目錄
一、理論知識回顧
1、神經網絡模型
2、明確任務以及參數
1)待估參數:
2)超參數:
3)任務
3、神經網絡數學模型定義
1)激活函數
?
2)各層權重、閾值定義
3)各層輸入輸出定義
4、優化問題的目標函數與迭代公式
1)目標函數
2)待估參數的優化迭代公式
二、python編程
1、編程步驟
2、數據準備、數據處理、數據劃分
1)數據下載
2)關鍵代碼
3、初始化待估參數
1)關鍵代碼
2)np.random.randint(a,b,(m,n))函數
3)astype(np.float64)
4、創建激活函數
5、參數迭代更新
1)關鍵代碼
2)dot、multiply
3)難點
6、測試模型
7、主函數運行
三、總結
1、幾個循環
2、問題集錦
1)若是有多個輸出怎么辦?
2)BP算法為什么叫做后向傳播?
四、完整代碼
堅持嗑完這篇文章一定會明白神經網絡BP算法的精髓所在的,以及各層之間誤差的互相影響以及傳播
一、理論知識回顧
參考文章:
《機器學習——人工神經網絡之發展歷史(神經元數學模型、感知器算法)》
《機器學習——人工神經網絡之多層神經網絡(多層與三層)》
《機器學習——人工神經網絡之后向傳播算法(BP算法)》
《機器學習——人工神經網絡之參數設置(BP算法)》
1、神經網絡模型
一個神經元即一個感知機模型,由多個神經元相互連接形成的網絡,即神經網絡。
這里我們只討論單隱層前饋神經網絡,其連接形式入下:

2、明確任務以及參數
1)待估參數:
每個神經元的閾值b或者value,以及神經元之間的連接權重weight。
2)超參數:
超參數就是求解不出來,需要用戶自己定義的參數,如在神經網絡中,超參數有:
神經網絡隱層的層數,一般只考慮隱層的層數,因為輸入層和輸出層一般默認為一層
每一層神經網絡的神經元個數:神經元的個數直接影響著待估參數的個數,假設隱層第m層有k個神經元,第m+1層有l個神經元,那么這兩層之間的權重系數weight的個數為k*l個,一般組成(k,l)矩陣的形式;每一層的閾值或者叫做偏置的個數和神經元個數相同
神經網絡:可能這個聽起來比較抽象,但是這就是需要自己進行定義的,具體見代碼,主要是指定神經網絡層數,每層神經元的個數,確定待估參數的初始值就基本上將神經網絡給定義好了
3)任務

通過訓練樣本將定義的神經網絡模型進行不斷的優化,將待測參數進行不斷的迭代,直到滿足條件為止(條件理論上是目標函數E對所有的待測參數的偏導為0,但是計算機沒有絕對的0值,因此一般通過迭代次數和偏導的最小值來作為迭代的終止條件)
3、神經網絡數學模型定義
對于該模型有如下定義:
訓練集:D={(x1, y1), (x2, y2), ......, (xm, ym)},x具有d個屬性值,y具有k個可能取值
則我們的神經網絡(單隱層前饋神經網絡)應該是具有d個輸入神經元,q個隱層神經元,k個輸出層神經元的神經網絡 ,我們默認輸入層只是數據的輸入,不對數據做處理,即輸入層沒有閾值。
1)激活函數
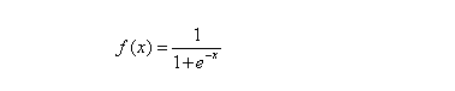
2)各層權重、閾值定義
輸出層第j個神經元的閾值為:θj
隱層第h個神經元的閾值為:γh(γ是Gamma)
輸入層第i個神經元與隱層第h個神經元的連接權重為:vih
隱層第h個神經元與輸出層第j個神經元的連接權重為:ωhj
3)各層輸入輸出定義
輸入層的輸入和輸出一樣,就是樣本數據
隱層第h個神經元的輸入
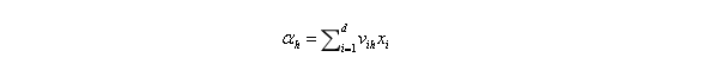
隱層第h個神經元的輸出
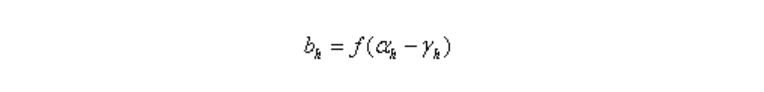
輸出層第j個神經元的輸入
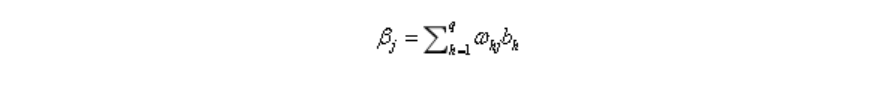
輸出層的輸出跟隱層的輸出類似
4、優化問題的目標函數與迭代公式
1)目標函數
對參數進行估計,需要有優化方向,我們繼續使用歐式距離,或者均方誤差來作為優化目標:

