索引
定義
索引是對數據庫表中一列或者多列的值進行排序的結構。
目的
數據庫索引好比一本書的目錄,提高查詢效率。但是為表設置索引要付出相應的代價:
-
增加了數據庫的存儲空間 -
在插入和修改時需花費更多的時間(因為索引也要隨之變動)
分類
1. 聚集索引
索引項的順序與表中記錄的物理順序一致。對于聚集索引,葉子結點即存儲其真實的數據行,不再有另外單獨的數據頁。
2. 非聚集索引
表數據存儲順序與索引順序無關。對于非聚集索引,葉子結點包含索引字段值和數據頁數據行的地址,其行數量與數據表中行數量一致。
注意:一個表中只有一個聚集索引,但是可以有多個非聚集索引。
3. 唯一索引
不允許具有索引值相同的行,但是可以為 NULL,不能有多個 NULL。
4. 主鍵索引
是唯一索引的特殊類型。數據庫表中經常有一列或多列組合,其值唯一標識表中的每一行,該列稱為表的主鍵。
在數據庫中為表定義主鍵將自動創建主鍵索引。
索引存儲結構
B 樹
對于 m 階 B 樹,有如下性質:
-
根節點至少有 2 個孩子節點
-
樹中每個節點最多含有 m 個孩子(m >= 2)
-
除根節點、葉子節點外其他節點至少有 ceil(m/2) 個孩子
-
所有葉子節點都在同一層
-
假設每個非終端節點中包含 n 個關鍵字信息,其中
a)Ki(i=1..n)為關鍵字,being且找順序升序排序 K(i-1) < Ki
b)關鍵字的個數 n 必須滿足:ceil(m/2)-1 <= n <= (m-1)
c)非葉子節點的指針:P[1],P[2],... ,P[M];其中 P[1] 指向關鍵字小于 K[1] 的子樹,P[M] 指向關鍵字大于 K[M-1] 的子樹,其他 P[i] 關鍵字屬于(K[i-1],K[i]) 的子樹
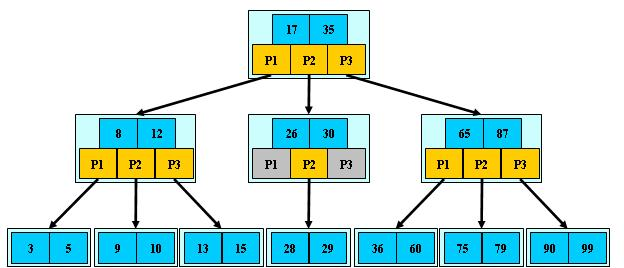
B+ 樹
