Redis持久化
RDB快照(snapshot)
在默認情況下, Redis 將內存數據庫快照保存在名字為?dump.rdb?的二進制文件中。
你可以對 Redis 進行設置, 讓它在“?N?秒內數據集至少有?M?個改動”這一條件被滿足時, 自動保存一次數據集。
比如說, 以下設置會讓 Redis 在滿足“?60?秒內有至少有?1000?個鍵被改動”這一條件時, 自動保存一次數據集:
# save 60 1000 //關閉RDB只需要將所有的save保存策略注釋掉即可
還可以手動執行命令生成RDB快照,進入redis客戶端執行命令save或bgsave可以生成dump.rdb文件,每次命令執行都會將所有redis內存快照到一個新的rdb文件里,并覆蓋原有rdb快照文件。
bgsave的寫時復制(COW)機制
Redis 借助操作系統提供的寫時復制技術(Copy-On-Write, COW),在生成快照的同時,依然可以正常處理寫命令。簡單來說,bgsave 子進程是由主線程 fork 生成的,可以共享主線程的所有內存數據。bgsave 子進程運行后,開始讀取主線程的內存數據,并把它們寫入 RDB 文件。此時,如果主線程對這些數據也都是讀操作,那么,主線程和 bgsave 子進程相互不影響。但是,如果主線程要修改一塊數據,那么,這塊數據就會被復制一份,生成該數據的副本。然后,bgsave 子進程會把這個副本數據寫入 RDB 文件,而在這個過程中,主線程仍然可以直接修改原來的數據。
save與bgsave對比:
| 命令 | save | bgsave |
| IO類型 | 同步 | 異步 |
| 是否阻塞redis其它命令 | 是 | 否(在生成子進程執行調用fork函數時會有短暫阻塞) |
| 復雜度 | O(n) | O(n) |
| 優點 | 不會消耗額外內存 | 不阻塞客戶端命令 |
| 缺點 | 阻塞客戶端命令 | 需要fork子進程,消耗內存 |
配置自動生成rdb文件后臺使用的是bgsave方式。
AOF(append-only file)
快照功能并不是非常耐久(durable): 如果 Redis 因為某些原因而造成故障停機, 那么服務器將丟失最近寫入、且仍未保存到快照中的那些數據。從 1.1 版本開始, Redis 增加了一種完全耐久的持久化方式: AOF 持久化,將修改的每一條指令記錄進文件appendonly.aof中(先寫入os cache,每隔一段時間fsync到磁盤)
比如執行命令“set hangzhou666”,aof文件里會記錄如下數據
*3
$3
set
$5
hangzhou
$3
666這是一種resp協議格式數據,星號后面的數字代表命令有多少個參數,$號后面的數字代表這個參數有幾個字符
注意,如果執行帶過期時間的set命令,aof文件里記錄的是并不是執行的原始命令,而是記錄key過期的時間戳
比如執行“set hangzhou 888 ex 1000”,對應aof文件里記錄如下
*3
$3
set
$6
hangzhou
$3
888
*3
$9
PEXPIREAT
$6
hangzhou
$13
1604249786301你可以通過修改配置文件來打開 AOF 功能:
# appendonly yes
從現在開始, 每當 Redis 執行一個改變數據集的命令時(比如?SET), 這個命令就會被追加到 AOF 文件的末尾。
這樣的話, 當 Redis 重新啟動時, 程序就可以通過重新執行 AOF 文件中的命令來達到重建數據集的目的。