2)待估參數的優化迭代公式
我們使用梯度下降的策略對參數進行迭代優化,所以任意一個參數的變化大小為(θ代表任意參數):

下面根據這個更新公式,我們來求各個參數的更新公式:
對數幾率函數的導數如下:
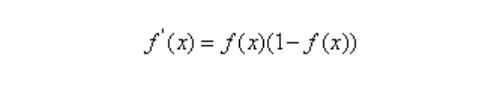
輸出層第j個神經元的閾值θj:


?隱層第h個神經元的閾值γh:
 ?
?
 ?
?
輸入層第i個神經元與隱層第h個神經元的連接權重vih?:?

 ?
?
隱層第h個神經元與輸出層第j個神經元的連接權重ωhj:?

 ?
?
現在四個參數的更新規則都計算出來了,我們可以開始編碼實現了。?
現在有一個問題:在二分類任務中,輸出層神經元有幾個?
???????????????????????????? 一個:如果只有1個,那么輸出0表示反例,1表示正例
???????????????????????????? 二個:那么輸出(1,0)表示反例,(0,1)表示正例
以下實例我們使用第一種:即輸出層的神經元只有一個
二、python編程
1、編程步驟
數據準備(通過讀取數據文件獲取)
數據處理(讀取的數據是字符串形式,需要將其轉換為浮點數或者整型)
數據劃分(將特征和標簽分割開)
初始化待估參數(通過自定義超參數每層神經元的個數來進行初始化待估參數)——這里不需要定義層數,因為這里只有一個隱層
參數迭代更新(用初始化的待估參數去對樣本數據進行逐一訓練,并且不斷地迭代更新,最后得到最優的待估參數)——這里和上一步其實就基本上將整個神經網絡的框架已經搭建好了
測試模型(利用上面得到的參數,對測試樣本集進行測試,查看準確率)
2、數據準備、數據處理、數據劃分
1)數據下載
我們使用一個二分類數據集:馬疝病數據集
UCI下載地址為:http://archive.ics.uci.edu/ml/datasets/Horse+Colic
或者:
以下是用戶《9527----到》提供的,可見文章:《基于tensorflow的logistics回歸--數據集為 horseColicTest and horseColicTraining.txt(文章底部附數據集鏈接)》文末
測試集
https://pan.baidu.com/s/1h1t0LLxZlESPPdfn1zxTXQ
訓練集
https://pan.baidu.com/s/1IVO2opIQ0e66_AEchw_X4Q
2)關鍵代碼
#創建加載數據讀取數據以及劃分數據集的函數,返回數據特征集以及數據標簽集
def loaddataset(filename):fp = open(filename)#(299,22)# 存放數據dataset = []# 存放標簽labelset = []for i in fp.readlines():#按照行來進行讀取,每次讀取一行,一行的數據作為一個元素存放在了類別中a = i.strip().split()#去掉每一行數據的空格以及按照默認的分隔符進行劃分# 每個數據行的最后一個是標簽dataset.append([float(j) for j in a[:len(a) - 1]])#讀取每一行中除最后一個元素的前面的元素,并且將其轉換為浮點數labelset.append(int(float(a[-1])))#讀取每一行的最后一個數據作為標簽數據return dataset, labelset#dataset是(299,21)的列表,labelset是(299,1)的列表
3、初始化待估參數
1)關鍵代碼
# x為輸入層神經元個數,y為隱層神經元個數,z輸出層神經元個數
#創建的是參數初始化函數,參數有各層間的權重weight和閾值即偏置value就是b
#本例的x,y=len(dataset[0])=22,z=1
def parameter_initialization(x, y, z):# 隱層閾值value1 = np.random.randint(-5, 5, (1, y)).astype(np.float64)#隨機生成(-5,5)之間的整數組成(1,y)的數組,然后再將其轉為浮點數顯示# 輸出層閾值value2 = np.random.randint(-5, 5, (1, z)).astype(np.float64)# 輸入層與隱層的連接權重weight1 = np.random.randint(-5, 5, (x, y)).astype(np.float64)# 隱層與輸出層的連接權重weight2 = np.random.randint(-5, 5, (y, z)).astype(np.float64)return weight1, weight2, value1, value2'''
weight1:輸入層與隱層的連接權重
weight2:隱層與輸出層的連接權重
value1:隱層閾值
value2:輸出層閾值
權重和閾值的個數和神經網絡的隱層層數有關,若隱層為n,則權重和閾值的個數為n+1
'''2)np.random.randint(a,b,(m,n))函數
np.random.randint(a,b,(m,n))
#在指定的范圍內隨機生成整數
#a,區間上限,b,區間下限,size=(m,n),a<b
#表示生成(m,n)的數組,數組元素為(a,b)間的整數import numpy as np
a = np.random.randint(-5,5,size=(2,4))
print(a)
print(type(a))[[-1 3 -5 3][-3 1 -4 4]]
<class 'numpy.ndarray'>3)astype(np.float64)
將元素轉化為指定的類型進行顯示
