一、概述、定義
目的:
遷移學習的目的是將某個領域或任務上學習到的模式、知識應用到不同但相關的領域里,獲取更多數據,而不必投入許多時間人力來進行數據的標注。
舉例:
已經會下中國象棋,就可以類比著來學習國際象棋;已經會編寫Java程序,就可以類比著來學習C#;已經學會英語,就可以類比著來學習法語;已經學會了騎自行車,就可以類比學習騎摩托車等等。
定義:
Transfer Learning Definition:
Ability of a system to recognize and apply knowledge and skills learned in previous domains/tasks to novel domains/tasks.
通俗地講,遷移學習就是運用已有的知識、模型來學習新的知識,構建新模型。其核心是找到已有知識與新知識的相似性與關聯性。
重要概念:
域:某個時刻的某個特定領域——例如書本評論、電影評論;
任務:所要完成的任務與實現的功能——例如情感分析、實體識別;
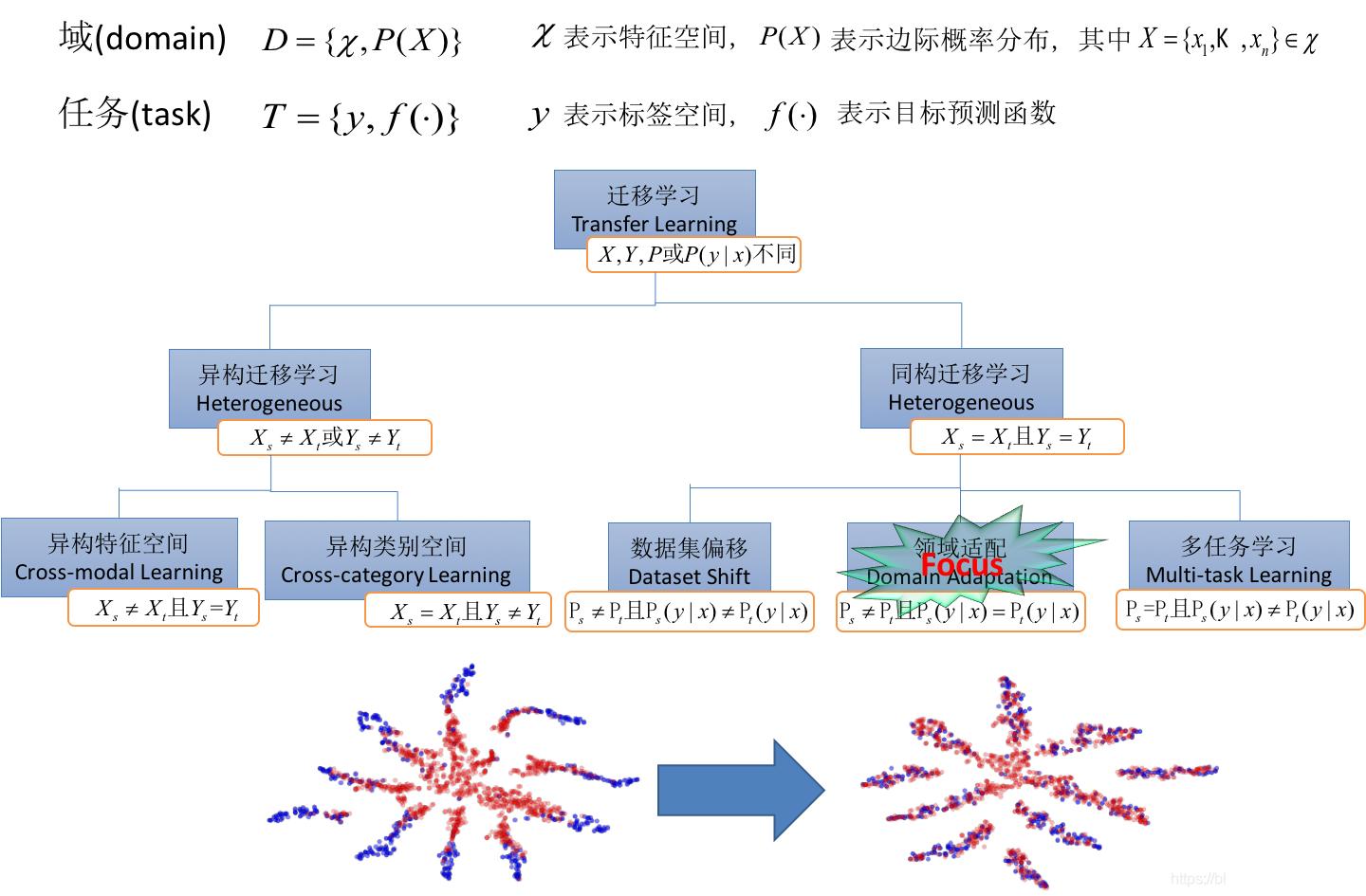
給定源域??和學習任務?
