目錄
一、AlexNet卷積神經網絡結構模型
1、數據庫ImageNet
2、AlexNet第一層卷積層
二、AlexNet卷積神經網絡的改進
1、非線性變化函數的改變——ReLU
2、最大池化(Max Pooling)概念的提出——卷積神經網絡通用
1)池化層
2)最大池化
問題1:在AlexNet中,后向傳播時,池化后特征圖像的梯度怎么傳給池化前的圖像?——贏者通吃法
3)池化過程的功能和效果
3、隨機丟棄(Drop Out)
問題2:為什么參數要乘以(1-p)?
4、增加訓練樣本
5、利用2片GPU進行加速
? 三、AlexNet的效果
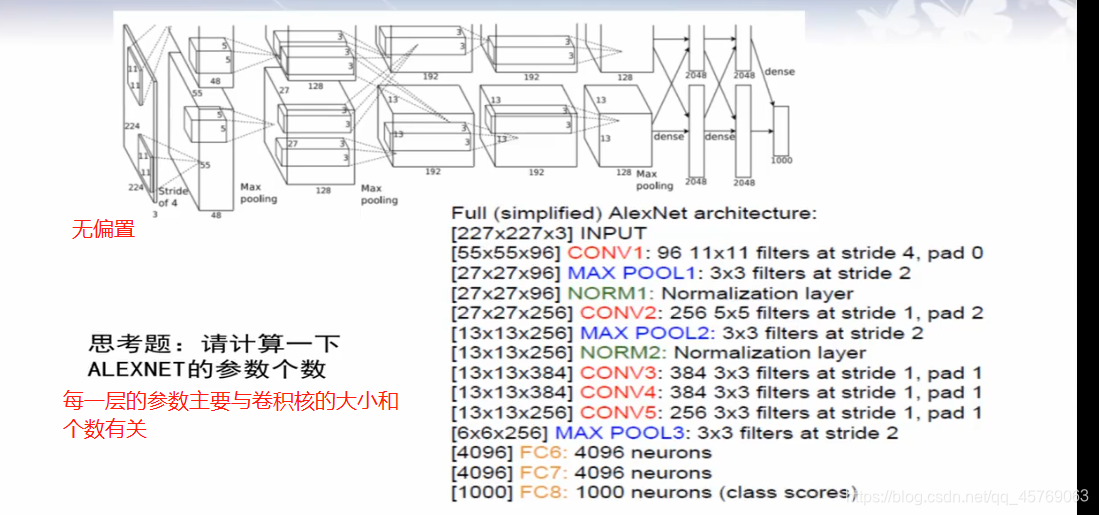
四、AlexNet中的參數
一、AlexNet卷積神經網絡結構模型
1998年LeNet卷積神經網絡
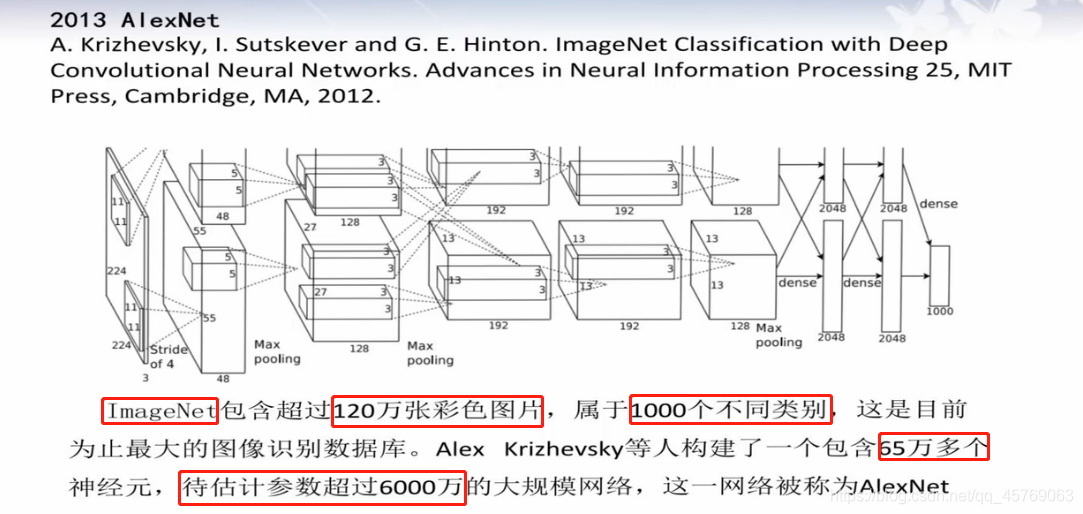
2013年AlexNet卷積神經網絡
AlexNet卷積神經網絡相較于LeNet卷積神經網絡其實本質上沒有改變,只是在一些細節上進行了改善
1、數據庫ImageNet
數據庫:ImageNet
樣本數據:120萬
類別:1000類

