文章目錄
- 傳輸層協議TCP基本認識
- TCP協議的格式
- TCP的可靠性初步理解——確認應答機制
- 暫時理解TCP的通信過程
- TCP的確認號和確認序號
- 確認號和確認序號的意義
- 捎帶應答
- TCP中其他字段的理解
- 16位窗口大小
- 標志位
- 標志位的本質
- 標志位的意義
- 以SYN + ACK標志位簡單理解TCP連接三次握手
- 以FIN標志位簡單理解TCP斷連四次揮手
- PSH標志位
- RST標志位
- 16位緊急指針 && URG標志位
傳輸層協議TCP基本認識
在講解完UDP的相關原理之后,我們將在UDP原理的基礎上,進行對TCP原理的探究!
TCP協議的格式
我們先來認識一下TCP協議的格式: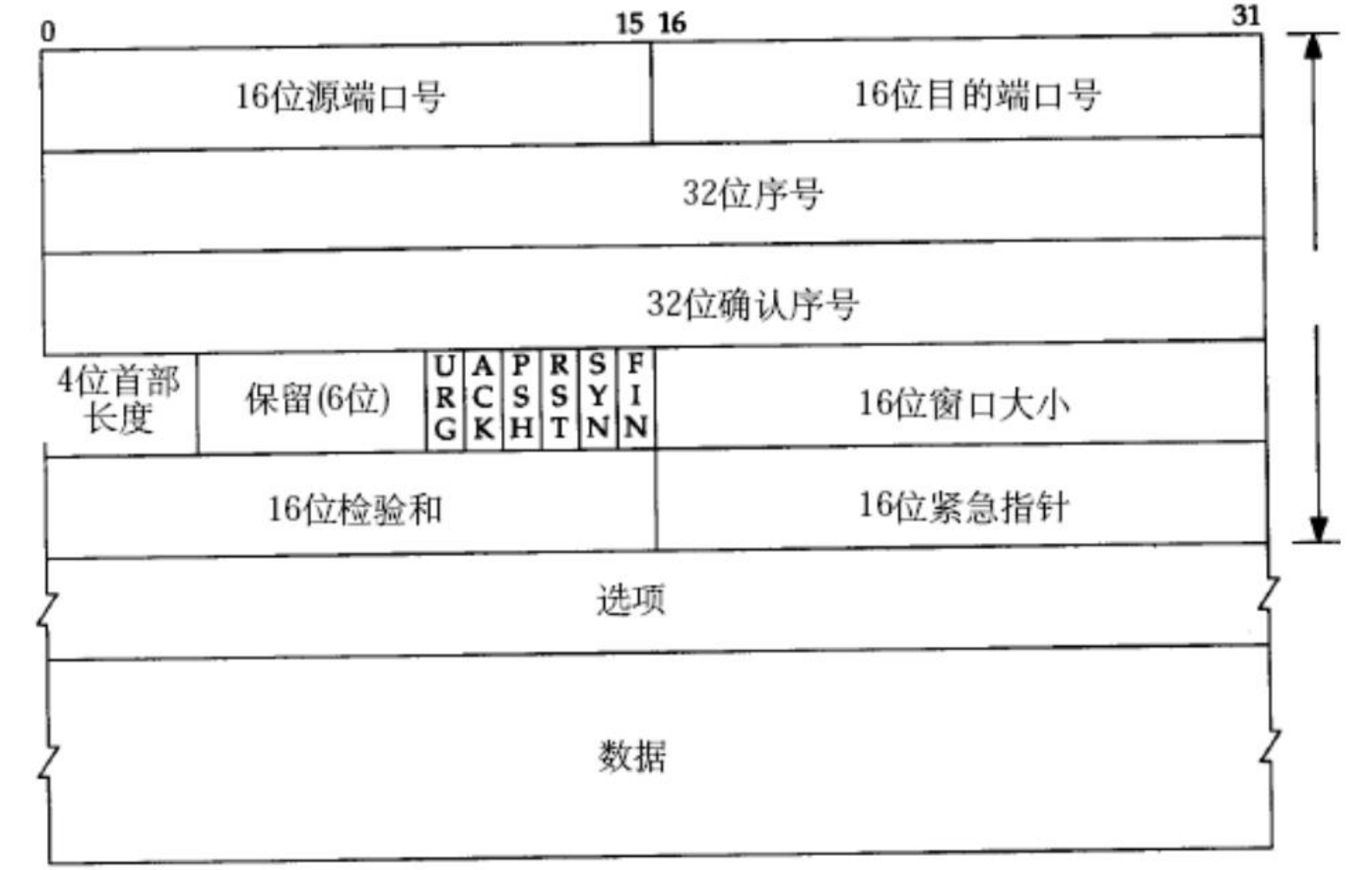
光是從格式上來看,我們就能發現,TCP是比UDP要復雜的多的多!但是沒有關系,我們將一步步地來解決TCP中可能遇到的、也可能是不理解的問題!
還是一樣,對于TCP報頭而言,以下兩個問題如何解決:
1.報頭和有效載荷如何分離?
2.如何分用?
分離:
對于TCP的報頭來說,絕大部分情況下,報頭大小都是固定的,即20字節(不包含選項+數據)!
但是,還有剩下一小部分是什么情況呢?
其實是因為:TCP的報頭中,選項字段可能存在,也可能不存在!這就導致了TCP報文的報頭的大小是浮動的。那這是一件比較棘手的事情。這如何解決?
解決方案:在報頭中存在一個字段——4位首部長度
這個4位首部長度,可以表示0 ~ 15的數字,可TCP報頭的最小都是20byte了,這是怎么回事?
所以這就說明,這個0 ~ 15的基本單位必然不可能是1byte,其實是4byte!