import numpy as np
a = np.random.randint(-5,5,size=(2,4)).astype(np.float64)
print(a)
print(type(a))[[-1. -2. -3. 3.][ 3. -2. -2. -3.]]
<class 'numpy.ndarray'>4、創建激活函數
#創建激活函數sigmoid
def sigmoid(z):return 1 / (1 + np.exp(-z))
5、參數迭代更新
這里是對所有的樣本逐一進行訓練一輪的函數,即對整個訓練樣本進行了一次迭代,若要循環迭代,則需要在外層再套一層循環,來表示迭代的次數,本例將其直接放在了主函數中進行迭代的不斷循環
1)關鍵代碼
#創建訓練樣本的函數,返回訓練完成后的參數weight和value,這里的函數是經過一次迭代后的參數,即所有的樣本經過一次訓練后的參數
#具體參數的值可以通過設置迭代次數和允許誤差來進行確定
def trainning(dataset, labelset, weight1, weight2, value1, value2):# x為步長x = 0.01#學習率for i in range(len(dataset)):#依次讀取數據特征集中的元素,一個元素即為一個樣本所含有的所有特征數據# 輸入數據#(1,21)inputset = np.mat(dataset[i]).astype(np.float64)#每次輸入一個樣本,將樣本的特征轉化為矩陣,以浮點數顯示# 數據標簽#(1,1)outputset = np.mat(labelset[i]).astype(np.float64)#輸入樣本所對應的標簽# 隱層輸入,隱層的輸入是由輸入層的權重決定的,wx#input1:(1,21).(21,21)=(1,21)input1 = np.dot(inputset, weight1).astype(np.float64)# 隱層輸出,由隱層的輸入和閾值以及激活函數決定的,這里的閾值也可以放在輸入進行計算#sigmoid((1,21)-(1,21))=(1,21)output2 = sigmoid(input1 - value1).astype(np.float64)# 輸出層輸入,由隱層的輸出#(1,21).(21,1)=(1,1)input2 = np.dot(output2, weight2).astype(np.float64)# 輸出層輸出,由輸出層的輸入和閾值以及激活函數決定的,這里的閾值也可以放在輸出層輸入進行計算# (1,1).(1,1)=(1,1)output3 = sigmoid(input2 - value2).astype(np.float64)# 更新公式由矩陣運算表示#a:(1,1)a = np.multiply(output3, 1 - output3)#輸出層激活函數求導后的式子,multiply對應元素相乘,dot矩陣運算#g:(1,1)g = np.multiply(a, outputset - output3)#outputset - output3:實際標簽和預測標簽差#weight2:(21,1),np.transpose(weight2):(1,21),b:(1,21)b = np.dot(g, np.transpose(weight2))#(1,21)c = np.multiply(output2, 1 - output2)#隱層輸出激活函數求導后的式子,multiply對應元素相乘,dot矩陣運算#(1,21)e = np.multiply(b, c)value1_change = -x * e#(1,21)value2_change = -x * g#(1,1)weight1_change = x * np.dot(np.transpose(inputset), e)#(21,21)weight2_change = x * np.dot(np.transpose(output2), g)#(21,1)# 更新參數,權重與閾值的迭代公式value1 += value1_changevalue2 += value2_changeweight1 += weight1_changeweight2 += weight2_changereturn weight1, weight2, value1, value2
2)dot、multiply
dot:兩個矩陣按照行列相乘組成新的矩陣
multiply:兩個矩陣和得到結果的矩陣的維度是一樣的,對應位置的元素進行相乘得到新矩陣對應位置的元素值
3)難點
這一部分最大的難點就是在于讀懂相關數學表達式的含義。建議將前面的理論部分之《待估參數的優化迭代公式》自己推導一遍,然后弄清楚這一部分中參數的維數,基本上就可以讀懂了,代碼中注釋已經將所有參數的維數變化進行了標注。
6、測試模型
將最后得到的待估參數的值作為最終的神經網絡的參數,對測試樣本進行測試
#創建測試樣本數據的函數
def testing(dataset1, labelset1, weight1, weight2, value1, value2):# 記錄預測正確的個數rightcount = 0for i in range(len(dataset1)):# 計算每一個樣例的標簽通過上面創建的神經網絡模型后的預測值inputset = np.mat(dataset1[i]).astype(np.float64)outputset = np.mat(labelset1[i]).astype(np.float64)output2 = sigmoid(np.dot(inputset, weight1) - value1)output3 = sigmoid(np.dot(output2, weight2) - value2)# 確定其預測標簽if output3 > 0.5:flag = 1else:flag = 0if labelset1[i] == flag:rightcount += 1# 輸出預測結果print("預測為%d 實際為%d" % (flag, labelset1[i]))# 返回正確率return rightcount / len(dataset1)
