散列表
完整可編譯運行代碼:Github:Data-Structures-Algorithms-and-Applications/_22hash/
定義
字典的另一種表示方法是散列(hashing)。它用一個散列函數(也稱哈希函數)把字典的數對映射到一個散列表(也稱哈希表)的具體位置。如果數對p的關鍵字是k,散列函數為f,那么在理想情況下,p 在散列表中的位置為f(k)。暫時假定散列表的每一個位置最多能夠存儲一個記錄。為了搜索關鍵字為 k 的數對,先要計算f(k),然后查看在散列表的f(k)處是否已有一個數對。如果有,便找到了該數對。如果沒有,字典就不包含該數對。在前一種情況下,可以刪除該數對,為此只需使散列表的f(k)位置為空。在后一種情況下,可以把該數對插在f(k)的位置。
初始化一個空字典需要的時間為 O(b)(b 為散列表擁有的位置數),查找、插入、刪除操作的時間均為0(1)。
散列函數和散列表
桶和起始桶
當關鍵字的范圍太大,不能用理想方法表示時,可以采用并不理想的散列表和散列函數:散列表位置的數量比關鍵字的個數少,散列函數把若干個不同的關鍵字映射到散列表的同一個位置。散列表的每一個位置叫一個桶(bucket);對關鍵字為 k的數對,f(k)是起始桶(home bucket);桶的數量等于散列表的長度或大小。因為散列函數可以把若干個關鍵字映射到同一個桶,所以桶要能夠容納多個數對。本章我們考慮兩種極端情況。第一種情況是每一個桶只能存儲一個數對。第二種情況是每一個桶都是一個可以容納全部數對的線性表。
除法散列函數
f ( k ) = k % D ( 10 ? 2 ) f(k)=k\%D (10-2) f(k)=k%D(10?2)
其中 k 是關鍵字,D 是散列表的長度(即桶的數量),%為求模操作符。散列表的位置索引從0到D-1。當D=11時,與關鍵字3、22、27、40、80和96分別對應的起始桶是f(3)=3,f(22)=0,f(27)=5,f(40)=7,f(80)=3 和f(96)=8。
沖突和溢出
散列表有 11 個桶,序號從 0 到 10,而且每一個桶可以存儲一個數對。除數D為11。因為80%11=3,則 80 的位置為3,40的位置為40%11=7,65的位置為65%11=10。每個數對都在相應的起始桶中。散列表余下的桶為空。
現在假設要插入 58。58 的起始桶為f(58)=58%11=3。這個桶已被另一個關鍵字占用。這時就發生了沖突。**當兩個不同的關鍵字所對應的起始桶相同時,就是沖突(collision)發生了。**因為一個桶可以存儲多個數對,因此發生碰撞也沒什么了不起。只要起始桶足夠大,所有對應同一個起始桶的數對都可存儲在一起。如果存儲桶沒有空間存儲一個新數對,就是溢出(overflow)發生了。
我需要一個好的散列函數
當映射到散列表中任何一個桶里的關鍵字數量大致相等時,沖突和溢出的平均數最少。**均勻散列函數(uniform hash function)**便是這樣的函數。
在實際應用中,關鍵字不是從關鍵字范圍內均勻選擇的,因此有的均勻散列函數表現好一點,有一些就差一些。那些在實際應用中性能表現好的均勻散列函數被稱為良好散列函數(good hash function)。
對于除法散列函數,假設 D 是偶數。當 k是偶數時,f(k)是偶數;當k 是奇數時,f(k)是奇數。例如 k%20,當k是偶數時為偶數,當k是奇數時為奇數。如果你的應用以偶數關鍵字為主,那么大部分關鍵字都被映射到序號為偶數的起始桶里。如果你的應用以奇數關鍵字為主,那么大部分關鍵字都被映射到序號為奇數的起始桶里。因此,選擇D為偶數,得到的是不良散列函數。
當 D 可以被諸如 3、5 和 7 這樣的小奇數整除時,不會產生良好散列函數。因此,要使除法散列函數成為良好散列函數,你要選擇的除數D應該既不是偶數又不能被小的奇數整除。理想的D是一個素數。當你不能用心算找到一個接近散列表長度的素數時,你應該選擇不能被2和19之間的數整除的D。
因為在實際應用的字典中,關鍵字是相互關聯的,所以你所選擇的均勻散列函數,其值應該依賴關鍵字的所有位(而不是僅僅取決于前幾位,或后幾位,或中間幾位)。當D既是素數又不能被小于20的數整除,就能得到良好散列函數。
除法和非整型關鍵字
為使用除法散列函數,在計算f(k)之前,需要把關鍵字轉換為非負整數。
需要將串數據、結構和算法轉換為整數。
沖突和溢出的解決方案
線性探查
- 插入元素
散列表有 11 個桶,序號從 0 到 10,而且每一個桶可以存儲一個數對。除數D為11。因為80%11=3,則 80 的位置為3,40的位置為40%11=7,65的位置為65%11=10。每個數對都在相應的起始桶中。散列表余下的桶為空。
現在假設要插入 58。58 的起始桶為f(58)=58%11=3。這個桶已被另一個關鍵字占用。這時就發生了沖突。
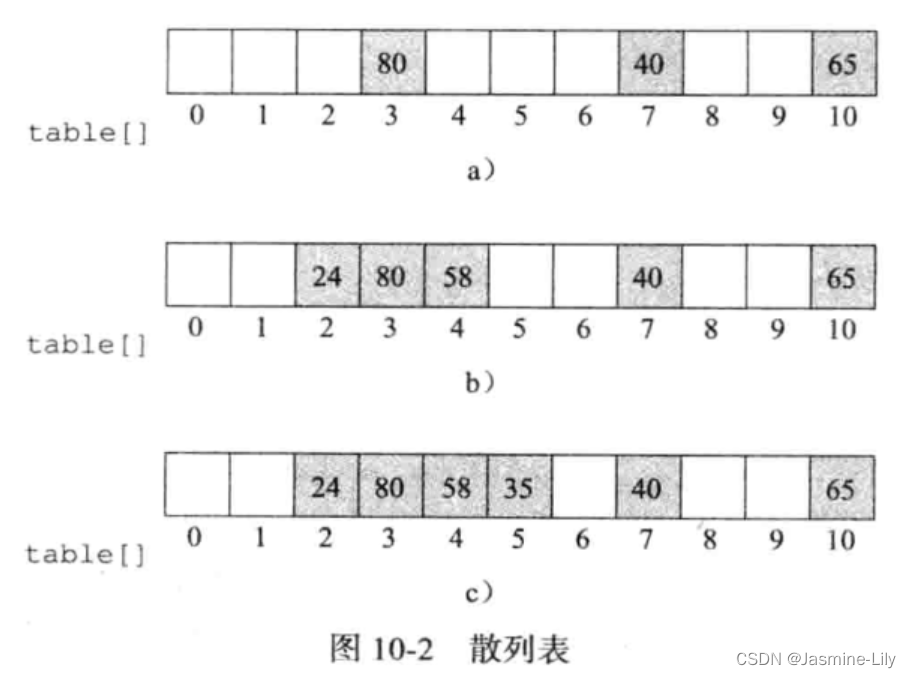
要在圖 10-2a 的散列表中把 58放進去,最簡單方法是找到下一個可用的桶。這種解決溢出的方法叫作線性探查(Linear Probing)。
