1 K8S 簡介
K8S是Kubernetes的簡稱,是一個開源的容器編排平臺,用于自動部署、擴展和管理“容器化(containerized)應用程序”的系統。它可以跨多個主機聚集在一起,控制和自動化應用的部署與更新。
K8S 架構
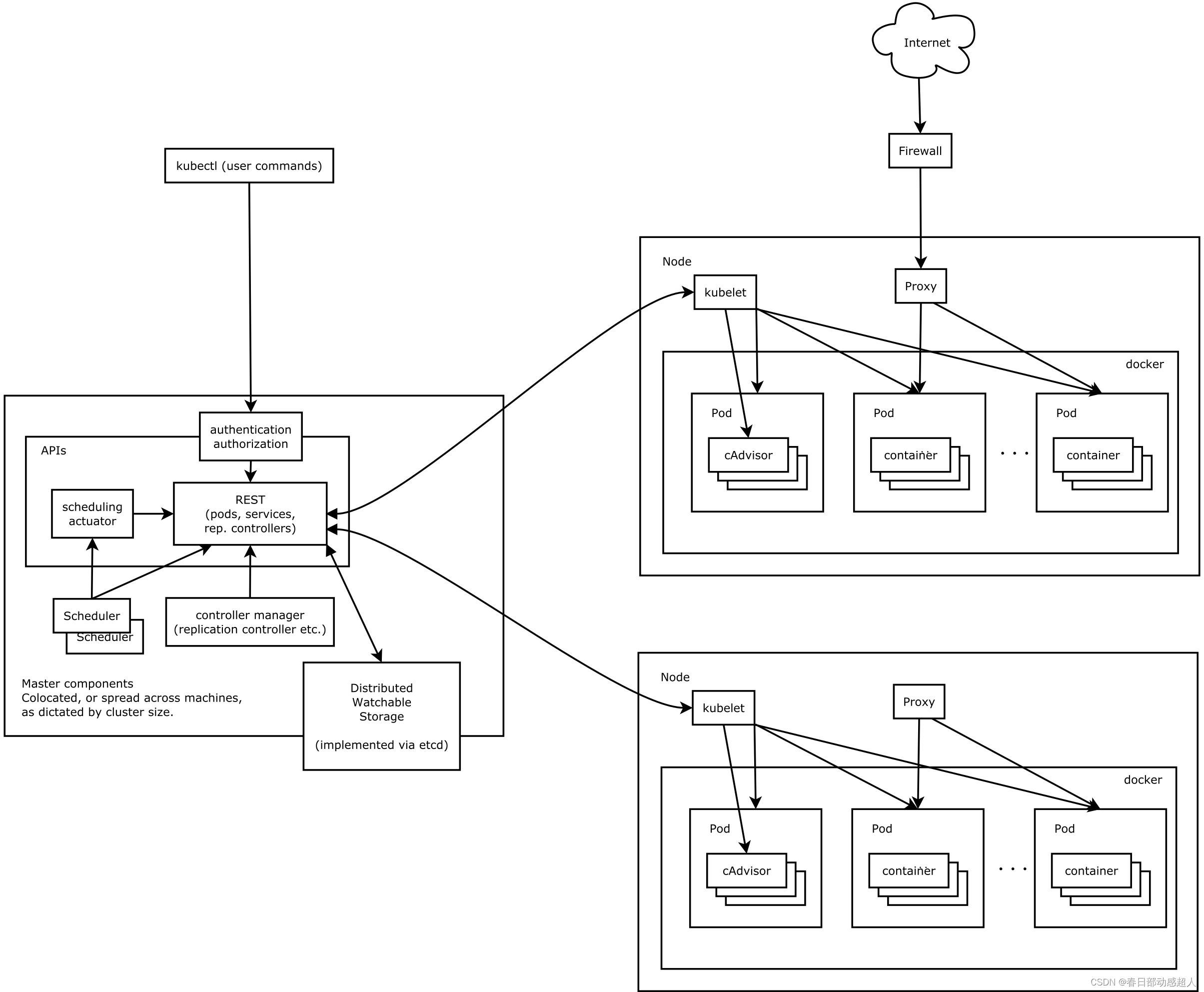
Kubernetes 主要由以下幾個核心組件組成:
- etcd 保存了整個集群的狀態;
- apiserver 提供了資源操作的唯一入口,并提供認證、授權、訪問控制、API 注冊和發現等機制;
- controller manager 負責維護集群的狀態,比如故障檢測、自動擴展、滾動更新等;
- scheduler 負責資源的調度,按照預定的調度策略將 Pod 調度到相應的機器上;
- kubelet 負責維護容器的生命周期,同時也負責 Volume(CSI)和網絡(CNI)的管理;
- Container runtime 負責鏡像管理以及 Pod 和容器的真正運行(CRI);
- kube-proxy 負責為 Service 提供 cluster 內部的服務發現和負載均衡;
除了核心組件,還有一些推薦的插件,其中有的已經成為 CNCF 中的托管項目:
-
CoreDNS 負責為整個集群提供 DNS 服務
-
Ingress Controller 為服務提供外網入口
-
Prometheus 提供資源監控
-
Dashboard 提供 GUI
-
Federation 提供跨可用區的集群
整體架構
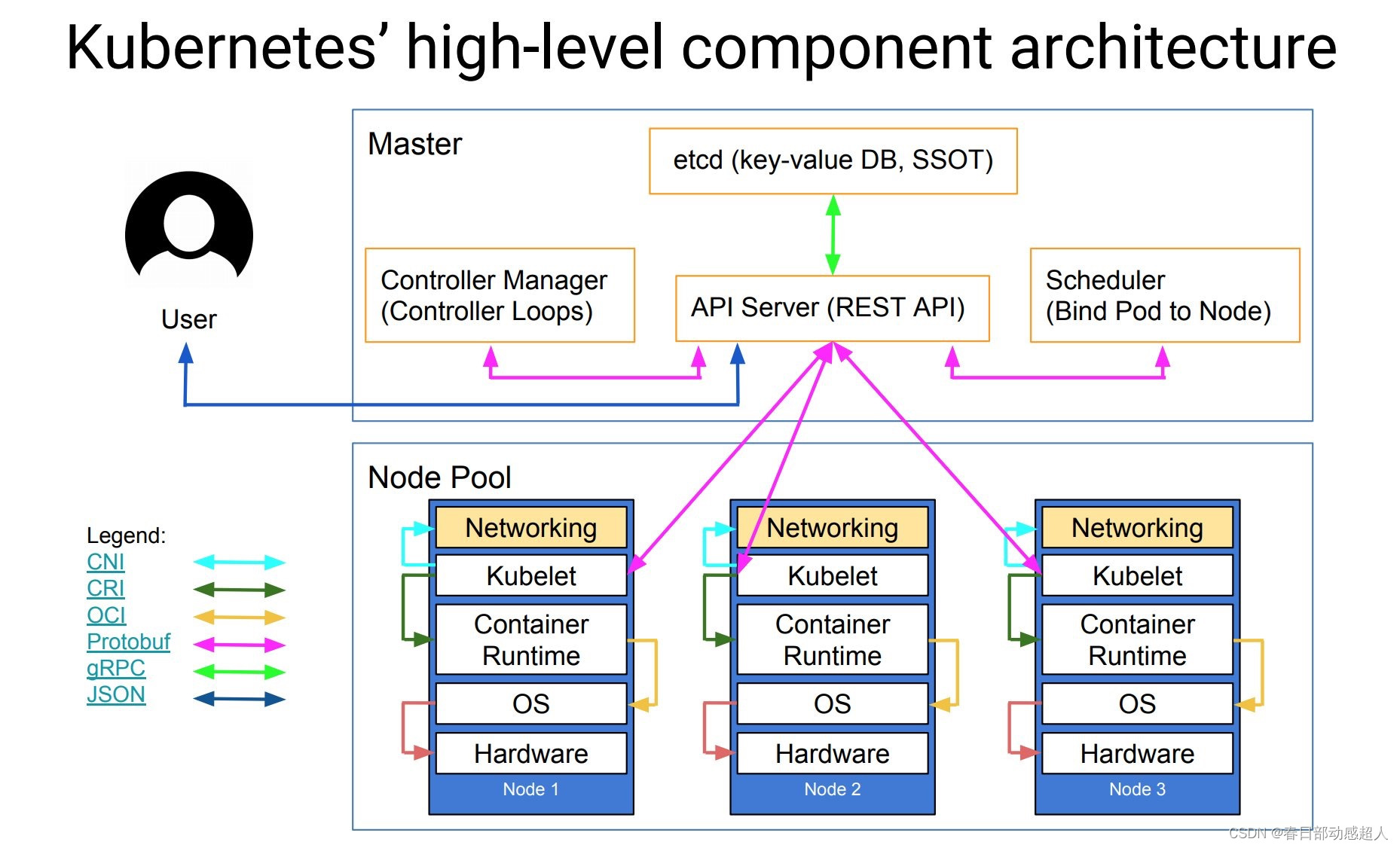
下圖清晰表明了 Kubernetes 的架構設計以及組件之間的通信協議。
下面是更抽象的一個視圖:
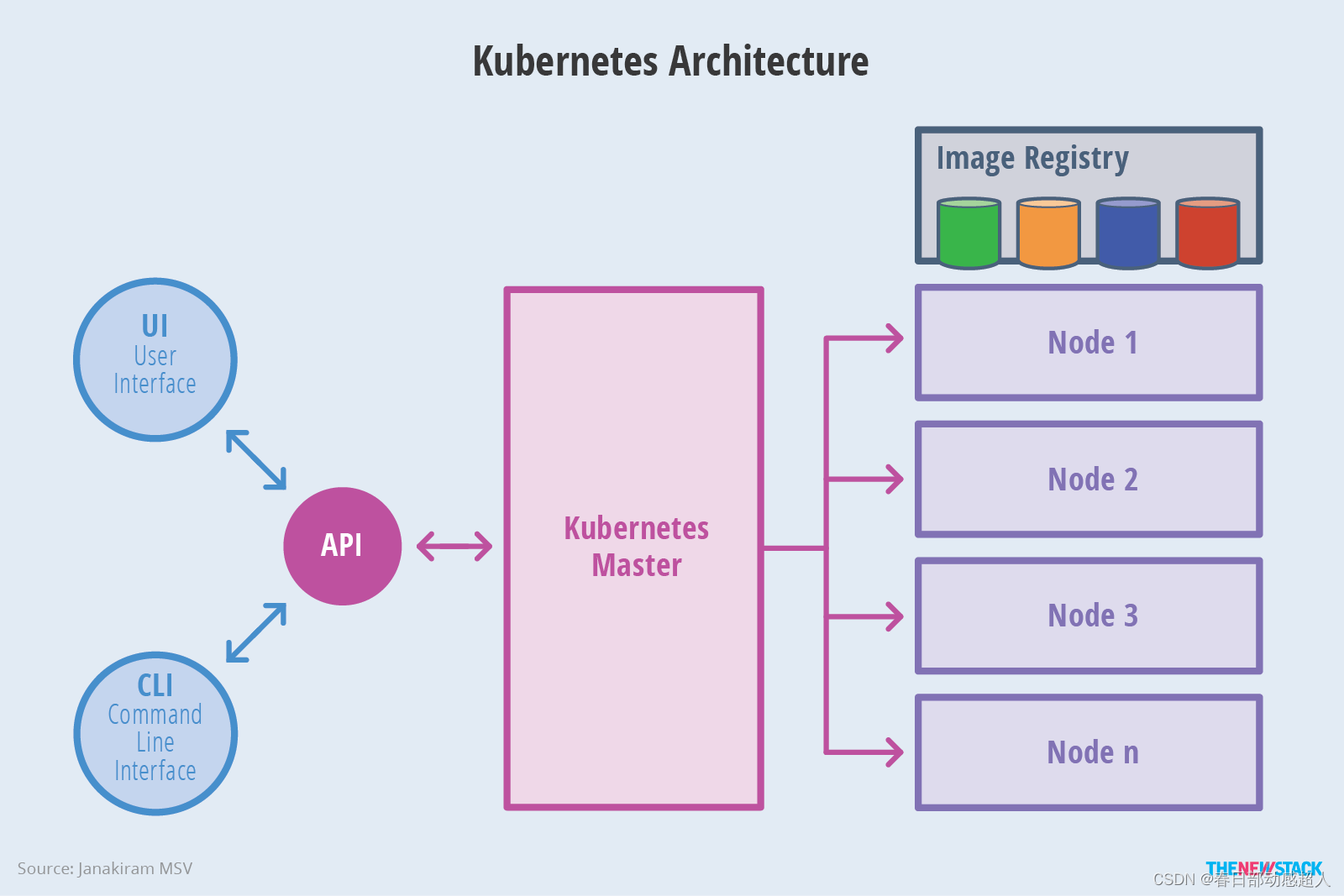
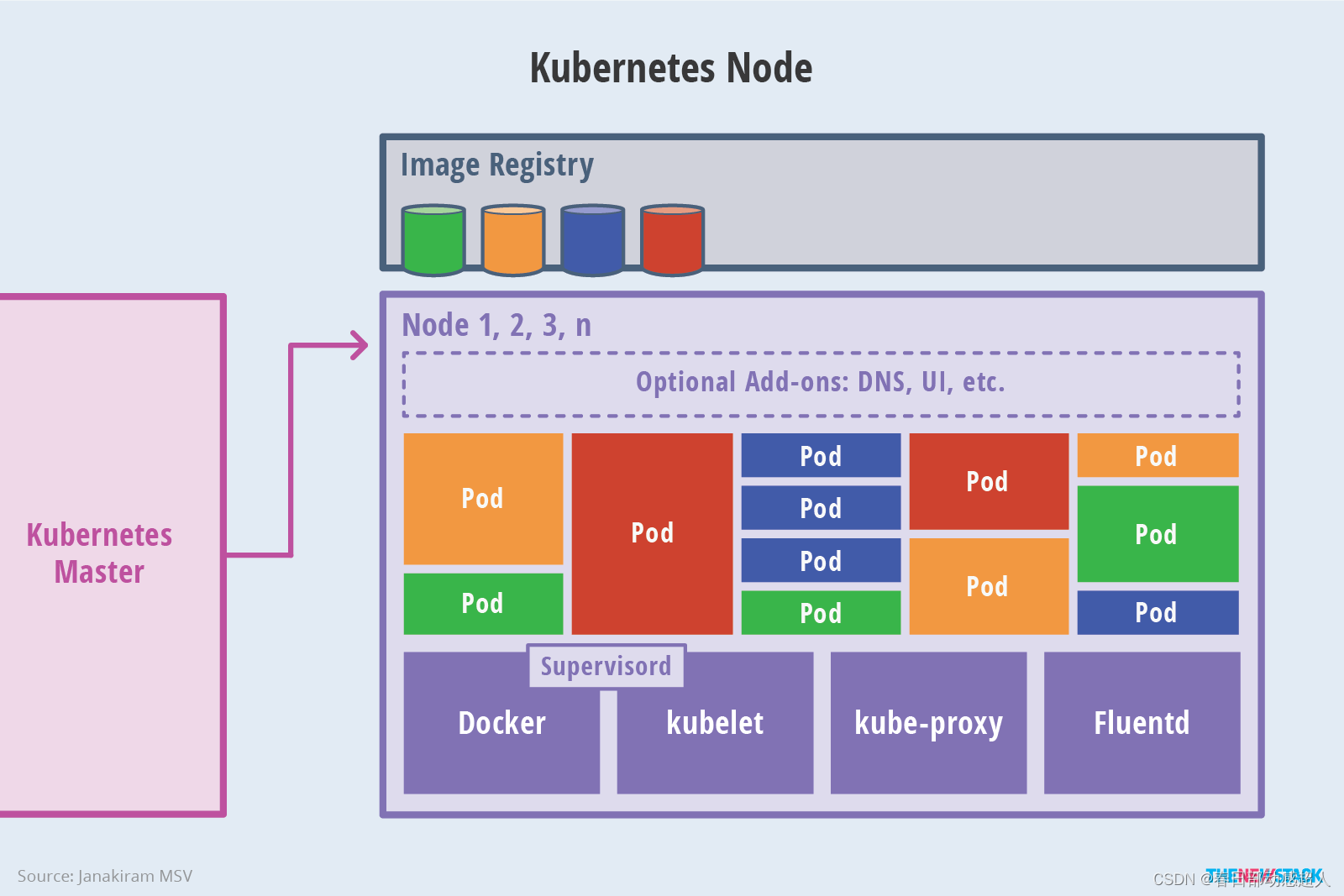
Master架構
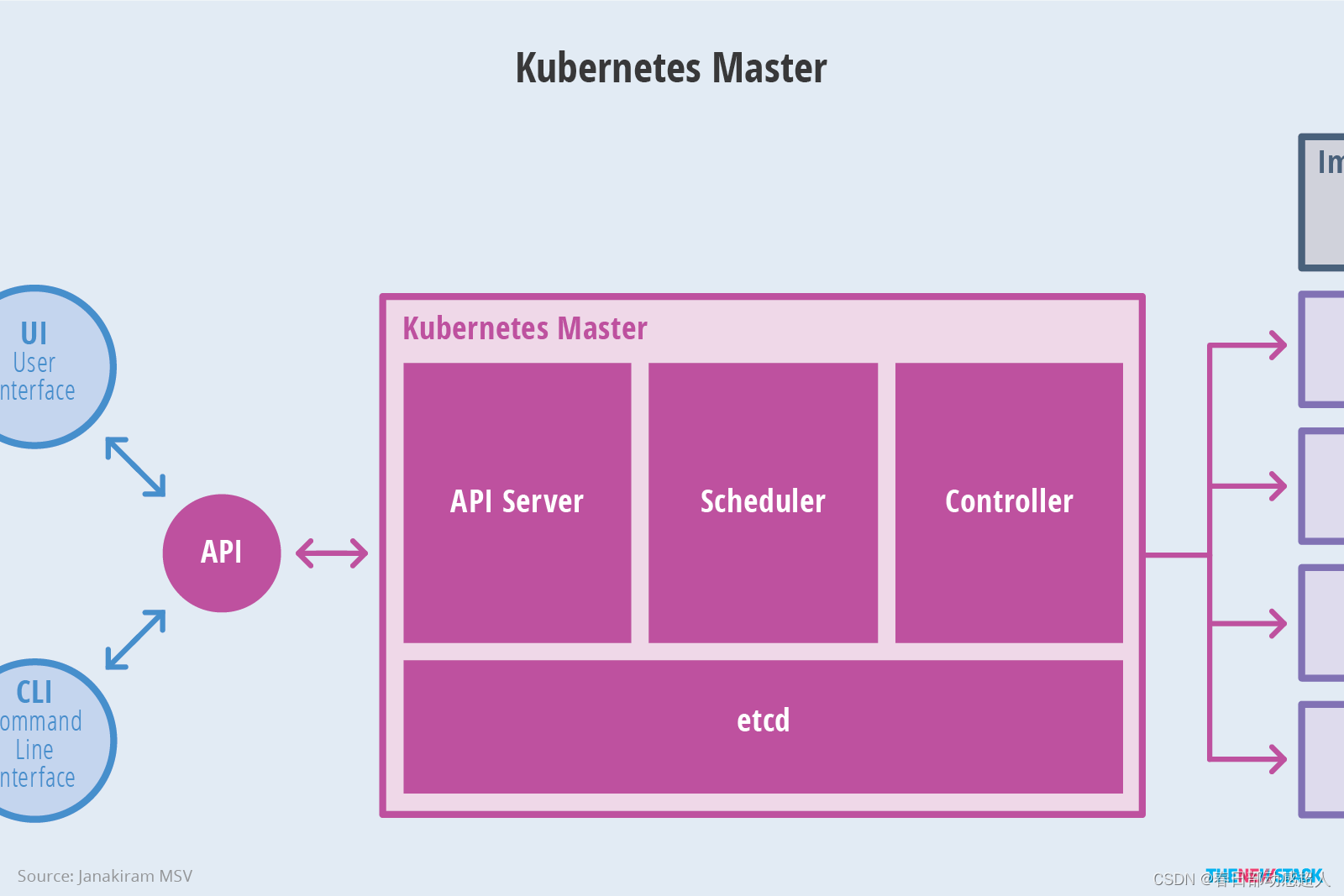
Node架構
分層架構
Kubernetes 設計理念和功能其實就是一個類似 Linux 的分層架構,如下圖所示。
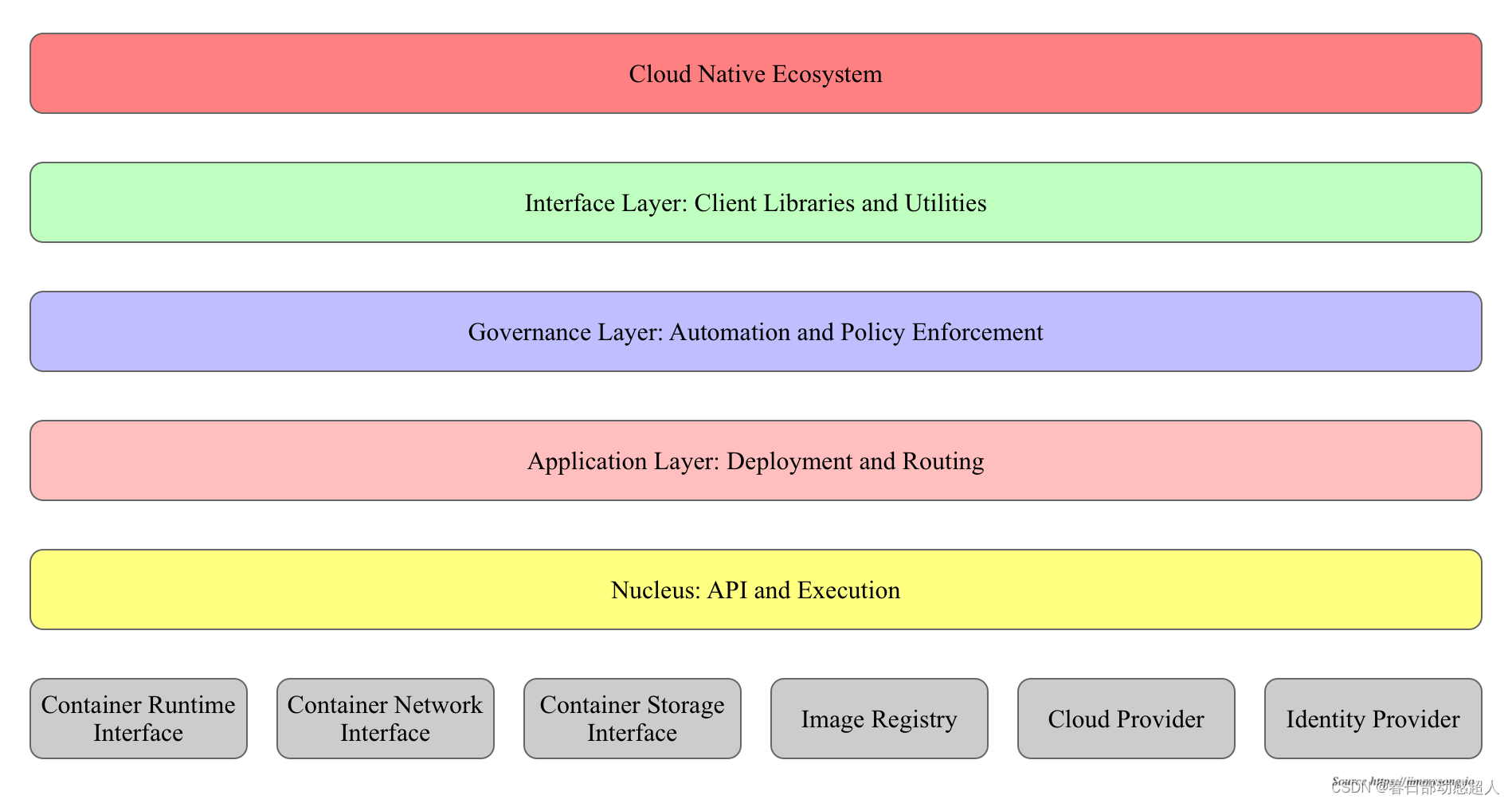
- 核心層:Kubernetes 最核心的功能,對外提供 API 構建高層的應用,對內提供插件式應用執行環境
- 應用層:部署(無狀態應用、有狀態應用、批處理任務、集群應用等)和路由(服務發現、DNS 解析等)、Service Mesh(部分位于應用層)
- 管理層:系統度量(如基礎設施、容器和網絡的度量),自動化(如自動擴展、動態 Provision 等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy 等)、Service Mesh(部分位于管理層)
- 接口層:kubectl 命令行工具、客戶端 SDK 以及集群聯邦
- 生態系統:在接口層之上的龐大容器集群管理調度的生態系統,可以劃分為兩個范疇
- Kubernetes 外部:日志、監控、配置管理、CI/CD、Workflow、FaaS、OTS 應用、ChatOps、GitOps、SecOps 等
- Kubernetes 內部:CRI、CNI、CSI、鏡像倉庫、Cloud Provider、集群自身的配置和管理等
2 CPU架構
ARM64和x86是指基于不同架構的處理器。
ARM64是指基于ARM架構的64位處理器,而ARM是指基于ARM架構的32位處理器。ARM架構廣泛應用于手機和移動設備領域,具有低成本、高性能、低電耗的特點。
x86則是指基于x86架構的處理器,它可以是32位或64位處理器架構,具體取決于處理器型號。x86架構廣泛應用于傳統的PC和服務器領域。
因為ARM64與x86是不同的CPU架構,兩者的指令集不同,因此在部署時,需要考慮具體適配的軟件安裝包。
本文將基于arm64架構的國產操作系統統信UOS為例,說明K8S部署流程,僅供參考。
3 環境信息
| 環境 | 版本 | 說明 |
|---|---|---|
| 操作系統 | UnionTech OS Server 20 | |
| CPU架構 | aarch64 | |
| docker | 17.09.0-ce | OS/Arch: linux/arm64 |
| K8S | 1.20.11 | OS/Arch: linux/arm64 |
| rancher | v2.5.16-linux-arm64 | OS/Arch: linux/arm64 |