7、主函數運行
def main():#讀取訓練樣本數據并且進行樣本劃分dataset, labelset = loaddataset('./horseColicTraining.txt')#讀取測試樣本數據并且進行樣本劃分dataset1, labelset1 = loaddataset('./horseColicTest.txt')#得到初始化的待估參數的值weight1, weight2, value1, value2 = parameter_initialization(len(dataset[0]), len(dataset[0]), 1)#迭代次數為1500次,迭代次數一般越大準確率越高,但是其運行時間也會增加for i in range(1500):#獲得對所有訓練樣本訓練迭代一次后的待估參數weight1, weight2, value1, value2 = trainning(dataset, labelset, weight1, weight2, value1, value2)#對測試樣本進行測試,并且得到正確率rate = testing(dataset1, labelset1, weight1, weight2, value1, value2)print("正確率為%f" % (rate))
if __name__ == '__main__':main()三、總結
1、幾個循環
在本例中(單隱層),可以分為以下幾個循環:
***通過行來遍歷每一個樣本的特征集和標簽
for i in range(len(dataset)):#依次讀取數據特征集中的元素,一個元素即為一個樣本所含有的所有特征數據***迭代次數的循環,通過迭代次數來控制迭代的終止條件,當然也可以用while循環來進行迭代,用誤差來控制迭代的終止
for i in range(1500):#獲得對所有訓練樣本訓練迭代一次后的待估參數weight1, weight2, value1, value2 = trainning(dataset, labelset, weight1, weight2, value1, value2)若是多隱層的話,還多一層循環:
***通過循環來遍歷所有的隱層,一般遍歷只是為了獲得每一隱層的神經元的個數,因此只需要通過字典定義好每一隱層的神經元個數,然后通過遍歷的方式獲得神經元個數即可(注意神經元個數和權重、閾值個數的關系)。或者如果隱層的層數比較少,可以通過多添加幾組待測參數即可,設有k層:
def parameter_initialization(x1,x2,...,xi,..., xk):# 隱層閾值value1 = np.random.randint(-5, 5, (x1, x2)).astype(np.float64)#隨機生成(-5,5)之間的整數組成(1,y)的數組,然后再將其轉為浮點數顯示# 輸出層閾值value2 = np.random.randint(-5, 5, (x1, x3)).astype(np.float64).........valuei = np.random.randint(-5, 5, (x1, xi)).astype(np.float64).........valuek = np.random.randint(-5, 5, (x1, xk+1)).astype(np.float64)# 輸入層與隱層的連接權重weight1 = np.random.randint(-5, 5, (x1, x2)).astype(np.float64)# 隱層與輸出層的連接權重weight2 = np.random.randint(-5, 5, (x2, x3)).astype(np.float64)........weighti = np.random.randint(-5, 5, (xi,xi+1)).astype(np.float64)........return weight1, weight2,...,weighti,...,weightk, value1, value2,...,valuei,...,valuek2、問題集錦
1)若是有多個輸出怎么辦?
若是有多個輸出的話,只需要在主函數中修改輸出層的神經元個數即可,神經元個數等于輸出的個數,設有i個輸出,輸出的增多也意味著輸出的歸類判斷會更加的復雜
weight1, weight2, value1, value2 = parameter_initialization(len(dataset[0]), len(dataset[0]), i)2)BP算法為什么叫做后向傳播?
因為從目標函數對待測參數求偏導可以看出,目標函數對越往前的神經網絡的參數進行求導,其要經過的層數就會越多,即要想求得目標函數對前面的參數的偏導,就必須先知道該層神經網絡后面的層數中目標函數對待測參數的偏導,因為鏈式法則。而且在求對閾值的偏導的時候,我們需要注意的是,對該層閾值的偏導,受下一層所有神經元的影響,如下圖就知道,每一層的神經元都互相有關系,所有每一層的神經元的閾值的偏導也和相鄰層神經元有關