所以,0 ~ 15,其實表示的是0 ~ 60字節!表示的是首部長度!
首部 = 20字節基礎報頭 + 選項報頭!
所以得出,選項的大小應該是0 ~ 40byte!而4位首部長度,最小值也應該是5!
有了上面的認識,我們想讓報頭和有效載荷分離就是比較簡單的事情了。直接先讀取出20字節的基礎報頭,得出4位首部長度的值。然后根據對應關系計算得出選項報頭的大小即可!
分用:
在能夠把報頭和有效載荷分離的情況下,想要分用報頭也是一件非常簡單的事情!
直接把報頭拿出來,根據TCP的格式就可以提取出相應的字段,交付給對應接口使用即可。
還有最后一個問題:
UDP協議的報頭中,存在一個16位長度字段,表示整個UDP報文的長度。
但是,在TCP這里,怎么只有標識首部長度的字段,而沒有整個TCP報文的長度呢?
其實是因為:
TCP是面向字節流的!在TCP協議看來,它根本不關心自己讀到的是什么,只認為它是一個個的字節!TCP根本不關心報文的邊界:
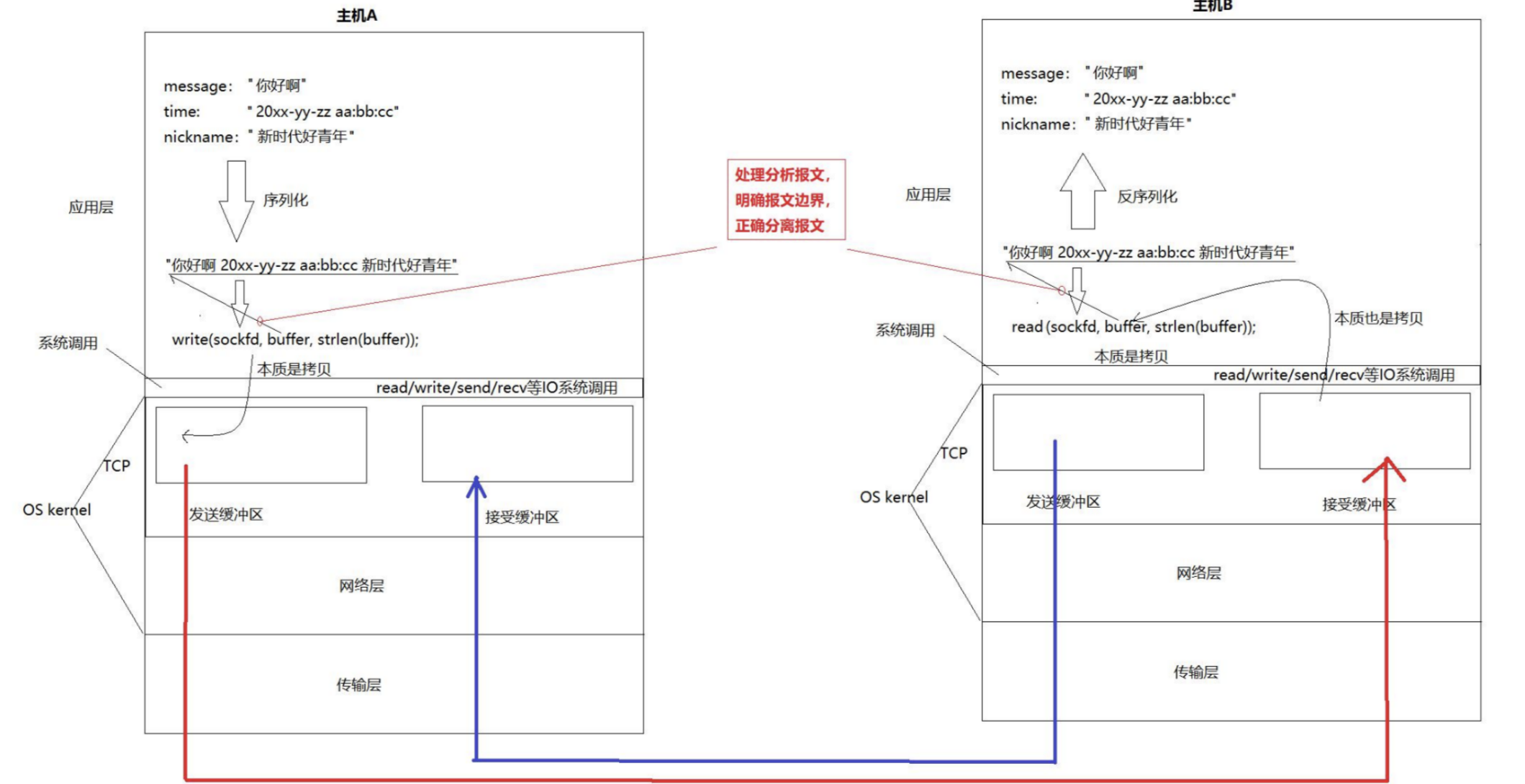
TCP協議有兩對發送<->接收的緩沖區。信息來的時候,或者寫入的時候,TCP這一層根本就不關心到底是什么數據。在TCP看來,就是一個個的字節。
只是TCP這一層規定好了對應的格式!然后發送到對端的時候,報頭和數據分離,數據會放到接收緩沖區。至于數據應該怎么被安全的傳輸到應用層,這個工作需要由應用層根據應用層的協議、具體的業務來進行處理,這不是TCP的范疇!
所以,對于TCP的報頭來說,根本沒有存在整個報文長度字段的必要!