4 部署Docker
如果當前環境已經部署完arm64的docker,請忽略此章節。
下面的操作,需要在規劃K8S的所有機器上執行。
4.1 環境準備
4.1.1 磁盤掛載
如果磁盤已經掛載,則省略該步驟。
docker推薦使用 xfs 磁盤格式。
磁盤掛載
$ mkfs.xfs -f /dev/vdb
$ mkdir /demo
$ mount /dev/vdb /demo
查看磁盤id
$ blkid
永久掛載
$ echo "UUID=94be2fa7-93aa-47a4-b661-45963b28fbb4 /demo xfs defaults 0 0" >> /etc/fstab
$ mount -a
備注:這里磁盤格式化僅做參考,具體的磁盤格式化以及掛載,請自行參考其他文檔。目的就是:掛載xfs格式的磁盤到指定目錄下(比如 /demo)
4.1.2 docker 根目錄
磁盤掛載路徑為/var/lib/docker時可忽略此步
磁盤掛載路徑為其他路徑時,通過mount --bind方式掛載目錄
1 創建掛載目錄
$ mkdir -p /demo/data/docker
2 將/demo/data/docker映射到/var/lib/docker
$ mount --bind /demo/data/docker /var/lib/docker
3 設置永久生效
$ echo "/demo/data/docker /var/lib/docker none bind 0 0" >> /etc/fstab
4 掛載
$ mount -a
4.2 下載Docker安裝包并且解壓
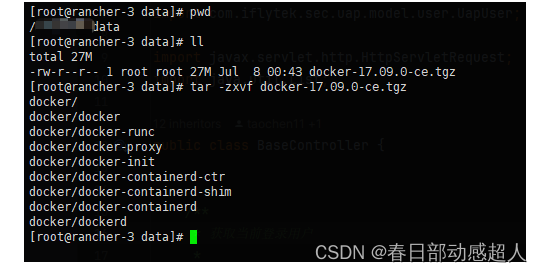
進入 /demo/data/ 目錄下,下載 aarch64的docker安裝包
執行如下命令:
# wget https://download.docker.com/linux/static/stable/aarch64/docker-17.09.0-ce.tgz

下載完成后,在當前目錄進行解壓操作:
$ tar -zxvf docker-17.09.0-ce.tgz
4.3 復制文件
在 /demo/data 目錄下執行如下命令:
$ cp docker/* /usr/bin/
4.4 創建containerd的service文件
執行如下命令:
$ touch /etc/systemd/system/docker.service
# 給予可執行權限
$ chmod +x /etc/systemd/system/docker.service
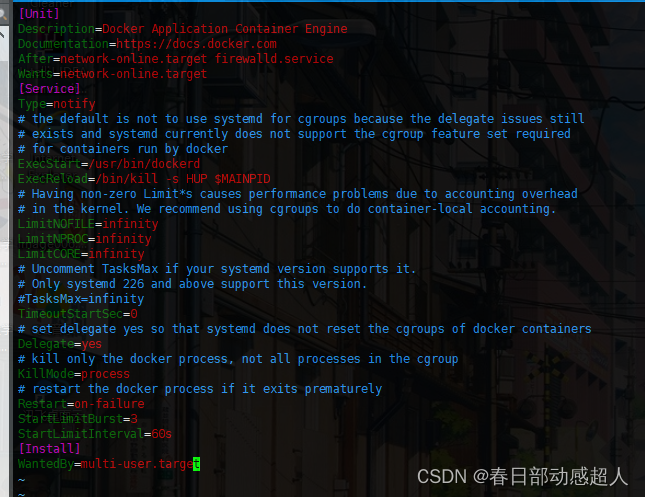
編輯docker.service文件,添加下面的內容:
$ vim /etc/systemd/system/docker.service
內容如下:
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target
[Service]
Type=notify
# the default is not to use systemd for cgroups because the delegate issues still
# exists and systemd currently does not support the cgroup feature set required
# for containers run by docker
ExecStart=/usr/bin/dockerd
ExecReload=/bin/kill -s HUP $MAINPID
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
# Uncomment TasksMax if your systemd version supports it.
# Only systemd 226 and above support this version.
#TasksMax=infinity
TimeoutStartSec=0
# set delegate yes so that systemd does not reset the cgroups of docker containers
Delegate=yes
# kill only the docker process, not all processes in the cgroup
KillMode=process