你可以配置 Redis 多久才將數據?fsync?到磁盤一次。
有三個選項:
appendfsync always:每次有新命令追加到 AOF 文件時就執行一次?fsync?,非常慢,也非常安全。
appendfsync everysec:每秒?fsync?一次,足夠快,并且在故障時只會丟失 1 秒鐘的數據。
appendfsync no:從不?fsync?,將數據交給操作系統來處理。更快,也更不安全的選擇。
推薦(并且也是默認)的措施為每秒?fsync?一次, 這種?fsync?策略可以兼顧速度和安全性。
AOF重寫
AOF文件里可能有太多沒用指令,所以AOF會定期根據內存的最新數據生成aof文件
例如,執行了如下幾條命令:
127.0.0.1:6379> incr readcount
(integer) 1
127.0.0.1:6379> incr readcount
(integer) 2
127.0.0.1:6379> incr readcount
(integer) 3
127.0.0.1:6379> incr readcount
(integer) 4
127.0.0.1:6379> incr readcount
(integer) 5重寫后AOF文件里變成
*3
$3
SET
$2
readcount
$1
5如下兩個配置可以控制AOF自動重寫頻率
# auto-aof-rewrite-min-size 64mb //aof文件至少要達到64M才會自動重寫,文件太小恢復速度本來就很快,重寫的意義不大# auto-aof-rewrite-percentage 100 //aof文件自上一次重寫后文件大小增長了100%則再次觸發重寫當然AOF還可以手動重寫,進入redis客戶端執行命令bgrewriteaof重寫AOF
注意,AOF重寫redis會fork出一個子進程去做(與bgsave命令類似),不會對redis正常命令處理有太多影響
RDB 和 AOF ,我應該用哪一個?
| 命令 | RDB | AOF |
| 啟動優先級 | 低 | 高 |
| 體積 | 小 | 大 |
| 恢復速度 | 快 | 慢 |
| 數據安全性 | 容易丟數據 | 根據策略決定 |
生產環境可以都啟用,redis啟動時如果既有rdb文件又有aof文件則優先選擇aof文件恢復數據,因為aof一般來說數據更全一點。
Redis 4.0 混合持久化
????????重啟 Redis 時,我們很少使用 RDB來恢復內存狀態,因為會丟失大量數據。我們通常使用 AOF 日志重放,但是重放 AOF 日志性能相對 RDB來說要慢很多,這樣在 Redis 實例很大的情況下,啟動需要花費很長的時間。 Redis 4.0 為了解決這個問題,帶來了一個新的持久化選項——混合持久化。
通過如下配置可以開啟混合持久化(必須先開啟aof):
# aof-use-rdb-preamble yes????????如果開啟了混合持久化,AOF在重寫時,不再是單純將內存數據轉換為RESP命令寫入AOF文件,而是將重寫這一刻之前的內存做RDB快照處理,并且將RDB快照內容和增量的AOF修改內存數據的命令存在一起,都寫入新的AOF文件,新的文件一開始不叫appendonly.aof,等到重寫完新的AOF文件才會進行改名,覆蓋原有的AOF文件,完成新舊兩個AOF文件的替換。
????????于是在 Redis 重啟的時候,可以先加載 RDB 的內容,然后再重放增量 AOF 日志就可以完全替代之前的 AOF 全量文件重放,因此重啟效率大幅得到提升。