B+ 樹是 B 樹的變體,其定義基本與 B 樹相同,除了:
-
非葉子節點的子樹指針和關鍵字個數相同
-
非葉子節點的子樹指針 P[i],指向關鍵字值 [K[i],K[i+1]) 的子樹
-
非葉子節點僅用來索引,數據都保存在葉子節點
-
所有葉子節點均有一個鏈指針指向下一個葉子節點
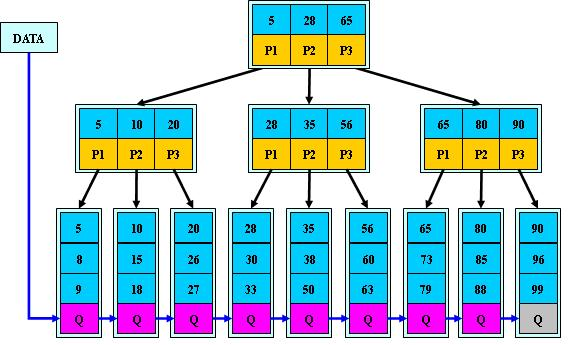
數據庫系統普遍采用 B+ 樹作為索引結構,主要有以下原因:
-
B+ 樹的磁盤讀寫代價更低
因為非葉子結點只存儲索引信息,其內部節點相同 B 樹更小,如果把 key 存入同一盤塊中,盤塊所能包含的 key 越多,一次性讀入內存中需要查找的 key 就越多,相對來說磁盤的 I/O次數就減少了。
舉個例子:假設磁盤中的一個盤塊容納 16 字節,而一個 key 占 2 字節,一個 key 具體信息指針占 2 字節。一棵 9 階 B 樹(一個結點最多 8 個關鍵字)的內部結點需要 2 ( (8*(2+2) / 16 = 2)個盤塊。B+ 樹內部結點只需要 1 (8 * 2 / 16 = 1)個盤塊。當需要把內部結點讀入內存中的時候,B 樹就比 B+ 樹多 1 次盤塊查找時間。
-
B+ 樹的查詢效率更加穩定
由于非葉子結點并不是最終指向文件內容的結點,而只是葉子結點中關鍵字的索引。所以任何關鍵字的查找必須走一條從根結點到葉子結點的路。所有關鍵字查詢的路徑長度相同,導致每一個數據的查詢效率相當。
-
B+ 樹更有利于對數據庫的掃描
B+ 樹只要遍歷葉子結點就可以遍歷到所有數據。
HASH
哈希索引就是采用一定的哈希算法,把鍵值換算成新的哈希值,檢索時不需要類似 B+ 樹那樣從根節點到葉子節點逐級查找,只需一次哈希算法即可立刻定位到相應位置,速度非常快。
哈希索引底層的數據結構是哈希表,能以 O(1) 時間進行查找,但是失去了有序性;因此在絕大多數需求為單條記錄查詢的時候,可以選擇哈希索引,查詢性能最快。