、目標域?
?和學習任務?
,遷移學習的目的是獲取源域
?和學習任務
?中知識來幫助提升目標域?
?中預測函數?
?的學習。其中?
?或者?
。
二、遷移學習的分類
1.?基于實例的遷移
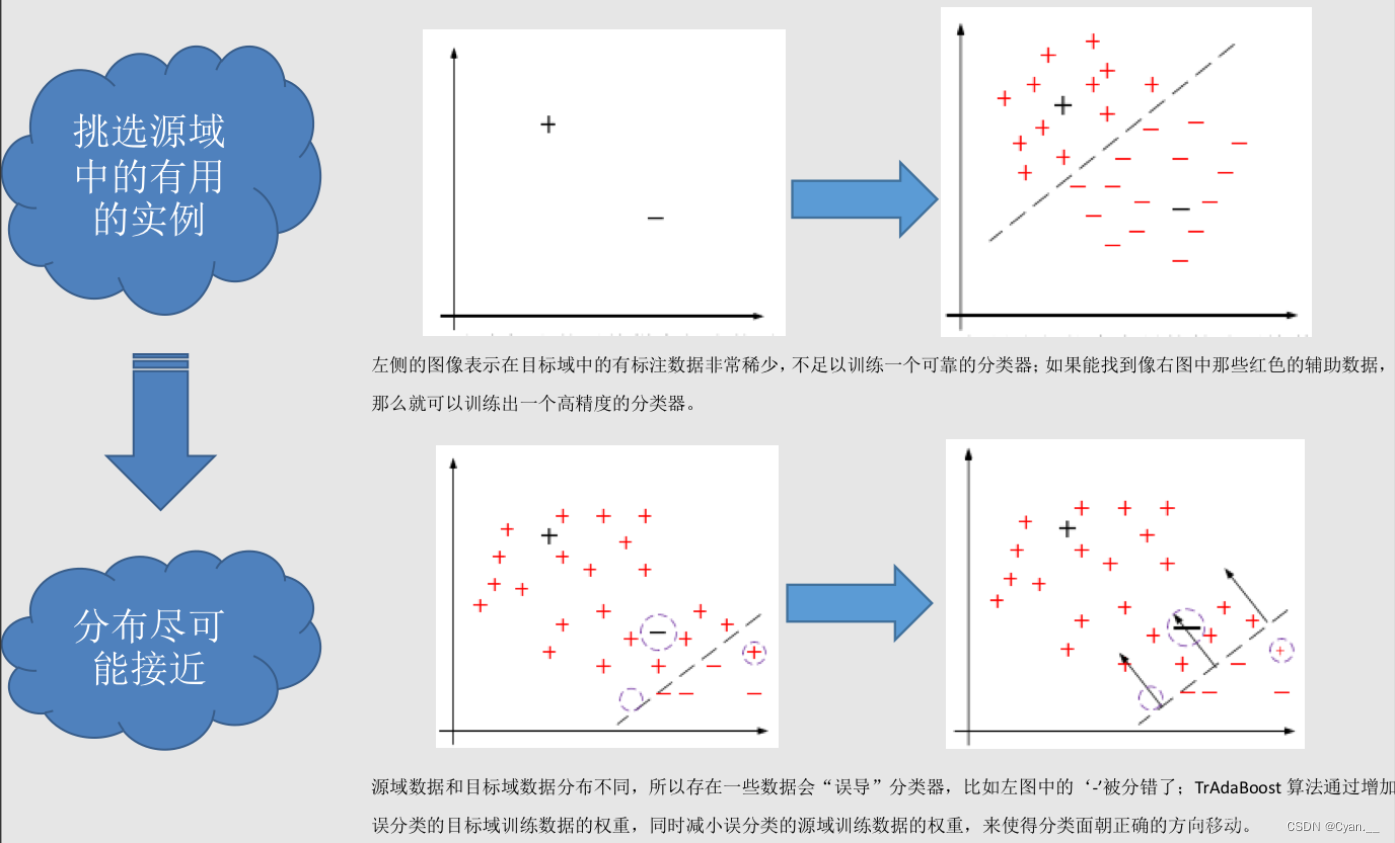
研究如何從源域中找出對目標領域訓練有作用的實例。
例:在對源域的有標記數據實例中進行有效的權重分配,讓源域的實例分布接近目標域的實例分布,從而在目標領域中建立一個分類精度較高并且可靠的學習模型。
遷移學習中,源域與目標域的數據分布不一致,故源域中并非所有有標記的數據實例都對目標域有作用。基于實例的遷移有現有的一些遷移算法,來對源域的有效數據遷移到目標域中。
TrAdaBoost算法就是典型基于實例的遷移。
TrAdaBoost算法的工作機制如下:
-
初始化:算法開始時,對源域和目標域數據的權重進行初始化。通常,目標域數據的初始權重會高于源域數據。
-
迭代更新:在每一輪中,算法使用當前的權重來訓練一個弱分類器。分類器首先在目標域上測試,然后在兩個域上進行誤差評估。
-
權重調整:算法根據分類器的表現來調整數據點的權重。對于源域數據,分類正確的數據點權重會增加(使得算法在后續迭代中更少地關注這些點),而分類錯誤的數據點權重會減少。這與傳統的AdaBoost相反,其核心思想是減少源域中對目標域幫助不大或有害的數據點的權重。對于目標域數據,權重更新與傳統AdaBoost相同,即增加被錯誤分類數據點的權重。
-
終止條件:算法會在達到預定的迭代次數后停止,或者當目標域上的誤差不再顯著減少時停止。
-
組合弱分類器:最后,算法結合所有的弱分類器,形成一個強分類器。每個弱分類器根據其在目標域上的性能加權,性能越好的分類器影響越大。