四、完整代碼
#導入模塊
import numpy as np#創建加載數據讀取數據以及劃分數據集的函數,返回數據特征集以及數據標簽集
def loaddataset(filename):fp = open(filename)#(299,22)# 存放數據dataset = []# 存放標簽labelset = []for i in fp.readlines():#按照行來進行讀取,每次讀取一行,一行的數據作為一個元素存放在了類別中a = i.strip().split()#去掉每一行數據的空格以及按照默認的分隔符進行劃分# 每個數據行的最后一個是標簽dataset.append([float(j) for j in a[:len(a) - 1]])#讀取每一行中除最后一個元素的前面的元素,并且將其轉換為浮點數labelset.append(int(float(a[-1])))#讀取每一行的最后一個數據作為標簽數據return dataset, labelset#dataset是(299,21)的列表,labelset是(299,1)的列表# x為輸入層神經元個數,y為隱層神經元個數,z輸出層神經元個數
#創建的是參數初始化函數,參數有各層間的權重weight和閾值即偏置value就是b
#本例的x,y=len(dataset[0])=22,z=1
def parameter_initialization(x, y, z):# 隱層閾值value1 = np.random.randint(-5, 5, (1, y)).astype(np.float64)#隨機生成(-5,5)之間的整數組成(1,y)的數組,然后再將其轉為浮點數顯示# 輸出層閾值value2 = np.random.randint(-5, 5, (1, z)).astype(np.float64)# 輸入層與隱層的連接權重weight1 = np.random.randint(-5, 5, (x, y)).astype(np.float64)# 隱層與輸出層的連接權重weight2 = np.random.randint(-5, 5, (y, z)).astype(np.float64)return weight1, weight2, value1, value2#創建激活函數sigmoid
def sigmoid(z):return 1 / (1 + np.exp(-z))'''
weight1:輸入層與隱層的連接權重
weight2:隱層與輸出層的連接權重
value1:隱層閾值
value2:輸出層閾值
權重和閾值的個數和神經網絡的隱層層數有關,若隱層為n,則權重和閾值的個數為n+1
'''#創建訓練樣本的函數,返回訓練完成后的參數weight和value,這里的函數是經過一次迭代后的參數,即所有的樣本經過一次訓練后的參數
#具體參數的值可以通過設置迭代次數和允許誤差來進行確定
def trainning(dataset, labelset, weight1, weight2, value1, value2):# x為步長x = 0.01#學習率for i in range(len(dataset)):#依次讀取數據特征集中的元素,一個元素即為一個樣本所含有的所有特征數據# 輸入數據#(1,21)inputset = np.mat(dataset[i]).astype(np.float64)#每次輸入一個樣本,將樣本的特征轉化為矩陣,以浮點數顯示# 數據標簽#(1,1)outputset = np.mat(labelset[i]).astype(np.float64)#輸入樣本所對應的標簽# 隱層輸入,隱層的輸入是由輸入層的權重決定的,wx#input1:(1,21).(21,21)=(1,21)input1 = np.dot(inputset, weight1).astype(np.float64)# 隱層輸出,由隱層的輸入和閾值以及激活函數決定的,這里的閾值也可以放在輸入進行計算#sigmoid((1,21)-(1,21))=(1,21)output2 = sigmoid(input1 - value1).astype(np.float64)# 輸出層輸入,由隱層的輸出#(1,21).(21,1)=(1,1)input2 = np.dot(output2, weight2).astype(np.float64)# 輸出層輸出,由輸出層的輸入和閾值以及激活函數決定的,這里的閾值也可以放在輸出層輸入進行計算# (1,1).