混合持久化AOF文件結構如下

?Redis數據備份策略:
- 寫crontab定時調度腳本,每小時都copy一份rdb或aof的備份到一個目錄中去,僅僅保留最近48小時的備份
- 每天都保留一份當日的數據備份到一個目錄中去,可以保留最近1個月的備份
- 每次copy備份的時候,都把太舊的備份給刪了
- 每天晚上將當前機器上的備份復制一份到其他機器上,以防機器損壞
Redis主從架構

redis主從架構搭建,配置從節點步驟:
1、復制一份redis.conf文件2、將相關配置修改為如下值:
port 6380
pidfile /var/run/redis_6380.pid # 把pid進程號寫入pidfile配置的文件
logfile "6380.log"
dir /usr/local/redis-5.0.3/data/6380 # 指定數據存放目錄
# 需要注釋掉bind
# bind 127.0.0.1(bind綁定的是自己機器網卡的ip,如果有多塊網卡可以配多個ip,代表允許客戶端通過機器的哪些網卡ip去訪問,內網一般可以不配置bind,注釋掉即可)3、配置主從復制
replicaof 192.168.0.60 6379 # 從本機6379的redis實例復制數據,Redis 5.0之前使用slaveof
replica-read-only yes # 配置從節點只讀4、啟動從節點
redis-server redis.conf # redis.conf文件務必用你復制并修改了之后的redis.conf文件5、連接從節點
redis-cli -p 63806、測試在6379實例上寫數據,6380實例是否能及時同步新修改數據7、可以自己再配置一個6381的從節點Redis主從工作原理
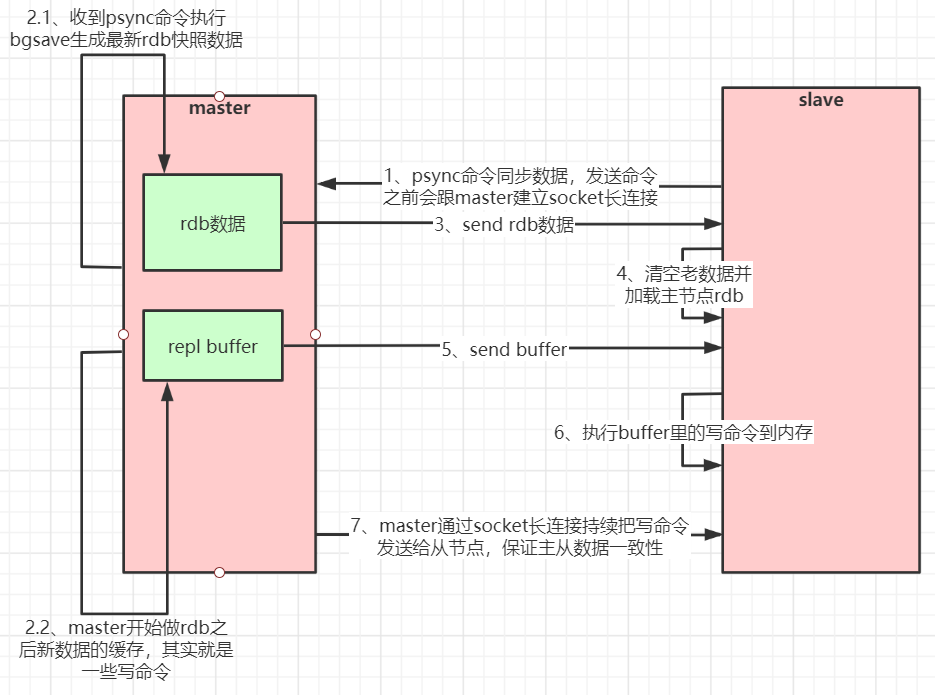
????????如果你為master配置了一個slave,不管這個slave是否是第一次連接上Master,它都會發送一個PSYNC命令給master請求復制數據。
????????master收到PSYNC命令后,會在后臺進行數據持久化通過bgsave生成最新的rdb快照文件,持久化期間,master會繼續接收客戶端的請求,它會把這些可能修改數據集的請求緩存在內存中。當持久化進行完畢以后,master會把這份rdb文件數據集發送給slave,slave會把接收到的數據進行持久化生成rdb,然后再加載到內存中。然后,master再將之前緩存在內存中的命令發送給slave。
????????當master與slave之間的連接由于某些原因而斷開時,slave能夠自動重連Master,如果master收到了多個slave并發連接請求,它只會進行一次持久化,而不是一個連接一次,然后再把這一份持久化的數據發送給多個并發連接的slave。
主從復制(全量復制)流程圖:
數據部分復制
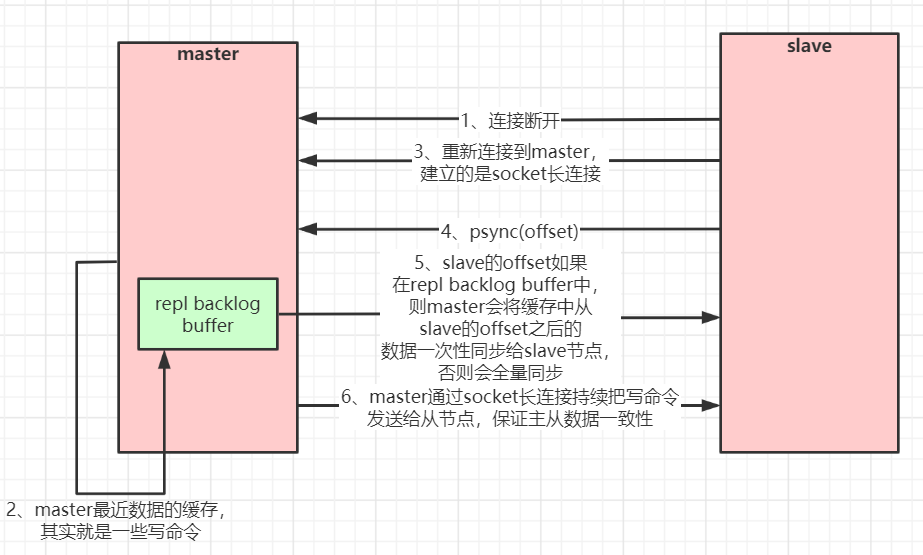
當master和slave斷開重連后,一般都會對整份數據進行復制。但從redis2.8版本開始,redis改用可以支持部分數據復制的命令PSYNC去master同步數據,slave與master能夠在網絡連接斷開重連后只進行部分數據復制(斷點續傳)。
