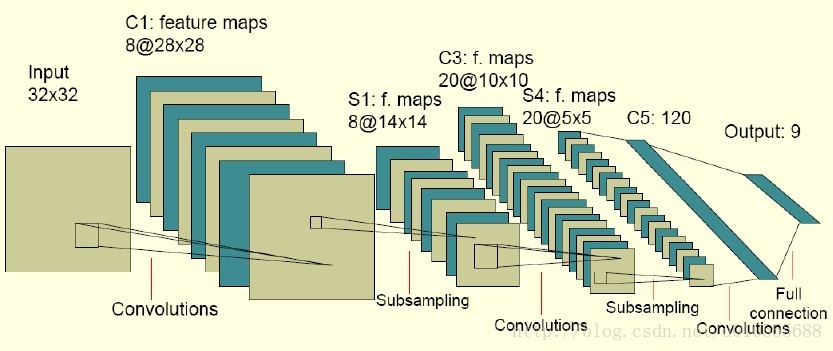
? ??圖中的卷積網絡工作流程如下,輸入層由32×32個感知節點組成,接收原始圖像。然后,計算流程在卷積和子抽樣之間交替進行,如下所述:
? ? 第一隱藏層進行卷積,它由8個特征映射組成,每個特征映射由28×28個神經元組成,每個神經元指定一個?5×5?的接受域;
? ? 第二隱藏層實現子?抽樣和局部平均,它同樣由?8?個特征映射組成,但其每個特征映射由14×14?個神經元組成。每個神經元具有一個?2×2?的接受域,一個可訓練?系數,一個可訓練偏置和一個?sigmoid?激活函數。可訓練系數和偏置控制神經元的操作點。
? ? 第三隱藏層進行第二次卷積,它由?20?個特征映射組?成,每個特征映射由?10×10?個神經元組成。該隱藏層中的每個神經元可能具有和下一個隱藏層幾個特征映射相連的突觸連接,它以與第一個卷積?層相似的方式操作。
? ? 第四個隱藏層進行第二次子抽樣和局部平均汁算。它由?20?個特征映射組成,但每個特征映射由?5×5?個神經元組成,它以?與第一次抽樣相似的方式操作。
? ? 第五個隱藏層實現卷積的最后階段,它由?120?個神經元組成,每個神經元指定一個?5×5?的接受域。
? ? 最后是個全?連接層,得到輸出向量。
? ? 相繼的計算層在卷積和抽樣之間的連續交替,我們得到一個“雙尖塔”的效果,也就是在每個卷積或抽樣層,隨著空?間分辨率下降,與相應的前一層相比特征映射的數量增加。卷積之后進行子抽樣的思想是受到動物視覺系統中的“簡單的”細胞后面跟著“復雜的”細胞的想法的啟發而產生的。
圖中所示的多層感知器包含近似?100000?個突觸連接,但只有大約2600?個自由參數(每個特征映射為一個平面,平面上所有神經元的權值相等)。自由參數在數量上顯著地減少是通過權值共享獲得?的,學習機器的能力(以?VC?維的形式度量)因而下降,這又提高它的泛化能力。而且它對自由參數的調整通過反向傳播學習的隨機形式來實?現。另一個顯著的特點是使用權值共享使得以并行形式實現卷積網絡變得可能。這是卷積網絡對全連接的多層感知器而言的另一個優點。
3、 CNN的訓練
? ? ? ??神經網絡用于模式識別的主流是有指導學習網絡,無指導學習網絡更多的是用于聚類分析。對于有指導的模式識別,由于任一樣本的類別是已知的,樣本在空間的分布不再是依據其自然分布傾向來劃分,而是要根據同類樣本在空間的分布及不同類樣本之間的分離程度找一種適當的空間劃分方法,或者找到一個分類邊界,使得不同類樣本分別位于不同的區域內。這就需要一個長時間且復雜的學習過程,不斷調整用以劃分樣本空間的分類邊界的位置,使盡可能少的樣本被劃分到非同類區域中。
?????? 卷積網絡在本質上是一種輸入到輸出的映射,它能夠學習大量的輸入與輸出之間的映射關系,而不需要任何輸入和輸出之間的精確的數學表達式,只要用已知的模式對卷積網絡加以訓練,網絡就具有輸入輸出對之間的映射能力。卷積網絡執行的是有導師訓練,所以其樣本集是由形如:(輸入向量,理想輸出向量)的向量對構成的。所有這些向量對,都應該是來源于網絡即將模擬的系統的實際“運行”結果。它們可以是從實際運行系統中采集來的。在開始訓練前,所有的權都應該用一些不同的小隨機數進行初始化。“小隨機數”用來保證網絡不會因權值過大而進入飽和狀態,從而導致訓練失敗;“不同”用來保證網絡可以正常地學習。實際上,如果用相同的數去初始化權矩陣,則網絡無能力學習。
?????? 訓練算法與傳統的BP算法差不多。主要包括4步,這4步被分為兩個階段:
第一階段,向前傳播階段:
a)從樣本集中取一個樣本(X,Yp),將X輸入網絡;
b)計算相應的實際輸出Op。
????? 在此階段,信息從輸入層經過逐級的變換,傳送到輸出層。這個過程也是網絡在完成訓練后正常運行時執行的過程。在此過程中,網絡執行的是計算(實際上就是輸入與每層的權值矩陣相點乘,得到最后的輸出結果):
????????? Op=Fn(…(F2(F1(XpW(1))W(2))…)W(n))
第二階段,向后傳播階段
a)算實際輸出Op與相應的理想輸出Yp的差;
b)按極小化誤差的方法反向傳播調整權矩陣。
?