58 因此被存儲在 4 號桶。假設下一個要插入的數對關鍵字為 24,24%11=2,2 號桶為空,于是把24放入2號桶。這時的散列表如圖 10-2b所示。現在要插入35。35的起始桶2已滿。用線性探查,結果如圖 10-2c 所示。最后一例,插入 98。它的起始桶 10已滿,而下一個可用桶是 0 號桶,于是 98 被插入在此。由此看來,在尋找下一個可用桶時,散列表被視為環形表。
- 查找元素
假設要查找關鍵字為k的數對,首先搜索起始桶f(k),然后把散列表當做環表繼續搜索下一個桶,直到以下情況之一發生為止:
1)存有關鍵字 k 的桶已找到,即找到了要查找的數對;
2)到達一個空桶;
3)又回到起始桶f(k)。
后兩種情況說明關鍵字為k的數對不存在。
- 刪除一個元素
刪除一個記錄要保證上述的搜索過程可以正常進行。若在圖 10-2c 中刪除了關鍵字 58,不能僅僅把4號桶置為空,否則就無法找到關鍵字為35的數對。刪除需要移動若干個數對。從刪除位置的下一個桶開始,逐個檢查每個桶,以確定要移動的元素,直至到達一個空桶或回到刪除位置為止。在做刪除移動時,一定要注意,不要把一個數對移到它的起始桶之前,否則,對這個數對的查找就可能失敗。
實現刪除的另一個策略是為每個桶增加一個域 neverUsed。在散列表初始化時,這個域被置為true。當一個數對存入一個桶中時,neverUsed域被置為false。現在,搜索的結束條件2)變成:桶的 neverUsed域為 true。不過在刪除時,只是把表的相應位置置為空。一個新元素被插入在其對應的起始桶之后所找到的第一個空桶中。注意,在這種方案中,neverUsed不會重新置為true。用不了多長時間,所有(或幾乎所有)桶的neverUsed域都等于false,這時搜索是否失敗,只有檢查所有的桶之后才可以確定。為了提高性能,當很多空桶的neverUsed域等于false時,必須重新組織這個散列表。例如,可把所有余下的數對都插到一個空的散列表中。這種方案不太可行
- 性能分析
我們只分析時間復雜度。設b為散列表的桶數,D為散列函數的除數,且b=D。散列表初始化的時間為0(b)。當表中有n個記錄時,最壞情況下的插入和查找時間均為0(n)。當所有關鍵字都對應同一個起始桶時,便是最壞情況。把字典的散列在最壞情況下的復雜度與線性表在最壞情況下的復雜度相比較,二者完全相同。
然而,就平均性能而言,散列遠遠優于線性表。令 U n U_n Un?,和 S n S_n Sn?,分別表示在一次成功搜索和不成功搜索中平均搜索的桶數,其中 n是很大的值。這個平均值是由插入的 n個關鍵字計算得來的。對于線性探查,有如下近似公式:
U n ≈ 1 2 ( 1 + 1 ( 1 ? α ) 2 ) ( 10 ? 3 ) U_n\approx\frac{1}{2}\left(1 + \frac{1}{(1-\alpha)^2}\right)(10-3) Un?≈21?(1+(1?α)21?)(10?3)
S n ≈ 1 2 ( 1 + 1 1 ? α ) ( 10 ? 4 ) S_n\approx\frac{1}{2}\left(1 + \frac{1}{1-\alpha}\right)(10-4) Sn?≈21?(1+1?α1?)(10?4)
其中 α \alpha α=n/b為負載因子(loading factor)。
從上述公式可以證明,當 α \alpha α=0.5時,一次不成功的搜索將平均查找2.5 個桶,一次成功的搜索將平均查找 1.5 個桶。當 α \alpha α=0.9時,這些數字分別為 50.5 和 5.5。當然,這時假定 n 比 51 大得多。當負載因子比較小時,使用線性探查,散列的平均性能比線性表的平均性能要優越許多。一般情況下都是 α \alpha α<0.75。可以根據 α \alpha α和n的值確定b的值,從什么樣的 α \alpha α能接受上考慮。
隨機探查分析
用隨機數生成器產生一個桶的搜索序列,然后用這個序列去確定插入位置。
理 10-1 設p 是某一事件發生的概率。為了該事件發生,獨立試驗的期望次數是 1/p。
U n U_n Un?,公式按如下方式導出:當裝載因子是a時,一個桶有數對的概率是a,沒有數對的概率為 p=1-a。在隨機探查中,使用一個獨立試驗序列進行搜索,一次失敗的搜索是找到一個空桶,為此,我們期望搜索的桶數是:
U n ≈ a p = 1 1 ? α ( 10 ? 5 ) U_n\approx\frac{a}{p}=\frac{1}{1-\alpha}(10-5) Un?≈pa?=1?α1?(10?5)
S n S_n Sn?,公式可以從 U n U_n Un?公式推導出來。按照插入順序,給散列表的 n個記錄編號為1,2,…,n。當插入第i個數對時,首先通過一次不成功的搜索找到一個空桶,然后把該數對插到這個空桶里。在插入第i個數對時,裝載因子是(i-1)/b,其中b是桶數。從公式(10-5)得出,在搜索第i個桶時,查看的期望桶數是:
a 1 ? i ? 1 b \frac{a}{1-\frac{i-1}{b}} 1?bi?1?a?
