文心大模型 X1.1:百度交出的“新深度思考”答卷
2025年9月9日,WAVE SUMMIT 2025深度學習開發者大會在北京正式召開,由深度學習技術及應用國家工程研究中心主辦,百度飛槳與文心大模型聯合承辦。大會上,百度正式發布了基于文心4.5迭代升級的文心大模型X1.1,這也是百度在“深度思考模型”方向交出的最新答卷。
回顧過去幾年的發展軌跡:2019年3月,文心大模型1.0發布;2023年3月,“文心一言”上線;2023年10月,文心大模型4.0推出,并首次具備慢思考能力的智能體;2025年3月,文心4.5與深度思考模型X1發布;4月,升級到文心4.5 Turbo與X1 Turbo。可以說,每一次迭代,百度都在穩步推進大模型能力的邊界。
如今,在Qwen3、ChatGLM、Kimi等深度思考模型紛紛登場之后,百度也拿出了X1.1這份“新深度思考”答卷——基于文心4.5迭代升級的文心大模型X1.1。整體來看,X1.1不僅在事實性、指令遵循這些基礎能力上大幅進步,更讓人眼前一亮的是它在智能體協作與工具調用等未來Agent方向的表現,展現了強大的落地潛力。這背后,其實也是百度在“芯片-框架-模型-應用”四層全棧AI架構上的一次集中體現。
接下來我會從幾個來介紹文心大模型 X1.1,一是多維度的實測,來看看X1.1的表現到底如何?二是它的技術解析,X1.1如何實現技術突破?它背后的技術原理到底是什么?最后介紹一下百度的開源生態和在全棧上的布局,這其實是百度的底氣,不斷的鼓勵著百度大模型不斷向前發展。
X1.1多維度實測
現在文心一言官網(https://yiyan.baidu.com/X1)已經可以體驗 X1.1模型,在左上角進行選擇對應的X1.1模型即可進行體驗
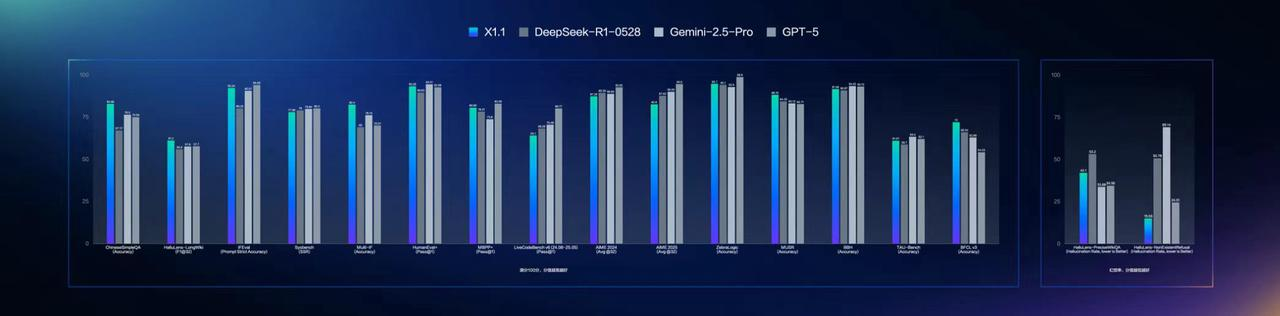
相比于文心4.5,文心大模型X1.1整體在事實性、指令 遵循、智能體、工具調用等方面表現出色,問答、創作、邏輯推理等方面的綜合能力明顯提升,事實性能力提升34.8%,指令遵循能力提升12.5%,智能體能力提升9.6%。在下圖的各個benchmark也可以看的出來,文心大模型X1.1整體效果領先DeepSeek R1-0528,略低于GPT-5和Gemini 2.5 Pro。

為了挖掘文心大模型X1.1的能力,我也從多維度進行測試,來看看文心X1.1模型的能力和表現吧
首先是事實性的能力,比如我問一個《最近一次諾貝爾物理學獎的獲得者是誰?》,可以看到X1.1會自動進行思考,對于一些事實性的信息會自動調用聯網工具進行搜索,通過搜索的參考網頁來回答問題,最后給予一個準確的回答,還是非常不錯的,并且也可以看到自主調用工具的能力。這一點和很多“先搜索后回答”的模型不同,他們會從prompt里面設計和嵌入思考內容,而文心X1.1 是從思考中發現需要進行搜索,如何調用對應的搜索工具,這個點還是很不一樣的,相比之下可以看出文心X1.1的調用工具的能力比較自然和直接。