TCP的可靠性初步理解——確認應答機制
我們需要先了解TCP通信的可靠性相關話題,這是理解TCP通信的基礎!然后以此理解TCP格式中的部分字段。在此之后,我們會再來理解其它的沒有提及的片段!
首先需要聲明的一點是:不存在100%可靠的協議!
但是我們又常常能夠見到各種教材和資料中都說:TCP具有可靠性,這是怎么一回事呢?
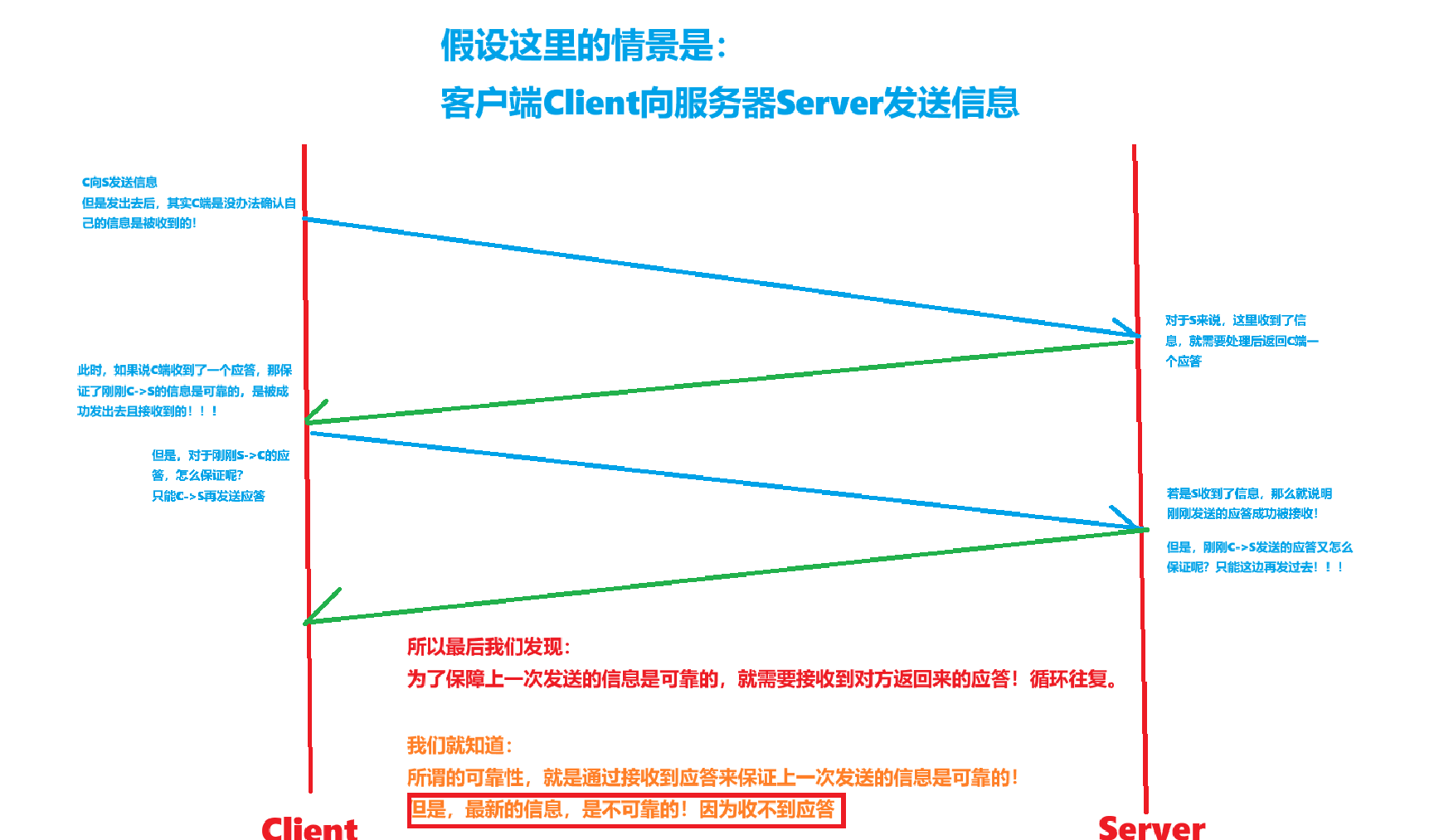
現在我們就需要對TCP的可靠性有一個全新的、正確的認識:
1.具有應答,保證的是歷史消息的可靠性!
2.最新的消息,我們是沒有辦法保證它的可靠性的,因為它沒有應答!
在TCP的可靠性中,處于核心地位的就是上面的 確認應答機制!
暫時理解TCP的通信過程
其實我們現在是沒有辦法完完全全理解TCP的通信過程,以及通信中出現的一些問題的!
但是,我們肯定能夠知道:TCP協議是一個基于確認應答機制的通信協議!
