上期介紹了大語言模型的定義和發展歷史,本期將分析基于亞馬遜云科技的大語言模型相關研究方向,以及大語言模型的訓練和構建優化。
大語言模型研究方向分析
Amazon Titan
2023 年 4 月,亞馬遜云科技宣布推出 Amazon Titan 大語言模型。根據其以下官方網站和博客的信息(如下圖所示):一些亞馬遜云科技的客戶已經預覽了亞馬遜全新的 Titan 基礎模型。目前發布的 Amazon Titan 大語言模型主要包括兩個基礎模型:
針對總結、文本生成、分類、開放式問答和信息提取等任務的生成式大語言模型;
文本嵌入(embeddings)大語言模型,能夠將文本輸入(字詞、短語甚至是大篇幅文章)翻譯成包含語義的數字表達(jiembeddings 嵌入編碼)。

雖然這種大語言模型不生成文本,但對個性化推薦和搜索等應用程序卻大有裨益,因為相對于匹配文字,對比編碼可以幫助模型反饋更相關、更符合情境的結果。實際上,Amazon.com 的產品搜索能力就是采用了類似的文本嵌入模型,能夠幫助客戶更好地查找所需的商品。為了持續推動使用負責任AI的最佳實踐,Titan 基礎模型可以識別和刪除客戶提交給定制大語言模型的數據中的有害內容,拒絕用戶輸入不當內容,過濾模型中包含不當內容的輸出結果,如仇恨言論、臟話和語言暴力。
Alpaca: LLM Training LLM
2023 年 3 月 Meta 的?LLaMA 大語言模型發布,該大語言模型對標 GPT-3。已經有許多項目建立在 LLaMA 大語言模型的基礎之上,其中一個著名的項目是 Stanford 的羊駝(Alpaca)大語言模型。Alpaca 基于 LLaMA 大語言模型,是有 70 億參數指令微調的語言 Transformer。Alpaca 沒有使用人工反饋的強化學習(RLHF),而是使用監督學習的方法,其使用了 52k 的指令-輸出對(instruction-output pairs)。
LLaMA 大語言模型:

研究人員沒有使用人類生成的指令-輸出對,而是通過查詢基于 GPT-3 的 text-davinci-003 模型來檢索數據。因此,Alpaca 本質上使用的是一種弱監督(weakly supervised)或以知識蒸餾(knowledge-distillation-flavored)為主的微調。
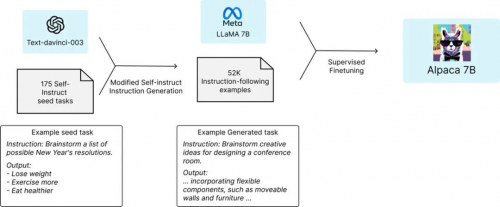
這里值得關注的是羊駝(Alpaca)大語言模型的訓練數據,是通過查詢 GPT-3 大語言模型獲得的。通俗地來說,這是“用 LLM 來訓練 LLM”,或者稱之為“用 AI 來訓練 AI”。我覺得大多數人可能低估了這件事情對人類社會影響的意義,我覺得其意義非凡。這意味著:AI 之間的相互學習成長這件事,已經開始了。很多年后,當我們回望 AI 世代的演進史,這件事也許會是一個重要的時間節點。
PaLM-E: Multimodality
在 2023 年 3 月,PaLM-E 大語言模型發布,展示了在大語言模型和多模態數據模式(multimodality)融合的一些最新進展。這是大語言模型的另一個重要趨勢:通過視覺、多模態和多任務訓練來擴展能力。

如以上論文中的圖示,PaLM-E 大語言模型是一種用于具體推理任務、視覺語言任務和語言任務的單一通用多模態大語言模型。PaLM-E 大語言模型對多模態句子進行操作,即一系列標記,其中來自任意模式(例如圖像、神經三維表示或狀態,綠色和藍色)的輸入與文本標記(橙色)一起插入,作為 LLM 的輸入,經過端到端訓練。

