本章內容
- 一致性檢查點
- 從檢查點恢復狀態
- 檢查點實現算法-barrier
- 保存點Savepoint
- 狀態后端(state backend)
本文先設置一個前提,流處理的數據都是可回放的(可以理解成消費的kafka的數據)
一致性檢查點(checkpoints)

圖1
- checkpoint是Flink故障恢復的核心,全稱是應用狀態的一致性檢查點
- 有狀態流應用的一致性檢查點,其實就是所有任務處理完數據的狀態,在某個時間點的一份拷貝(一份快照,存儲在狀態后端),這個時間點,應用是所有任務能恰好處理完一個相同的輸入數據的時候
(圖1中不考慮時間,假設1、2、3、4、5、6、7為source源,even為偶數6=2+4,odd為奇數求和9=1+3+5,此時5這個數據在所有tasks都處理完成了,每個任務都會提交一份快照給JM,最終這份拓撲結構(source任務狀態是5、sum_even狀態是6、sum_odd狀態是9)稱為checkpoint)
從檢查點恢復狀態
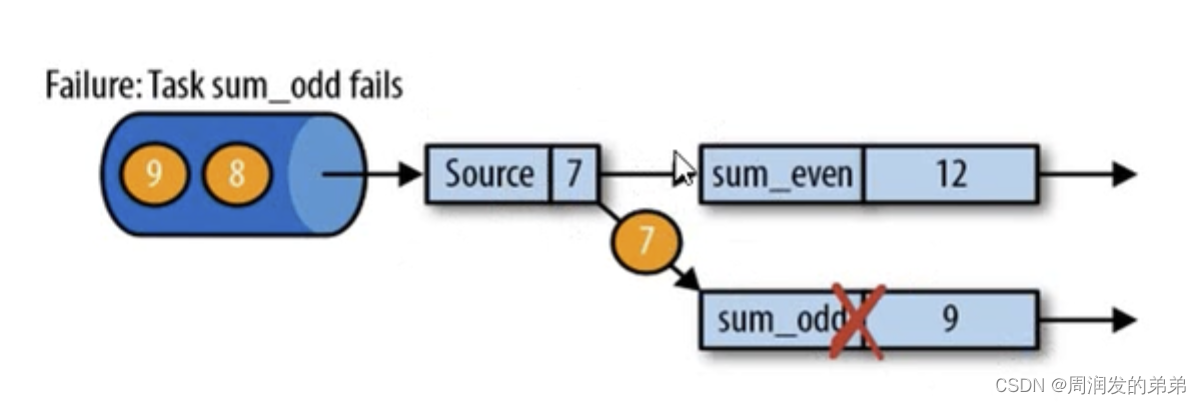
圖2
- 在執行流應用期間,Flink會定期保存狀態的一致性檢查點
- 如果發生故障,Flink會使用最近的檢查點來一致恢復應用程序的狀態,并重新啟動處理流程
(假設處理到7這個數據的時候,sum_even=2+4+6=12,sum_odd在處理7這個數據的時候fail了,應該如果恢復數據呢)
第一步:遇到故障之后,重啟受影響的應用,應用重啟的之后,所有任務的狀態都是空的
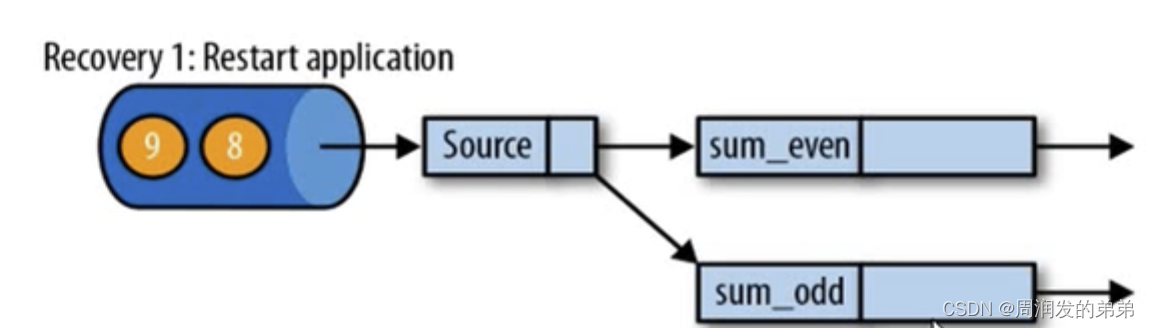
圖3
第二步:從checkpoint中讀取狀態,將狀態重置,從檢查點重新啟動應用程序后,其內部狀態與檢查點完成時的狀態完全相同(回到了和圖1相同的狀態,如果算子設置了并行度,也可以恢復)。恢復后,source任務必須從檢查點恢復的結果后開始讀取數據(必須從6開始讀取數據)
圖4
第三步:開始消費并處理檢查點到發生故障之間的所有數據。(處理完7后,sum_even=2+4+6=12,sum_odd=1+3+5+7=16, 所有tasks都處理完后,又會提交一個checkpoint)