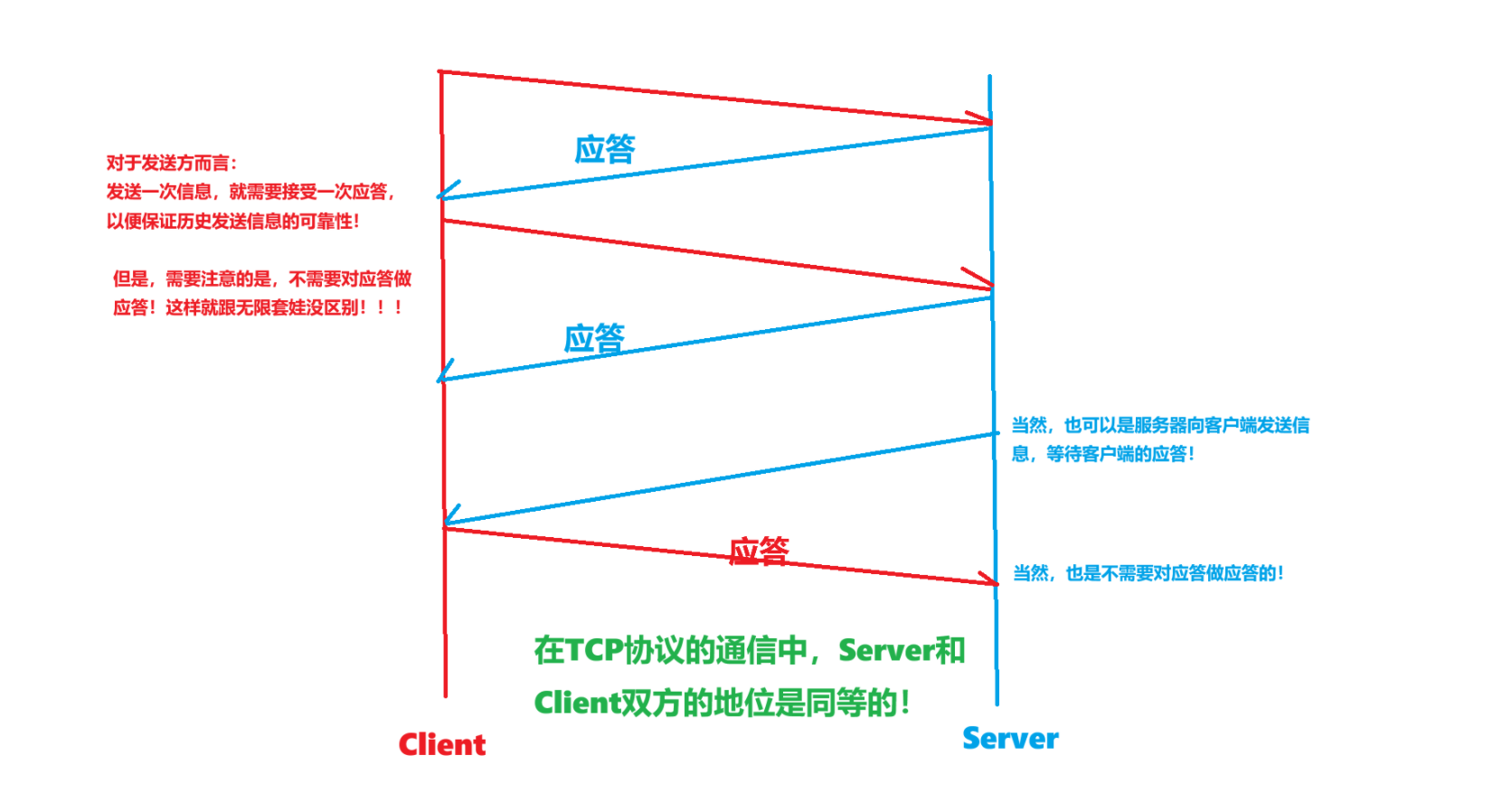
最簡單的通信流程就如上圖所示:
服務器和客戶端都可以向對方發送信息,都需要接收到對方的應答來保證自己歷史發送的數據是可靠的!-> 在TCP中,通信的雙方地位是平等的!
通過上面最簡單的例子, 我們就知道通信的雙方為什么能夠說通信可靠!
當然,有很多問題我們沒有說,如應答丟失等,這些我們后面說!
TCP的確認號和確認序號
但是,在今后對于通信的理解的時候,我們需要重新說明的一點是:
在很多教材、資料中,都很喜歡把通信的流程圖認為就是發一個簡單的信息,一個簡單的字段!但其實這是不對的!我們需要牢記:在TCP通信中,傳輸的至少是一個TCP報頭!
傳輸的報文中,可以只有報頭而沒有數據!我們在HTTP協議那里也是見過:
在瀏覽器訪問ip:port的時候,就是向服務器申請一個HTTP請求,是不帶正文的!
現在我們需要看一個新的場景:
上面講TCP基本通信流程的時候,是一邊發送一個報文,一邊給應答。是有很明顯的串行順序的!但是,這種串行的順序進行通信,其實是有很大的效率問題的!因為這樣一個個來做發送<->應答效率還是有點低了!
那有沒有一種可能:發送報文是連續放松的,返回應答也是連續的呢?
