一、術語與寬窄依賴
1、術語解釋
1、Master(standalone):資源管理的主節點(進程)
2、Cluster Manager:在集群上獲取資源的外部服務(例如:standalone,Mesos,Yarn)
3、Worker Node(standalone):資源管理的從節點(進程)或者說管理本機資源的進程
4、Driver Program:用于連接工作進程(Worker)的程序
5、Executor:是一個worker進程所管理的節點上為某Application啟動的一個進程,該進程負責運行任務,并且負責將數據存在內存或者磁盤上。每個應用都有各自獨立的executors
6、Task:被送到某個executor上的工作單元
7、Job:包含很多任務(Task)的并行計算,可以看做和action對應
8、Stage:一個Job會被拆分很多組任務,每組任務被稱為Stage(就像Mapreduce分map task和reduce task一樣)
2、窄依賴和寬依賴
RDD之間有一系列的依賴關系,依賴關系又分為窄依賴和寬依賴。
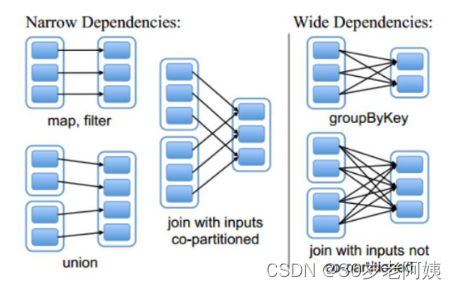
窄依賴
父RDD和子RDD partition之間的關系是一對一的。或者父RDD一個partition只對應一個子RDD的partition情況下的父RDD和子RDD partition關系是多對一的。不會有shuffle的產生。
寬依賴
父RDD與子RDD partition之間的關系是一對多。會有shuffle的產生。
寬窄依賴圖理解:
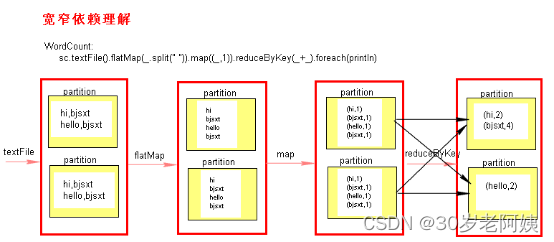
二、Stage的計算模式
Spark任務會根據RDD之間的依賴關系,形成一個DAG有向無環圖,DAG會提交給DAGScheduler,DAGScheduler會把DAG劃分相互依賴的多個stage,劃分stage的依據就是RDD之間的寬窄依賴。遇到寬依賴就劃分stage,每個stage包含一個或多個task任務。然后將這些task以taskSet的形式提交給TaskScheduler運行。stage是由一組并行的task組成。
stage切割規則:
切割規則:從后往前,遇到寬依賴就切割stage。
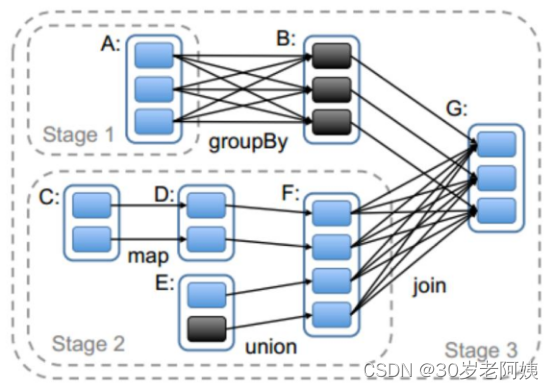
stage計算模式:
pipeline管道計算模式,pipeline只是一種計算思想,模式。
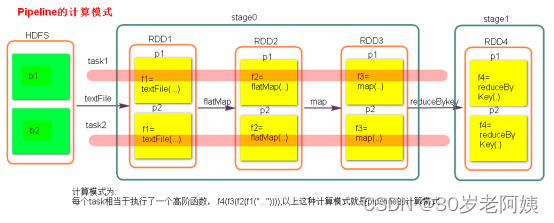
1、數據一直在管道里面什么時候數據會落地?
- 對RDD進行持久化。
- shuffle write的時候。
2、Stage的task并行度是由stage的最后一個RDD的分區數來決定的 。
3、如何改變RDD的分區數?
