
???YOLOv5實戰寶典--星級指南:從入門到精通,您不可錯過的技巧
??-- 聚焦于YOLO的 最新版本, 對頸部網絡改進、添加局部注意力、增加檢測頭部,實測漲點?? 深入淺出YOLOv5:我的專業筆記與技術總結
??-- YOLOv5輕松上手, 適用技術小白,文章代碼齊全,僅需 一鍵train,解決 YOLOv5的技術突破和創新潛能?? YOLOv5創新攻略:突破技術瓶頸,激發AI新潛能"
?? -- 指導獨特且專業的分析, 也支持對YOLOv3、YOLOv4、YOLOv8等網絡的修改?? 改進YOLOv5?? ,改進點包括: ?? 替換多種骨干網絡/輕量化網絡, 添加多種注意力, 包含自注意力/上下文注意力/自頂向下注意力機制/空間通道注意力/,設計不同的網絡結構,助力漲點!!!

YOLOv5結合華為諾亞VanillaNet Block模塊
- 介紹
- 核心代碼
- 加入YOLOv5
- yaml文件:
- 運行結果
論文: VanillaNet: the Power of Minimalism in
Deep Learning
代碼: https://link.zhihu.com/?target=https%3A//github.com/huawei-noah/VanillaNet
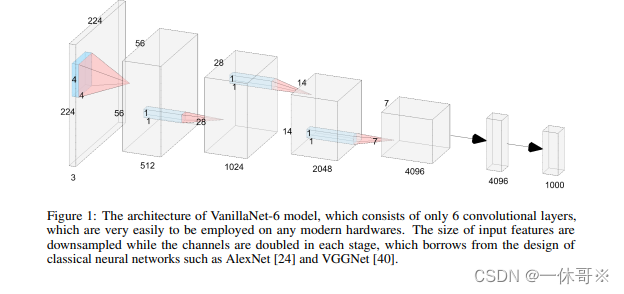
介紹
??基礎模型的設計哲學往往遵循“更多即更好”的原則,在計算機視覺和自然語言處理領域取得的顯著成就中得到了驗證。盡管如此,對于Transformer模型而言,隨之而來的優化挑戰和固有的復雜性也促使了向更簡潔設計的轉變。
??本研究引入了VanillaNet,一種在設計上追求簡潔性的神經網絡架構。VanillaNet避免了復雜的構建如高深度網絡結構、捷徑連接和自注意力機制,呈現出一種令人耳目一新的簡明強大。它的每一層都經過精心設計,簡潔且直接,訓練后的非線性激活函數被精簡,以還原至最初的簡潔結構。
??VanillaNet以其對復雜性的挑戰克服,成為資源受限環境下的理想選擇,其易于理解和簡化的構架開啟了高效部署的新可能。廣泛的實驗結果驗證了VanillaNet在圖像分類、目標檢測和語義分割等多項任務中可與知名的深度網絡和視覺Transformer相媲美的性能,彰顯了極簡主義在深度學習中的潛力。VanillaNet的創新之路預示著重新定義行業格局和挑戰傳統模型的巨大潛力,為簡潔而有效的模型設計鋪開了全新的道路。


??為了解決多頭自注意力(MHSA)在可擴展性方面的問題,先前的研究提出了各種稀疏注意力機制,其中查詢只關注有限的鍵值對,而非全部。通常依賴于靜態的手工設計模式或在所有查詢之間共享鍵值對的采樣子集,缺乏自適應性和獨立性。
??本研究提出了VanillaNet,一種簡單而高效的神經網絡架構,它采用了幾層卷積層,去除了所有分支,甚至包括捷徑連接。通過調整VanillaNets中的層數來構建一系列網絡。VanillaNet-9在保持79.87%準確率的同時,將推理速度降至2.91ms,遠超ResNet-50和ConvNextV2-P。
??令人驚訝的成果突顯了VanillaNet在實時處理任務中的潛力。進一步擴展了通道數量和池化大小,從而得到了VanillaNet-13-1.5×?,在ImageNet上達到了83.11%的Top-1準確率。這表明,通過簡單的擴展,VanillaNets可以實現與深層網絡相當的性能。不同架構的深度與推理速度的對比顯示,網絡的深度而非參數數量與推理速度緊密相關,強調了簡單和淺層網絡在實時處理任務中的巨大潛力。VanillaNet在所有考察的架構中實現了最優的速度與準確度的平衡,特別是在GPU延遲較低的情況下,表明了在充分計算能力支持下VanillaNet的卓越性??。
核心代碼
#Copyright (C) 2023. Huawei Technologies Co., Ltd. All rights reserved.#This program is free software; you can redistribute it and/or modify it under the terms of the MIT License.#This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the MIT License for more details.import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import weight_init, DropPath
from timm.models.registry import register_modelclass activation(nn.ReLU):def __init__(self, dim, act_num=3, deploy=False):super(activation, self).__init__()self.deploy = deployself.weight = torch.nn.Parameter(torch.randn(dim, 1, act_num*2 + 1, act_num*2 + 1))self.bias = Noneself.bn = nn.BatchNorm2d(dim, eps=1e-6)self.dim = dimself.act_num = act_numweight_init.trunc_normal_(self.weight, std=.02)def forward(self, x):if self.deploy:return torch.nn.functional.conv2d(super(activation, self).forward(x), self.weight, self.bias, padding=(self.act_num*2 + 1)//2, groups=self.dim)else:return self.bn(torch.nn.functional.conv2d(super(activation, self).forward(x),self.weight, padding=(self.act_num*2 + 1)//2, groups=self.dim))def _fuse_bn_tensor(self, weight, bn):kernel = weightrunning_mean = bn.running_meanrunning_var = bn.running_vargamma = bn.weightbeta = bn.biaseps = bn.epsstd = (running_var + eps).sqrt()t = (gamma / std).reshape(-1, 1, 1, 1)return kernel * t, beta + (0 - running_mean) * gamma / stddef switch_to_deploy(self):kernel, bias = self._fuse_bn_tensor(self.weight, self.bn)self.weight.data = kernelself.bias = torch.nn.Parameter(torch.zeros(self.dim))self.bias.data = biasself.__delattr__('bn')self.deploy = Trueclass Block(nn.Module):def __init__(self, dim, dim_out, act_num=3, stride=2, deploy=False, ada_pool=None):super().__init__()self.act_learn = 1self.deploy = deployif self.deploy:self.conv = nn.Conv2d(dim, dim_out, kernel_size=1)else:self.conv1 = nn.Sequential(nn.Conv2d(dim, dim, kernel_size=1),nn.BatchNorm2d(dim, eps=1e-6),)self.conv2 = nn.Sequential(nn.Conv2d(dim, dim_out, kernel_size=1),nn.BatchNorm2d(dim_out, eps=1e-6))if not ada_pool:self.pool = nn.Identity() if stride == 1 else nn.MaxPool2d(stride)else:self.pool = nn.Identity() if stride == 1 else nn.AdaptiveMaxPool2d((ada_pool, ada_pool))self.act = activation(dim_out, act_num)def forward(self, x):if self.deploy:x = self.conv(x)else:x = self.conv1(x)x = torch.nn.functional.leaky_relu(x,self.act_learn)x = self.conv2(x)x = self.pool(x)x = self.act(x)return xdef _fuse_bn_tensor(self, conv, bn):kernel = conv.weightbias = conv.biasrunning_mean = bn.running_meanrunning_var = bn.running_vargamma = bn.weightbeta = bn.biaseps = bn.epsstd = (running_var + eps).sqrt()t = (gamma 








:基于亞馬遜云科技的研究分析與實踐)
事務)