# restart the docker process if it exits prematurely
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
4.5 啟動docker
重新加載配置文件
$ systemctl daemon-reload
啟動docker
$ systemctl start docker
設置 docker 開機啟動
$ systemctl enable docker.service
5 部署K8S
5.1 關閉selinux
selinux 是一個 Linux 內核模塊,同時也是 Linux 的一個安全子系統。
SELinux 的主要作用是最大限度地減小系統中的安全風險,提高系統的安全性。
這個重要的安全工具由美國國家安全局開發,并且已經被集成到了主流的 Linux 2.6 及以上版本的內核中。
#臨時關閉
$ setenforce 0
#永久關閉 SELINUX=disabled
$ vim /etc/sysconfig/selinux

5.2 關閉swap分區
Swap分區,也被稱為交換分區或虛擬內存,是Linux系統中用于當物理內存不足時,將部分硬盤空間虛擬成內存使用的系統機制。它的作用在于釋放物理內存中的一部分空間,以供當前運行的程序使用。當系統的物理內存不夠用的時候,將其中一些暫時不需要的數據交換到交換空間。
but 有利有弊:
在安裝Kubernetes(K8S)時,建議關閉swap分區。因為K8S的各個組件和容器都需要足夠的內存來運行,而Swap的使用可能導致性能下降,甚至是應用程序的奔潰。如果系統內存不足,Kubernetes會將一部分數據交換到swap分區,而這可能會降低系統的性能,甚至導致Pod異常終止。
此外,對于一些集群,它們的swap位于機械硬盤陣列上,大量動用swap基本可以等同于死機,你甚至連root都登錄不上,不用提殺掉問題進程了。往往結局就是硬重啟。
然而,在關閉swap分區之前,需要確保系統的內存容量足夠滿足所有Pod的內存需求,以及不會因為關閉swap分區而導致系統崩潰或出現其他問題。因此,如果系統內存充足或者有額外的物理內存可供使用,建議保留swap分區。
#臨時關閉
swapoff -a
#永久關閉 注釋 swap 行
vim /etc/fstab
5.3 關閉防火墻
systemctl stop firewalld
systemctl disable firewalld
5.4 網絡配置 iptables
Linux橋接功能是一種虛擬交換機,它是用純軟件實現的,具有和物理交換機相同的功能,例如二層交換,MAC地址學習等。它是一個軟件層面的網絡設備,用于在Linux系統中創建和管理網絡橋接。
網橋的主要作用是將多個物理或虛擬網絡接口連接在一起,以創建一個共享相同網絡段的網絡。而將網絡接口連接起來的結果就是,一個網絡接口接收到網絡數據包后,會復制到其他網絡接口中。
此外,如果你想把虛擬機當做一臺完全獨立的計算機看待,并且允許它和其他終端一樣的進行網絡通信,那么橋接模式通常是虛擬機訪問網絡的最簡單途徑。同時,bridge技術還可以把一個linux設備上的兩塊網卡橋接在一起,對外表現為一個大的網卡接口,比如你有兩臺設備,但是又沒有路由器,那么把他們橋接在一起,可以共享其中一臺的網絡,這樣兩臺都可以上網。
在Kubernetes(K8S)中,打開橋接功能的主要目的是為了解決網絡通信問題。首先,每個Pod的網卡都是veth設備,veth pair的另一端連上宿主機上的網橋。由于網橋是虛擬的二層設備,同節點的Pod之間通信直接走二層轉發,跨節點通信才會經過宿主機eth0。
其次,如果需要在K8S集群內部署一個VPN,需要采用橋接VPN+靜態路由的雙重策略,才能實現互相都可以直接使用IP進行訪問。此外,開發人員在進行微服務開發的時候需要通過服務發現進行Pod級服務的直接訪問,現在的K8S網絡沒辦法做到直接訪問pod或者service的ip。這時,可以通過Bridge to Kubernetes功能將應用程序的所有出站流量路由回Kubernetes群集。
總的來說,K8S打開橋接功能主要是為了優化網絡通信,提高服務發現的效率和靈活性,以及實現不同網絡間的無縫連接。
net.bridge.bridge-nf-call-iptables是一個 Linux 內核參數,用于控制橋接設備是否調用iptables進行網絡過濾。當設置為 1 時,表示啟用iptables;當設置為 0 時,表示禁用iptables。這個參數通常在/etc/sysctl.conf文件中進行配置。