圖5
這種檢查點的保存和恢復機制可以為應用程序狀態提供“精確一次”(exactly-once)的一致性,因為所有的算子都會保存檢查點并恢復其所有狀態,這樣依一來所有的輸入流就都會被重置到檢查點完成時的位置。
檢查點的實現算法
基于Chandy-Lamport算法的分布式快照,將檢查點的保存和數據處理分離開,不暫停整個應用
思考一個問題:flink如何判斷某個數據已經處理完了呢?(比如圖1的offset=5的數據)
答案:是否在每個數據后面跟一個標記,當讀到這個標記的時候觸發task狀態的保存
檢查點分界線(checkpoint barrier)
- Flink的檢查點算法用到了一種稱為分界線(barrier)的特殊數據形式,用來把一條流上數據按照不同的檢查點分開
- 分界線之前到來的數據導致的狀態更改,都會包含在當前分界線所屬的檢查點中;二基于分界線之后的數據導致的所有更改,就會包含在之后的檢查點中
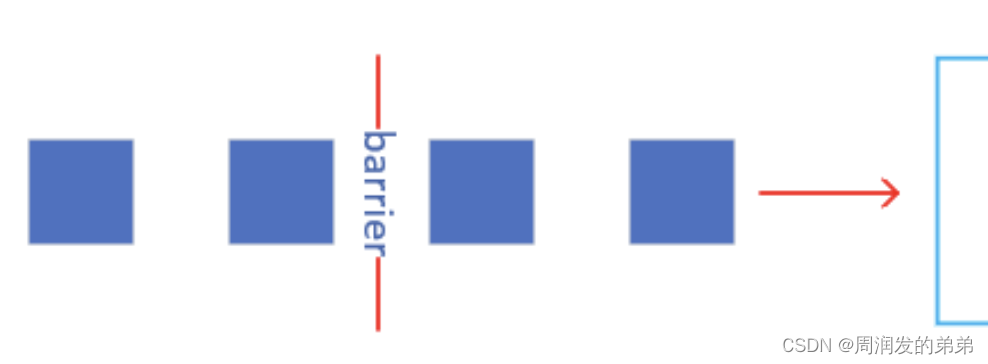
圖6
barrier有很多叫法,如檢查點屏障等
分析一下barrier的工作流程,假設現在有這樣的一個場景:有兩個輸入流的應用程序,用并行的兩個source任務來讀取(可以認為kafka的兩個分區,source并行度設置為2),如圖7所示。barrier也是和watermark一樣,都是通過廣播的方式傳遞給下游算子

圖7
(source任務的并行度=2,sum任務的并行度也是2,sink任務的并行度也是2。)
如圖7,兩個流的數據都是1、2、3、4、5、6;藍色數字圓圈代表最后一個處理的是藍流里面的數據,黃色數字圓圈代表最后一個處理的是黃流里面的數據。