總體而言,卷積網絡可以簡化為下圖所示模型:
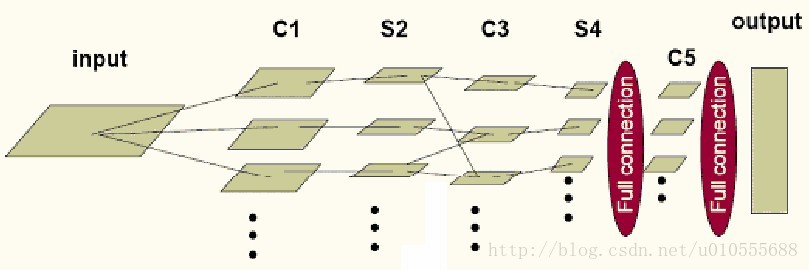
? ??其中,input?到C1、S4到C5、C5到output是全連接,C1到S2、C3到S4是一一對應的連接,S2到C3為了消除網絡對稱性,去掉了一部分連接,?可以讓特征映射更具多樣性。需要注意的是?C5?卷積核的尺寸要和?S4?的輸出相同,只有這樣才能保證輸出是一維向量。
4.1?卷積層的學習
卷積層的典型結構如下圖所示:
卷積層的前饋運算是通過如下算法實現的:
卷積層的輸出=?Sigmoid(?Sum(卷積)?+偏移量)
其中卷積核和偏移量都是可訓練的。下面是其核心代碼:
ConvolutionLayer::fprop(input,output) {//取得卷積核的個數int n=kernel.GetDim(0);for (int i=0;i<n;i++) {//第i個卷積核對應輸入層第a個特征映射,輸出層的第b個特征映射//這個卷積核可以形象的看作是從輸入層第a個特征映射到輸出層的第b個特征映射的一個鏈接int a=table[i][0], b=table[i][1];//用第i個卷積核和輸入層第a個特征映射做卷積convolution = Conv(input[a],kernel[i]);//把卷積結果求和sum[b] +=convolution;}for (i=0;i<(int)bias.size();i++) {//加上偏移量sum[i] += bias[i];}//調用Sigmoid函數output = Sigmoid(sum);
}? ? 其中,input是?n1×n2×n3?的矩陣,n1是輸入層特征映射的個數,n2是輸入層特征映射的寬度,n3是輸入層特征映射的高度。output,?sum,?convolution,?bias是n1×(n2-kw+1)×(n3-kh+1)的矩陣,kw,kh是卷積核的寬度高度(圖中是5×5)。kernel是卷積核矩陣。table是連接表,即如果第a輸入和第b個輸出之間?有連接,table里就會有[a,b]這一項,而且每個連接都對應一個卷積核。
?
?
?
卷積層的反饋運算的核心代碼如下:
?
ConvolutionLayer::bprop(input,output,in_dx,out_dx) {//梯度通過DSigmoid反傳sum_dx = DSigmoid(out_dx);//計算bias的梯度for (i=0;i<bias.size();i++) {bias_dx[i] = sum_dx[i];}//取得卷積核的個數int n=kernel.GetDim(0);for (int i=0;i<n;i++){int a=table[i][0],b=table[i][1];//用第i個卷積核和第b個輸出層反向卷積(即輸出層的一點乘卷積模板返回給輸入層),并把結果累加到第a個輸入層input_dx[a] += DConv(sum_dx[b],kernel[i]);//用同樣的方法計算卷積模板的梯度kernel_dx[i] += DConv(sum_dx[b],input[a]);}
}?