net.bridge.bridge-nf-call-ip6tables=1是一個 Linux 內核參數,用于控制橋接設備是否調用ip6tables進行網絡過濾。當設置為 1 時,表示啟用ip6tables;當設置為 0 時,表示禁用ip6tables。這個參數通常在/etc/sysctl.conf文件中進行配置。
net.ipv4.ip_forward=1是一個 Linux 內核參數,用于控制 IPv4 數據包轉發功能是否開啟。當設置為 1 時,表示啟用 IPv4 數據包轉發;當設置為 0 時,表示禁用 IPv4 數據包轉發。這個參數通常在/etc/sysctl.conf文件中進行配置。
m.swappiness=0是一個 Linux 內核參數,用于控制虛擬機(VM)的交換空間使用情況。當設置為 0 時,表示禁用交換空間;當設置為 100 時,表示啟用交換空間并盡可能使用它。這個參數通常在/etc/sysctl.conf文件中進行配置。
對iptables內部的nf-call需要打開的內生的橋接功能
$ touch /etc/sysctl.d/k8s.conf
$ vim /etc/sysctl.d/k8s.conf
修改如下內容:
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
vm.swappiness=0
修改完成后執行:
$ modprobe br_netfilter
$ sysctl -p /etc/sysctl.d/k8s.conf
5.5 配置kubernetes源
yum源是一個在Linux下的軟件包管理器,它能夠從指定的服務器自動下載RPM包并完成安裝,同時可以自動處理軟件包之間的依賴關系。
根據存儲位置的不同,yum源可以被分為本地yum源和網絡yum源兩種類型。本地yum源是指yum倉庫在本地,通常是本地的鏡像文件;而網絡yum源則是指yum倉庫在遠程,也就是說我們需要聯網才能使用。
yum.repos.d目錄是Linux系統中存放yum源配置文件的默認位置。在該目錄下,每個子目錄都代表一個yum源,子目錄的名稱通常以.repo結尾。在
/etc/yum.repos.d/目錄下,系統會默認存在一些yum源配置文件,例如 CentOS 官方源、epel源等。同時,用戶也可以自己創建新的yum源配置文件并放置在該目錄下,以便安裝其他軟件包或更新系統時使用。需要注意的是,當修改了
yum.repos.d目錄下的任何一個配置文件后,都需要運行yum clean all命令清除緩存,否則新添加的軟件包可能無法被正確識別和安裝。
創建/etc/yum.repos.d/kubernetes.repo文件
$ touch /etc/yum.repos.d/kubernetes.repo
編輯:
$ vim /etc/yum.repos.d/kubernetes.repo
添加如下內容:
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-aarch64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
#清除緩存
yum clean all
#把服務器的包信息下載到本地電腦緩存起來,makecache建立一個緩存
yum makecache
5.6 安裝kubelet kubeadm kubectl
kubelet:運行在K8S cluster所有節點上,負責啟動POD和容器
kubeadm:用于初始化K8S集群
kubectl:kubectl是kubenetes命令行工具,通過kubectl可以部署和管理應用,查看各種資源,創建,刪除和更新組件
當不指定具體版本時,將下載當前yum源對應的最新版本
$ yum install -y kubelet kubeadm kubectl
也可以指定版本,建議指定如下版本
#安裝指定版本的kubelet,kubeadm,kubectl
$ yum install -y kubelet-1.20.11 kubeadm-1.20.11 kubectl-1.20.11
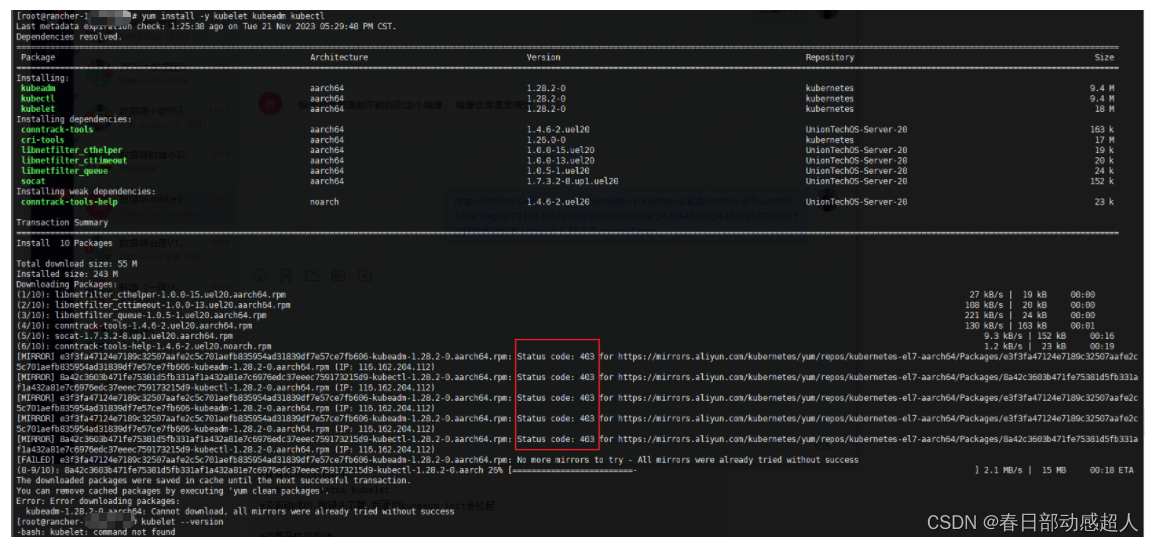
安裝時如果出現 403,解決方案是多嘗試幾次。
安裝完成后,查看K8S版本
#查看kubelet版本
$ kubelet --version
查看kubeadm版本
$ kubeadm version