哈希索引的不足:
-
無法用于排序與分組 -
只支持 精確查找,無法用于部分查找和范圍查找 -
不能避免全表掃描 -
遇到大量 Hash 沖突的情況效率會大大降低
索引的物理存儲
MySQL 索引使用的是 B 樹中的 B+ 樹,但索引是在存儲引擎層實現的,而不是在服務器層實現的,所以不同存儲引擎具有不同的索引類型和實現。
MyISAM 索引存儲機制
MyISAM 引擎使用 B+ 樹作索引結構,葉子節點的 data 域存放的是數據記錄的地址,所有索引均是非聚集索引。
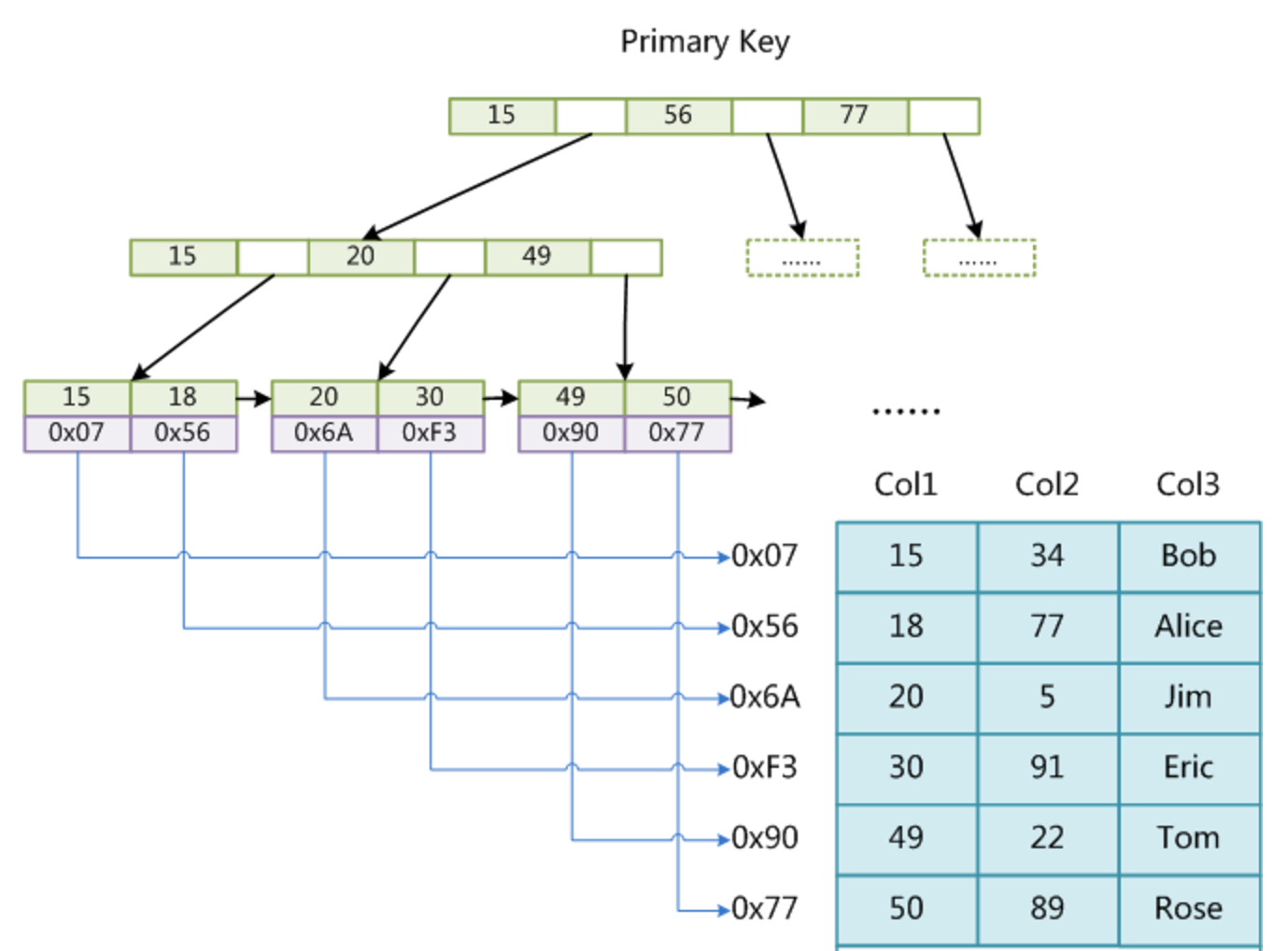
上圖是一個 MyISAM 表的主索引(Primary key)示意圖。
假設該表一共有三列,以 Col1 為主鍵。MyISAM 的索引文件僅僅保存數據記錄的地址。
在 MyISAM 中,主索引和輔助索引(Secondary key)在結構上沒有任何區別,只是主索引要求 key 是唯一的,而輔助索引的 key 可以重復。如果在 Col2 上建立一個輔助索引,則該輔助索引的結構如下:
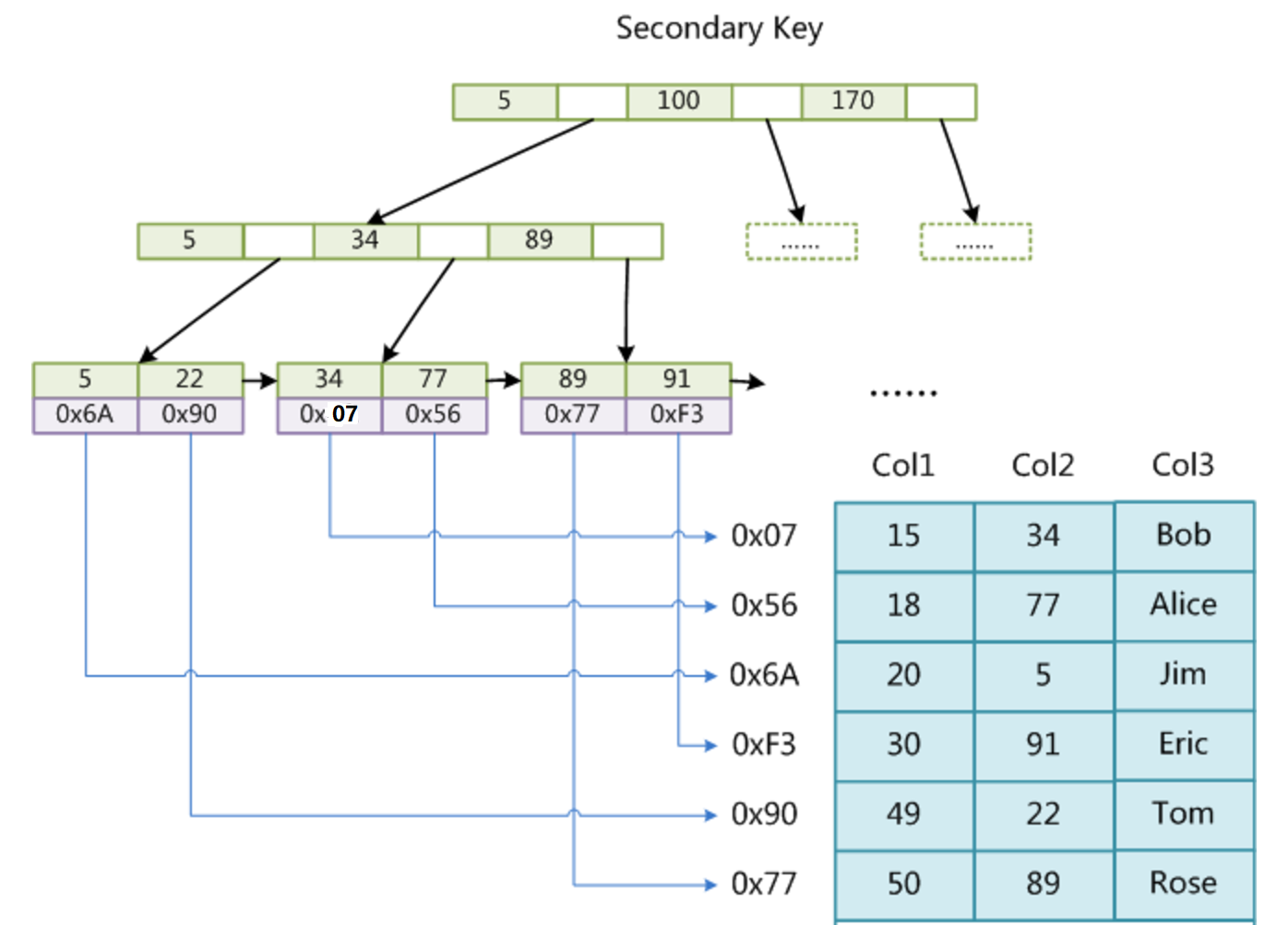
同樣也是一棵 B+ 樹,data 域保存數據記錄的地址。
MyISAM 中首先按照 B+ 樹搜索算法搜索索引,如果指定的 key 存在,則取出其 data 域的值,然后以 data 域的值為地址,讀取相應數據記錄。 MyISAM 的索引方式也叫做非聚集索引(稀疏索引)(索引和數據是分開存儲的)。
InnoDB 索引存儲機制
InnoDB 也使用 B+ 樹作為索引結構。有且僅有一個聚集索引,和多個非聚集索引。
