本文首發于AIWalker,歡迎關注。

https://arxiv.org/abs/2312.02139
https://github.com/NVlabs/DiffiT
擴散模型以其強大的表達能力和高樣本質量在許多領域得到了新的應用。對于樣本生成,這些模型依賴于通過迭代去噪生成圖像的去噪神經網絡。然而,去噪網絡架構的作用并沒有得到很好的研究,大多數工作都依賴于卷積殘差U-Nets。
本文研究了視覺transformer在基于擴散的生成學習中的有效性。本文提出一種新模型,稱為擴散視覺transformer (DiffiT),由一個具有U形編碼器和解碼器的混合分層架構組成。本文提出一種新的依賴時間的自注意力模塊,允許注意力層以有效的方式自適應其在去噪過程的不同階段的行為。
此外,本文還提出了LatentDiffiT,由transformer模型和所提出的自注意力層組成,用于高分辨率圖像生成。結果表明,DiffiT在生成高保真圖像方面驚人地有效,并在各種類條件和無條件合成任務中實現了最先進的(SOTA)基準。在潛空間中,DiffiT在ImageNet256數據集上取得了新的SOTA FID分數1.73。

本文方案
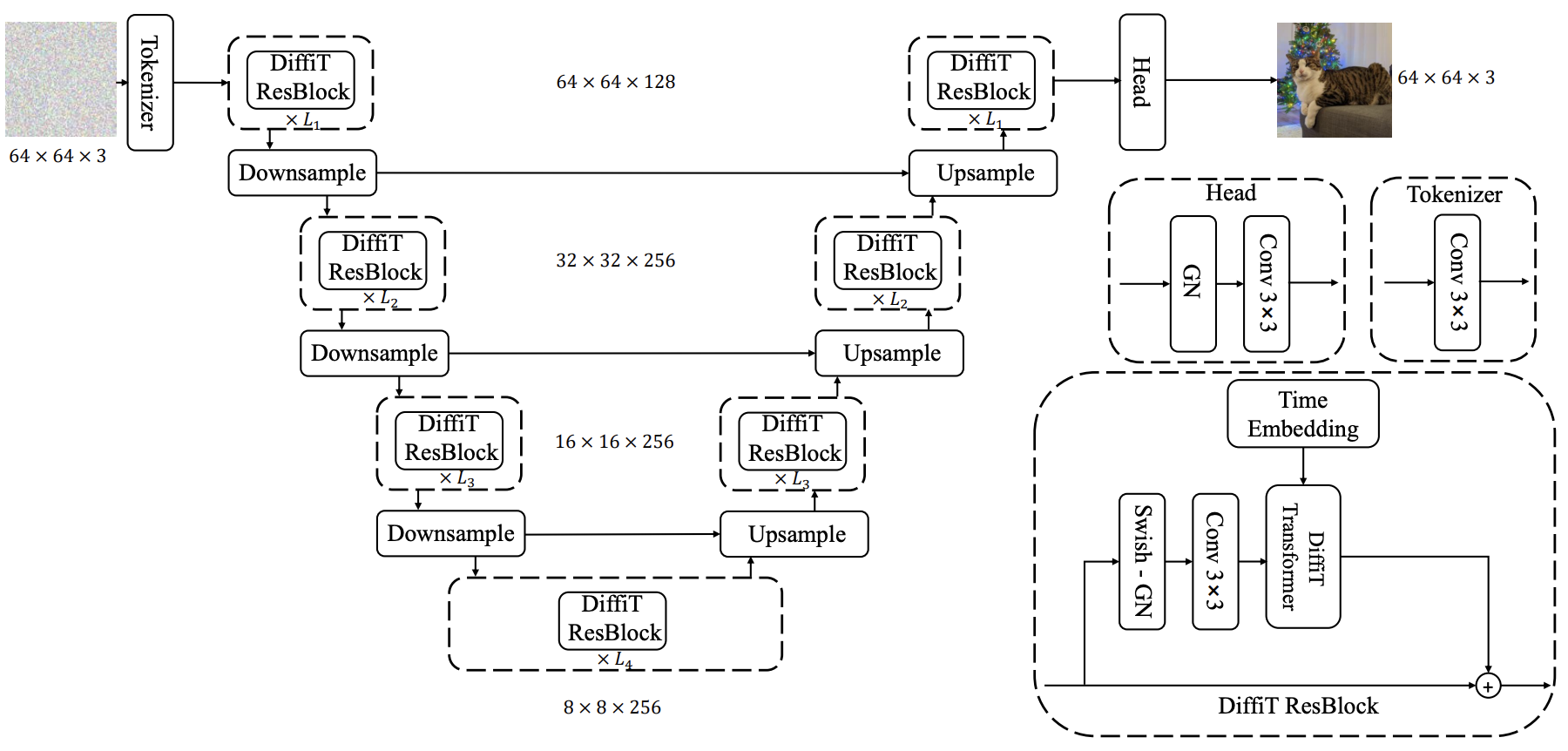
上圖為本文所提DiffIT整體架構示意圖,很明顯,核心是所提DiffiT ResBlock,故我們僅對該核心模塊進行簡要介紹。
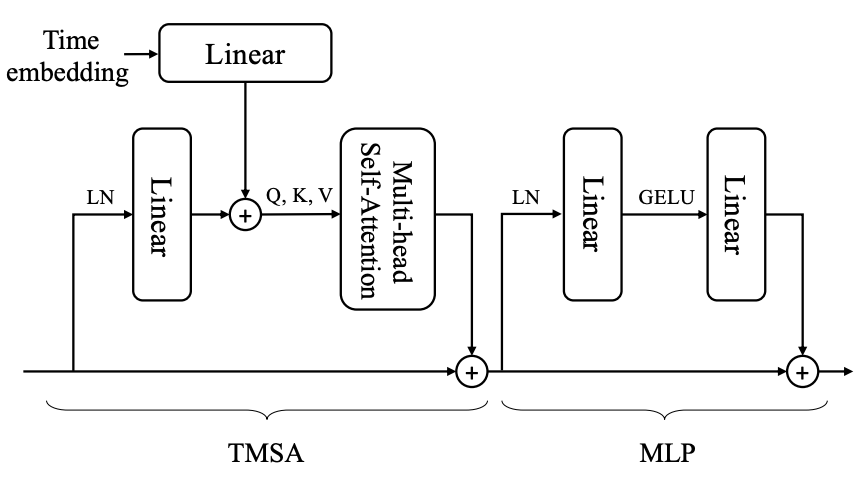
上圖為DiffiT模塊示意圖,可以描述如下:
關于TMSA,在每一層,我們的transformer塊接收{xs},一組標記在其輸入中空間上排列在2D網格上。它還接收xt,這是表示時間步長的時間標記。通過將位置時間嵌入提供給具有swish激活的小型MLP來獲得時間標記[19]。這次令牌被傳遞到我們的去噪網絡中的所有層。本文提出了時間依賴的多頭自注意力,通過在共享空間中投影特征和時間標記嵌入來捕捉長程空間和時間依賴性。具體來說,共享空間中的時間依賴查詢q、鍵k和值v是 通過空間和時間嵌入的線性投影xs和xt via計算
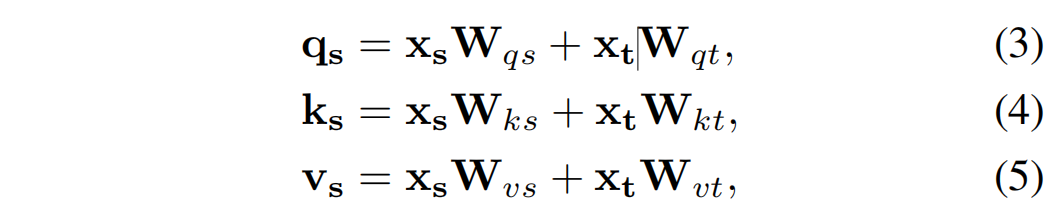
key、query和value都是時間和空間token的線性函數,它們可以針對不同的時間步長自適應地修改注意力的行為。
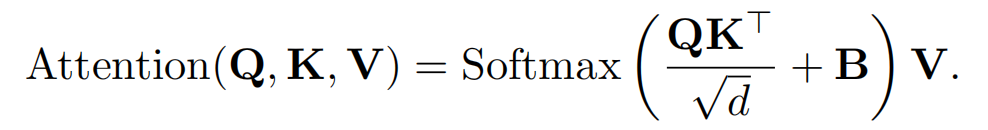
圖像空間
DiffIT結構 DiffiT使用對稱的u型編碼器-解碼器架構,其中收縮和擴展路徑在每個分辨率上通過跳躍連接相互連接。編碼器或解碼器路徑的每個分辨率由L連續的DiffiT塊組成,其中包含所提出的時間依賴的自注意力模塊。在每條路徑的開始,對于編碼器和解碼器,使用一個卷積層來匹配特征圖的數量。此外,卷積上采樣或下采樣層還用于每個分辨率之間的過渡。我們推測,這些卷積層的使用嵌入了可以進一步提高性能的歸納圖像偏差。在本節的其余部 分,我們討論了DiffiT Transformer塊和提出的時間依賴自注意力機制。在構建u型去噪架構時,使用所提出的Transformer塊作為殘差單元。
DiffiT ResBlock 通過將所提出的DiffiT Transformer塊 與額外的卷積層相結合,定義最終的殘差單元:
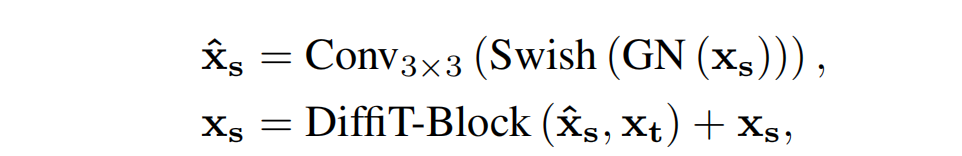
潛空間
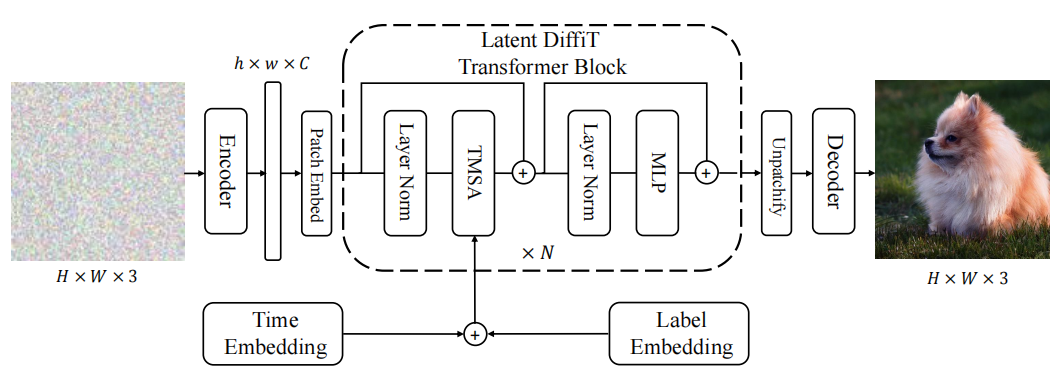
潛擴散模型被證明可以有效地生成高質量的大分辨率圖像。在圖4中,我們展示了隱DiffiT模型的架構。我們首先使用預訓練的變分自編碼器網絡對圖像進行編碼,然后將特征圖轉換為不重疊的塊并投影到新的嵌入空間。與DiT模型[52]類似,我們使用視覺transformer,沒有上采樣或下采樣層,作為潛空間中的去噪網絡。此外,還利用三通道無分類器指導來提高生成樣本的質量。架構的最后一層是一個簡單的線性層,用于對輸出進行解碼。
本文實驗
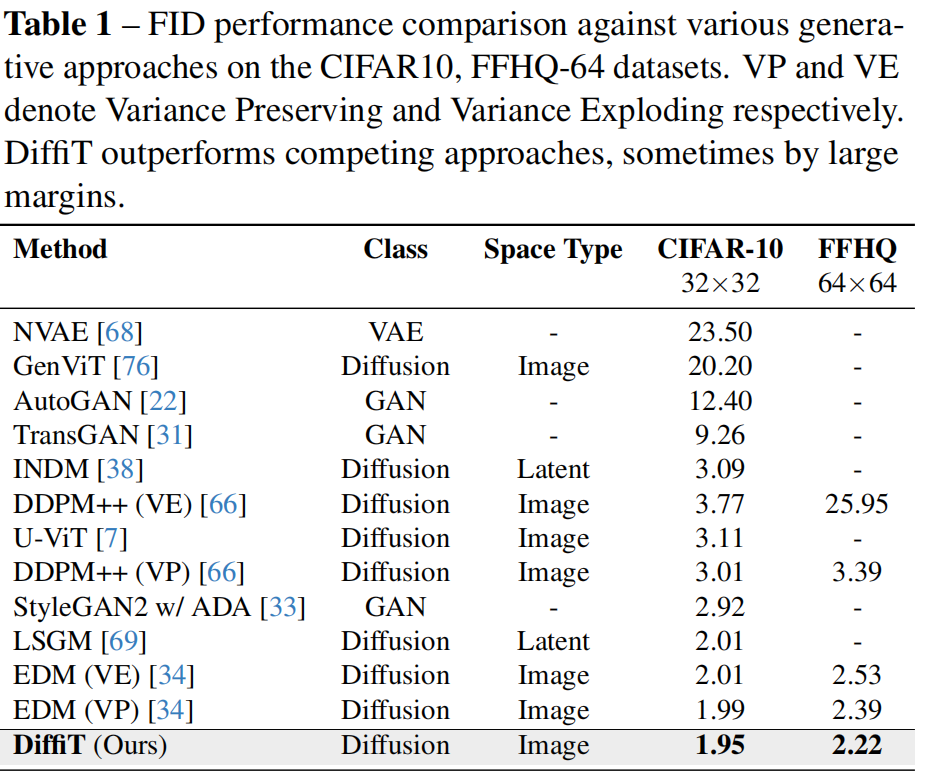
 DiffiT在CIFAR- 10數據集上取得了最先進的圖像生成FID分數1.95, 超 過 了EDM [34]和LSGM [69]等 最 先 進 的 擴 散 模 型 。 與 最 近 的 兩 個 基 于vit的 擴 散 模 型 相 比 , 所 提出的DiffiT在CIFAR-10數據集上的FID分數明顯優 于U-ViT [7]和GenViT [76]模 型 。 此 外 , 就FID分 數 而言,DiffiT在VP和VE訓練配置方面明顯優于EDM [34]和ddpm++ [66]模型。在圖5中,我們對FFHQ-64數 據集上生成的圖像進行了說明。
DiffiT在CIFAR- 10數據集上取得了最先進的圖像生成FID分數1.95, 超 過 了EDM [34]和LSGM [69]等 最 先 進 的 擴 散 模 型 。 