5.7 啟動kubelet并設置開機啟動服務
Systemctl是Systemd的主命令,主要用于管理系統和服務。Systemd是Linux系統最新的初始化系統,也就是init,它的主要作用是提高系統的啟動速度,盡可能啟動較少的進程,并讓更多的進程并發啟動。
daemon-reload是一個systemd命令,它的主要功能是重新加載systemd的守護進程。當服務文件(service file)發生變化時,可以使用此命令來使這些變化立即生效,而無需重啟整個系統。例如,如果你新安裝了一個服務,并且這個服務被systemd管理,那么為了讓新服務的配置文件生效,你需要運行
systemctl daemon-reload命令。此外,如果服務的程序配置文件發生了變化,也需要重新加載以使新的配置生效。需要注意的是,使用此命令需要管理員權限,通常可以通過在命令前添加
sudo來獲取。例如:sudo systemctl daemon-reload。
重新加載配置文件
$ systemctl daemon-reload
啟動kubelet
$ systemctl start kubelet
查看kubelet啟動狀態
$ systemctl status kubelet
沒啟動成功,報錯先不管,后面的kubeadm init會拉起

設置開機自啟動
$ systemctl enable kubelet

查看kubelet開機啟動狀態 enabled:開啟, disabled:關閉
$ systemctl is-enabled kubelet

查看日志
journalctl -xefu是一個常用的命令,用于查看系統日志并顯示錯誤信息。其中,各個選項的含義如下:
-x: 顯示系統啟動后的所有日志,包括正常和錯誤日志。-e: 只顯示最近的錯誤日志。-f: 實時刷新日志輸出,即當有新的日志產生時,會立即顯示在屏幕上。-u: 顯示內核日志。通過運行這個命令,可以快速定位系統中的問題,并了解系統的運行狀態。例如,如果系統出現了崩潰或異常情況,可以使用此命令來查找相關的錯誤日志,以幫助解決問題。
$ journalctl -xefu kubelet
arm64環境,到此步后,先看看 FAQ中的問題4.
5.8 初始化K8S集群Master
注意,此操作只在規劃的Master服務器上執行
#執行初始化命令
kubeadm init --image-repository registry.aliyuncs.com/google_containers --apiserver-advertise-address=172.31.186.36 --kubernetes-version=v1.20.11 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12
可能比較耗時,請耐心等待
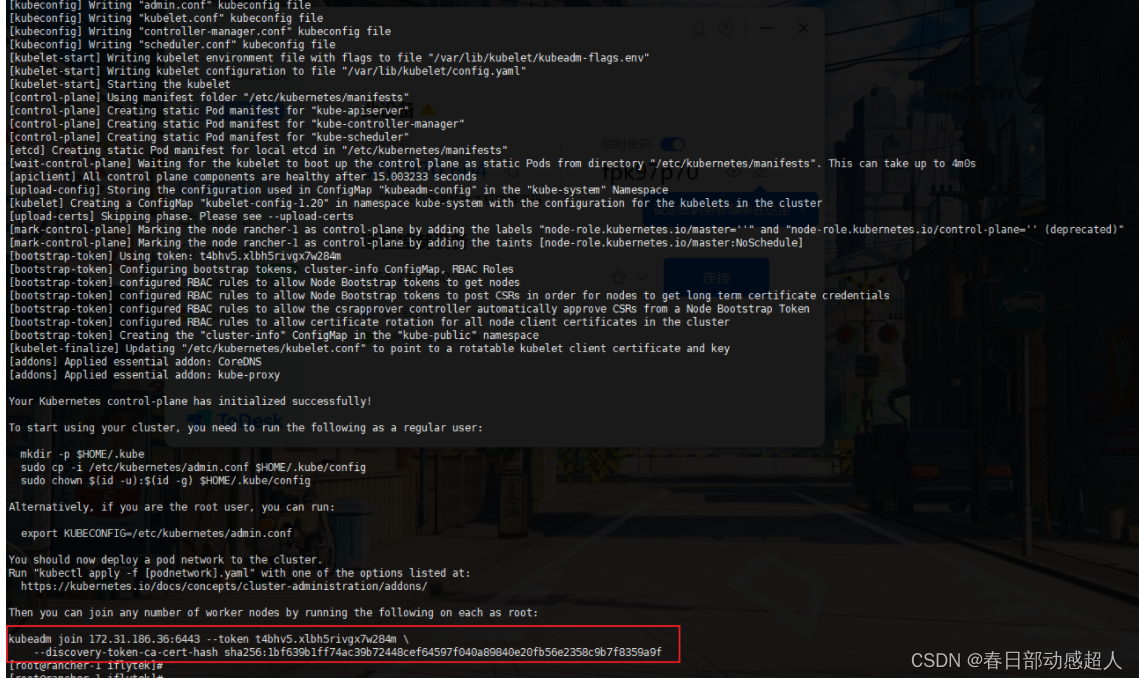
待初始化完成后,需要按照提示,執行如下命令:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
export KUBECONFIG=/etc/kubernetes/admin.conf
這里需要注意,要將最后一個命令復制出來并且保存,用于后續添加節點使用:
kubeadm join 172.31.186.36:6443 --token t4bhv5.xlbh5rivgx7w284m \--discovery-token-ca-cert-hash sha256:1bf639b1ff74ac39b72448cef64597f040a89840e20fb56e2358c9b7f8359a9f
查看K8S集群節點
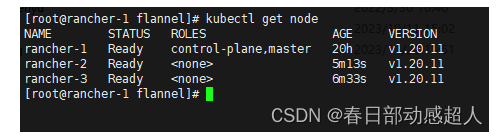
$ kubectl get node

NAME STATUS ROLES AGE VERSION
rancher-1 NotReady control-plane,master 13h v1.20.11
這里會發現狀態是 NotReady ,是因為沒有安裝網絡插件。
查看kubelet的日志
$ journalctl -xef -u kubelet -n 20
5.9 安裝flannel網絡插件
創建文件夾
$ mkdir -p /demo/package_k8s/flannel
$ cd /demo/package_k8s/flannel
在/demo/package_k8s/flannel目錄,下載文件