master會在其內存中創建一個復制數據用的緩存隊列,緩存最近一段時間的數據,master和它所有的slave都維護了復制的數據下標offset和master的進程id,因此,當網絡連接斷開后,slave會請求master繼續進行未完成的復制,從所記錄的數據下標開始。如果master進程id變化了,或者從節點數據下標offset太舊,已經不在master的緩存隊列里了,那么將會進行一次全量數據的復制。
主從復制(部分復制,斷點續傳)流程圖:
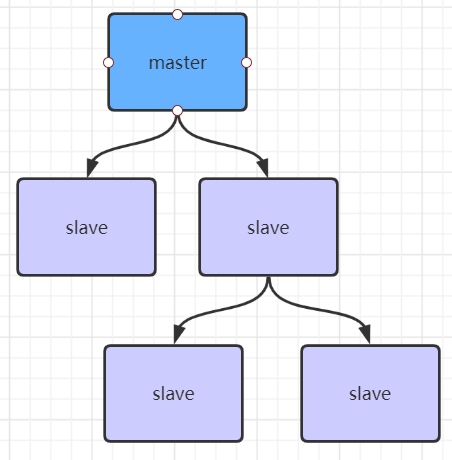
如果有很多從節點,為了緩解主從復制風暴(多個從節點同時復制主節點導致主節點壓力過大),可以做如下架構,讓部分從節點與從節點(與主節點同步)同步數據
Jedis連接代碼示例:
1、引入相關依賴:
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.9.0</version>
</dependency>訪問代碼:
public class JedisSingleTest {public static void main(String[] args) throws IOException {JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();jedisPoolConfig.setMaxTotal(20);jedisPoolConfig.setMaxIdle(10);jedisPoolConfig.setMinIdle(5);// timeout,這里既是連接超時又是讀寫超時,從Jedis 2.8開始有區分connectionTimeout和soTimeout的構造函數JedisPool jedisPool = new JedisPool(jedisPoolConfig, "192.168.0.60", 6379, 3000, null);Jedis jedis = null;try {//從redis連接池里拿出一個連接執行命令jedis = jedisPool.getResource();System.out.println(jedis.set("single", "hangzhou"));System.out.println(jedis.get("single"));//管道示例//管道的命令執行方式:cat redis.txt | redis-cli -h 127.0.0.1 -a password - p 6379 --pipe/*Pipeline pl = jedis.pipelined();for (int i = 0; i < 10; i++) {pl.incr("pipelineKey");pl.set("zhuge" + i, "hangzhou");}List<Object> results = pl.syncAndReturnAll();System.out.println(results);*///lua腳本模擬一個商品減庫存的原子操作//lua腳本命令執行方式:redis-cli --eval /tmp/test.lua , 10/*jedis.set("product_count_10016", "15"); //初始化商品10016的庫存String script = " local count = redis.call('get', KEYS[1]) " +" local a = tonumber(count) " +" local b = tonumber(ARGV[1]) " +" if