假設每一個數對搜索的概率是相等的,由此可得:
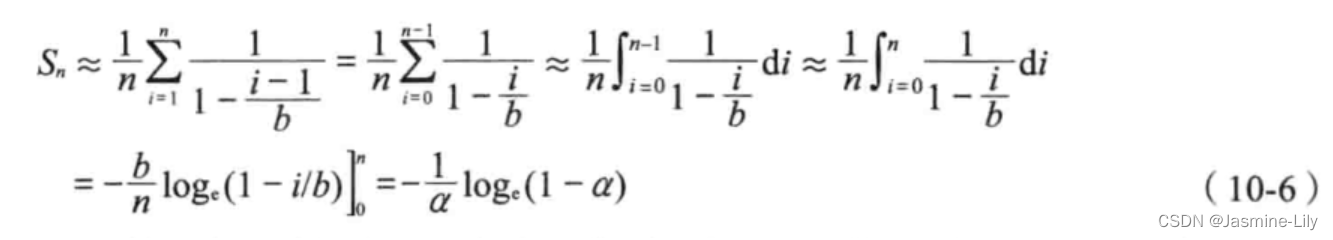
就需要查看的桶數而言,線性探查的性能不如隨機探查。例如,當a=0.9時,使用線性探查進行一次不成功的搜索而期望查看的桶數是50.5,而用隨機探查時,這個數降到10。
為什么不使用隨機探查?
- 真正影響運行時間的不是要查看的桶數。計算一個隨機數比查看若干個桶更需要時間。
- 隨機探查是用隨機方式搜索散列表,高速緩存使運行時間增大。因此,盡管隨機探查需要查看的桶數要比線性探查少,但是它實際使用的時間很多,除非裝載因子接近1。
鏈式散列
如果散列表的每一個桶可以容納無限多個記錄,那么溢出問題就不存在了。實現這個目標的一個方法是給散列表的每一個位置配置一個線性表。這時,每一個數對可以存儲在它的起始桶線性表中。
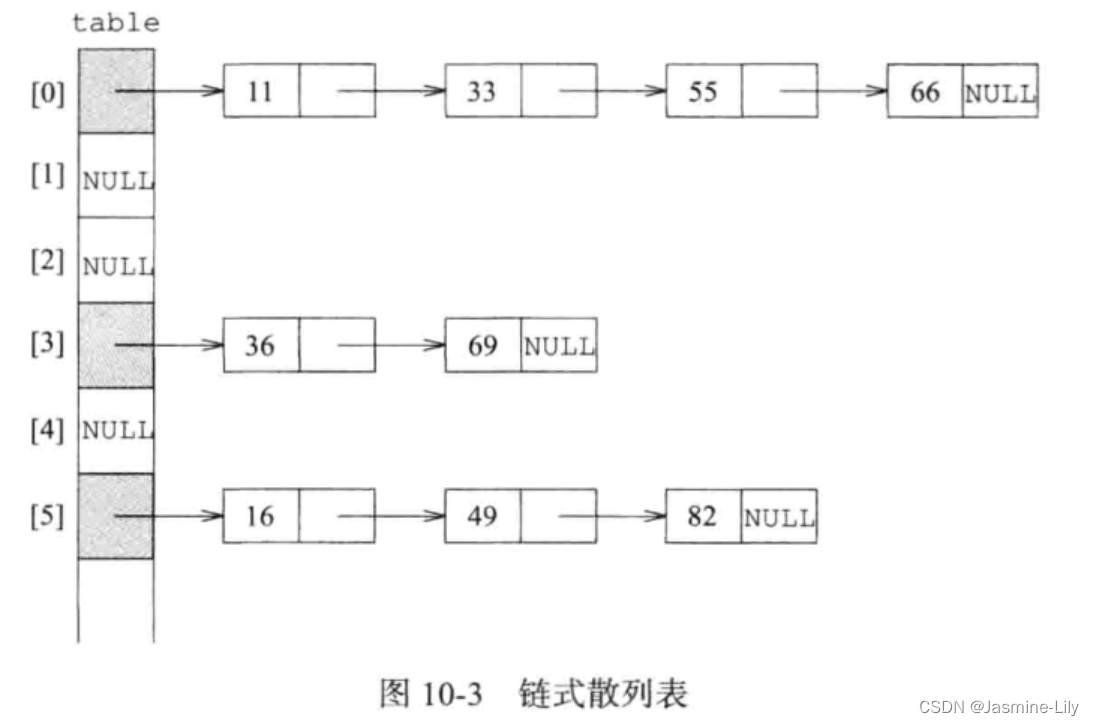
為搜索關鍵字值為 k的記錄,首先計算其起始桶,k%D,然后搜索該桶所對應的鏈表。為插入一個記錄,首先要保證散列表沒有一個記錄與該記錄的關鍵字相同,為此而進行的搜索僅限于該記錄的起始桶所對應的鏈表。要刪除一個關鍵字為k的記錄,我們要搜索它所對應的起始桶鏈表,找到該記錄,然后刪除。
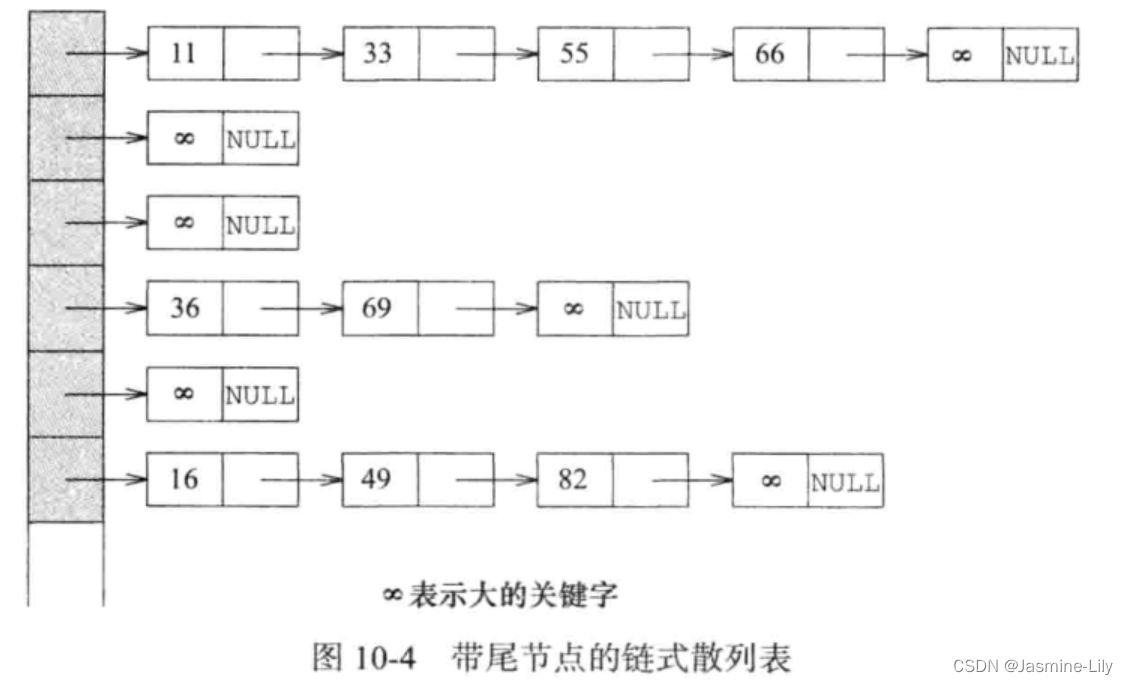
在圖 10-4的每個鏈表上增加一個尾節點,可以改進一些程序的性能。尾節點的關鍵字值最起碼要比插入的所有數對的關鍵字都大。在圖10-4中,尾節點的關鍵字用正無窮來表示。在實際應用中,當關鍵字為整數時,可以用limits.h文件中定義的INT_MAX常量來替代。有了尾節點,就可以省去在sortedChain的方法中出現的大部分對空指針的檢驗操作。注意,在圖 10-4 中,每個鏈表都有不同的尾節點,而實際上,所有鏈表可共用一個尾節點。
鏈式散列與線性探查相比:
線性探查占用的空間小于鏈式散列的空間,因為鏈式散列需要存儲一些指針。
使用鏈表時要檢查的節點數比使用線性和隨機探查時要檢查的桶數少。(詳細證明見《數據結構、算法與應用C++語言描述》原書第二版鏈式散列介紹中 與線性探查比較 公式詳細介紹)
鏈式散列與跳表相比:
通過使用隨機過程,跳表和散列操作的平均復雜度分別是對數級和常數級。跳表方法的最壞時間復雜度為O(n+maxLevel),而散列的最壞時間復雜度為O(n)。跳表中指針平均占用的空間約為maxLevel+n/(1-p);最壞情況需要maxLevel*(n+1)個指針空間。就最壞情況下的空間需求而言,跳表遠遠大于鏈式散列。鏈式散列需要的指針空間為D+n。
不過,跳表比散列更靈活。例如,只需簡單地沿著 0 級鏈就可以在線性時間內按關鍵字升序輸出所有的元素。使用鏈式散列時,需要O(D)時間去搜索最多D個非空鏈表,另外需要O(nlogD)時間把有序鏈表按關鍵字升序合并。合并過程如下:
1)把鏈表放到一個隊列中;
2)從隊列中提取一對鏈表,把它們合并為一個有序鏈表,然后放入隊列;
3)重復步驟2),直至隊列中僅剩一個鏈表。其他的操作,如查找或刪除其關鍵字最大或最小的數對,使用散列也要花費更多的時間(僅考慮平均復雜度)。
代碼測試
main.cpp
/*
Project name : allAlgorithmsTest
Last modified Date: 2022年8月13日17點38分
Last Version: V1.0
Descriptions: main()函數,控制運行所有的測試函數
*/
#include <iostream>
#include "_25hashTable.h"
#include "_26hashChains.h"int main()
{hashTableTest();hashChainsTest();return 0;
}
_25hash.h
/*
Project name : allAlgorithmsTest
Last modified Date: 2022年8月23日10點18分
Last Version: V1.0
Descriptions: 哈希---散列函數(將type K轉換為非負整數)
// functions to convert from type K to nonnegative integer
// derived from similar classes in SGI STL
*/
#pragma once
#ifndef _HASH_H_
#define _HASH_H_
#include <iostream>
#include <string>
using namespace std;
/*之前名稱時hash,實例化hash一直報錯,然后我就各種找原因*/
/*后來發現原因可能是 C++STL源文件定義了hash類,所以我后面定義的模板就不作數,所以一直報錯*/
/*因此解決方案就是:將類名稱hash改為hashNode*/
template <class K>
class hashNode
{
public:size_t operator()(const int theKey) const{return size_t(theKey);}
};/*這是一個實例化*/
template<>
class hashNode<string>
{
public:size_t operator()(const string theKey) const{// Convert theKey to a nonnegative integer.unsigned long hashNodeValue = 0;int length = (int)theKey.length();for (int i = 0; i < length; i++)hashNodeValue = 5 * hashNodeValue + theKey.at(i);return size_t(hashNodeValue);}
};
/*這是一個實例化*/
template<>
class hashNode<int>
{
public:size_t operator()(const int theKey) const{return size_t(theKey);}
};
/*這是一個實例化*/
template<>
class hashNode<long>
{
public:size_t operator()(const long theKey) const{return size_t(theKey);}
};#endif
_25hashTable.h
/*
Project name : allAlgorithmsTest
Last modified Date: 2022年8月23日10點18分
Last Version: V1.0
Descriptions: 哈希表(數組存儲)---使用線性探查的頭文件---是無序的
// hash table using linear open addressing and division
// implements dictionary methods other than erase
*/
#pragma once
#ifndef _HASHTABLE_H_
#define _HASHTABLE_H_
#include <iostream>
#include "_1myExceptions.h"
#include "_25hash.h" // mapping functions from K to nonnegative integer
using namespace std;
/*測試函數*/
void hashTableTest();template<class K, class E>
class hashTable
{
public:hashTable(int theDivisor = 11);~hashTable() { delete[] table; }bool empty() const { return dSize == 0; }int size() const { return dSize; }pair<const K, E>* find(const K&) const;void insert(const pair<const K, E>&);void erase(const K theKey);/*友元函數*//*輸入字典*/istream& input(istream& in);
// friend istream& operator>> <K, E>(istream& in, hashTable<K, E>& m);/*輸出字典*/ostream& output(ostream& out) const;