curl -O https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
因為網絡原因,可能比較耗時,如果下載失敗了,請耐心的多嘗試幾次。
kube-flannel.yml里需要下載鏡像,我這里提前先下載
$ docker pull quay.io/coreos/flannel:v0.14.0-rc1
創建flannel網絡插件
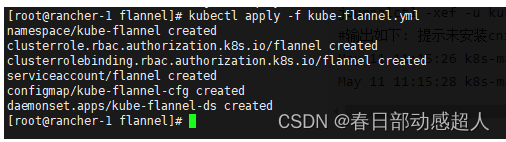
$ kubectl apply -f kube-flannel.yml
5.10 集群添加節點
在其他節點上執行5.1、5.2、5.3、5.4、5.5、5.6、5.7、5.9
執行完后,在除Master之外的節點執行 5.8 生產的命令:
kubeadm join 172.31.186.36:6443 --token t4bhv5.xlbh5rivgx7w284m \--discovery-token-ca-cert-hash sha256:1bf639b1ff74ac39b72448cef64597f040a89840e20fb56e2358c9b7f8359a9f

在master節點執行:
$ kubectl get node
6 部署rancher
Rancher是一個企業級容器管理平臺,可以幫助組織在生產環境中輕松快捷的部署和管理容器。Rancher支持多種云和本地生態系統,提供一鍵部署、多種編排調度工具、多租戶、多種基礎架構等功能,適用于混合云、多環境、多資源池、DevOps流水等場景 。
-
如果不需要用rancher來管理K8S集群,請忽略此章節。
-
如果當前環境已經部署完arm64的rancher,請忽略此章節。
部署rancher前,請保證arm64架構的docker已經部署成功
6.1 pull 鏡像
rancher需要pull第三方鏡像,為了節省時間,我們可以提前下載好rancher相關的鏡像
這里的 docker中央倉庫地址 只是舉例,請根據實際情況填寫 dockerpull 的鏡像地址
執行如下pull:
docker pull docker中央倉庫地址/fleet-agent:v0.3.10-security1
docker pull docker中央倉庫地址/rancher-agent:v2.5.16
docker pull docker中央倉庫地址/rancher:v2.5.16-linux-arm64
docker pull docker中央倉庫地址/hyperkube:v1.20.15-rancher2
docker pull docker中央倉庫地址/nginx-ingress-controller:nginx-1.2.1-rancher1
docker pull docker中央倉庫地址/rke-tools:v0.1.80
docker pull docker中央倉庫地址/mirrored-coreos-flannel:v0.15.1
docker pull docker中央倉庫地址/mirrored-ingress-nginx-kube-webhook-certgen:v1.1.1
docker pull docker中央倉庫地址/hyperkube:v1.20.11-rancher1
docker pull docker中央倉庫地址/mirrored-pause:3.6
docker pull docker中央倉庫地址/rke-tools:v0.1.78
docker pull docker中央倉庫地址/mirrored-metrics-server:v0.5.0
docker pull docker中央倉庫地址/nginx-ingress-controller:nginx-0.43.0-rancher3
docker pull docker中央倉庫地址/mirrored-coreos-etcd:v3.4.15-rancher1
docker pull docker中央倉庫地址/mirrored-coredns-coredns:1.8.0
docker pull docker中央倉庫地址/mirrored-cluster-proportional-autoscaler:1.8.1
docker pull docker中央倉庫地址/flannel-cni:v0.3.0-rancher6
docker pull docker中央倉庫地址/kube-api-auth:v0.1.4
docker pull docker中央倉庫地址/mirrored-pause:3.2
