Dubbo篇
1、Dubbo的服務調用流程
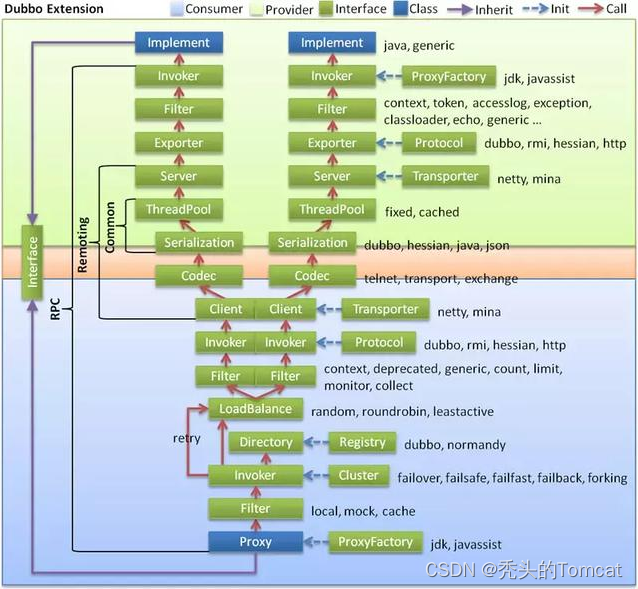
2、Dubbo支持那種協議,每種協議的應用場景,優缺點?
- dubbo: 單一長連接和 NIO 異步通訊,適合大并發小數據量的服務調用,以及消費者遠大于提供者。傳輸協議 TCP,異步,Hessian 序列化;
- rmi: 采用 JDK 標準的 rmi 協議實現,傳輸參數和返回參數對象需要實現 Serializable 接口,使用 java 標準序列化機制,使用阻塞式短連接,傳輸數據包大小混合,消費者和提供者個數差不多,可傳文件,傳輸協議 TCP。 多個短連接,TCP 協議傳輸,同步傳輸,適用常規的遠程服務調用和 rmi 互操作。在依賴低版本的 Common-Collections包,java 序列化存在安全漏洞;
- webservice: 基于 WebService 的遠程調用協議,集成 CXF 實現,提供和原生 WebService 的互操作。多個短連接,基于 HTTP 傳輸,同步傳輸,適用系統集成和跨語言調用;
- http: 基于 Http 表單提交的遠程調用協議,使用 Spring 的HttpInvoke 實現。多個短連接,傳輸協議 HTTP,傳入參數大小混合,提供者個數多于消費者,需要給應用程序和瀏覽器 JS 調用;
- hessian: 集成 Hessian 服務,基于 HTTP 通訊,采用 Servlet 暴露服務,Dubbo 內嵌 Jetty 作為服務器時默認實現,提供與 Hession 服務互操作。多個短連接,同步 HTTP 傳輸,Hessian 序列化,傳入參數較大,提供者大于消費者,提供者壓力較大,可傳文件;
- memcache: 基于 memcached 實現的 RPC 協議
- redis: 基于 redis 實現的 RPC 協議
3、Dubbo推薦用什么協議?
默認使用 dubbo 協議
4、Dubbo中有哪些注冊中心?
- Multicast 注冊中心: Multicast 注冊中心不需要任何中心節點,只要廣播地址,就能進行服務注冊和發現。基于網絡中組播傳輸實現;
- Zookeeper 注冊中心: 基于分布式協調系統 Zookeeper 實現,采用Zookeeper 的 watch 機制實現數據變更;
- redis 注冊中心: 基于 redis 實現,采用 key/Map 存儲,住 key 存儲服務名和類型,Map 中 key 存儲服務 URL,value 服務過期時間。基于 redis 的發布/訂閱模式通知數據變更;
- Simple 注冊中心
- Dubbo 默認采用 Zookeeper
5、為什么需要服務治理?
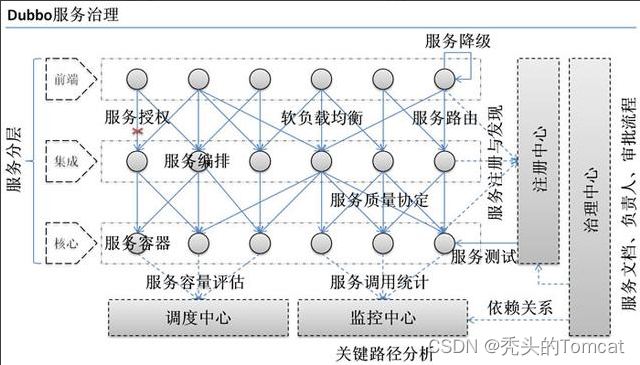
- 過多的服務 URL 配置困難
- 負載均衡分配節點壓力過大的情況下也需要部署集群?
- 服務依賴混亂,啟動順序不清晰
- 過多服務導致性能指標分析難度較大,需要監控
6、Dubbo的注冊中心集群掛掉,發布者和訂閱者之間還能通信嗎?
可以的,啟動 dubbo 時,消費者會從 zookeeper 拉取注冊的生產者的地址接口等數據,緩存在本地。每次調用時,按照本地存儲的地址進行調用。
7、Dubbo與Spring的關系
Dubbo 采用全 Spring 配置方式,透明化接入應用,對應用沒有任何API 侵入,只需用 Spring 加載 Dubbo 的配置即可,Dubbo 基于Spring 的 Schema 擴展進行加載。
8、Dubbo使用的是什么通信框架?
默認使用 NIO Netty 框架
9、Dubbo集群提供了那些負載均衡策略?
- Random LoadBalance: 隨機選取提供者策略,有利于動態調整提供者權重。截面碰撞率高,調用次數越多,分布越均勻;
- RoundRobin LoadBalance: 輪循選取提供者策略,平均分布,但是存在請求累積的問題;
- LeastActive LoadBalance: 最少活躍調用策略,解決慢提供者接收更少的請求;
- ConstantHash LoadBalance: 一致性 Hash 策略,使相同參數請求總是發到同一提供者,一臺機器宕機,可以基于虛擬節點,分攤至其他提供者,避免引起提供者的劇烈變動;
- 缺省時為 Random 隨機調用
10、Dubbo的集群容錯方案有哪些?
- Failover Cluster?失敗自動切換,當出現失敗,重試其它服務器。通常用于讀操作,但重試會帶來更長延遲。
- Failfast Cluster 快速失敗,只發起一次調用,失敗立即報錯。通常用于非冪等性的寫操作,比如新增記錄。
- Failsafe Cluster 失敗安全,出現異常時,直接忽略。通常用于寫入審計日志等操作。
- Failback Cluster 失敗自動恢復,后臺記錄失敗請求,定時重發。通常用于消息通知操作。
- Forking Cluster?并行調用多個服務器,只要一個成功即返回。通常用于實時性要求較高的讀操作,但需要浪費更多服務資源。可通過 forks="2" 來設置最大并行數。
- Broadcast Cluster 廣播調用所有提供者,逐個調用,任意一臺報錯則報錯 。通常用于通知所有提供者更新緩存或日志等本地資源信息。









 The requested URL returned error: 404)