其中in_dx,out_dx?的結構和?input,output?相同,代表的是相應點的梯度。
4.2?子采樣層的學習
子采樣層的典型結構如下圖所示:

類似的子采樣層的輸出的計算式為:
輸出=?Sigmoid(?采樣*權重?+偏移量)?
其核心代碼如下:
?
SubSamplingLayer::fprop(input,output) {int n1= input.GetDim(0);int n2= input.GetDim(1);int n3= input.GetDim(2);for (int i=0;i<n1;i++) {for (int j=0;j<n2;j++) {for (int k=0;k<n3;k++) {//coeff 是可訓練的權重,sw 、sh 是采樣窗口的尺寸。sub[i][j/sw][k/sh] += input[i][j][k]*coeff[i];}}}for (i=0;i<n1;i++) {//加上偏移量sum[i] = sub[i] + bias[i];}output = Sigmoid(sum);
}?
?
子采樣層的反饋運算的核心代碼如下:
?
SubSamplingLayer::bprop(input,output,in_dx,out_dx) {//梯度通過DSigmoid反傳sum_dx = DSigmoid(out_dx);//計算bias和coeff的梯度for (i=0;i<n1;i++) {coeff_dx[i] = 0;bias_dx[i] = 0;for (j=0;j<n2/sw;j++)for (k=0;k<n3/sh;k++) {coeff_dx[i] += sub[j][k]*sum_dx[i][j][k];bias_dx[i] += sum_dx[i][j][k]);}}for (i=0;i<n1;i++) {for (j=0;j<n2;j++)for (k=0;k<n3;k++) {in_dx[i][j][k] = coeff[i]*sum_dx[i][j/sw][k/sh];}}
}?
5、CNN的優點
????????卷積神經網絡CNN主要用來識別位移、縮放及其他形式扭曲不變性的二維圖形。由于CNN的特征檢測層通過訓練數據進行學習,所以在使用CNN時,避免了顯式的特征抽取,而隱式地從訓練數據中進行學習;再者由于同一特征映射面上的神經元權值相同,所以網絡可以并行學習,這也是卷積網絡相對于神經元彼此相連網絡的一大優勢。卷積神經網絡以其局部權值共享的特殊結構在語音識別和圖像處理方面有著獨特的優越性,其布局更接近于實際的生物神經網絡,權值共享降低了網絡的復雜性,特別是多維輸入向量的圖像可以直接輸入網絡這一特點避免了特征提取和分類過程中數據重建的復雜度。
??????? 流的分類方式幾乎都是基于統計特征的,這就意味著在進行分辨前必須提取某些特征。然而,顯式的特征提取并不容易,在一些應用問題中也并非總是可靠的。卷積神經網絡,它避免了顯式的特征取樣,隱式地從訓練數據中進行學習。這使得卷積神經網絡明顯有別于其他基于神經網絡的分類器,通過結構重組和減少權值將特征提取功能融合進多層感知器。它可以直接處理灰度圖片,能夠直接用于處理基于圖像的分類。
?????? 卷積網絡較一般神經網絡在圖像處理方面有如下優點: a)輸入圖像和網絡的拓撲結構能很好的吻合;b)特征提取和模式分類同時進行,并同時在訓練中產生;c)權重共享可以減少網絡的訓練參數,使神經網絡結構變得更簡單,適應性更強。
6、CNN的實現問題
???????CNNs中這種層間聯系和空域信息的緊密關系,使其適于圖像處理和理解。而且,其在自動提取圖像的顯著特征方面還表現出了比較優的性能。在一些例子當中,Gabor濾波器已經被使用在一個初始化預處理的步驟中,以達到模擬人類視覺系統對視覺刺激的響應。在目前大部分的工作中,研究者將CNNs應用到了多種機器學習問題中,包括人臉識別,文檔分析和語言檢測等。為了達到尋找視頻中幀與幀之間的相干性的目的,目前CNNs通過一個時間相干性去訓練,但這個不是CNNs特有的。? ? ?
References:
卷積神經網絡(CNN)
GitHub卷及神經網絡代碼(MATLAB)
CNN代碼理解(matlab)
http://blog.csdn.net/nan355655600/article/details/17690029
http://blog.csdn.net/zouxy09/article/details/8782018
本文轉自博客園知識天地的博客,原文鏈接:Deep Learning(深度學習)學習筆記整理(二),如需轉載請自行聯系原博主。







)









----------------Tju_Oj_3517The longest athletic track)

 —— AnalogClock)