與 最 近 的 兩 個 基 于vit的 擴 散 模 型 相 比 , 所 提出的DiffiT在CIFAR-10數據集上的FID分數明顯優 于U-ViT [7]和GenViT [76]模 型 。 此 外 , 就FID分 數 而言,DiffiT在VP和VE訓練配置方面明顯優于EDM [34]和ddpm++ [66]模型。在圖5中,我們對FFHQ-64數 據集上生成的圖像進行了說明。


-
在ImageNet-256數據集中, 潛在DiffiT模型在FID分數方面優于MDT-G [21]、DiTXL/2-G [52]和StyleGAN-XL [61]等競爭方法,并設 置了新的SOTA FID分數為1.73。在IS和sFID等其他 指 標 方 面 , 潛DiffiT模 型 表 現 出 了 有 競 爭 力 的 性 能 , 從 而 表 明 了 所 提 出 的 時 間 依 賴 自 注 意 力 的 有 效 性 。 -
在ImageNet-512數 據 集 中 , 隱DiffiT模 型 在FID和Inception分數(IS)方面明顯優于DiT-XL/2-G。 盡管StyleGAN-XL [61]在FID和IS方面顯示了更好的 性能,但眾所周知,基于gan的模型存在多樣性低 的問題,這些問題無法被FID分數捕獲。這些問題 反映在StyleGAN-XL在準確率和召回率方面的次優 性能上。 -
此外,在圖6中,我們展示了在ImageNet- 256和ImageNet-512數據集上生成的未策劃圖像的可視 化。潛DiffiT模型能夠在不同的類別中生成各種高質量 的圖像。
本文由 mdnice 多平臺發布

)





頂一個諸葛亮(docker))


)





)