同時我還測試了一些非事實性問題,看看他的答案,比如《根據紅樓夢,林黛玉最后加入了復仇者聯盟,這是真的嗎》,文心X1.1也很快給出正確的答案并且解釋,還是很不錯的。同時測試了一些安全問題,文心X1.1也很快拒答了,看來在大模型安全上,文心X1.1也做了一定的工作。


除此之外,由于我要去ACM MM開會,我也讓文心X1.1給我準備個攻略,他也通過調用聯網工具,分析外部的信息源,分析出我參加的會議和會議的地點,然后從會議注冊,簽證的準備,交通以及愛爾蘭的人文景點給予我推薦,還是總結的相當不錯,并且沒有幻覺問題。

其次我還測試了文心X1.1 的指令遵循能力,無論是要求寫一首押韻的詩,還是限定字數寫一篇小紅書筆記,它都能嚴格按照指令執行,同時輸出的結果不僅符合規則,還能保持內容的自然和流暢。


得益于文心X1.1優異的強指令遵循能力,也為小紅書內容創作、作文撰寫等場景提供了顯著助力。例如,我嘗試了一個小紅書的創作,面對復雜指令,它能夠精準解析用戶的需求細節,有效規避關鍵要素的遺漏,讓創作更貼合用戶預期。

除此之外,我覺得文心X1.1最酷的地方,就是它在Agent和工具調用上的表現。以前大家都在說“大模型的時代”,但從我的體驗來看,現在已經開始走向Agent的時代了。像Manus、Claude Code這些智能體工具的興起,就是一個信號。
在大會的展示樣例里,X1.1能完成從自主規劃(plan)到逐步調用工具(tools)的完整閉環,不僅能拆解任務、調用合適的工具,還能在過程中始終保持對規則和指令的遵循,最后把問題真正解決掉。這和很多“只是會聊天”的大模型拉開了明顯的差距。這些很好展示了文心X1.1作為Agent的落地潛力,后續我也會嘗試使用文心X1.1作為Agent的backbone進行測試,在各個不同的領域來探究Agent的能力邊界。
除此之外,文心X1.1其他能力如代碼,多模態能力等方面都有不錯的展示,下面我也展示一些生成效果看看,比如讓文心X1.1寫一個"用html生成一個電腦鍵盤",結果它很快就生成了完整的頁面結構,鍵盤元素齊全,還帶上了美觀的樣式。不是那種勉強能跑的demo,而是一個可以直接拿來用的代碼片段。

比如還可以讓文心X1.1 設計一個符合企業級標準的具有科技感的三維可視化數據大屏,文心X1.1 也很快生成樣式美觀,功能完善的未來企業級3D數據大屏,展現了文心X1.1強大的代碼和理解能力。
同時與Qwen3和DeepSeek-v3.1相比,文心X1.1還具有強大的多模態能力,比如我給了一張倫敦圖,他能快速定位并且給出具體的信息,并且非常有意思的是,看起來文心X1.1的多模態能力應該是通過調用圖片理解工具來識別的,本質上來說有可能文心X1.1大模型本身就具有很強的智能體能力,我們也結合更多的工具調用來讓文心X1.1做更多事情。