圖8
圖8中兩條流的情況下,barrier如何傳遞呢?(watermark是取上游分區的最小值)下面一起來看一下
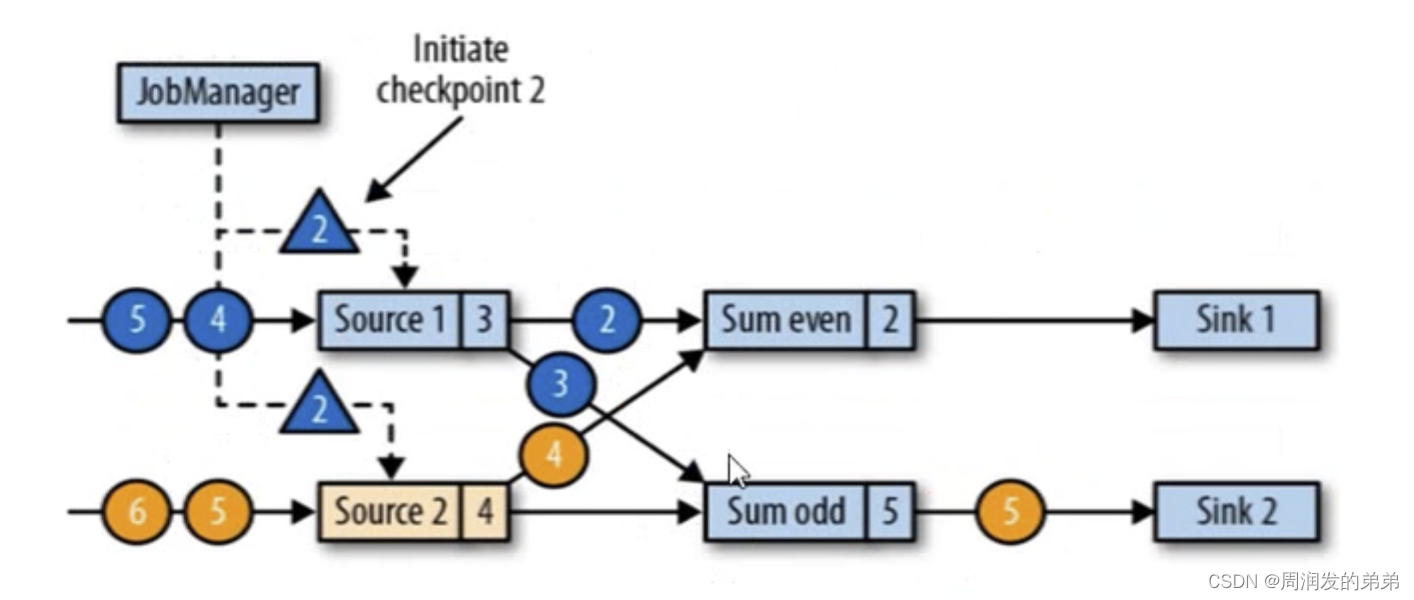
圖9
barrier是怎么產生的?
答:JobManager會向每個source任務(同時發給并行的source任務)發送一條帶有檢查點ID的消息(藍色三角形2),通過這種方式來啟動檢查點。產生barrier的過程中,不會影響下游task的正常工作(圖9相比圖8黃2和藍2都sink完成了)圖9中barrier(ID=2)插入在stream1的3后面,stream2的4后面

圖10
barrier隨著數據流動,廣播到下游,source任務處理完barrier(ID=2)后,會向狀態后端發送checkpoint,記錄此時的狀態。圖10相比圖9藍3和黃4都被sum任務處理了。
- 數據源將他們的狀態寫入檢查點,并發出一個檢查點barrier
- 狀態后端在狀態存入檢查點之后,會返回通知給source任務,source任務就會向JobManager確認檢查點完成
sum_even收到上游所有的barrier之后,才能去做checkpoint狀態保存,這就叫做Barrier對齊(分分界線對齊)