InnoDB 的數據文件本身就是索引文件。MyISAM 索引文件和數據文件是分離的,索引文件僅保存數據記錄的地址。而在 InnoDB 中,表數據文件本身就是按 B+ 樹組織的一個索引結構,這棵樹的葉子節點 data 域保存了完整的數據記錄。這個索引的 key 是數據表的主鍵,因此 InnoDB 表數據文件本身就是主索引。
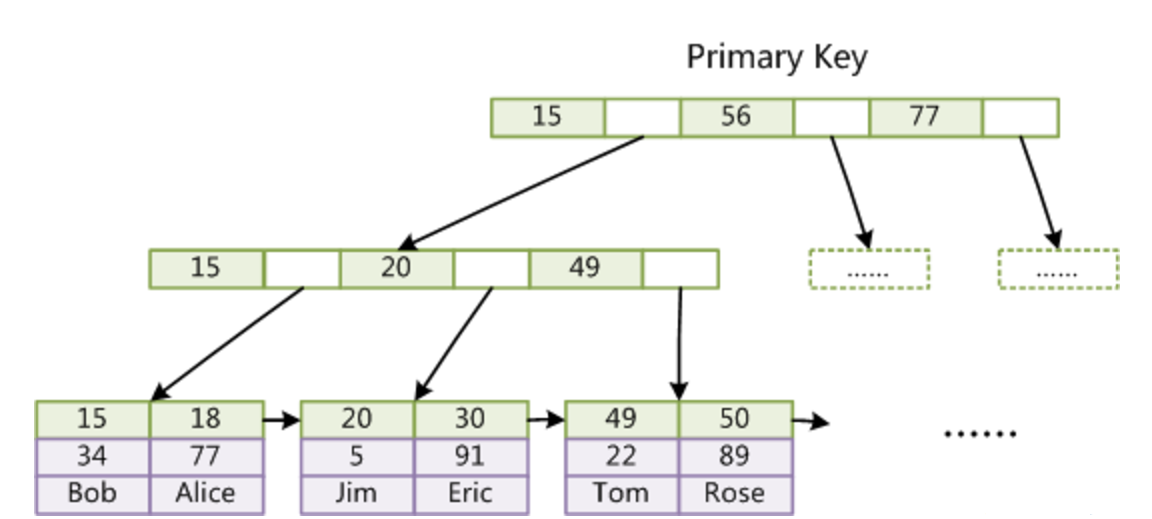
上圖是 InnoDB 主索引(同時也是數據文件)的示意圖。可以看到葉子節點包含了完整的數據記錄。
這種索引叫做聚集索引(密集索引)(索引和數據保存在同一文件中):
-
若一個主鍵被定義,該主鍵作為聚集索引; -
若沒有主鍵定義,該表的第一個唯一非空索引作為聚集索引; -
若均不滿足,則會生成一個隱藏的主鍵( MySQL 自動為 InnoDB 表生成一個隱含字段作為主鍵,這個字段是遞增的,長度為 6 個字節)。
與 MyISAM 索引的不同是 InnoDB 的輔助索引 data 域存儲相應記錄主鍵的值而不是地址。例如,定義在 Col3 上的一個輔助索引:

聚集索引這種實現方式使得按主鍵的搜索十分高效,但是輔助索引搜索需要檢索 2 遍索引:
首先檢索輔助索引獲得主鍵,然后用主鍵到主索引中檢索獲得記錄。
注意 InnoDB 索引機制中:
-
不建議使用過長的字段作為主鍵,因為所有輔助索引都引用主索引,過長的主索引會令輔助索引變得過大。
-
不建議用非單調的字段作為主鍵,因為 InnoDB 數據文件本身是一棵 B+ 樹,非單調的主鍵會造成在插入新記錄時數據文件為了維持 B+ 樹的特性而頻繁的分裂調整,十分低效。
使用自增字段作為主鍵則是一個很好的選擇。
索引的優點
-
大大減少了服務器需要掃描的數據行數。 -
幫助服務器避免進行排序和分組,以及避免創建臨時表(B+Tree 索引是有序的,可以用于 ORDER BY 和 GROUP BY 操作。臨時表主要是在排序和分組過程中創建,不需要排序和分組,也就不需要創建臨時表)。 -