a >= b then " +" redis.call('set', KEYS[1], a-b) " +" return 1 " +" end " +" return 0 ";Object obj = jedis.eval(script, Arrays.asList("product_count_10016"), Arrays.asList("10"));System.out.println(obj);*/} catch (Exception e) {e.printStackTrace();} finally {//注意這里不是關閉連接,在JedisPool模式下,Jedis會被歸還給資源池。if (jedis != null)jedis.close();}}
}順帶講下redis管道與調用lua腳本,代碼示例上面已經給出:
管道(Pipeline)
????????客戶端可以一次性發送多個請求而不用等待服務器的響應,待所有命令都發送完后再一次性讀取服務的響應,這樣可以極大的降低多條命令執行的網絡傳輸開銷,管道執行多條命令的網絡開銷實際上只相當于一次命令執行的網絡開銷。需要注意到是用pipeline方式打包命令發送,redis必須在處理完所有命令前先緩存起所有命令的處理結果。打包的命令越多,緩存消耗內存也越多。所以并不是打包的命令越多越好。
????????pipeline中發送的每個command都會被server立即執行,如果執行失敗,將會在此后的響應中得到信息;也就是pipeline并不是表達“所有command都一起成功”的語義,管道中前面命令失敗,后面命令不會有影響,繼續執行。
詳細代碼示例見上面jedis連接示例:
Pipeline pl = jedis.pipelined();
for (int i = 0; i < 10; i++) {pl.incr("pipelineKey");pl.set("hangzhou" + i, "zhuge");//模擬管道報錯// pl.setbit("hangzhou", -1, true);
}
List<Object> results = pl.syncAndReturnAll();
System.out.println(results);Redis Lua腳本(放在后面Redis高并發分布式鎖實戰課里詳細講)
Redis在2.6推出了腳本功能,允許開發者使用Lua語言編寫腳本傳到Redis中執行。使用腳本的好處如下:
1、減少網絡開銷:本來5次網絡請求的操作,可以用一個請求完成,原先5次請求的邏輯放在redis服務器上完成。使用腳本,減少了網絡往返時延。這點跟管道類似。
2、原子操作:Redis會將整個腳本作為一個整體執行,中間不會被其他命令插入。管道不是原子的,不過redis的批量操作命令(類似mset)是原子的。
3、替代redis的事務功能:redis自帶的事務功能很雞肋,而redis的lua腳本幾乎實現了常規的事務功能,官方推薦如果要使用redis的事務功能可以用redis lua替代。
官網文檔上有這樣一段話:
A Redis script is transactional by definition, so everything you can do with a Redis transaction, you can also do with a script, and usually the script will be both simpler and faster.