2、AlexNet第一層卷積層
第一層卷積層的相關參數
圖像大小:227*227*3
卷積核大小:11*11*3
卷積核個數:96個
步長:【4,4】
特征圖像大小:55*55*96,圖上看起來是48,實際上是96,將96分成兩個48給兩個GPU進行處理
二、AlexNet卷積神經網絡的改進
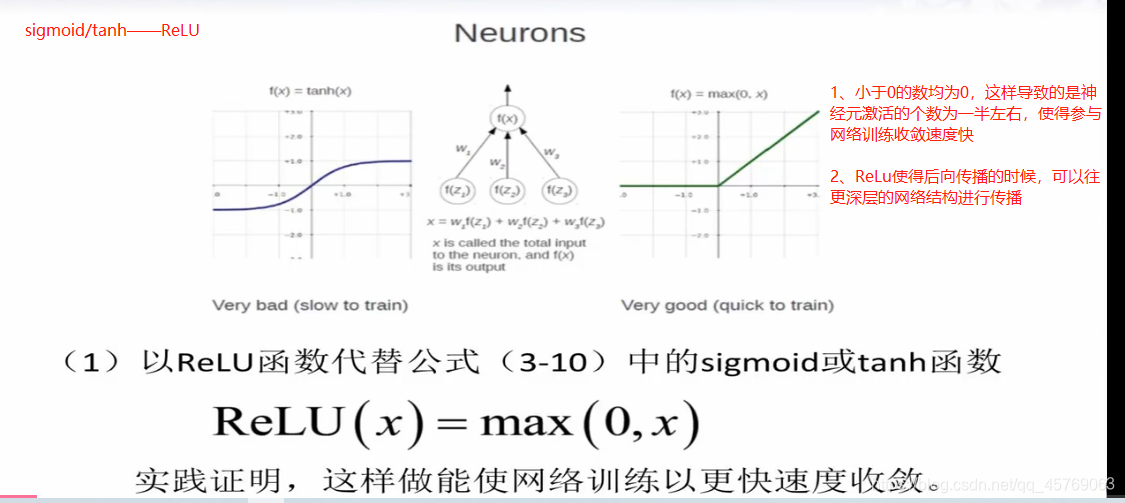
1、非線性變化函數的改變——ReLU
2、最大池化(Max Pooling)概念的提出——卷積神經網絡通用

1)池化層
在LeNet中這一層叫做降采樣層,Alex將其改名為池化層Pooling
2)最大池化
LeNet中這一層所做的事情是將紅色區域的所有值的平均值作為輸出,變成右邊的一個藍色像素格子
但是在AlexNet中,是將紅色區域中最大的像素值作為輸出,變成右邊的一個藍色像素格子的值
問題1:在AlexNet中,后向傳播時,池化后特征圖像的梯度怎么傳給池化前的圖像?——贏者通吃法

答:在LeNet中前向傳播是平均池化,后向傳播時將池化后的特征每一個格子的梯度平均分給池化前的圖像
但是在AlexNet中由于是最大池化得到的池化后的特征圖像,因此在后向傳播的梯度處理上,也是基于此。將上圖中藍色格子的梯度直接傳播賦值給池化前紅色區域的像素值最大的格子,其余的格子的梯度設置為0,這就是贏者通吃法則
3)池化過程的功能和效果
功能:
降采樣
非線性操作——因此池化用的是最大池化,和RULE函數進行非線性轉換的效果是一樣的
效果:
只有最大像素值有關,其余像素的梯度均設置為0,這樣導致的結果就是參與前向計算的神經元減少,降低了過擬合的可能
3、隨機丟棄(Drop Out)

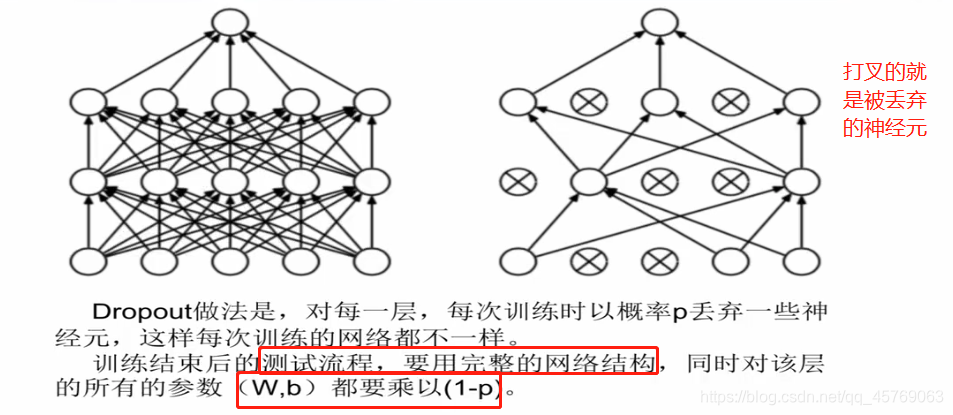 訓練用丟棄神經元后的神經網絡,測試的時候需要用完整的神經網絡
訓練用丟棄神經元后的神經網絡,測試的時候需要用完整的神經網絡
注:隨機丟棄可以隨機地激活一部分神經元,會使得參數穩定化,避免了過擬合
問題2:為什么參數要乘以(1-p)?
答:望賜教
4、增加訓練樣本
有的時候參數過多,訓練樣本不夠,這樣就會導致待測參數的不準確,使得性能不夠

5、利用2片GPU進行加速

 三、AlexNet的效果
三、AlexNet的效果
 ?
?
四、AlexNet中的參數
參數個數可參考:《機器學習——深度學習之卷積神經網絡(CNN)——LeNet卷積神經網絡結構》


的使用)


—— calibrate_sheet_of_light_calplate.hdev)








 —— measure_stamping_part.hdev)
)