答案是:完全有可能,如下圖所示:
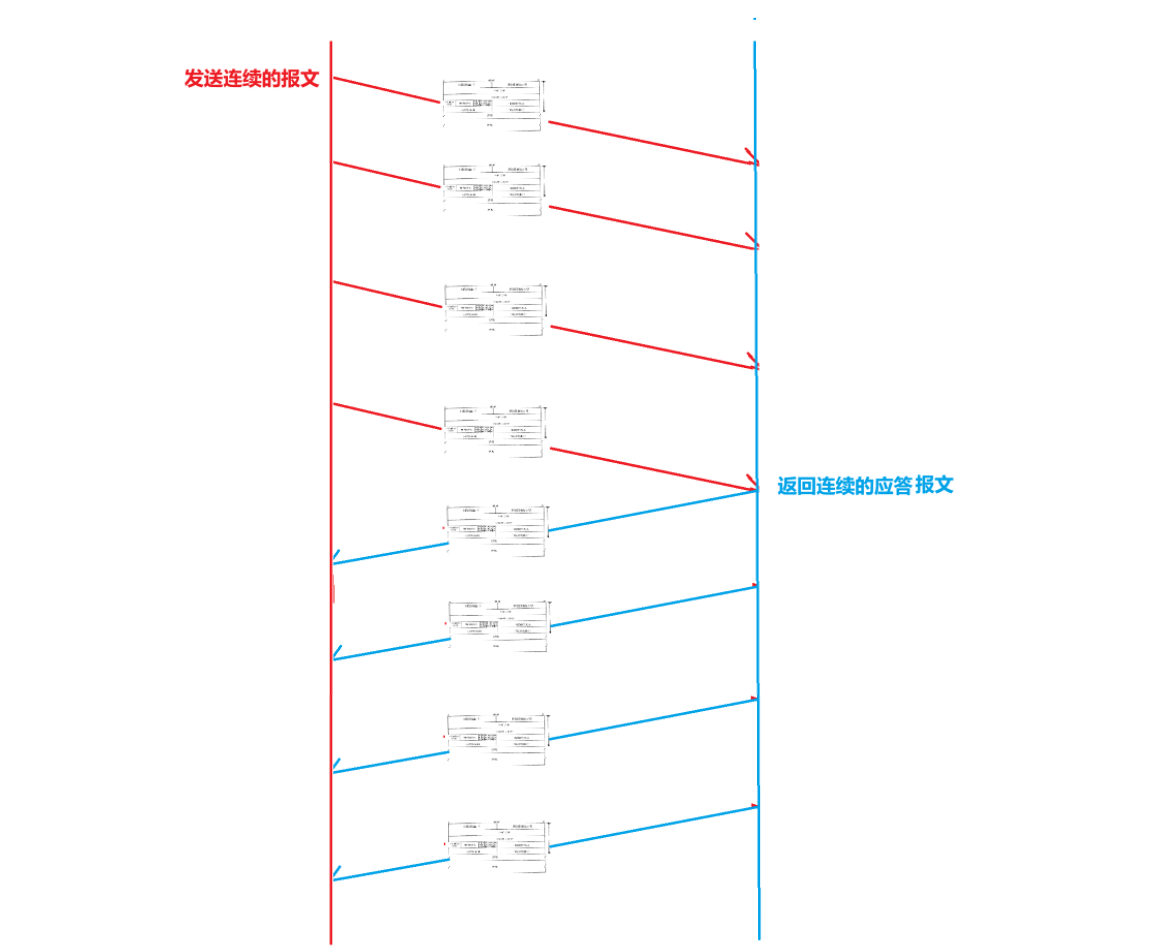
這種就是并行的進行發送和返回,效率會高一些!但是,有一個很大的問題:
既然是連續發送的報文,那么返回應答報文的時候:
1.發送方怎么知道返回的應答是針對于哪一個發送的報文的?
2.應答可能會丟失,若是丟失了若干個怎么判斷可靠情況?
先解決第一個問題:

就是通過TCP報頭中的32位序號和32位確認序號來做判斷的!
發送方每次發送一個報文的時候,都會在序號字段上設置對應的數字,代表一個序號!
然后,返回應答的一方,收到某個32位序號為x的報文,就會設置應答報文中的確認序號為x+1,然后返回給發送端!
也就是說:確認序號 = 序號 + 1!
確認序號的物理意義是:代表該序號之前的所有序號的報文都已經接收成功,下一次需要從該序號開始發送報文!
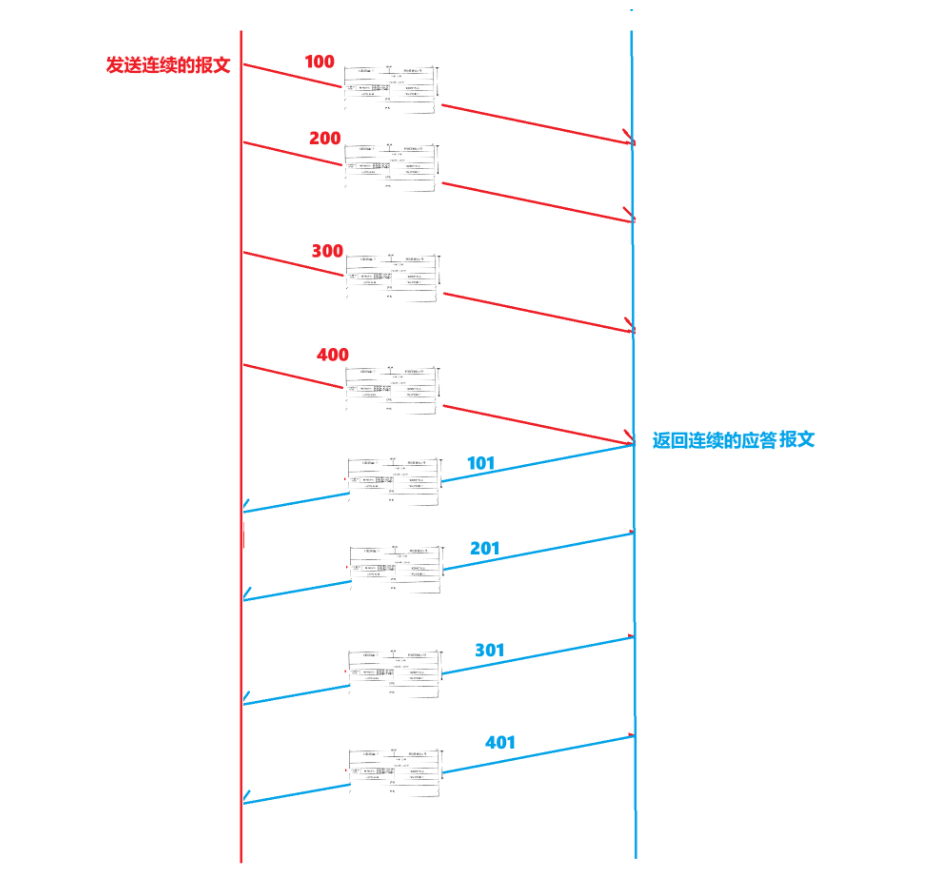
當然,實際上并不是一定要按照確認序號開始發送,可能也是別的數字,但是一定是>=確認序號的!這點我們先不做過多理解,知道有這么一回事即可!