從Redis2.6.0版本開始,通過內置的Lua解釋器,可以使用EVAL命令對Lua腳本進行求值。EVAL命令的格式如下:
EVAL script numkeys key [key ...] arg [arg ...] script參數是一段Lua腳本程序,它會被運行在Redis服務器上下文中,這段腳本不必(也不應該)定義為一個Lua函數。numkeys參數用于指定鍵名參數的個數。鍵名參數 key [key ...] 從EVAL的第三個參數開始算起,表示在腳本中所用到的那些Redis鍵(key),這些鍵名參數可以在 Lua中通過全局變量KEYS數組,用1為基址的形式訪問( KEYS[1] , KEYS[2] ,以此類推)。
在命令的最后,那些不是鍵名參數的附加參數 arg [arg ...] ,可以在Lua中通過全局變量ARGV數組訪問,訪問的形式和KEYS變量類似( ARGV[1] 、 ARGV[2] ,諸如此類)。例如
127.0.0.1:6379> eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
1) "key1"
2) "key2"
3) "first"
4) "second"其中 "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 是被求值的Lua腳本,數字2指定了鍵名參數的數量, key1和key2是鍵名參數,分別使用 KEYS[1] 和 KEYS[2] 訪問,而最后的 first 和 second 則是附加參數,可以通過 ARGV[1] 和 ARGV[2] 訪問它們。
在 Lua 腳本中,可以使用redis.call()函數來執行Redis命令
Jedis調用示例詳見上面jedis連接示例:
jedis.set("product_stock_10016", "15"); //初始化商品10016的庫存
String script = " local count = redis.call('get', KEYS[1]) " +" local a = tonumber(count) " +" local b = tonumber(ARGV[1]) " +" if a >= b then " +" redis.call('set', KEYS[1], a-b) " +" return 1 " +" end " +" return 0 ";
Object obj = jedis.eval(script, Arrays.asList("product_stock_10016"), Arrays.asList("10"));
System.out.println(obj);注意,不要在Lua腳本中出現死循環和耗時的運算,否則redis會阻塞,將不接受其他的命令,?所以使用時要注意不能出現死循環、耗時的運算。redis是單進程、單線程執行腳本。管道不會阻塞redis。
Redis哨兵高可用架構
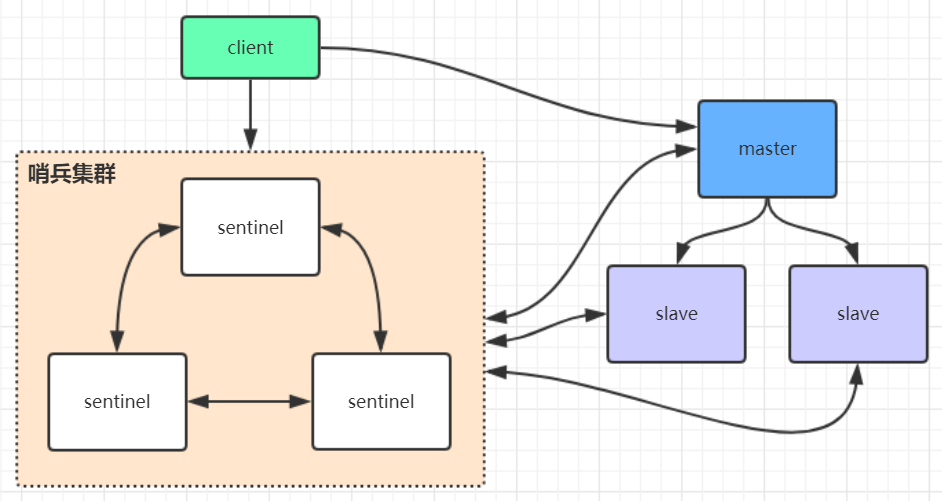
sentinel哨兵是特殊的redis服務,不提供讀寫服務,主要用來監控redis實例節點。
哨兵架構下client端第一次從哨兵找出redis的主節點,后續就直接訪問redis的主節點,不會每次都通過sentinel代理訪問redis的主節點,當redis的主節點發生變化,哨兵會第一時間感知到,并且將新的redis主節點通知給client端(這里面redis的client端一般都實現了訂閱功能,訂閱sentinel發布的節點變動消息)
redis哨兵架構搭建步驟:
1、復制一份sentinel.conf文件
cp sentinel.conf sentinel-26379.conf2、將相關配置修改為如下值:
port 26379
daemonize yes
pidfile "/var/run/redis-sentinel-26379.pid"
logfile "26379.log"
dir "/usr/local/redis-5.0.3/data"
# sentinel monitor <master-redis-name> <master-redis-ip> <master-redis-port> <quorum>
# quorum是一個數字,指明當有多少個sentinel認為一個master失效時(值一般為:sentinel總數/2 + 1),master才算真正失效
sentinel monitor mymaster 192.168.0.60 6379 2 # mymaster這個名字隨便取,客戶端訪問時會用到3、啟動sentinel哨兵實例
src/redis-sentinel sentinel-26379.conf4、查看sentinel的info信息