通過這種方式,能夠有效利用源域數據來幫助構建在目標域上表現良好的分類器,即便源域和目標域的數據分布有所不同。
2.?基于特征的遷移
①特征選擇
找出源域和目標域之間共同的特征表示,找出特征之間對應的不同相關性,利用這些特征進行知識遷移。
②特征映射
將源域和目標域的數據從原始特征空間映射到新的特征空間之中。
源域的特征值經過一系列變換,對應到目標域的特征值,經過一一映射,使得源域數據與目標域的數據分布相同,從而在新的空間中,更好地利用源域已有的標記數據樣本進行分類訓練。最終對目標域的數據進行分類測試。
3.?基于共享參數的遷移
找到源域與目標域空間模型之間的共同參數或先驗分布。
前提:學習任務的每個相關模型都會共享一些相同的參數或者先驗分布。
三、遷移學習使用場景
1. 有大量數據樣本,但大部分樣本無標注
要想繼續增加更多數據標注,需要付出很多成本。利用遷移學習思想,可以尋找一些和目標數據相似而且已經有標注的數據,利用數據之間的相似性對知識進行遷移,提高對目標數據的預測效果或者標注精度。
2. 幫助解決算法的冷啟動問題
在跨域推薦系統將用戶偏好模型從現有域(如圖書推薦領域)遷移到一個新域(如電影推薦領域)中。
3. 想要獲取具有更強泛化能力,但是數據樣本較少. 許多應用場景數據量小
高質量有標簽數據總是供不應求。傳統的機器學習算法常常因為數據量小而產生過擬合問題,因而無法很好地泛化到新的場景中。
4. 數據來自不同的分布時
數據分布不僅會隨著時間和空間而變化,也會隨著不同的情況而變化,我們可能無法使用相同的數據分布來對待新的訓練數據。已經訓練完成的模型需要在使用前進行調整,在不同于訓練數據的新場景下。
四、遷移學習的示例
例:假設現在要構建一個對手寫數字進行識別的模型,但目前已有的已標注數據較少,如何不花費大量時間精力標注數據也能獲得一個效果較好的模型?
