文章目錄
- 上一篇
- 機器學習概述
- 歸納(示例)學習
- ID3決策樹算法
- K近鄰算法
- 下一篇
上一篇
人工智能原理復習–搜索策略(二)
機器學習概述
學習系統的基本結構:
環境向系統的學習部分提供某些信息
學習利用這些信息修改數據庫,以怎金系統執行部分完成任務的效能
執行部分根據知識庫完成任務,同時把獲得的信息反饋給學習部分
最重要的因素是`環境向系統提供的信息
機器學習分類:
- 監督學習:決策樹、支持向量機(SVM)、k-臨近算法(KNN)
- 無監督學習:k-均值、DBSCAN密度聚類算法、最大期望算法
- 強化學習:環境,獎勵,狀態 ,動作–> 狀態獎勵
歸納(示例)學習
歸納學習是一種通過觀察和分析現象,發現其中規律和模式,并據此進行預測和決策的方法。歸納學習的基本思想是通過從數據樣本中歸納出一般性規律或模式,從而實現對未知數據的預測和分類。
歸納學習是通過一系列的示例(正例和反例)出發,生成一個反映這些示例本質的定義:
- 覆蓋所有的正例,而不包含任何反例
- 可用來指導對新例子的分類識別
歸納學習過程可以分為以下幾個步驟:
- 數據采集:收集需要學習的數據樣本。
- 特征提取:從數據樣本中提取出有用的特征,用于歸納學習。
- 模型訓練:使用歸納學習算法從數據樣本中歸納出一般性規律或模式。
- 模型評估:使用測試數據對歸納模型進行評估,計算出模型的準確率和誤差。
- 模型應用:使用歸納模型對新的數據進行分類或預測。
概念描述搜索及獲取
- 例子空間:所有可能的正例、反例構成的空間
- 假設空間:所有可能的假設(概念描述)構成的空間
- 頂層假設:最泛化的概念描述,不指定任何的特征值
- 底層假設:最特化(具體)的概念描述,所有特征都給定特征值
- 假設空間的搜索方法:1、特化搜索(寬度優先,自頂向下) 2、泛化搜索(寬度優先,自底向上) 3、雙向搜索(版本空間法)
ID3決策樹算法
信息的定量描述
衡量信息多少的物理量稱為信息量:
- 若概率很大,受信者事先已有所估計,則該消息信息量就很小
- 若概率很小,受信者感覺很突然,該信息所含信息量就很大
使用信息量函數 f ( p ) f(p) f(p)描述, f ( p ) f(p) f(p)條件:
- f ( p ) f(p) f(p) 應是p的嚴格單調遞減函數
- 當p = 1時, f ( p ) = 0 f(p) = 0 f(p)=0, 當p = 0時, f ( p ) = ∞ f(p) = \infty f(p)=∞
- 當兩個獨立事件的聯合信息量應等于他們分別的信息量之和
信息量定義 :若一個消息 x x x 出現的的概率為 p p p, 則這一消息所含信息量為:
I = ? log ? p I = - \log{p} I=?logp
單位:
- 以2為底,單位 b i t bit bit (
常用) - 以e為底,單位 n a t nat nat
- 以10為底,單位 h a r t hart hart
信息熵
所有可能消息的平均不確定性,信息量的平均值
H ( X ) = ? ∑ p ( x i ) log ? ( p ( x i ) ) H(X) = -\sum{p(x_i)\log{(p(x_i))}} H(X)=?∑p(xi?)log(p(xi?))

定義:
- M ( C ) M(C) M(C) 為根節點總的信息熵
- B ( C , A ) B(C, A) B(C,A) 為根據A屬性分類后的加權信息熵的和,每一類占全部的比例作為加權,將分完之后的信息熵加權求和
- g a i n = M ( C ) ? B ( C , A ) gain = M(C) - B(C,A) gain=M(C)?B(C,A)信息增益,信息增益越大越好
分別求出每個屬性的信息增益,然后將最大的作為這個節點的分類屬性
步驟:
- 首先求出根節點的信息熵
- 然后按每個特征求出對應的信息增益
- 比較得出最大的信息增益的特征作為給節點的劃分屬性
- 循環1-3步直到將全部類別分開,或者劃分比例達到要求值
d
ID3算法
優點:
- 計算復雜度不高
- 輸出結果易于理解
- 可以處理不相關特征數據
缺點:
- 不能處理帶有缺失值的數據集
- 在進行算法學習之前需要對數據集中的缺失值進行預處理
- 存在過擬合問題
K近鄰算法
一種監督學習分類算法,沒有學習過程,在分類時通過類別已知的樣本對新樣本的類別進行預測。
基本思路:
- 通過以某個數據為中心,分析離其最近的K個鄰居的類型,獲得該數據可能的類型
- 以少數服從多數的原理,推斷出測試樣本的類別
只要訓練樣本足夠多,K近鄰算法就能達到很好的分類效果
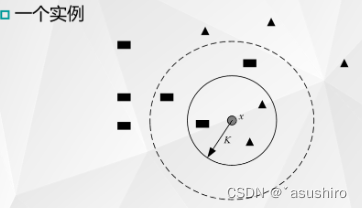
- 當K = 3時,即選擇最近的3個點,由于三角形樣本所占近鄰樣本的比例為2/3,于是可以得出圓形輸入實例應該為三角形
- 當K = 5時,由于長方形樣本棧近鄰樣本比例為3/5,此時測試樣本被歸為長方形類別。
步驟:
- 計算測試數據與每個訓練數據之間的距離
- 按照距離的遞增關系進行排序
- 選取距離最小的k個點
- 確定前k個點所在類別的出現頻率
- 返回前k個點中出現頻率最高的類別做為測試數據的預測分類
優點:
- 簡單,便于理解和實現
- 應用范圍廣
- 分類效果好
- 無需進行參數估計
缺點:
- 樣本小時誤差難以估計
- 存儲所有樣本,需要較大存儲空間
- 大樣本計算量大
- k的取值對結果也有較大影響(k較小對噪聲敏感,k過大可能包含別的類樣本)
下一篇
未完待續
`
與車輛路徑問題(VRP))


















)