注意:執行到docker pull docker中央倉庫地址/mirrored-pause:3.2時,可能需要手動按一下回車鍵。
6.2 啟動rancher
這里會先從倉庫拉取rancher的鏡像,根據網絡環境,可能耗時較久,請等待。
docker run -d --privileged --restart=unless-stopped -p 8080:80 -p 8445:443 \
-v /demo/data/rancher/rancher:/var/lib/rancher \
-v /demo/data/rancher/auditlog:/var/log/auditlog \
--name rancher rancher/rancher:v2.5.16-linux-arm64
稍等片刻,瀏覽器輸入:https://ip:8445/g/clusters
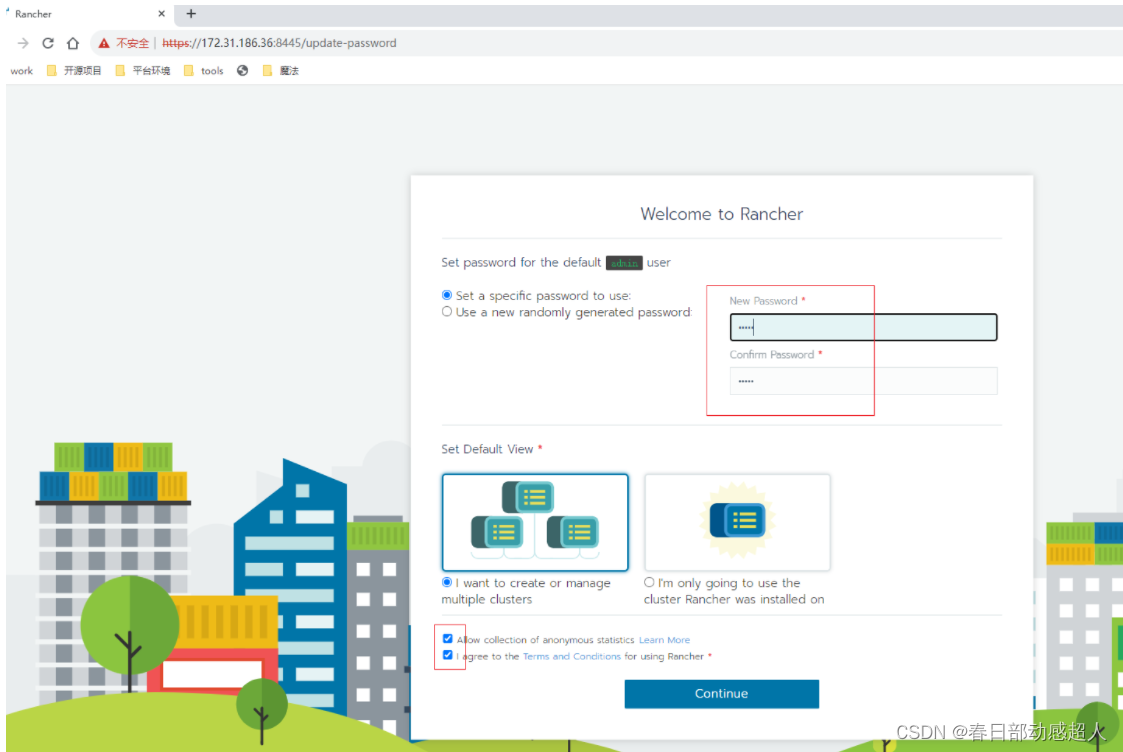
部署完rancher后,第一次打開頁面,需要進行免密設置
6.3 導入K8S集群
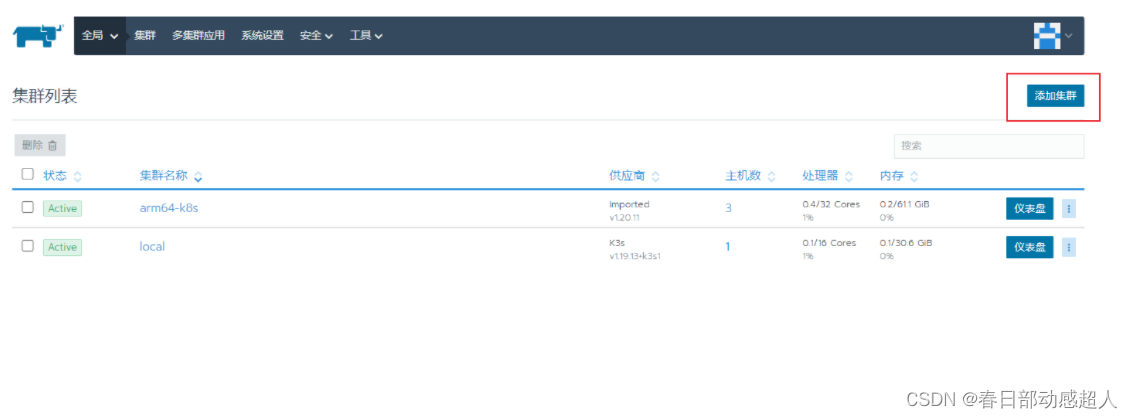
進入rancher頁面,點擊右上角的 “添加集群” 操作
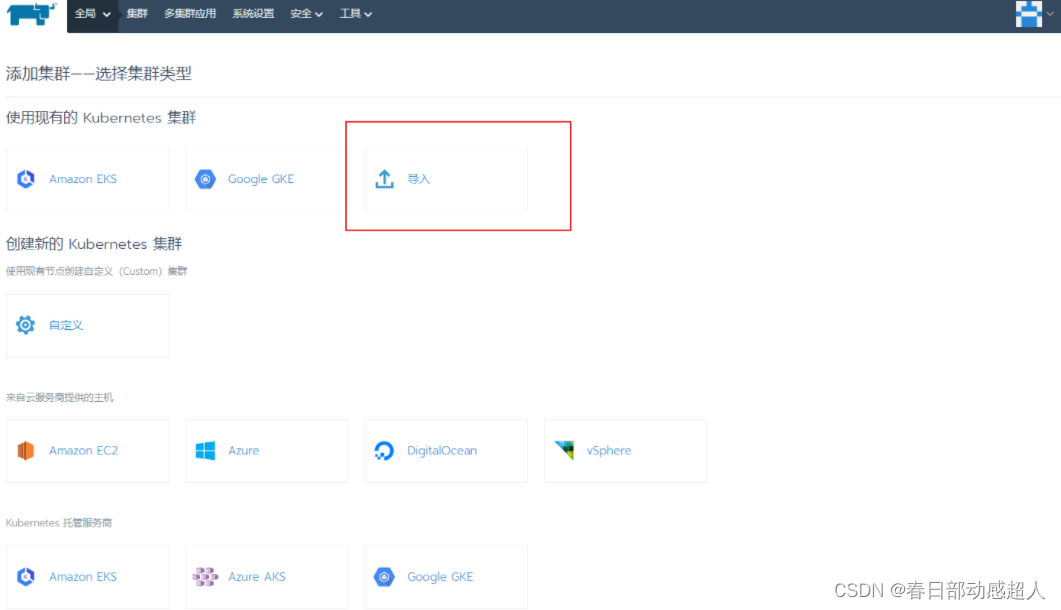
然后選擇 “導入”
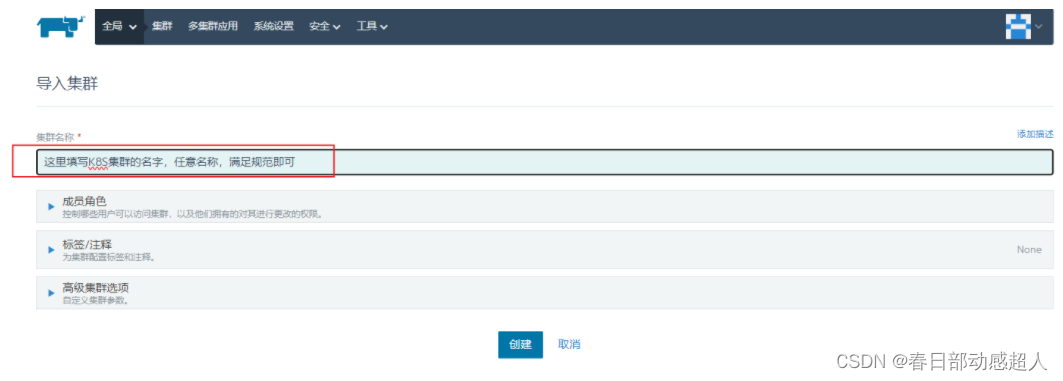
填寫K8S集群名稱
點擊 “創建” 按鈕后,會出現三個命令行,將第一個命令行的 [USER_ACCOUNT]替換為 admin。
依次在K8S Master機器上執行下面三個命令行。
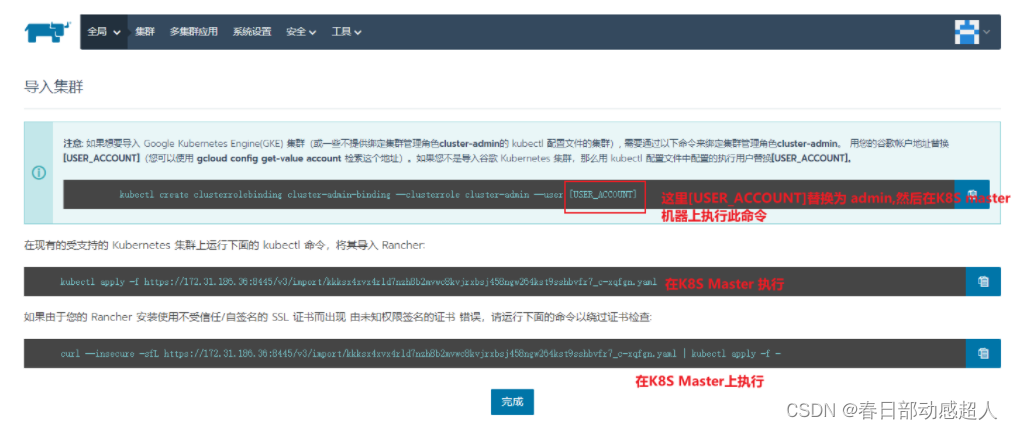
執行命令1
在K8S master機器上執行:
$ kubectl create clusterrolebinding cluster-admin-binding --clusterrole cluster-admin --user admin
執行命令2
$ kubectl apply -f https://172.31.186.36:8445/v3/import/kkksx4xvx4rld7nzh8b2mvwc8kvjrxbsj458ngw264kst9sshbvfr7_c-xqfgn.yaml
如果執行命令2時,x509錯誤,則可以通過將對應的yaml文件下載到服務器本地,然后執行apply
下載yaml文件
$ wget https://172.31.186.36:8445/v3/import/6w5jzw4wtc7pg7h8cjbhcnj4ptbhgkdrrsc8ftjgkhqkvm2qc557tv_c-9g9rs.yaml --no-check-certificate
執行安裝:
$ kubectl apply -f 6w5jzw4wtc7pg7h8cjbhcnj4ptbhgkdrrsc8ftjgkhqkvm2qc557tv_c-9g9rs.yaml
執行命令3
執行復制忽略證書檢查命令:
curl --insecure -sfL https://172.31.186.36:8445/v3/import/7d64lpx6gpl8mdz4tz9nzk6r2wb684fls7fs728ns2sbzvzfdw55j4_c-llx8j.yaml | kubectl apply -f -
稍等片刻,如果一切順利,則可看到如下:
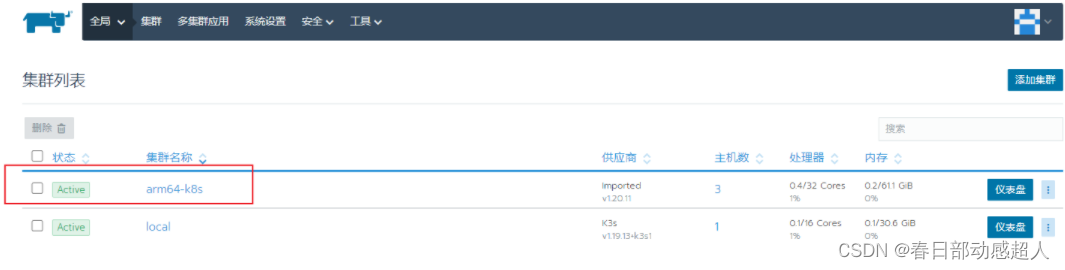
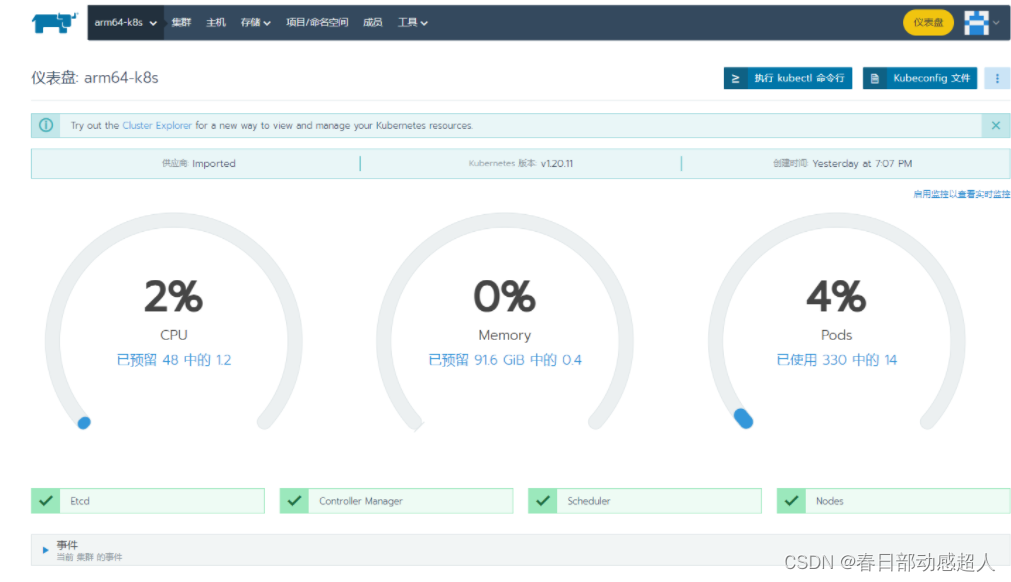
FAQ
1 問題:節點狀態為NotReady
如果安裝了flannel網絡插件后,查看節點狀態,仍然是 NotReady
且日志顯示 failed to find plugin “portmap” in path [/opt/cni/bin]

查看日志
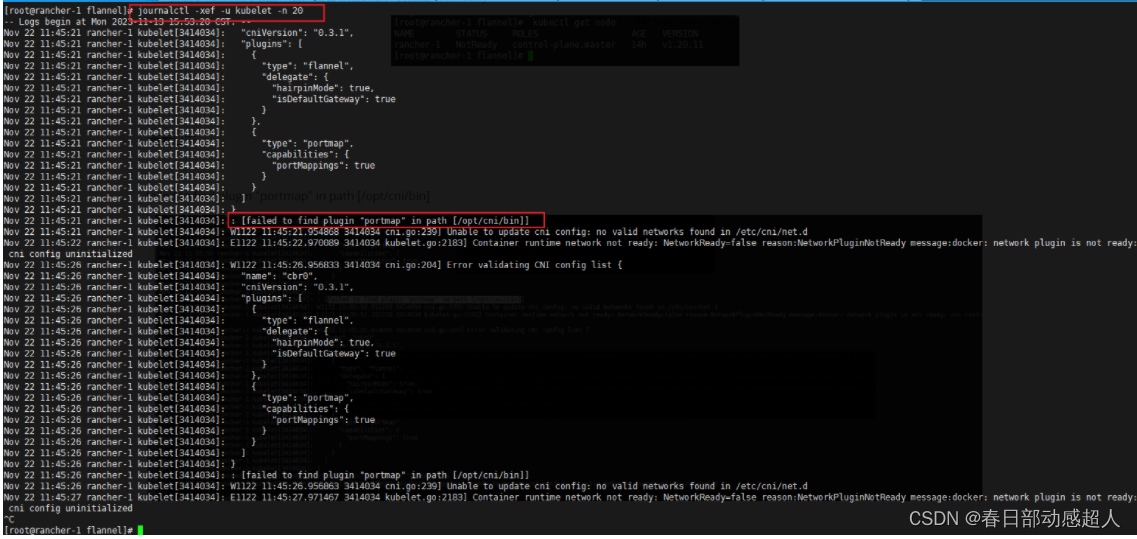
解決方案:
下載 cni-plugins-linux-arm64-v1.1.1.tgz 包,然后解壓,將其中的文件copy到 /opt/cni/bin/ 目錄下即可
tar -zxvf cni-plugins-linux-arm64-v1.1.1.tgz -C /opt/cni/bin
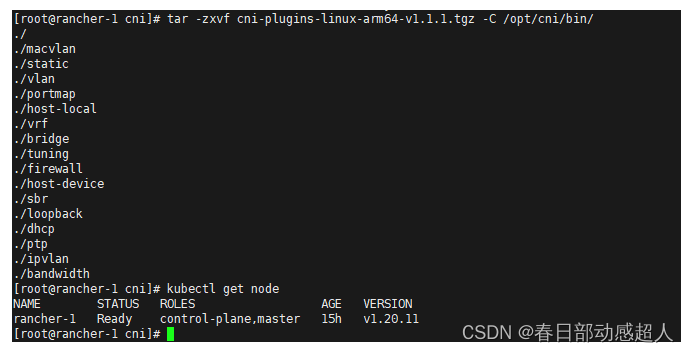
2 問題:在非master節點執行 kubectl get node