方法:借助遷移學習,利用其它模型來輔助實現該任務。
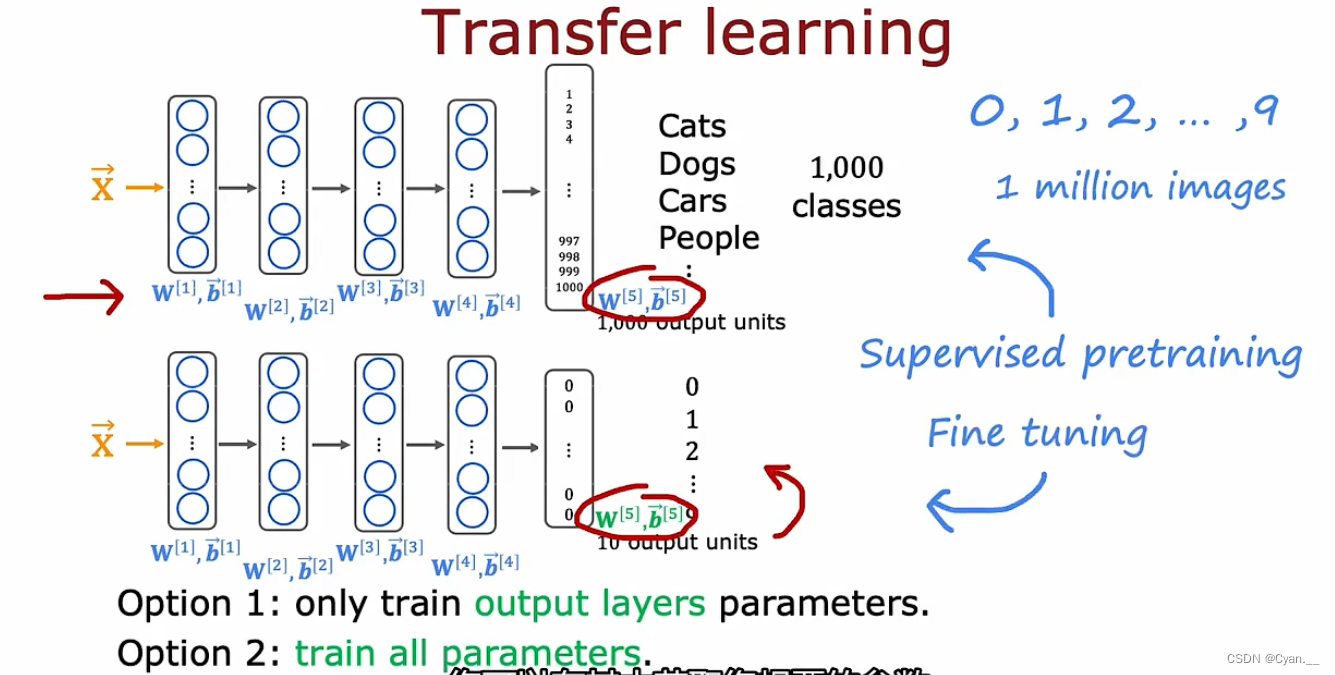
假設有一個已經訓練好的可以識別貓、狗、汽車和人的圖像識別模型。復制此神經網絡,在其中插入新的參數,那么對于最后的輸出層,可以消除輸出層并用一個更小的輸出層(10個)替換它。
可以做的是使用前幾層隱藏層的參數(實際上是除輸出層之外所有隱藏層),然后采用兩種方法訓練新的網絡:
①將五個新的輸出層參數作為頂部的值,固定它們然后使用隨機梯度下降或Adam算法更新參數,來降低識別數字0到9的成本函數。
②更新并訓練網絡中的所有參數,但前幾層參數可以借助之前的神經網絡。
首先在大數據集上進行訓練,然后再在較小的數據集上進一步調整參數,這就是監督預訓練。
然后進行微調,在其中獲取已初始化或從監督預訓練中獲得的參數,進一步運行梯度下降微調權重以適應對應新的學習任務的特定應用參數。
原理:如果同樣是圖像識別的神經網絡,那么在前幾層——檢測圖像邊緣、檢測角點、檢測通用形狀、基本曲線等等都是相同的步驟,因而可以通用進行。
故而,可以下載、借助他人預訓練的神經網絡來根據自己的數據進一步訓練、微調神經網絡以達成相應目的。









)


 和 execute() 方法有什么區別?)