第二個問題:
如果說返回的應答丟失了幾個怎么辦?假設今天返回的應答報文丟失了確認序號為201、301的兩個,發送方只收到101和401,怎么判斷呢?
只需要緊緊抓住確認序號的定義:代表著該序號之前的所有報文信息都已經接收成功!
收到101 -> 101以前的都成功。
收到401 -> 401以前的都成功。
->在發送方看來,收到401就直接默認401以前都成功了,哪怕201和301丟失了,但是因為收到了401,所以還是能認為401以前的所有都接收成功!
如果發送方的幾個報文丟失了怎么辦?如丟失了200、300,接受方只收到100和400?
對于接收方來說,收到100,返回101!但是,因為200和300丟失,,是不能直接跳過未收到的報文,從而直接發送401回去的!
因為確認序號代表該序號之前的所有報文信息都已經接收成功! 200和300都沒接收到,這怎么能夠發401回去呢?不符合確認序號的定義了!
但是,對于應答丟失來說,如果能夠返回401,這一定能夠說明:
200和300接收方一定收到了,只不過應答丟失了!所以,收到401確實是可以認為401之前的全部接收成功!這是接收方和發送方的區別!
確認號和確認序號的意義
現在已經初步認識了確認號和確認序號了,但是,還有一些問題:
1.為什么要同時存在兩個這樣的字段?通過上面的場景來看,直接用一個字段不就好了?
2.這個確認號和確認序號的意義到底是什么?
現在,讓我們一起來解釋這兩個問題!
問題一:
從上面的場景來看,確實是只需要一個字段來表示序號即可!但是,上面的場景是單一的。
假設客戶端向服務器發送報文,有沒有這么一種可能:
今天的服務器在返回應答的同時,也需要攜帶對應的信息發送給客戶端做應答呢?
舉個更通俗的例子:
A和B打電話:
A:B你吃了沒(A向B發送信息)
B:A我吃了(對A的信息應答),我吃的餃子,你吃的什么(同時攜帶信息,需要A應答)
A:我吃的xxx(對B的攜帶信息進行應答),你在家嗎(再向B發送信息)…
…
上面的過程就很生動形象的展示了TCP通信雙方的,可能在應答中攜帶信息的情況!
所以,通信的雙方都可能稱為發送方或者應答方,所以,是需要兩個字段來標識序號的!
問題二:
我們可以發現,上述的過程中,序號和確認序號做到了三點:
1.讓報文按序到達。
2.解決了信息傳輸不可靠問題(當然會有對應的機制處理丟包,這里先不說)。
3.針對于報文的亂序問題,也是可以處理的!也可以接收報文在并發發送的亂序問題!
捎帶應答
這里只需要理解剛剛上面這一種情況,就能理解捎帶應答!
即今天的服務器在返回應答的同時,也需要攜帶對應的信息發送給客戶端做應答呢?
當一方做應答的時候,又想攜帶信息讓接收方做應答,這種情況就是捎帶應答:
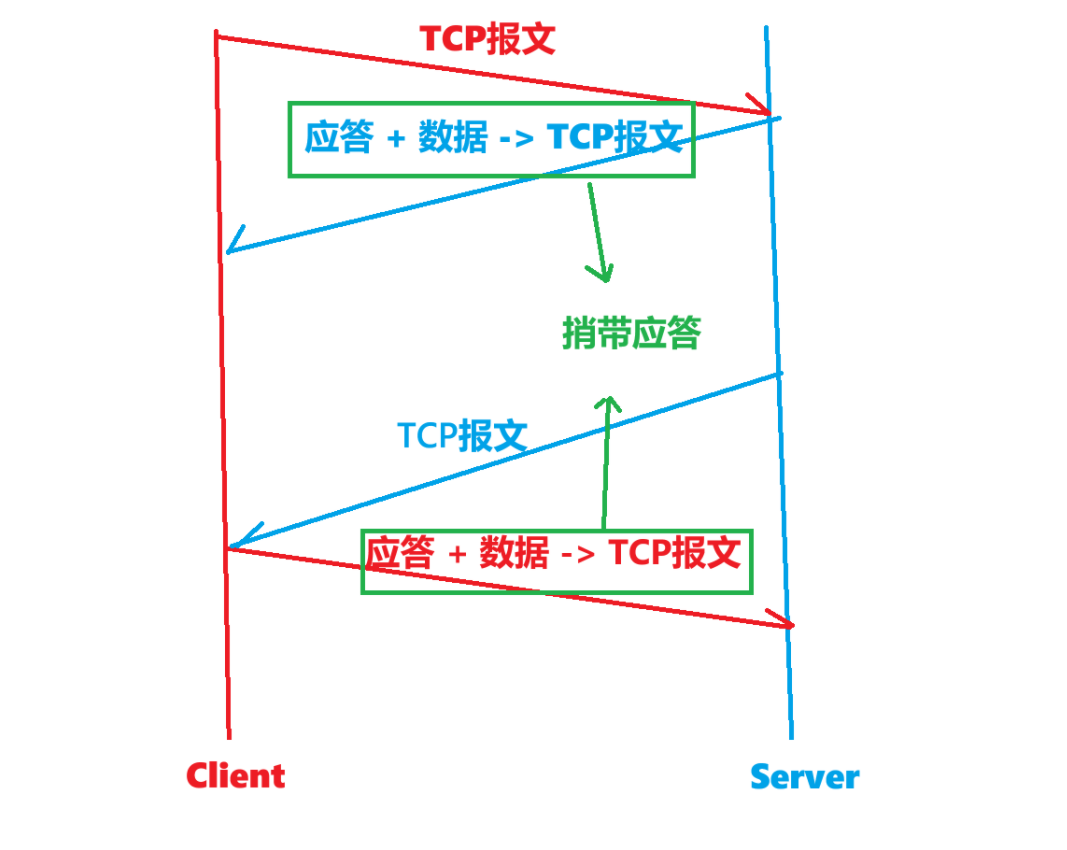
如上圖所示!