// friend ostream& operator<< <K, E>(ostream& out, const hashTable<K, E>& m);protected:int search(const K&) const;pair<const K, E>** table; // hash tablehashNode<K> hashNode; // maps type K to nonnegative integerint dSize; // number of pairs in dictionaryint divisor; // hash function divisor
};/*輸入字典*/
template<class K, class E>
istream& hashTable<K, E>::input(istream& in)
{int numberOfElement = 0;cout << "Please enter the number of element:";while (!(in >> numberOfElement)){in.clear();//清空標志位while (in.get() != '\n')//刪除無效的輸入continue;cout << "Please enter the number of element:";}K first;E second;for (int i = 0; i < numberOfElement; i++){cout << "Please enter the element " << i + 1 << ":";while (!(in >> first >> second)){in.clear();//清空標志位while (in.get() != '\n')//刪除無效的輸入continue;cout << "Please enter the element " << i + 1 << ":";}const pair<const K, E> element(first, second);insert(element);}return in;
}
template<class K, class E>
istream& operator>>(istream& in, hashTable<K, E>& m){m.input(in);return in;
}
/*輸出字典*/
template<class K, class E>
ostream& hashTable<K, E>::output(ostream& out) const
{for (int i = 0; i < divisor; i++)if (table[i] == nullptr)cout << "nullptr" << " ";elsecout << "(" << table[i]->first << "," << table[i]->second << ")" << " ";cout << endl;return out;
}template<class K, class E>
ostream& operator<<(ostream& out, const hashTable<K, E>& m){m.output(out);return out;
}template<class K, class E>
hashTable<K, E>::hashTable(int theDivisor)
{divisor = theDivisor;dSize = 0;// allocate and initialize hash table arraytable = new pair<const K, E>*[divisor];for (int i = 0; i < divisor; i++)table[i] = nullptr;
}template<class K, class E>
int hashTable<K, E>::search(const K& theKey) const
{// Search an open addressed hash table for a pair with key theKey.// Return location of matching pair if found, otherwise return// location where a pair with key theKey may be inserted// provided the hash table is not full.int i = (int)hashNode(theKey) % divisor; // home bucketint j = i; // start at home bucketdo{if (table[j] == nullptr || table[j]->first == theKey)return j;j = (j + 1) % divisor; // next bucket} while (j != i); // returned to home bucket?return j; // table full
}template<class K, class E>
pair<const K, E>* hashTable<K, E>::find(const K& theKey) const
{// Return pointer to matching pair.// Return nullptr if no matching pair.// search the tableint b = search(theKey);// see if a match was found at table[b]if (table[b] == nullptr || table[b]->first != theKey)return nullptr; // no matchreturn table[b]; // matching pair
}template<class K, class E>
void hashTable<K, E>::insert(const pair<const K, E>& thePair)
{// Insert thePair into the dictionary. Overwrite existing// pair, if any, with same key.// Throw hashTableFull exception in case table is full.// search the table for a matching pairint b = search(thePair.first);// check if matching pair foundif (table[b] == nullptr){// no matching pair and table not fulltable[b] = new pair<const K, E>(thePair);dSize++;}else{// check if duplicate or table fullif (table[b]->first == thePair.first){// duplicate, change table[b]->secondtable[b]->second = thePair.second;}else // table is fullthrow hashTableFull();}
}/*刪除關鍵字為theKey的元素*/
template<class K, class E>
void hashTable<K, E>::erase(const K theKey)
{int i = (int)hashNode(theKey) % divisor;int j = i;/*從起始桶開始尋找關鍵字為theKey的元素*/while (table[j] != nullptr && table[j]->first != theKey){j = (++j) % divisor;/*如果找完了所有桶都沒找到以theKey為關鍵字的數對,說明該數對不存在,拋出異常*/if (j == i)throw illegalParameterValue("The key is not exist");}if(table[j] == nullptr)throw illegalParameterValue("The key is not exist");/*能到這里說明已經找到以theKey為關鍵字的數對了*/i = j;//使用i記錄該數對的位置delete table[i];//將該數對刪除table[i] = nullptr;j++;//找到下一個數對/*將后面的數對前移*//*不是空桶不是起始桶不是原始桶*/while (table[j] != nullptr && (int)hashNode(table[j]->first) % divisor != j && j != i){table[j - 1] = table[j];//移動后面的元素j = (++j) % divisor;}