將隨機 I/O 變為順序 I/O(B+Tree 索引是有序的,會將相鄰的數據都存儲在一起)。
建索引的原則
-
最左前綴匹配原則
MySQL 會一直向右匹配知道遇到范圍查詢(>、<、between、like)就停止匹配。比如
a=3 and b=4 and c>5 and d=6,如果建立 (a,b,c,d) 順序的索引,d 就是用不到索引的,如果建立(a,b,d,c) 的索引則都可以用到,并且 a,b,d 的順序可以任意調整。 -
= 和 in 可以亂序
比如
a = 1 and b = 2 and c = 3建立 (a,b,c) 索引可以任意順序,MySQL 的查詢優惠器可進行優化。 -
盡量選擇選擇度高的列建索引
#?選擇度計算
SELECT?COUNT(DISTINCT?staff_id)/COUNT(*)?AS?staff_id_selectivity,
COUNT(DISTINCT?customer_id)/COUNT(*)?AS?customer_id_selectivity,
COUNT(*)
FROM?payment; -
使用 like 進行模糊查詢時,如果已經建立索引,第一個位置不要使用 '%',否則索引會失效。
-
當檢索性能遠遠大于檢索性能時,不應該建立索引。
索引失效
-
最左前綴匹配原則,遇到范圍查詢
-
like 模糊查詢,第一個位置使用 '%'
-
沒有查詢條件
-
表比較小時,全表掃描速度比索引速度快時,索引失效
(由于索引掃描后要利用索引中的指針去逐一訪問記錄,假設每個記錄都使用索引訪問,則讀取磁盤的次數是查詢包含的記錄數T,而如果表掃描則讀取磁盤的次數是存儲記錄的塊數B,如果T>B 的話索引就沒有優勢了。)
本文由 mdnice 多平臺發布

)
)

)


 20)


工程中提示詞的開發優化基礎概念學習總結)
)