該論文展示了 PaLM-E 在三個不同的機器人領域做遷移學習的測試結果對比圖。使用 PaLM-E 、ViT 預訓練、機器人和視覺語言的混合數據組合,與僅對相應的域內數據進行訓練相比,有顯著的性能提升。
值得注意的是,PaLM-E 繼續被訓練為一個完全基于解碼器的 LLM,它根據給定的前綴或提示自回歸生成文本補全。那么,它們如何啟用狀態表征或者圖像的輸入呢?他們對網絡進行了預訓練以將其編碼為 embeddings。對于圖像,他們使用 4B 和 22B 參數的視覺 Transformer (ViT) 來生成嵌入向量;然后對這些嵌入向量進行線性投影,以匹配單詞令牌嵌入的嵌入維度。
在訓練過程中,為了形成多模態的句子,他們首先使用特殊標記 Tokens,例如:<img1>、<img2> 等,然后將其與嵌入的圖像交換(類似于通過嵌入層嵌入單詞標記的方式)。

一些第三方領域學者對其論文和展示的性能提升也做了分析,如上圖所示。使用 PaLM-E 、ViT 預訓練、機器人和視覺語言的混合數據組合進行聯合訓練,與針對單個任務的訓練模型相比,可以實現兩倍以上的性能提升。
大語言模型的訓練和構建優化
訓練大語言模型的挑戰
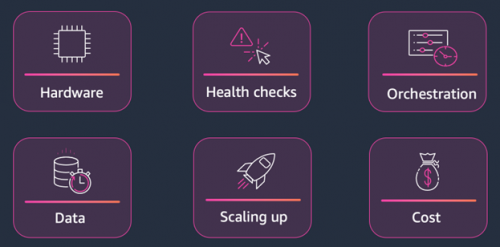
訓練大語言模型涉及許多挑戰。這些挑戰概括來說,大致來自于六個方面,如下圖示:
硬件(Hardware)
健康檢查(Health Checks)
編排(Orchestration)
數據(Data)
規模擴展(Scaling up)
成本考慮(Cost)
首先是硬件。你想使用最新的硬件。最新的硬件通常可以讓你在各種基準測試中獲得更好的性能,因此,如果這些大語言模型需要數周或數月的時間來訓練,而你沒有利用最新硬件的性能優勢,那么你將無法訓練大語言模型以獲得最適合你的用例的結果。
第二個是健康檢查。您需要確保硬件運行良好,以便最大限度地減少大語言模型訓練期間的干擾。
我們還需要考慮編排,啟動集群,關閉集群,確保網絡和安全配置運行良好,機器學習團隊在運行各種工作負載時不會相互干擾。
我們需要考慮的其他事情是大數據集。存儲、處理和加載它們以進行機器學習訓練并不是一件容易的事,并且可能需要大量的開發工作才能高效完成。
我們擴大基礎設施的規模并設計算法以繞過基礎設施的局限性是另一個挑戰。我們今天談論的大語言模型通常不適用于單個 GPU,因此你必須考慮如何將該大語言模型拆分到 GPU 上。
最后,我們必須考慮成本。這些大語言模型的訓練成本可能高達數十萬甚至數百萬美元。所以,你想很好地利用機器學習團隊的時間。與其讓他們在基礎架構上工作,他們可以專注于嘗試新的大語言模型創意,這樣您的企業就可以利用該大語言模型取得最佳結果。
大語言模型的構建優化
幸運的是,Amazon SageMaker 可以幫助你應對所有這些挑戰,從而加速大語言模型的訓練。現在,Amazon SageMaker 可幫助您使用托管基礎設施、工具和工作流程為任何用例構建、訓練和部署機器學習模型。如下圖所示。
下圖中黃色的部分,例如:Amazon SageMaker 分布式訓練庫、Amazon SageMaker 訓練編譯優化等,我們還會在下一篇的動手實驗部分,用完整的代碼來演繹實現,讓你有更身臨其境的感受。