}
#endif
_25hashTable.cpp
/*
Project name : allAlgorithmsTest
Last modified Date: 2022年8月23日10點18分
Last Version: V1.0
Descriptions: 哈希表(數組存儲)---使用線性探查的cpp文件
*/
#include <iostream>
#include "_25hashTable.h"
using namespace std;void hashTableTest()
{cout << endl << "*********************************hashTableTest()函數開始**************************************" << endl;hashTable<int, int> a;//測試輸入和輸出cout << endl << "測試友元函數*******************************************" << endl;cout << "輸入輸出************************" << endl;cin >> a;cout << "hashTable a is:" << a;cout << endl << "測試成員函數*******************************************" << endl;cout << "empty()*************************" << endl;cout << "a.empty() = " << a.empty() << endl;cout << "size()**************************" << endl;cout << "a.size() = " << a.size() << endl;cout << "find()**************************" << endl;cout << "a.find(1)->second = " << a.find(1)->second << endl;cout << "insert()************************" << endl;pair<const int, int> insertData(3, 4);a.insert(insertData);cout << "hashTable a is:" << a;cout << "erase()*************************" << endl;a.erase(2);cout << "hashTable a is:" << a;cout << "*********************************hashTableTest()函數結束**************************************" << endl;
}
_23dictionary.h
/*
Project name : allAlgorithmsTest
Last modified Date: 2022年8月22日09點17分
Last Version: V1.0
Descriptions: 字典的抽象類
*/
/*
pair:介紹:是將2個數據組合成一組數據,是一個結構體,主要的兩個成員變量first和second,分別存儲兩個數據.使用:使用std命名空間引入對組std::pair
*/
#pragma once
#ifndef _DICTIONARY_H_
#define _DICTIONARY_H_
using namespace std;
template<class K,class E>
class dictionary
{
public:virtual ~dictionary() {}/*返回為true,當且僅當字典為空*/virtual bool empty() const = 0;/*返回字典中數對的數目*/virtual int size() const = 0;/*返回匹配數對的指針*/virtual pair<const K, E>* find(const K&) const = 0;/*刪除匹配的數對*/virtual void erase(const K&) = 0;/*往字典中插入一個數對*/virtual void insert(const pair<const K, E>&) = 0;
};
#endif
_23pairNode.h
/*
Project name : allAlgorithmsTest
Last modified Date: 2022年8月22日09點17分
Last Version: V1.0
Descriptions: 是字典的一個節點
*/
#pragma once
#ifndef _PAIRNODE_H_
#define _PAIRNODE_H_
using namespace std;
template <class K, class E>
struct pairNode
{typedef pair<const K, E> pairType;pairType element;pairNode<K, E>* next;pairNode(const pairType& thePair) :element(thePair) {}pairNode(const pairType& thePair, pairNode<K, E>* theNext):element(thePair) {next = theNext;}
};
#endif
_23dictionaryChain.h
/*
Project name : allAlgorithmsTest
Last modified Date: 2022年8月22日09點17分
Last Version: V1.0
Descriptions: 使用鏈表實現的字典的頭文件---是有序的
*/
#pragma once
#ifndef _DICTIONARY_CHAIN_H_
#define _DICTIONARY_CHAIN_H_
#include <iostream>
#include "_23pairNode.h"
#include "_23dictionary.h"
using namespace std;
/*測試函數*/
void dictionaryChainTest();template<class K, class E>
class dictionaryChain : public dictionary<K, E>
{
public:/*成員函數*//*構造函數和析構函數*/dictionaryChain() { firstNode = nullptr; dSize = 0; }~dictionaryChain();/*其他成員函數*/bool empty() const { return dSize == 0; }int size() const { return dSize; }pair<const K, E>* find(const K&) const;void erase(const K&);void insert(const pair<const K, E>&);/*友元函數*//*輸入字典*/istream& input(istream& in);
// friend istream& operator>> <K,E>(istream& in, dictionaryChain<K,E>& m);/*輸出字典*/ostream& output(ostream& out) const;
// friend ostream& operator<< <K,E>(ostream& out, const dictionaryChain<K,E>& m);
protected:pairNode<K, E>* firstNode; // pointer to first node in chainint dSize; // number of elements in dictionary
};/*輸入字典*/
template<class K, class E>
istream& dictionaryChain<K, E>::input(istream& in)
//istream& operator>>(istream& in, dictionaryChain<K,E>& m)