TCP中其他字段的理解
我們現在已經了解了TCP報頭中的若干字段:
源端口號、目的端口號、序號、確認序號、4位首部長度。
當然,TCP報頭中還有一些字段是需要我們進行了解的,下面我們一起來看看。
當然,我們這里只是進行簡單的理解,具體操作我們放在后面講解。
16位窗口大小
我們先來理解第一個,就是TCP報頭中的16位窗口大小。
TCP協議的通信現在是否存在一個情況:
就是說一方發過去的報文,但是接收方的接收緩沖區已經滿了!那么,這個時候收方也沒辦法接收該報文,只能把它丟棄了!
但是,TCP是一個可靠的協議,可以做重傳(具體的重傳邏輯我們先弱化)。
上面都是我們過往對TCP的理解,不需要過多解釋。但是,一個報文,需要從一臺主機通過網絡發送到另一臺主機,是需要經過各種操作、轉發、消費算例、網絡帶寬。結果到最后送給對方主機的時候還是被丟棄了!這真的合理嗎?
答案是不合理!在網絡的通信中是希望能盡量避免這種情況的出現的!
如何解決呢?
->如果說,發送方能夠知道對方是否能夠接收我們發送過去的報文,不就可以解決這個問題?
在TCP的報頭中,16位窗口大小,就是來表示當前接收緩沖區的大小的,但是,是表示自己的,還是表示對方的呢?
答案必然是自己的!因為具體緩沖區內還有多少空間,只有自己知道。同時,我們告訴對方當前我方的剩余空間,對方就可以根據這個空間做流量控制!
即發送方的發送速度需要參考對方的接收窗口大小,從而進行合理的流量控制!
16位窗口大小的意義
所以,通過接收對方發來的報文,拿出對方16位窗口大小的字段的值,就可以在發送之前知道對方的接受能力了!然后通過合理的流量控制算法進行控制。
標志位
在TCP的報頭中,存在著這么幾個字段:
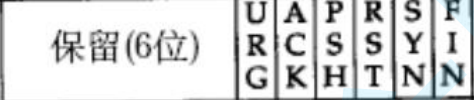
這些就是標志位!它們分別是干什么的呢?
標志位的本質
首先,我們需要搞清楚標志位的本質是什么:
其實標志位就是在TCP報頭中特定位置的一個比特位罷了!其中有6位是被保留起來的(這個部分不做了解)!剩下的6個需要我們理解。
有時候我們可以在一些教材/資料上看到這樣的說法:
A向B發送xxx標志位,B向A返回xxx標志位。
在今天的我們來看:
我們需要丟棄這種說法。始終要記住:在TCP的通信中,最少也得是一個報文。
所謂向對方發送xxx標志位,其實就是發送報文的時候,在對應的比特位上置1罷了!
我們也可以從tcp結構體中一探究竟:
struct tcphdr {__be16 source; // 源端口__be16 dest; // 目的端口__be32 seq; // 序列號__be32 ack_seq; // 確認號
#if defined(__LITTLE_ENDIAN_BITFIELD)__u16 res1:4, // 保留位doff:4, // 數據偏移(頭部長度)fin:1, // FIN 標志syn:1, // SYN 標志rst:1, // RST 標志psh:1, // PSH 標志ack:1, // ACK 標志urg:1, // URG 標志ece:1, // ECN-Echo (RFC 3168)cwr:1; // Congestion Window Reduced
#elif defined(__BIG_ENDIAN_BITFIELD)// 大端序下的相同定義(位域順序相反)
#else
#error "Adjust your <asm/byteorder.h> defines"
#endif__be16 window; // 窗口大小__sum16 check; // 校驗和__be16 urg_ptr; // 緊急指針(URG=1時有效)
};
標志位的意義
TCP報頭中,每個字段存在都是有它對應的意義的。我們先不談單一的字段的作用,我們就從宏觀角度上來理解,即TCP報頭中設置這個標志位的意義是什么?有什么作用?
我們就以服務器為例子:
服務器是和客戶端連接使用的。那么,在服務器中,肯定存在著一系列的報文!
但是,所有的報文都是請求同一個操作的嗎?
↓
有沒有可能:有些報文請求的就是連接、有些請求的是斷開連接、甚至還有各種各樣的,不同種類的報文?答案是必然的,肯定有。
所以,接受方肯定會接收到不同種類的報文,而針對于不同種類的報文是有不同的做法的!
那么,對于接收方來講,首要任務就是要識別出報文的種類 -> 需要對應的標志位來標識!
所以,在TCP的報頭中,標志位(其實就是特定字段中的一個比特位,不同的比特位對應的標志位是不同的!),就用來標識報文的種類!