(1,1)=(1,1)output3 = sigmoid(input2 - value2).astype(np.float64)# 更新公式由矩陣運算表示#a:(1,1)a = np.multiply(output3, 1 - output3)#輸出層激活函數求導后的式子,multiply對應元素相乘,dot矩陣運算#g:(1,1)g = np.multiply(a, outputset - output3)#outputset - output3:實際標簽和預測標簽差#weight2:(21,1),np.transpose(weight2):(1,21),b:(1,21)b = np.dot(g, np.transpose(weight2))#(1,21)c = np.multiply(output2, 1 - output2)#隱層輸出激活函數求導后的式子,multiply對應元素相乘,dot矩陣運算#(1,21)e = np.multiply(b, c)value1_change = -x * e#(1,21)value2_change = -x * g#(1,1)weight1_change = x * np.dot(np.transpose(inputset), e)#(21,21)weight2_change = x * np.dot(np.transpose(output2), g)#(21,1)# 更新參數,權重與閾值的迭代公式value1 += value1_changevalue2 += value2_changeweight1 += weight1_changeweight2 += weight2_changereturn weight1, weight2, value1, value2#創建測試樣本數據的函數
def testing(dataset1, labelset1, weight1, weight2, value1, value2):# 記錄預測正確的個數rightcount = 0for i in range(len(dataset1)):# 計算每一個樣例的標簽通過上面創建的神經網絡模型后的預測值inputset = np.mat(dataset1[i]).astype(np.float64)outputset = np.mat(labelset1[i]).astype(np.float64)output2 = sigmoid(np.dot(inputset, weight1) - value1)output3 = sigmoid(np.dot(output2, weight2) - value2)# 確定其預測標簽if output3 > 0.5:flag = 1else:flag = 0if labelset1[i] == flag:rightcount += 1# 輸出預測結果print("預測為%d 實際為%d" % (flag, labelset1[i]))# 返回正確率return rightcount / len(dataset1)def main():#讀取訓練樣本數據并且進行樣本劃分dataset, labelset = loaddataset('./horseColicTraining.txt')#讀取測試樣本數據并且進行樣本劃分dataset1, labelset1 = loaddataset('./horseColicTest.txt')#得到初始化的待估參數的值weight1, weight2, value1, value2 = parameter_initialization(len(dataset[0]), len(dataset[0]), 1)#迭代次數為1500次,迭代次數一般越大準確率越高,但是其運行時間也會增加for i in range(1500):#獲得對所有訓練樣本訓練迭代一次后的待估參數weight1, weight2, value1, value2 = trainning(dataset, labelset, weight1, weight2, value1, value2)#對測試樣本進行測試,并且得到正確率rate = testing(dataset1, labelset1, weight1, weight2, value1, value2)print("正確率為%f" % (rate))if __name__ == '__main__':main()參考:《機器學習 BP神經網絡(Python實現)》寫的很詳細
詳解—— Camera_calibration_multi_image.hdev)


——LeNet卷積神經網絡結構)
主要參數詳述)



—— xyz_attrib_to_object_model_3d)

——AlexNet卷積神經網絡結構)


的使用)


—— calibrate_sheet_of_light_calplate.hdev)