圖11
- 分界線對齊:barrier向下游傳遞,sum任務會等待所有的輸入分區的barrier到達
- 對于barrier已經到達的分區,繼續到達的數據會被緩存
- 而barrier尚未到達的分區,數據會被正常處理
圖11中的sum_even中的藍4需要被緩存,因為來自上游任務的黃色barrier(ID=2)還未到達。(stream1有可能在同一個slot,stream2和stream1跨slot,可能barrier到達的時間會不一致)
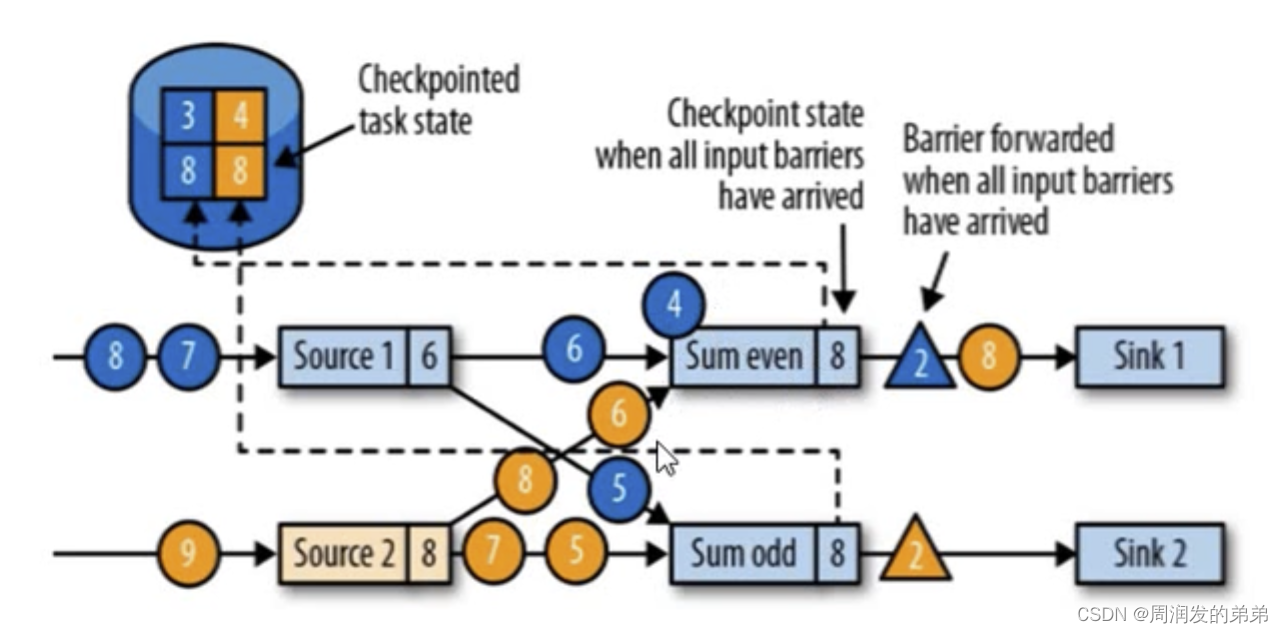
圖12
- 當收到所有分區的barrier時,任務就講其狀態保存到狀態后端的檢查點中,然后barrier繼續向下游廣播
圖12中,barrier(ID=2)繼續向下游廣播。此時藍色4會從緩存中拿出來做接下來的計算
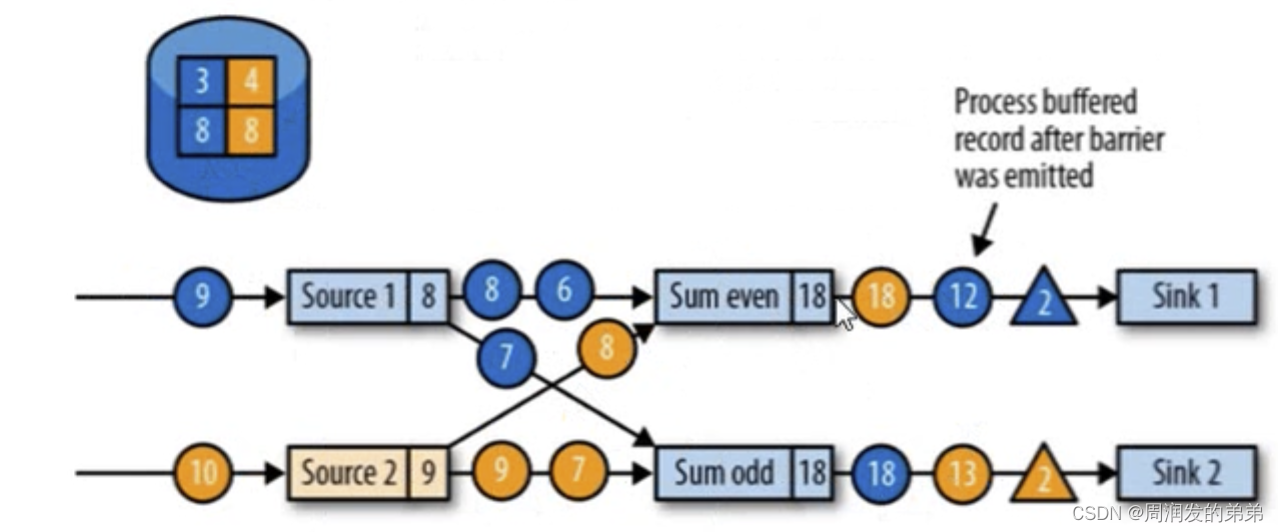
圖13
圖13中,sum_even處理完4+8=12,以及4+6+8=18,任務開始正常的數據處理
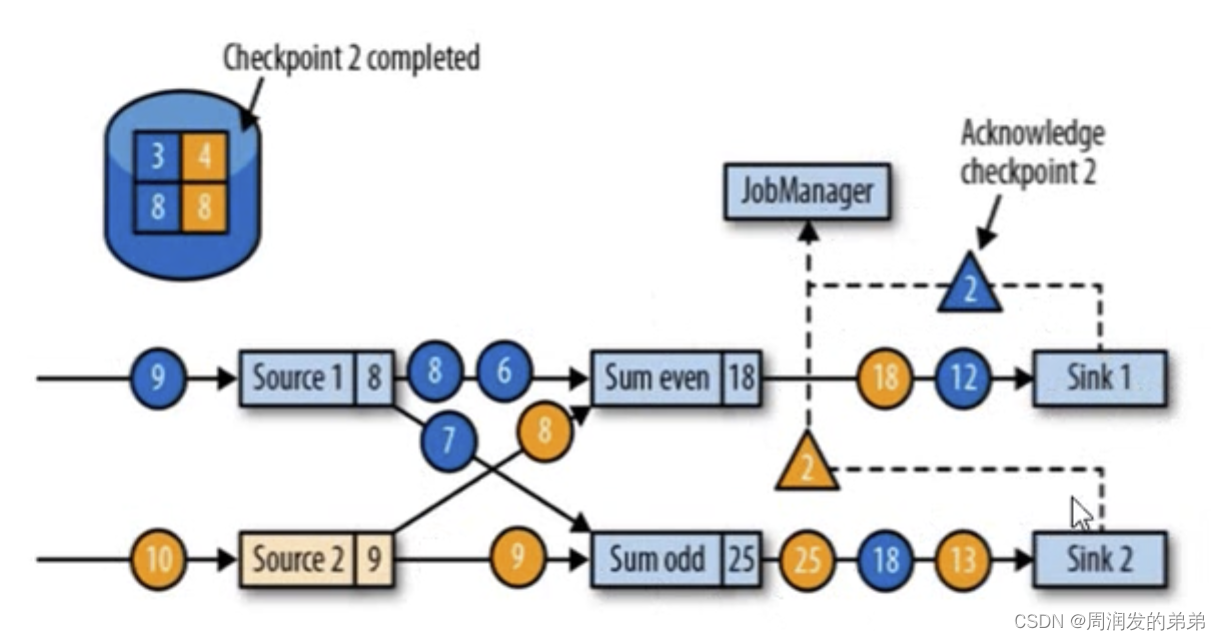
圖14
- sink任務向JobManager確認狀態保存到checkpoint完畢
- 當所有的任務都確認已經成功將狀態保存到檢查點時,檢查點就真正完成了(3-4-8-8拓撲保存完成)