src/redis-cli -p 26379
127.0.0.1:26379>info
可以看到Sentinel的info里已經識別出了redis的主從5、可以自己再配置兩個sentinel,端口26380和26381,注意上述配置文件里的對應數字都要修改sentinel集群都啟動完畢后,會將哨兵集群的元數據信息寫入所有sentinel的配置文件里去(追加在文件的最下面),我們查看下如下配置文件sentinel-26379.conf,如下所示:
sentinel known-replica mymaster 192.168.0.60 6380 #代表redis主節點的從節點信息
sentinel known-replica mymaster 192.168.0.60 6381 #代表redis主節點的從節點信息
sentinel known-sentinel mymaster 192.168.0.60 26380 52d0a5d70c1f90475b4fc03b6ce7c3c56935760f #代表感知到的其它哨兵節點
sentinel known-sentinel mymaster 192.168.0.60 26381 e9f530d3882f8043f76ebb8e1686438ba8bd5ca6 #代表感知到的其它哨兵節點當redis主節點如果掛了,哨兵集群會重新選舉出新的redis主節點,同時會修改所有sentinel節點配置文件的集群元數據信息,比如6379的redis如果掛了,假設選舉出的新主節點是6380,則sentinel文件里的集群元數據信息會變成如下所示:
sentinel known-replica mymaster 192.168.0.60 6379 #代表主節點的從節點信息
sentinel known-replica mymaster 192.168.0.60 6381 #代表主節點的從節點信息
sentinel known-sentinel mymaster 192.168.0.60 26380 52d0a5d70c1f90475b4fc03b6ce7c3c56935760f #代表感知到的其它哨兵節點
sentinel known-sentinel mymaster 192.168.0.60 26381 e9f530d3882f8043f76ebb8e1686438ba8bd5ca6 #代表感知到的其它哨兵節點同時還會修改sentinel文件里之前配置的mymaster對應的6379端口,改為6380
sentinel monitor mymaster 192.168.0.60 6380 2當6379的redis實例再次啟動時,哨兵集群根據集群元數據信息就可以將6379端口的redis節點作為從節點加入集群
哨兵的Jedis連接代碼:
public class JedisSentinelTest {public static void main(String[] args) throws IOException {JedisPoolConfig config = new JedisPoolConfig();config.setMaxTotal(20);config.setMaxIdle(10);config.setMinIdle(5);String masterName = "mymaster";Set<String> sentinels = new HashSet<String>();sentinels.add(new HostAndPort("192.168.0.60",26379).toString());sentinels.add(new HostAndPort("192.168.0.60",26380).toString());sentinels.add(new HostAndPort("192.168.0.60",26381).toString());//JedisSentinelPool其實本質跟JedisPool類似,都是與redis主節點建立的連接池//JedisSentinelPool并不是說與sentinel建立的連接池,而是通過sentinel發現redis主節點并與其建立連接JedisSentinelPool jedisSentinelPool = new JedisSentinelPool(masterName, sentinels, config, 3000, null);Jedis jedis = null;try {jedis = jedisSentinelPool.getResource();System.out.println(jedis.set("sentinel", "zhuge"));System.out.println(jedis.get("sentinel"));} catch (Exception e) {e.printStackTrace();} finally {//注意這里不是關閉連接,在JedisPool模式下,Jedis會被歸還給資源池。if (jedis != null)jedis.close();}}