{int numberOfElement = 0;cout << "Please enter the number of element:";while (!(in >> numberOfElement)){in.clear();//清空標志位while (in.get() != '\n')//刪除無效的輸入continue;cout << "Please enter the number of element:";}pair<K, E> element;for (int i = 0; i < numberOfElement; i++){cout << "Please enter the element " << i + 1 << ":";while (!(in >> element.first >> element.second)){in.clear();//清空標志位while (in.get() != '\n')//刪除無效的輸入continue;cout << "Please enter the element " << i + 1 << ":";}insert(element);}return in;
}
template<class K, class E>
istream& operator>>(istream& in, dictionaryChain<K,E>& m){m.input(in);return in;
}
/*輸出字典*/
template<class K, class E>
ostream& dictionaryChain<K, E>::output(ostream& out) const
//ostream& operator<<(ostream& out, const dictionaryChain<K,E>& m)
{pairNode<K, E>* currentNode = firstNode;while (currentNode != nullptr){out << "(" << currentNode->element.first << " ," << currentNode->element.second << ")" << " ";currentNode = currentNode->next;}cout << endl;return out;
}
template<class K, class E>
ostream& operator<<(ostream& out, const dictionaryChain<K,E>& m){m.output(out);return out;
}
/*析構函數*/
template<class K,class E>
dictionaryChain<K,E>::~dictionaryChain()
{pairNode<K, E>* nextNode;while (firstNode != nullptr){nextNode = firstNode->next;delete firstNode;firstNode = nextNode;}
}
/*尋找關鍵字為key的數對并返回*/
template<class K, class E>
pair<const K, E>* dictionaryChain<K, E>::find(const K& key) const
{//返回匹配的數對的指針//如果不存在匹配的數對,則返回nullptrpairNode<K, E>* currentNode = firstNode;while (currentNode != nullptr && currentNode->element.first != key)currentNode = currentNode->next;if (currentNode != nullptr && currentNode->element.first == key)return ¤tNode->element;return nullptr;//如果沒找到就返回nullptr
}
/*刪除關鍵字為key的數對*/
template<class K, class E>
void dictionaryChain<K, E>::erase(const K& key)
{//刪除關鍵字為key的數對pairNode<K, E>* p = firstNode;//存儲的是插入元素之后的位置pairNode<K, E>* tp = nullptr;//存儲的是插入元素之前的位置//搜索關鍵字為key的數對while (p != nullptr && p->element.first < key){tp = p;p = p->next;}//確定是否匹配if (p != nullptr && p->element.first == key)if (tp == nullptr) firstNode = p->next;//p是第一個節點else tp->next = p->next;delete p;dSize--;
}
/*往字典中插入data,覆蓋已經存在的匹配的數對*/
template<class K,class E>
void dictionaryChain<K, E>::insert(const pair<const K, E>& data)
{pairNode<K, E>* p = firstNode;//存儲的是插入元素之后的位置pairNode<K, E>* tp = nullptr;//存儲的是插入元素之前的位置while (p != nullptr && p->element.first < data.first){tp = p;p = p->next;}//檢查是否有匹配的數對if (p != nullptr && p->element.first == data.first){p->element.second = data.second;return;}//無匹配的數對,為thePair建立新節點pairNode<K, E>* newNode = new pairNode<K, E>(data, p);//在tp之后插入新節點if (tp == nullptr) firstNode = newNode;else tp->next = newNode;dSize++;return;
}#endif
_26hashChains.h
/*
Project name : allAlgorithmsTest
Last modified Date: 2022年8月24日11點16分
Last Version: V1.0
Descriptions: 哈希表---鏈式散列(鏈表存儲)---頭文件---是無序的
// hash table using sorted chains and division
// implements all dictionary methods
*/
#pragma once
#ifndef _HASHCHAINDS_H_
#define _HASHCHAINDS_H_
#include <iostream>
#include "_23dictionary.h"
#include "_23dictionaryChain.h"
#include "_25hash.h"
using namespace std;
/*測試函數*/
void hashChainsTest();template<class K, class E>
class hashChains : public dictionary<K, E>
{
public:hashChains(int theDivisor = 11){divisor = theDivisor;dSize = 0;// allocate and initialize hash table arraytable = new dictionaryChain<K, E>[divisor];}~hashChains() { delete[] table; }bool empty() const { return dSize == 0; }int size() const { return dSize; }pair<const K, E>* find(const K& theKey) const{return table[hashNode(theKey) % divisor].find(theKey);}void insert(const pair<const K, E>& thePair){int homeBucket = (int)hashNode(thePair.first) % divisor;int homeSize = table[homeBucket].size();table[homeBucket].insert(thePair);if (table[homeBucket].size() > homeSize)dSize++;}void erase(const K& theKey){table[hashNode(theKey) % divisor].erase(theKey);}/*友元函數*//*輸入字典*/istream& input(istream& in);