最終JobManager會向所有的任務確認task的狀態是否正確,確認完成后任務完成。
保存點
- Flink還提供了自定義的鏡像保存功能,就是保存點(savepoints)
- 原則上,創建保存點使用的算法與檢查點的完全相同,因此保存點可以認為就是具有一些額外元數據的檢查點
- Flink不會自動創建保存點,因此用戶(或者外部調度系統)必須明確的觸發創建操作
- 保存點是一個強大的功能。除了故障恢復外,保存點可以用于:有計劃的手動備份,更新應用程序,版本遷移,暫停和重啟應用,等等
狀態后端
Flink 提供了三種可用的狀態后端用于在不同情況下進行狀態的保存
-
MemoryStateBackend
內存級的狀態后端,將監控狀態作為內存中的對象進行管理,將他們存儲在TM的JVM堆上,而將checkpoint存儲在JM的內存中
-
FsStateBackend
將checkpoint存儲到遠程的持久化系統FileSystem中,而對于本地狀態,和MemotyStateBackend一樣,也會存儲在TM的JVM堆上
-
RocksDBStateBackend
將所有的狀態序列化后,存入本地的RocksDB中(注意:RocksDb的支持并不直接包含在Flink中,需要引入依賴),RocksDBStateBackend 是唯一支持增量快照的狀態后端。
后續補充具體的代碼






)








)

——Pattern Recognition (2))