在下層,我們有基礎設施,Amazon SageMaker 可讓你訪問最新的硬件,包括 GPU 和 Trainium,以及實例之間的快速網絡互連,這對于分發訓練至關重要。
在中間層,有托管基礎設施和工具的能力。
Amazon SageMaker 會為你處理大規模集群編排,它加速了集群,最后它會向下旋轉。它有助于完成所有這些安全和網絡配置,因此你可以輕松保護客戶數據和 IP 的安全。
在訓練工作開始時還會進行健康檢查,以確保硬件有效運行,減少對訓練工作的干擾。編排還意味著你只需為所用的計算資源付費。你只需要在集群啟動時付費,為你訓練大語言模型,這樣你就不必全天候為所有昂貴的硬件付費。
還有用于分析、調試和監控實驗的工具,以及使用各種策略進行超參數優化的工具,以確保獲得盡可能好的大語言模型。
在頂層,有針對云端進行了優化的框架和庫,例如在 Amazon SageMaker 上非常易于使用的 PyTorch、TensorFlow 和 Hugging Face,以及可幫助你處理超大型數據集或超大語言模型的 Amazon SageMaker 分布式訓練庫。
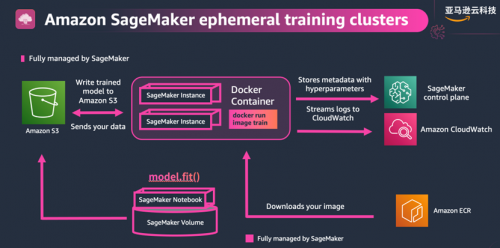
我已經談了很多使用 Amazon SageMaker 進行訓練的能力和好處,讓我們來談談它是如何運作的。訓練大語言模型,我們需要一些計算資源,然后在某些數據集上運行我們編寫的訓練代碼。Amazon SageMaker 做到這一點的方法是:通過啟動短暫的訓練集群來完成任務。
當提交訓練作業時,Amazon SageMaker 將根據你選擇的集群配置啟動集群。它將從 ECR 加載訓練代碼,從 S3 加載數據,然后開始訓練。訓練過程中,它會將日志和指標輸出到 CloudWatch,將大語言模型檢查點(checkpoint)同步到 S3,并在任務結束時關閉集群。如果你編寫的代碼考慮了具有彈性,編寫成能夠從檢查點自動恢復,則你的訓練作業將無需手動干預即可自動重啟。
以下是用于開始訓練作業的核心代碼,即 estimator API:
from sagemaker.pytorch import PyTorch
estimator = PyTorch(entry_point = ‘./cifar10.py’,
role = role,
framework_version = ‘1.13’,
py_version = ‘py38’,
instance_count = 1,
instance_type = ‘ml.g5.xlarge’,
hyperparameters = {‘epochs’: 50, ‘batch_size’: 32},
metric_definitions = [{‘Name’: ‘train:loss’, ‘Regex’: ‘loss: (.*)’}]
estimator.fit(“s3://bucket/path/to/training/data”)
這里選擇了 PyTorch 估算器,并定義了入口點的函數文件:cifar10.py。這與我們在自己的本地電腦上運行用于訓練大語言模型的腳本非常相似,我們稱之為腳本模式。使用 Amazon SageMaker 訓練作業的方法有很多,靈活性更強,你可以提供自己的 docker 容器或一些內置算法。
然后定義想要使用的框架和 Python 版本,以及訓練作業的實例類型、實例數量和超參數。你現在可以隨時輕松更改這些內容,啟動其他訓練任務來嘗試不同的實例類型,看看哪種硬件最適合你的用例。
接下來將給出指標定義。這將告訴 Amazon SageMaker 如何解析從腳本中輸出的日志,Amazon SageMaker 會將這些指標發送到 CloudWatch,供你稍后查看。
?最后調用 estimator.fit(),其中包含訓練數據的路徑。
事務)


