}哨兵的Spring Boot整合Redis連接代碼見示例項目:redis-sentinel-cluster
1、引入相關依賴:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId>
</dependency>springboot項目核心配置:
server:port: 8080spring:redis:database: 0timeout: 3000sentinel: #哨兵模式master: mymaster #主服務器所在集群名稱nodes: 192.168.0.60:26379,192.168.0.60:26380,192.168.0.60:26381lettuce:pool:max-idle: 50min-idle: 10max-active: 100max-wait: 1000訪問代碼:
@RestController
public class IndexController {private static final Logger logger = LoggerFactory.getLogger(IndexController.class);@Autowiredprivate StringRedisTemplate stringRedisTemplate;/*** 測試節點掛了哨兵重新選舉新的master節點,客戶端是否能動態感知到* 新的master選舉出來后,哨兵會把消息發布出去,客戶端實際上是實現了一個消息監聽機制,* 當哨兵把新master的消息發布出去,客戶端會立馬感知到新master的信息,從而動態切換訪問的masterip** @throws InterruptedException*/@RequestMapping("/test_sentinel")public void testSentinel() throws InterruptedException {int i = 1;while (true){try {stringRedisTemplate.opsForValue().set("zhuge"+i, i+"");System.out.println("設置key:"+ "zhuge" + i);i++;Thread.sleep(1000);}catch (Exception e){logger.error("錯誤:", e);}}}
}StringRedisTemplate與RedisTemplate詳解
spring 封裝了 RedisTemplate 對象來進行對redis的各種操作,它支持所有的 redis 原生的 api。在RedisTemplate中提供了幾個常用的接口方法的使用,分別是:
private ValueOperations<K, V> valueOps;
private HashOperations<K, V> hashOps;
private ListOperations<K, V> listOps;
private SetOperations<K, V> setOps;
private ZSetOperations<K, V> zSetOps;RedisTemplate中定義了對5種數據結構操作
redisTemplate.opsForValue();//操作字符串
redisTemplate.opsForHash();//操作hash
redisTemplate.opsForList();//操作list
redisTemplate.opsForSet();//操作set
redisTemplate.opsForZSet();//操作有序setStringRedisTemplate繼承自RedisTemplate,也一樣擁有上面這些操作。
StringRedisTemplate默認采用的是String的序列化策略,保存的key和value都是采用此策略序列化保存的。
RedisTemplate默認采用的是JDK的序列化策略,保存的key和value都是采用此策略序列化保存的。
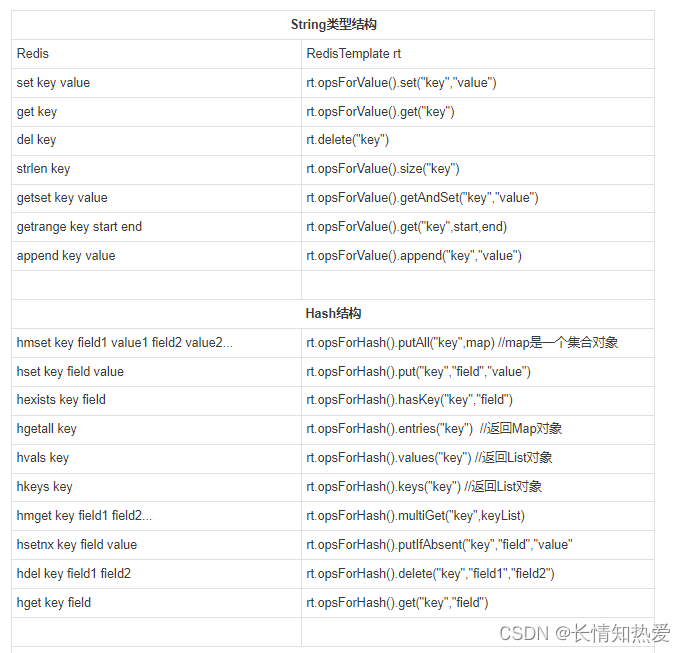
Redis客戶端命令對應的RedisTemplate中的方法列表:
|
|
?
?


)












)

 計算兩點云之間的最小距離)

函數)