// friend istream& operator>> <K, E>(istream& in, hashChains<K, E>& m);/*輸出字典*/ostream& output(ostream& out) const;
// friend ostream& operator<< <K, E>(ostream& out, const hashChains<K, E>& m);
protected:dictionaryChain<K, E>* table; // hash tablehashNode<K> hashNode; // maps type K to nonnegative integerint dSize; // number of elements in listint divisor; // hash function divisor
};/*輸入字典*/
template<class K, class E>
istream& hashChains<K, E>::input(istream& in)
{int numberOfElement = 0;cout << "Please enter the number of element:";while (!(in >> numberOfElement)){in.clear();//清空標志位while (in.get() != '\n')//刪除無效的輸入continue;cout << "Please enter the number of element:";}K first;E second;for (int i = 0; i < numberOfElement; i++){cout << "Please enter the element " << i + 1 << ":";while (!(in >> first >> second)){in.clear();//清空標志位while (in.get() != '\n')//刪除無效的輸入continue;cout << "Please enter the element " << i + 1 << ":";}const pair<const K, E> element(first, second);cout << element.first << endl;cout << element.second << endl;insert(element);}return in;
}
template<class K, class E>
istream& operator>>(istream& in, hashChains<K, E>& m){m.input(in);return in;
}
/*輸出字典*/
template<class K, class E>
ostream& hashChains<K, E>::output(ostream& out) const
{for (int i = 0; i < divisor; i++){if (table[i].size() == 0)cout << "nullptr" << endl;elsecout << table[i] << " ";}return out;
}
template<class K, class E>
ostream& operator<<(ostream& out, const hashChains<K, E>& m){m.output(out);return out;
}#endif
_26hashChains.cpp
/*
Project name : allAlgorithmsTest
Last modified Date: 2022年8月24日11點16分
Last Version: V1.0
Descriptions: 哈希表---鏈式散列(鏈表存儲)---cpp文件
// hash table using sorted chains and division
// implements all dictionary methods
*/
#include <iostream>
#include "_26hashChains.h"
using namespace std;void hashChainsTest()
{cout << endl << "*********************************hashChainsTest()函數開始*************************************" << endl;hashChains<int, int> a;//測試輸入和輸出cout << endl << "測試友元函數*******************************************" << endl;cout << "輸入輸出************************" << endl;cin >> a;cout << "hashChains a is:" << a;cout << endl << "測試成員函數*******************************************" << endl;cout << "empty()*************************" << endl;cout << "a.empty() = " << a.empty() << endl;cout << "size()**************************" << endl;cout << "a.size() = " << a.size() << endl;cout << "find()**************************" << endl;cout << "a.find(1)->second = " << a.find(1)->second << endl;cout << "insert()************************" << endl;pair<const int, int> insertData(3, 4);a.insert(insertData);cout << "hashChains a is:" << a;cout << "erase()*************************" << endl;a.erase(1);cout << "hashChains a is:" << a;cout << "*********************************hashChainsTest()函數結束*************************************" << endl;
}
_1myExceptions.h
/*
Project name : allAlgorithmsTest
Last modified Date: 2022年8月13日17點38分
Last Version: V1.0
Descriptions: 綜合各種異常
*/
#pragma once
#ifndef _MYEXCEPTIONS_H_
#define _MYEXCEPTIONS_H_
#include <string>
#include<iostream>using namespace std;// illegal parameter value
class illegalParameterValue
{
public:illegalParameterValue(string theMessage = "Illegal parameter value"){message = theMessage;}void outputMessage() {cout << message << endl;}
private:string message;
};// illegal input data
class illegalInputData
{
public:illegalInputData(string theMessage = "Illegal data input"){message = theMessage;}void outputMessage() {cout << message << endl;}
private:string message;
};// illegal index
class illegalIndex
{
public:illegalIndex(string theMessage = "Illegal index"){message = theMessage;}void outputMessage() {cout << message << endl;}