例如:reduceByKey(XXX,3),GroupByKey(4)
4、測試驗證pipeline計算模式
1.val conf = new SparkConf()
2.conf.setMaster("local").setAppName("pipeline");
3.val sc = new SparkContext(conf)
4.val rdd = sc.parallelize(Array(1,2,3,4))
5.val rdd1 = rdd.map { x => {
6. println("map--------"+x)
7. x
8.}}
9.val rdd2 = rdd1.filter { x => {
10. println("fliter********"+x)
11. true
12.} }
13.rdd2.collect()
14.sc.stop()三、Spark資源調度和任務調度
-
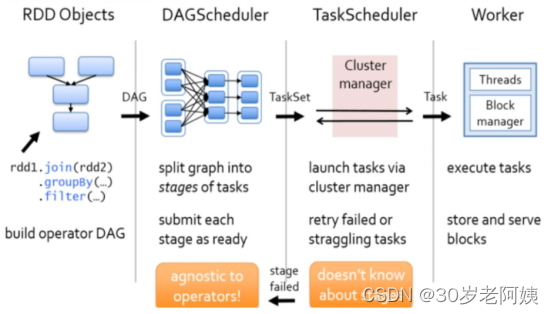
Spark資源調度和任務調度的流程:
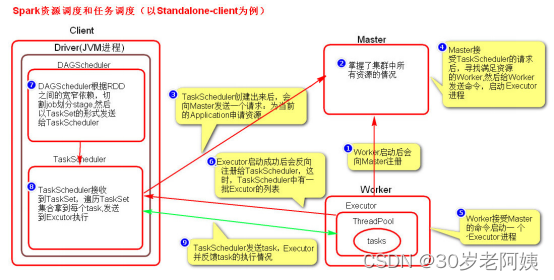
啟動集群后,Worker節點會向Master節點匯報資源情況,Master掌握了集群資源情況。當Spark提交一個Application后,根據RDD之間的依賴關系將Application形成一個DAG有向無環圖。任務提交后,Spark會在Driver端創建兩個對象:DAGScheduler和TaskScheduler,DAGScheduler是任務調度的高層調度器,是一個對象。DAGScheduler的主要作用就是將DAG根據RDD之間的寬窄依賴關系劃分為一個個的Stage,然后將這些Stage以TaskSet的形式提交給TaskScheduler(TaskScheduler是任務調度的低層調度器,這里TaskSet其實就是一個集合,里面封裝的就是一個個的task任務,也就是stage中的并行度task任務),TaskSchedule會遍歷TaskSet集合,拿到每個task后會將task發送到計算節點Executor中去執行(其實就是發送到Executor中的線程池ThreadPool去執行)。task在Executor線程池中的運行情況會向TaskScheduler反饋,當task執行失敗時,則由TaskScheduler負責重試,將task重新發送給Executor去執行,默認重試3次。如果重試3次依然失敗,那么這個task所在的stage就失敗了。stage失敗了則由DAGScheduler來負責重試,重新發送TaskSet到TaskSchdeuler,Stage默認重試4次。如果重試4次以后依然失敗,那么這個job就失敗了。job失敗了,Application就失敗了。
TaskScheduler不僅能重試失敗的task,還會重試straggling(落后,緩慢)task(也就是執行速度比其他task慢太多的task)。如果有運行緩慢的task那么TaskScheduler會啟動一個新的task來與這個運行緩慢的task執行相同的處理邏輯。兩個task哪個先執行完,就以哪個task的執行結果為準。這就是Spark的推測執行機制。在Spark中推測執行默認是關閉的。推測執行可以通過spark.speculation屬性來配置。
注意:
- 對于ETL類型要入數據庫的業務要關閉推測執行機制,這樣就不會有重復的數據入庫。
- 如果遇到數據傾斜的情況,開啟推測執行則有可能導致一直會有task重新啟動處理相同的邏輯,任務可能一直處于處理不完的狀態。
2、圖解Spark資源調度和任務調度的流程
3、粗粒度資源申請和細粒度資源申請
- 粗粒度資源申請(Spark)
在Application執行之前,將所有的資源申請完畢,當資源申請成功后,才會進行任務的調度,當所有的task執行完成后,才會釋放這部分資源。
優點:在Application執行之前,所有的資源都申請完畢,每一個task直接使用資源就可以了,不需要task在執行前自己去申請資源,task啟動就快了,task執行快了,stage執行就快了,job就快了,application執行就快了。
缺點:直到最后一個task執行完成才會釋放資源,集群的資源無法充分利用。
- 細粒度資源申請(MapReduce)
Application執行之前不需要先去申請資源,而是直接執行,讓job中的每一個task在執行前自己去申請資源,task執行完成就釋放資源。
優點:集群的資源可以充分利用。
缺點:task自己去申請資源,task啟動變慢,Application的運行就相應的變慢了。



