kubectl命令需要使用kubernetes-admin來運行,需要admin.conf文件(conf文件是通過“ kubeadmin init”命令在主節點/etc/kubernetes 中創建),但是從節點沒有conf文件,也沒有設置 KUBECONFIG =/root/admin.conf環境變量,所以需要復制conf文件到從節點,并設置環境變量就OK了。
其實這個問題也沒必要解決,不影響。
3 問題:rancher面板中 Controller Manager與 Scheduler不健康
如果rancher面板中 Controller Manager與 Scheduler不健康
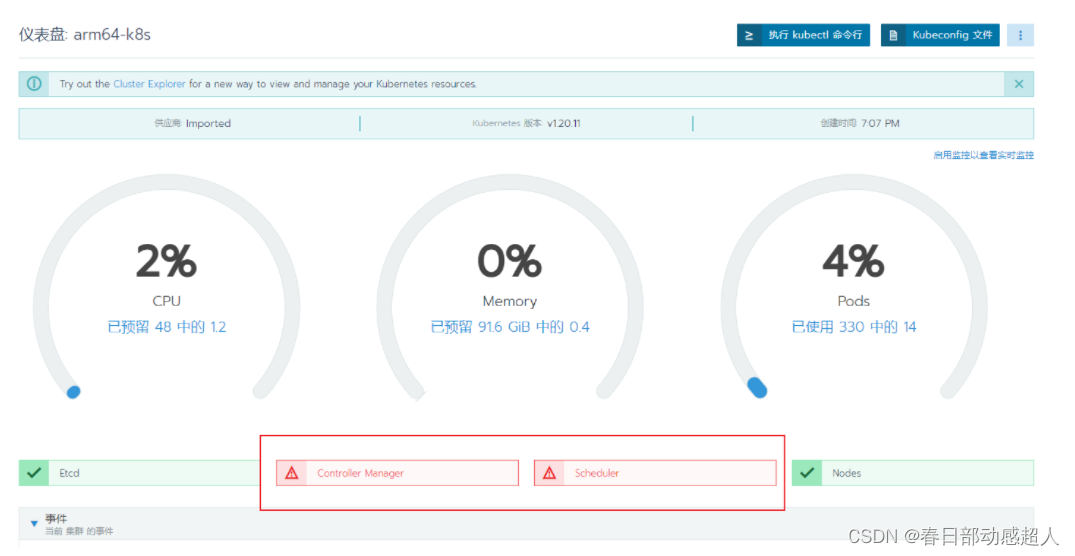
登錄到master server機器,修改如下文件:
- /etc/kubernetes/manifests/kube-controller-manager.yaml
- /etc/kubernetes/manifests/kube-scheduler.yaml
兩個文件中刪除 --port=0 配置項
然后重啟kubelete
$ service kubelet restart
稍等片刻,如果一切順利,Controller Manager與 Scheduler將恢復健康。
4 問題:failed to find plugin “portmap” in path [/opt/cni/bin]
如果kubelet服務異常,且日志里有如下報錯:
failed to find plugin "portmap" in path [/opt/cni/bin]
大概率是/opt/cni/bin目錄下沒有對應的 portmap 插件
解決方案:
1、下載 cni-plugins-linux-arm64-v1.1.1.tgz 插件
$ wget https://github.com/containernetworking/plugins/releases/download/v1.1.1/cni-plugins-linux-arm64-v1.1.1.tgz
2、解壓 cni-plugins-linux-arm64-v1.1.1.tgz 插件,并且復制到 /opt/cni/bin/
$ tar -zxvf cni-plugins-linux-arm64-v1.1.1.tgz -C /opt/cni/bin/
/opt/cni/bin是一個目錄路徑,通常用于存放網絡連接插件(CNI)的可執行文件。CNI是容器網絡接口(Container Network Interface)的縮寫,它提供了一種標準化的方式來定義和實現容器運行時的網絡連接。在Kubernetes等容器編排系統中,每個節點上的CNI插件負責為在該節點上運行的容器創建、配置和管理網絡連接。這些插件可以提供不同的網絡解決方案,例如橋接、路由、隧道等。
具體來說,
/opt/cni/bin目錄通常包含以下內容:
ip: IP地址管理工具,用于分配IP地址給容器。bridge: 橋接網絡插件,用于在主機上創建一個虛擬網絡橋接,并將容器連接到該橋接上。flannel: Flannel是一種覆蓋網絡(Overlay Network)解決方案,用于在主機之間建立虛擬網絡連接。weave: Weave是一種基于IPv6的覆蓋網絡解決方案,用于在主機之間自動創建虛擬網絡連接。calico: Calico是一種高性能的容器網絡解決方案,支持多種網絡模型和策略。請注意,具體的CNI插件可能因系統和部署環境而異。以上列出的插件只是一些常見的示例。
附錄 K8S 運維技術點簡介
刪除POD
要刪除 Kubernetes(K8S)中的 Pod,可以使用 kubectl delete pod 命令。下面是刪除 Pod 的一般格式:
# kubectl delete pod <pod-name> [-n=<namespace>]
$ kubectl delete pod coredns-7f89b7bc75-46tlx -n kube-system
按照創建時間升序查看POD
要按照創建時間升序查看 Kubernetes(K8S)中的 Pod,可以使用 kubectl get pods --sort-by=.metadata.creationTimestamp 命令。
$ kubectl get pods -A --sort-by=.metadata.creationTimestamp






)

Vue生命周期、組件技術、事件總線、)



)