private:string message;
};// matrix index out of bounds
class matrixIndexOutOfBounds
{
public:matrixIndexOutOfBounds(string theMessage = "Matrix index out of bounds"){message = theMessage;}void outputMessage() {cout << message << endl;}
private:string message;
};// matrix size mismatch
class matrixSizeMismatch
{
public:matrixSizeMismatch(string theMessage ="The size of the two matrics doesn't match"){message = theMessage;}void outputMessage() {cout << message << endl;}
private:string message;
};// stack is empty
class stackEmpty
{
public:stackEmpty(string theMessage ="Invalid operation on empty stack"){message = theMessage;}void outputMessage() {cout << message << endl;}
private:string message;
};// queue is empty
class queueEmpty
{
public:queueEmpty(string theMessage ="Invalid operation on empty queue"){message = theMessage;}void outputMessage() {cout << message << endl;}
private:string message;
};// hash table is full
class hashTableFull
{
public:hashTableFull(string theMessage ="The hash table is full"){message = theMessage;}void outputMessage() {cout << message << endl;}
private:string message;
};// edge weight undefined
class undefinedEdgeWeight
{
public:undefinedEdgeWeight(string theMessage ="No edge weights defined"){message = theMessage;}void outputMessage() {cout << message << endl;}
private:string message;
};// method undefined
class undefinedMethod
{
public:undefinedMethod(string theMessage ="This method is undefined"){message = theMessage;}void outputMessage() {cout << message << endl;}
private:string message;
};
#endif
運行結果
"C:\Users\15495\Documents\Jasmine\prj\_Algorithm\Data Structures, Algorithms and Applications in C++\_22hash\cmake-build-debug\_22hash.exe"*********************************hashTableTest()函數開始**************************************測試友元函數*******************************************
輸入輸出************************
Please enter the number of element:3
Please enter the element 1:1 2
Please enter the element 2:2 4
Please enter the element 3:5 6
hashTable a is:nullptr (1,2) (2,4) nullptr nullptr (5,6) nullptr nullptr nullptr nullptr nullptr 測試成員函數*******************************************
empty()*************************
a.empty() = 0
size()**************************
a.size() = 3
find()**************************
a.find(1)->second = 2
insert()************************
hashTable a is:nullptr (1,2) (2,4) (3,4) nullptr (5,6) nullptr nullptr nullptr nullptr nullptr
erase()*************************
hashTable a is:nullptr (1,2) nullptr (3,4) nullptr (5,6) nullptr nullptr nullptr nullptr nullptr
*********************************hashTableTest()函數結束***********************************************************************hashChainsTest()函數開始*************************************測試友元函數*******************************************
輸入輸出************************
Please enter the number of element:3
Please enter the element 1:1 2
1
2
Please enter the element 2:3 5
3
5
Please enter the element 3:6 9
6
9
hashChains a is:nullptr
(1 ,2)nullptr
(3 ,5)nullptr
nullptr
(6 ,9)nullptr
nullptr
nullptr
nullptr測試成員函數*******************************************
empty()*************************
a.empty() = 0
size()**************************
a.size() = 3
find()**************************
a.find(1)->second = 2
insert()************************
hashChains a is:nullptr
(1 ,2)nullptr
(3 ,4)nullptr
nullptr
(6 ,9)nullptr
nullptr
nullptr
nullptr
erase()*************************
hashChains a is:nullptr
nullptr
nullptr
(3 ,4)nullptr
nullptr
(6 ,9)nullptr
nullptr
nullptr
nullptr
*********************************hashChainsTest()函數結束*************************************Process finished with exit code 0

)





)
![[chroot+seccomp逃逸] THUCTF2019 之 固若金湯](http://pic.xiahunao.cn/[chroot+seccomp逃逸] THUCTF2019 之 固若金湯)
】)






)


)