Lhotse 是一個旨在使語音和音頻數據準備更具靈活性和可訪問性的 Python 庫,它與 k2 一起,構成了下一代 Kaldi 語音處理庫的一部分。
主要目標:
1. 以 Python 為中心的設計吸引更廣泛的社區參與語音處理任務。
2. 為有經驗的 Kaldi 用戶提供富有表現力的命令行接口。
3. 為常用的語料庫提供標準的數據準備方案。
4. 為與語音和音頻相關的任務提供 PyTorch 數據集類。
5. 通過音頻剪輯的概念實現模型訓練中的靈活數據準備。
6. 提高效率,特別是在 I/O 帶寬和存儲容量方面。
使用 Lhotse 對數據集結構化抽象、存儲和轉換成 PyTorch 數據管道,可以很方便實現語音識別和語音合成工程項目。

無論是音頻大文件和小文件,都可以使用 cut 來有效表達:




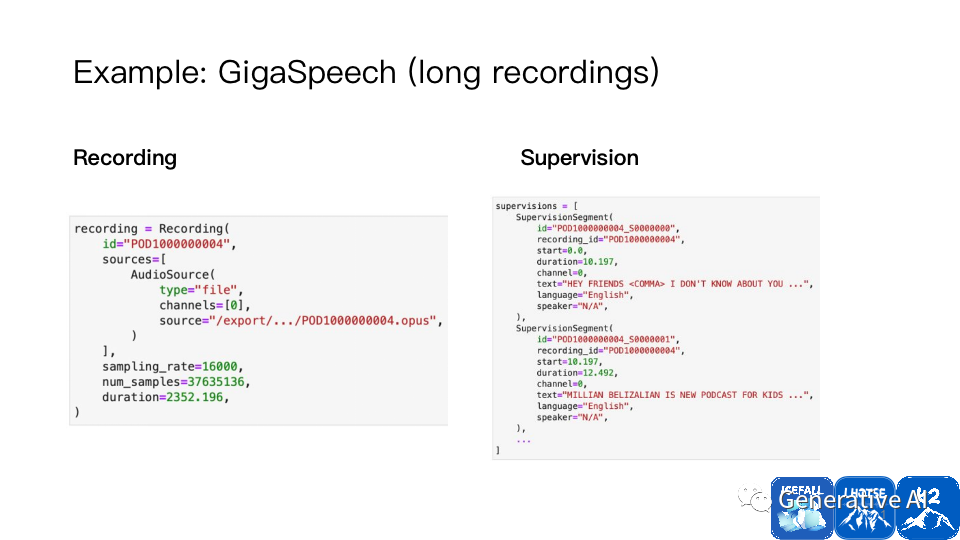
Lhotse 支持了近百個數據集,開箱即用,新的數據集可參考這些例子來完成。

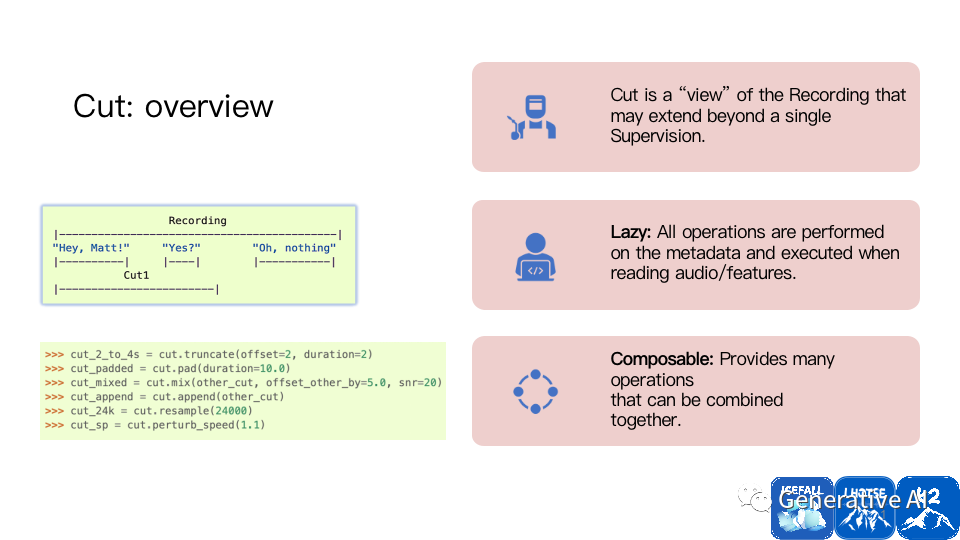
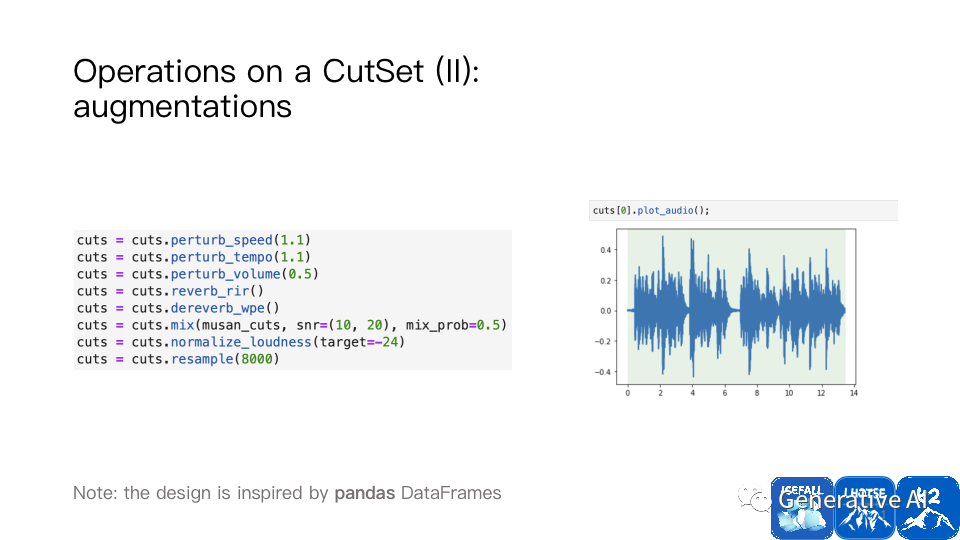
操作數據集也很方便

很方便地與 PyTorch 集成

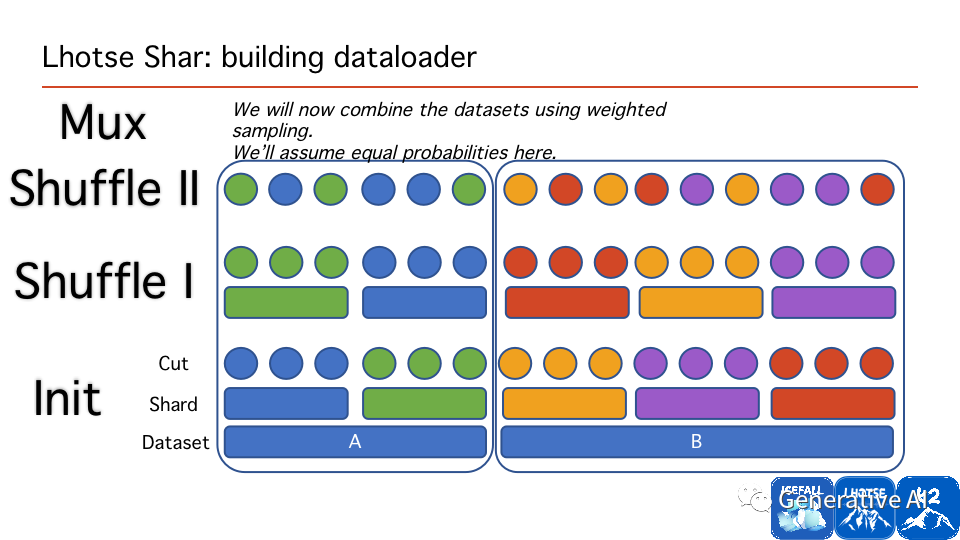
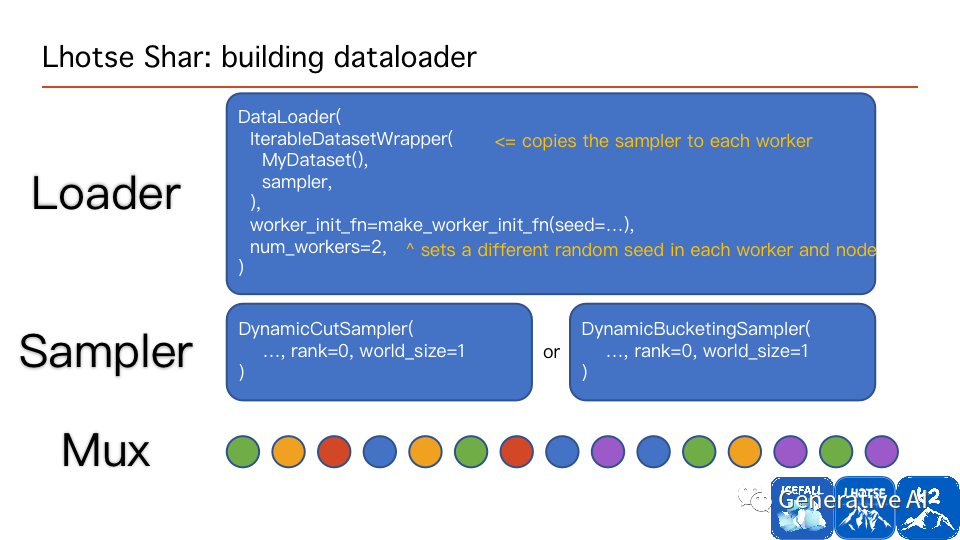
Lhotse 的可擴展性

