介紹
2021 年,我使用 GPT 模型編寫了最初的幾行代碼,那時我意識到文本生成已經達到了拐點。我要求 GPT-3 總結一份很長的文檔,并嘗試了幾次提示。我可以看到結果比以前的模型先進得多,這讓我對這項技術感到興奮,并渴望了解它是如何實現的。現在,后續的 GPT-3.5、ChatGPT 和 GPT-4 模型正在迅速獲得廣泛采用,該領域的更多人也對它們的工作原理感到好奇。雖然其內部工作細節是專有且復雜的,但所有 GPT 模型都共享一些不難理解的基本思想。
生成語言模型如何工作
讓我們首先探討生成語言模型的工作原理。最基本的想法如下:它們將n 個標記作為輸入,并產生一個標記作為輸出。

這看起來是一個相當簡單的概念,但為了真正理解它,我們需要知道令牌是什么。
令牌是一段文本。在 OpenAI GPT 模型的上下文中,常見單詞和短單詞通常對應于單個標記,例如下圖中的單詞“We”。長且不常用的單詞通常被分成幾個標記。例如,下圖中的“擬人化”一詞被分解為三個標記。像“ChatGPT”這樣的縮寫可以用單個標記表示,也可以分為多個標記,具體取決于字母一起出現的常見程度。您可以轉到 OpenAI 的Tokenizer 頁面,輸入文本,然后查看它如何拆分為標記。您可以選擇用于文本的“GPT-3”標記化和用于代碼的“Codex”標記化。我們將保留默認的“GPT-3”設置。

您還可以使用 OpenAI 的開源tiktoken庫使用 Python 代碼進行代幣化。OpenAI 提供了幾種不同的標記器,每個標記器的行為都略有不同。在下面的代碼中,我們使用“davinci”(GPT-3 模型)的分詞器來匹配您使用 UI 看到的行為。
import tiktoken# Get the encoding for the davinci GPT3 model, which is the "r50k_base" encoding.
encoding = tiktoken.encoding_for_model("davinci")text = "We need to stop anthropomorphizing ChatGPT."
print(f"text: {text}")token_integers = encoding.encode(text)
print(f"total number of tokens: {encoding.n_vocab}")print(f"token integers: {token_integers}")
token_strings = [encoding.decode_single_token_bytes(token) for token in token_integers]
print(f"token strings: {token_strings}")
print(f"number of tokens in text: {len(token_integers)}")encoded_decoded_text = encoding.decode(token_integers)
print(f"encoded-decoded text: {encoded_decoded_text}")text: We need to stop anthropomorphizing ChatGPT.
total number of tokens: 50257
token integers: [1135, 761, 284, 2245, 17911, 25831, 2890, 24101, 38, 11571, 13]
token strings: [b'We', b' need', b' to', b' stop', b' anthrop', b'omorph', b'izing', b' Chat', b'G', b'PT', b'.']
number of tokens in text: 11
encoded-decoded text: We need to stop anthropomorphizing ChatGPT.您可以在代碼的輸出中看到,此標記生成器包含 50,257 個不同的標記,并且每個標記在內部映射到一個整數索引。給定一個字符串,我們可以將其拆分為整數標記,然后將這些整數轉換為它們對應的字符序列。對字符串進行編碼和解碼應該始終返回原始字符串。
這讓您對 OpenAI 標記器的工作原理有一個很好的直覺,但您可能想知道為什么他們選擇這些標記長度。讓我們考慮一些其他標記化選項。假設我們嘗試最簡單的實現,其中每個字母都是一個標記。這使得將文本分解為標記變得很容易,并使不同標記的總數保持較小。然而,我們無法編碼與 OpenAI 方法中一樣多的信息。如果我們在上面的示例中使用基于字母的標記,則 11 個標記只能編碼“We need to”,而 OpenAI 的 11 個標記可以編碼整個句子。事實證明,當前的語言模型對它們可以接收的最大令牌數量有限制。因此,我們希望在每個 token 中包含盡可能多的信息。
現在讓我們考慮每個單詞都是一個標記的場景。與 OpenAI 的方法相比,我們只需要 7 個 token 就可以表示同一個句子,這似乎更高效。按字拆分也很容易實現。然而,語言模型需要有一個完整的可能遇到的標記列表,而這對于整個單詞來說是不可行的——不僅因為字典中有太多單詞,而且因為很難跟上領域的步伐——特定術語和發明的任何新詞。
因此,OpenAI 選擇介于這兩個極端之間的解決方案也就不足為奇了。其他公司也發布了遵循類似方法的標記器,例如Google 的Sentence Piece 。
現在我們對令牌有了更好的理解,讓我們回到原來的圖表,看看我們是否可以更好地理解它。生成模型采用n 個標記,這些標記可以是幾個單詞、幾個段落或幾頁。他們產生一個單一的標記,它可以是一個短單詞或單詞的一部分。
現在這更有意義了。
但如果您使用過OpenAI 的 ChatGPT,您就會知道它會生成許多令牌,而不僅僅是單個令牌。這是因為這個基本思想應用于擴展窗口模式。你給它n 個令牌,它會產生一個令牌輸出,然后它將該輸出令牌合并為下一次迭代的輸入的一部分,產生一個新的令牌輸出,依此類推。此模式不斷重復,直到達到停止條件,表明它已完成生成您需要的所有文本。
例如,如果我輸入“We need to”作為模型的輸入,算法可能會產生如下所示的結果:

在使用 ChatGPT 時,您可能還注意到該模型不是確定性的:如果您兩次問完全相同的問題,您可能會得到兩個不同的答案。這是因為該模型實際上并沒有生成單個預測標記;而是生成了單個預測標記。相反,它返回所有可能標記的概率分布。換句話說,它返回一個向量,其中每個條目表示選擇特定標記的概率。然后,模型從該分布中采樣以生成輸出令牌。

該模型是如何得出該概率分布的?這就是訓練階段的目的。在訓練期間,模型會接觸大量文本,并且在給定輸入標記序列的情況下,調整其權重以預測良好的概率分布。GPT 模型是通過大部分互聯網進行訓練的,因此它們的預測反映了它們所看到的信息的混合。
您現在對生成模型背后的想法有了很好的理解。請注意,我只是解釋了這個想法,但還沒有給你一個算法。事實證明,這個想法已經存在了幾十年,并且多年來已經使用幾種不同的算法來實現。接下來我們將看看其中一些算法。
生成語言模型簡史
隱馬爾可夫模型 (HMM) 在 20 世紀 70 年代開始流行。它們的內部表示對句子(名詞、動詞等)的語法結構進行編碼,并在預測新單詞時使用這些知識。然而,由于它們是馬爾可夫過程,因此在生成新令牌時僅考慮最新的令牌。因此,他們實現了“?n 個令牌輸入,一個令牌輸出”思想的非常簡單的版本,其中n?= 1。因此,它們不會生成非常復雜的輸出。讓我們考慮以下示例:

如果我們將“The Quick Brown Fox Jumps Over the”輸入到語言模型中,我們會期望它返回“Lazy”。然而,隱馬爾可夫模型只會看到最后一個標記“the”,并且信息如此之少,它不太可能給出我們期望的預測。當人們嘗試 HMM 時,很明顯語言模型需要支持多個輸入標記才能生成良好的輸出。當人們嘗試 HMM 時,很明顯語言模型需要支持多個輸入標記才能生成良好的輸出。
N-gram 在 20 世紀 90 年代變得流行,因為它們通過采用多個標記作為輸入來解決 HMM 的主要限制。對于前面的示例,n-gram 模型在預測“lazy”這個詞方面可能會做得很好。
n-gram 最簡單的實現是具有基于字符的標記的二元語法,它給定單個字符,能夠預測序列中的下一個字符。您只需幾行代碼即可創建其中一個,我鼓勵您嘗試一下。首先,計算訓練文本中不同字符的數量(我們稱之為n),并創建一個用零初始化的nxn二維矩陣。通過選擇與第一個字符對應的行和與第二個字符對應的列,每對輸入字符可用于定位該矩陣中的特定條目。當您解析訓練數據時,對于每一對字符,您只需將一個添加到相應的矩陣單元中即可。例如,如果您的訓練數據包含單詞“car”,您可以向“c”行和“a”列中的單元格添加 1,然后向“a”行和“r”中的單元格添加 1柱子。累積所有訓練數據的計數后,通過將每個單元格除以該行的總數,將每一行轉換為概率分布。
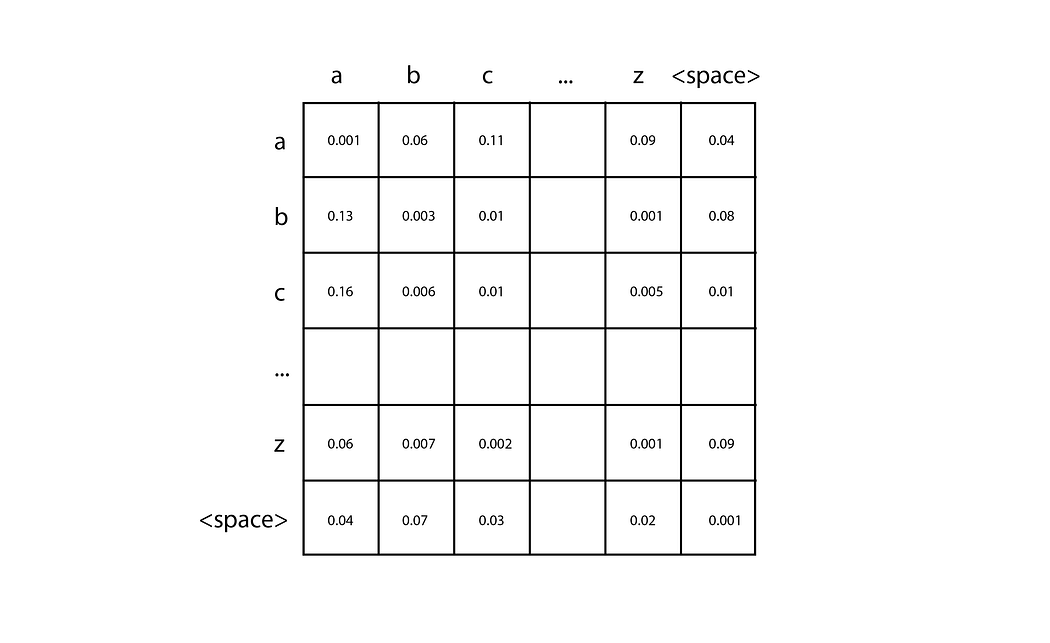
然后,為了進行預測,您需要給它一個單個字符來開始,例如“c”。您查找與“c”行相對應的概率分布,并對該分布進行采樣以生成下一個字符。然后,您將生成的角色重復該過程,直到達到停止條件。高階 n 元語法遵循相同的基本思想,但它們能夠通過使用 n 維張量來查看更長的輸入標記序列。
N 元語法很容易實現。然而,由于矩陣的大小隨著輸入標記數量的增加而呈指數增長,因此它們不能很好地擴展到更大數量的標記。并且僅使用幾個輸入標記,他們就無法產生良好的結果。需要一種新技術來繼續在這一領域取得進展。
在 2000 年代,循環神經網絡 (RNN) 變得非常流行,因為它們能夠接受比以前的技術更多數量的輸入標記。特別是,LSTM 和 GRU(RNN 的類型)得到了廣泛應用,并被證明能夠產生相當好的結果。
RNN 是一種神經網絡,但與傳統的前饋神經網絡不同,它們的架構可以適應接受任意數量的輸入并產生任意數量的輸出。例如,如果我們向 RNN 提供輸入標記“We”、“need”和“to”,并希望它生成更多標記直到達到完整點,則 RNN 可能具有以下結構:

上述結構中的每個節點都具有相同的權重。您可以將其視為連接到自身并重復執行的單個節點(因此稱為“循環”),或者您可以將其視為上圖所示的擴展形式。與基本 RNN 相比,LSTM 和 GRU 添加的一項關鍵功能是存在從一個節點傳遞到下一個節點的內部存儲單元。這使得后面的節點能夠記住前面節點的某些方面,這對于做出良好的文本預測至關重要。
然而,RNN 在處理很長的文本序列時存在不穩定問題。模型中的梯度往往呈指數增長(稱為“梯度爆炸”)或減小到零(稱為“梯度消失”),從而阻止模型繼續從訓練數據中學習。LSTM 和 GRU 可以緩解梯度消失問題,但不能完全阻止它。因此,盡管理論上它們的架構允許任意長度的輸入,但實際上該長度存在限制。文本生成的質量再次受到算法支持的輸入標記數量的限制,需要新的突破。
2017年,Google發布了介紹Transformers的論文,我們進入了文本生成的新時代。Transformers 中使用的架構允許輸入令牌數量大幅增加,消除了 RNN 中出現的梯度不穩定問題,并且具有高度并行性,這意味著它能夠利用 GPU 的強大功能。Transformer 如今已被廣泛使用,OpenAI 選擇將其用于最新的 GPT 文本生成模型。
Transformer 基于“注意力機制”,該機制允許模型比其他輸入更多地關注某些輸入,無論它們出現在輸入序列中的位置。例如,讓我們考慮以下句子:

在這種情況下,當模型預測動詞“買”時,它需要匹配動詞“去”的過去時。為了做到這一點,它必須非常關注“去”這個令牌。事實上,它可能更關注標記“went”而不是標記“and”,盡管“went”在輸入序列中出現得更早。
GPT 模型中的這種選擇性注意力行為是由 2017 年論文中的一個新穎想法實現的:使用“屏蔽多頭注意力”層。讓我們分解這個術語,并深入研究它的每個子術語:
Attention:“注意力”層包含一個權重矩陣,表示輸入句子中所有標記位置對之間的關??系強度。這些權重是在訓練期間學習的。如果一對位置對應的權重很大,那么這些位置上的兩個代幣相互影響很大。這種機制使 Transfomer 能夠比其他標記更加關注某些標記,無論它們出現在句子中的哪個位置。
Masked:如果矩陣僅限于每個標記位置與輸入中較早位置之間的關系,則注意力層將被“屏蔽”。這就是 GPT 模型用于文本生成的方法,因為輸出標記只能依賴于它之前的標記。
Multi-head:Transformer 使用屏蔽的“多頭”注意層,因為它包含多個并行操作的屏蔽注意層。
LSTM 和 GRU 的記憶單元還使后面的 token 能夠記住早期 token 的某些方面。然而,如果兩個相關的令牌相距很遠,梯度問題可能會產生阻礙。Transformer 不存在這個問題,因為每個令牌都與其之前的所有其他令牌有直接連接。
現在您已經了解了 GPT 模型中使用的 Transformer 架構的主要思想,接下來我們來看看目前可用的各種 GPT 模型之間的區別。
不同的GPT模型是如何實現的
截至撰寫本文時,OpenAI 最新發布的三個文本生成模型是 GPT-3.5、ChatGPT 和 GPT-4,它們均基于 Transformer 架構。事實上,“GPT”代表“生成式預訓練變壓器”。
GPT-3.5 是一個被訓練為補全式模型的轉換器,這意味著如果我們給它一些單詞作為輸入,它能夠生成更多可能在訓練數據中跟隨它們的單詞。
另一方面,ChatGPT 被訓練為對話式模型,這意味著當我們像進行對話一樣與它進行交流時,它的性能最佳。它基于與 GPT-3.5 相同的變壓器基礎模型,但它根據對話數據進行了微調。然后使用人類反饋強化學習 (RLHF) 對其進行進一步微調,這是 OpenAI 在其2022 年 InstructGPT 論文中引入的一項技術。在這種技術中,我們給模型兩次相同的輸入,得到兩個不同的輸出,然后詢問人類排名者它更喜歡哪個輸出。然后使用該選擇通過微調來改進模型。這項技術使模型的輸出與人類期望保持一致,這對于 OpenAI 最新模型的成功至關重要。
另一方面,GPT-4 既可以用于補全,也可以用于對話,并且擁有自己的全新基礎模型。該基本模型還使用 RLHF 進行了微調,以更好地符合人類期望。
編寫使用 GPT 模型的代碼
兩者之間的主要區別在于 Azure 提供了以下附加功能:
- 自動化、負責任的 AI 過濾器可減少 API 的不道德使用
- Azure 的安全功能,例如專用網絡
- 區域可用性,在與 API 交互時獲得最佳性能
如果您正在編寫使用這些模型的代碼,則需要選擇要使用的特定版本。以下是 Azure OpenAI 服務中當前可用版本的快速備忘單:
- GPT-3.5:文本-davinci-002,文本-davinci-003
- ChatGPT:gpt-35-turbo
- GPT-4:gpt-4、gpt-4–32k
兩個 GPT-4 版本的主要區別在于它們支持的令牌數量:gpt-4 支持 8,000 個令牌,gpt-4–32k 支持 32,000 個令牌。相比之下,GPT-3.5 模型僅支持 4,000 個代幣。
由于 GPT-4 是目前最昂貴的選項,因此最好從其他型號之一開始,僅在需要時進行升級。有關這些模型的更多詳細信息,請查看文檔。
結論
在本文中,我們介紹了所有生成語言模型的共同基本原理,特別是 OpenAI 最新 GPT 模型的獨特之處。
一路上,我們強調了語言模型的核心思想:“?n 個令牌輸入,一個令牌輸出”。我們探討了代幣是如何分解的,以及為什么要這樣分解。我們追溯了語言模型數十年的演變,從早期的隱馬爾可夫模型到最近基于 Transformer 的模型。最后,我們描述了 OpenAI 的三個最新的基于 Transformer 的 GPT 模型、每個模型的實現方式以及如何編寫使用它們的代碼。
到目前為止,您應該已經做好了充分準備,可以就 GPT 模型進行知情對話,并開始在自己的編碼項目中使用它們。我計劃寫更多關于語言模型的解釋,所以請關注我,讓我知道您希望看到哪些主題!感謝您的閱讀!






)





)






