斯坦福大學的FlashFFTConv優化了擴展序列的快速傅里葉變換(FFT)卷積。該方法引入Monarch分解,在FLOP和I/O成本之間取得平衡,提高模型質量和效率。并且優于PyTorch和FlashAttention-v2。它可以處理更長的序列,并在人工智能應用程序中打開新的可能性。
處理長序列的效率一直是機器學習領域的一個挑戰。卷積神經網絡(cnn)最近作為序列建模的關鍵工具獲得了突出的地位,在從自然語言處理到計算機視覺和遺傳學的各個領域都提供了一流的性能。盡管卷積序列模型具有卓越的品質,但在速度方面仍落后于Transformers 。
快速傅里葉變換(FFT)卷積算法,通過在頻域內計算輸入序列和核之間的卷積,可以解決上面卷積的問題。但是FFT卷積在執行時間方面有非常大的問題。
斯坦福大學的研究人員正在努力優化現代FFT卷積方法:
為較短序列優化FFT卷積是一種常見的做法,涉及跨多個批次重用內核濾波器和FFT的預計算。這種方法允許跨批處理和核的并行化,而核融合使中間卷積輸出能夠被有效地緩存。
但是隨著序列長度的增長,出現了兩個主要障礙。1、FFT卷積不能充分利用當代加速器中專用的矩陣-矩陣乘法單元。2、當序列超過SRAM的容量時,核融合因為需要昂貴的I/O操作變得不切實際。
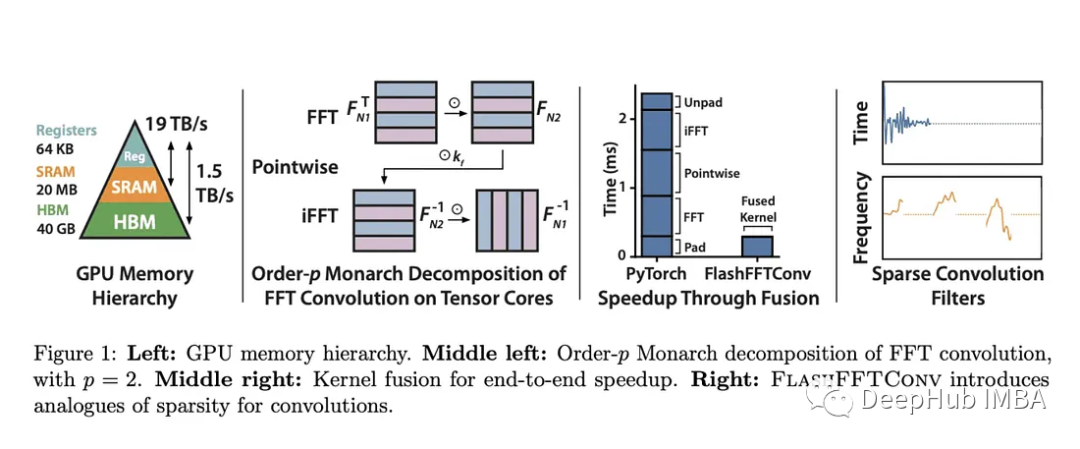
而斯坦福大學的研究人員引入了FlashFFTConv,利用FFT的Monarch分解來優化擴展序列的卷積。這種分解將FFT重新想象為一系列矩陣-矩陣乘法運算,并選擇分解順序,表示為“p”。
這項研究提供了使用基于序列長度的直接成本模型來優化GPU中FLOP和I/O成本的“p”的見解。這種分解不僅有利于較長序列的核融合,而且還減少了必須駐留在SRAM中的序列數據量。FlashFFTConv可以有效地處理從256到驚人的400萬個字符的序列。FlashFFTConv利用實值FFT算法并優化零填充輸入的矩陣乘法操作,可以將FFT操作長度減少高達50%。
此外,FlashFFTConv還提供了一個通用的框架:部分卷積和頻率稀疏卷積。這些技術類似于Transformers中的稀疏和近似注意力機制,可以顯著降低內存使用和運行時間。
FlashFFTConv加速FFT卷積,可以提高卷積序列模型的質量和效率。對于相同的計算,它還可以實現指標的改進,例如Hyena-GPT-s的perplexity降低2.3,M2-BERT-base的平均GLUE分數提高3.3。這種性能提升類似于將模型的參數大小增加一倍。
FlashFFTConv在效率方面也很出色,與PyTorch相比,它提供了高達7.93倍的效率和高達5.6倍的內存節省。并且這些效率的提高在很長的序列長度范圍內都持續存在。由于降低了FLOP成本,它在2K或更長時間序列的計算時間上超過了FlashAttention-v2,實現了高達62.3%的端到端FLOP使用率。
FlashFFTConv使模型能夠處理更長的序列,打破了以前認為不可逾越的障礙。它已經完成了Path-512任務,這是一項序列長度為256K的高分辨率圖像分類任務,并使用部分卷積將HyenaDNA擴展到驚人的400萬序列長度。
斯坦福大學的FlashFFTConv在優化長序列的FFT卷積方面取得了非常巨大的進步。這項突破性技術有望重塑卷積序列模型的格局,提高它們的質量和效率。
以下是一些相關的信息:
https://avoid.overfit.cn/post/de29ba25d1c94218b1c9da494b5e58c3






:基于亞馬遜云科技的研究分析與實踐)
事務)