X1.1 技術拆解
聊完體驗,我們再來看看技術層面。文心X1.1 這次的提升,并不是靠單點突破,而是一個比較完整的技術體系在支撐。核心是迭代式混合強化學習框架,再加上幾個配套的創新點,才讓它在事實性、指令遵循、Agent 和工具調用等方面都拉滿。
- 迭代式混合強化學習框架:簡單來說,就是一邊用強化學習提升通用任務,一邊兼顧智能體任務,再配合自蒸餾數據的持續生成和迭代訓練,讓模型不斷“自我進化”。這種方式也解釋了為什么X1.1在Agent能力上的提升特別明顯。
- 知識一致性強化:在訓練過程中,文心X1.1會不斷對比策略模型和基礎模型的知識一致性,類似“老師隨時檢查作業”,這樣能讓模型在事實性上更靠譜,減少胡編亂造的情況。
- 指令驗證器 + 檢查清單:這一點挺有意思的,就是在訓練時給模型配了一個“Checklist”和“Validator”,要求它嚴格對照檢查清單完成復雜指令。這也是為什么我測試它寫詩、寫小紅書筆記的時候,總能很好地遵循格式和要求。
- 思維鏈 + 行動鏈:以前很多模型只有“思維鏈(CoT)”,但X1.1在此基礎上加了“行動鏈”。意思就是,它不光能思考,還能把思考轉化為具體的行動,比如自主調用工具一步步解決問題。我覺得這可能也就是為什么它在Agent場景里表現很突出的原因。
整體來看,這套組合拳讓文心X1.1 不只是“會答題”,而是更像一個能動手、會規劃的“數字助手”。而從benchmark表現來看,它已經超過了DeepSeek R1-0528,整體逼近GPT-5和Gemini 2.5 Pro。在事實性、指令遵循和Agent能力三個關鍵指標上都有實打實的提升。
文心飛槳開源生態
如果說文心X1.1是百度在模型上的一次“能力躍升”,那背后的底氣其實就是飛槳和開源生態。很多人會覺得大模型的突破只靠數據和算力,但其實 框架、工具、生態 才是真正能撐起長期發展的“地基”。
首先是飛槳框架的優化,今年剛發布的飛槳 3.2 版本,說白了就是專門為大模型“提速”。比如存算重疊的稀疏注意力計算(FlashMask V3)、高效的FP8混合精度訓練、顯存友好的流水線并行調度,還有大規模集群的容錯系統。這些名字聽上去很硬核,但核心就是——讓大模型訓練更快、更穩、更省。X1.1 之所以能保持高性能和低成本,背后就是飛槳在“算力-框架-模型”的深度協同。
在推理和部署方面,飛槳這次配套了 FastDeploy v2.2,支持極致壓縮、稀疏注意力、多步投機解碼等一系列黑科技。官方的數據是,在 300B 級別的模型上,輸入吞吐能到 57K,輸出吞吐 29K,延遲控制在 50ms 以內。這意味著什么?就是超大模型不再是只能“實驗室里跑一跑”,而是真能部署到產業級場景里。
更關鍵的是開源。百度今年6月已經完全開源了文心4.5系列10款模型,包括47B、3B的MoE模型和0.3B的稠密模型,連權重和推理代碼都放出來了。甚至這次大會還追加開源了一個專門的思考模型 ERNIE-4.5-21B-Thinking。相比X1.1,它速度更快,適合做研究和二次開發。對我們開發者來說,這種“雙層開源”(模型+框架)很有價值,也正是百度生態的一個亮點。而且這些開源不是“半遮半掩”,預訓練權重、推理代碼全開放,還遵循Apache 2.0協議,開發者可以自由修改、商用。
為了降低門檻,百度還提供了完整的工具鏈:飛槳框架做底層,ERNIEKit專門針對文心4.5,甚至給出了“4張GPU訓練300B模型”的方案。這樣一來,中小開發者也能玩得起。現在文心飛槳生態里已經聚集了2333萬開發者、76萬家企業,在上海、武漢等產業賦能中心,已經能看到開源技術落地成真正的AI應用。
百度全棧AI架構
最后不得不提百度的全棧布局。真正能做到“芯片-框架-模型-應用”閉環的公司全球屈指可數,百度算是少數早早布局的人工智能公司之一:
- 芯片層:有自研的昆侖芯,算是百度在底層算力上的自主保障。
- 框架層:飛槳已經成了中國自主研發的最主流的深度學習框架,支撐了文心系列的訓練和推理。
- 模型層:文心大模型本身就是核心成果,從最早的1.0到現在的X1.1,逐步把語言、多模態、深度思考、Agent能力都補齊。
- 應用層:百度系的應用落地很多,從搜索、地圖、辦公,到慧播星數字人,都可以基于大模型能力去賦能。
這種全棧自研,不只是“技術自洽”,不讓卡脖子,更是成本與效率優勢。X1.1之所以能在性能提升的同時價格更低,本質就是得益于這種全棧協同:芯片算得更快、框架更省資源、模型更高效,最后推出來的產品自然就能更有性價比。
總結
整體看下來,文心X1.1給我的感覺是:它不再只是一個“能答題的大模型”,而是真正往Agent時代邁進了一步。事實性更穩,指令遵循更準,Agent和工具調用能力也更成熟,這些能力疊加起來,讓它已經不只是一個語言模型,而是一個能思考、會執行的數字助手。并且對于百度來說,基于自身的全棧架構,帶來的不只是性能的提升,更是成本和效率上的優勢,讓X1.1可以在效果和價格之間找到平衡。
從現有的大模型發展的來看,Agent時代中,智能體和工具調用能力將會越來越重要,文心X1.1不僅是百度的“新深度思考”答卷,也是一種信號,下一階段,可能不僅是模型能力的比拼,更是Agent落地的比拼。
)


![[工作表控件19] 驗證規則實戰:如何用正則表達式規范業務輸入?](http://pic.xiahunao.cn/[工作表控件19] 驗證規則實戰:如何用正則表達式規范業務輸入?)

)




——使用FastRTC+Gemini創建沉浸式音頻+視頻的藝術評論家)


——1 概述)



)