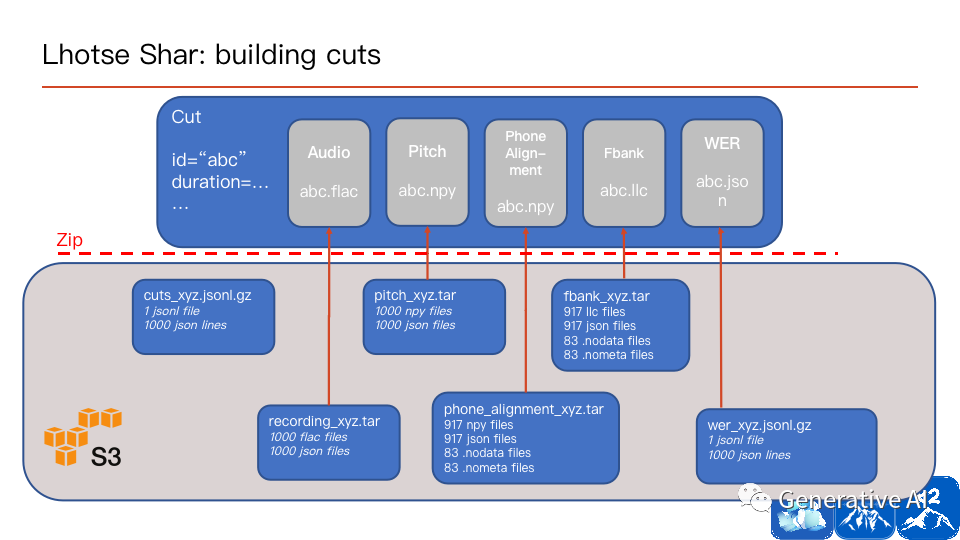


除了文本與語音信息外,Lhotse 還可以 custom 許多信息:強制對齊、duration、pitch 等,可以方便地支持多種語音任務。
對于特征抽取的存儲,Lhotse 的寫入效率會隨著文件大小逐漸變慢,必要的時候需要 CutSet.split 成多個 JOB 執行來提高效率。?
此外,盡管 Lhotse 提供了命令行工具,但缺乏 web 工具去分析數據集、樣例數據。
依賴?Lhotse 的項目
-
https://github.com/k2-fsa/icefall
-
https://github.com/lifeiteng/vall-e
參考資料:
-
https://lhotse.readthedocs.io/en/latest/index.html
-
Slides for the Interspeech 2023 tutorial
-
https://github.com/k2-fsa/icefall/issues/1230
-










)

 計算兩點云之間的最小距離)

函數)




![2023年中國高壓驅動芯片分類、市場規模及發展趨勢分析[圖]](http://pic.xiahunao.cn/2023年中國高壓驅動芯片分類、市場規模及發展趨勢分析[圖])