以SYN + ACK標志位簡單理解TCP連接三次握手
ACK(ACKNOWLEDGEMENT): 確認號是否有效
SYN(SYNCHRONOUS): 請求建立連接; 我們把攜帶SYN標識的稱為同步報文段
我們需要先簡單講一下TCP建立連接的三次握手的過程,以便于理解上述的兩個標志位:
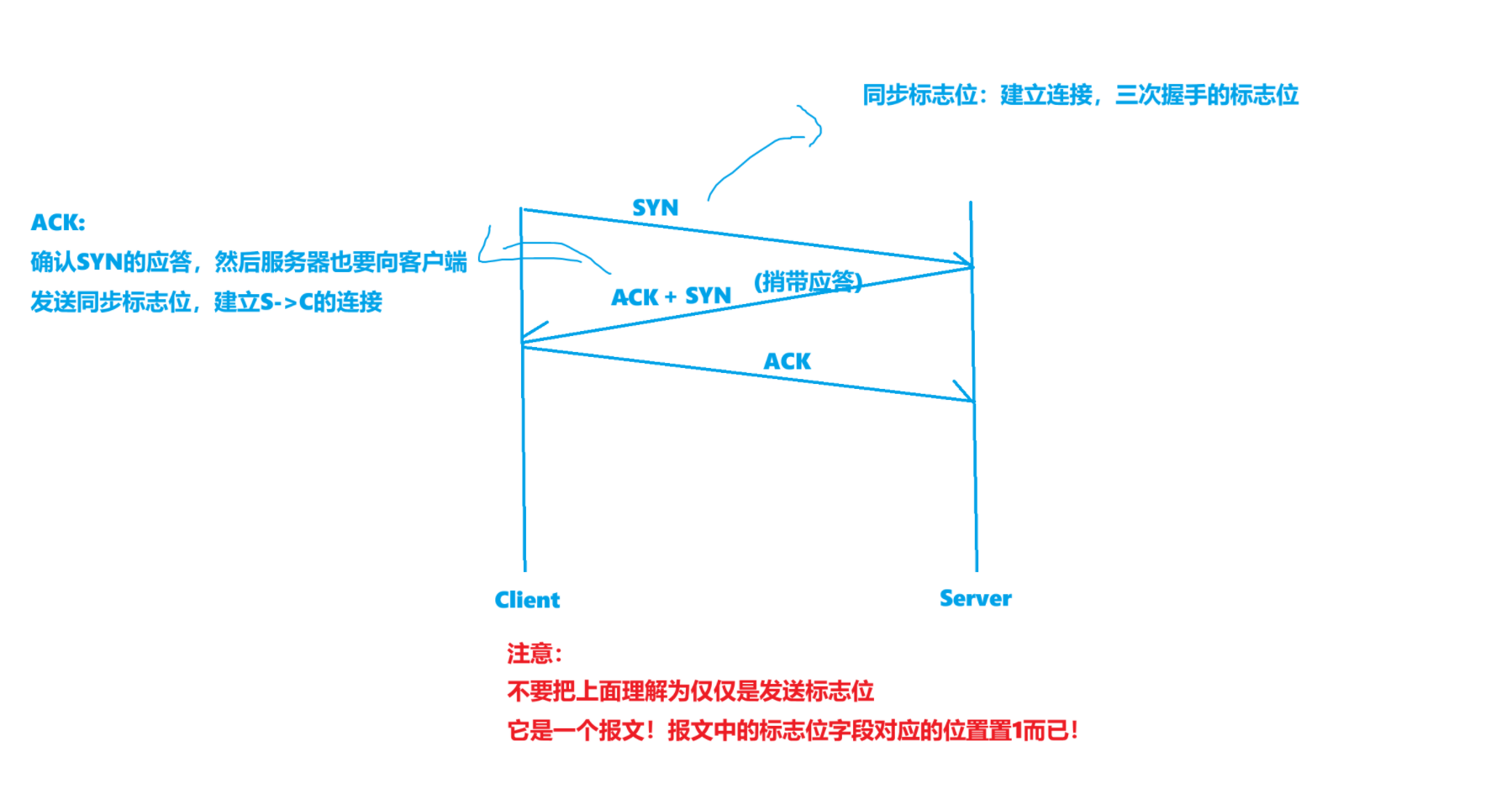
假設以客戶端向服務器發送連接請求為例:
首先,SYN是同步標志位,我們目前可以簡單理解為這是用來發起連接請求的標志位即可!
ACK就是確認應答的標志位!在該位置設置1,代表接收方已經收到了報文,保證歷史發送信息的可靠性。
我們現在需要轉而理解:為什么需要進行三次握手?
首先,第一次C向S發送報文,帶有SYN標志位,即申請連接。然后S->C返回ACK應答,這是確保C->S的發送的連接請求是可靠的!
但是,TCP是全雙工,雙方都要進行連接,所以S->C發送ACK的同時,可以帶上SYN(捎帶應答),這樣子不僅是保證歷史數據可靠,也是向對方發送請求。
然后C還得向S發送一個帶有ACK標志位的報文!因為要保證S->C的信息是可靠的!
所以,基于確認應答機制的理解:
通過這三次握手,就已經是在協商SC雙方通信的意愿了!
只不過是:在三次握手階段,因為雙方沒有完全建立好連接的共識,所以雙方發送的都是報頭,即不帶正文數據的!
這里還可以提出一個小問題:
當建立連接成功后,第一次向對方發送帶有數據的報文的,怎么知道對方接收緩沖區大小呢?流量控制怎么做?
答案其實很簡單:第一次發送數據 = 第一次發送報文!
其實早在雙方三次握手期間,就可以在16位窗口大小的字段上設值,然后雙方就可以在正式通信之前來協商雙方的接受能力了!
其余的細節我們將在后續的TCP連接管理部分進行講解!
以FIN標志位簡單理解TCP斷連四次揮手
FIN(FINISH): 通知對方, 本端要關閉了, 我們稱攜帶 FIN 標識的為結束報文段
比如下圖客戶端和服務器斷開連接四次揮手示意圖所示:
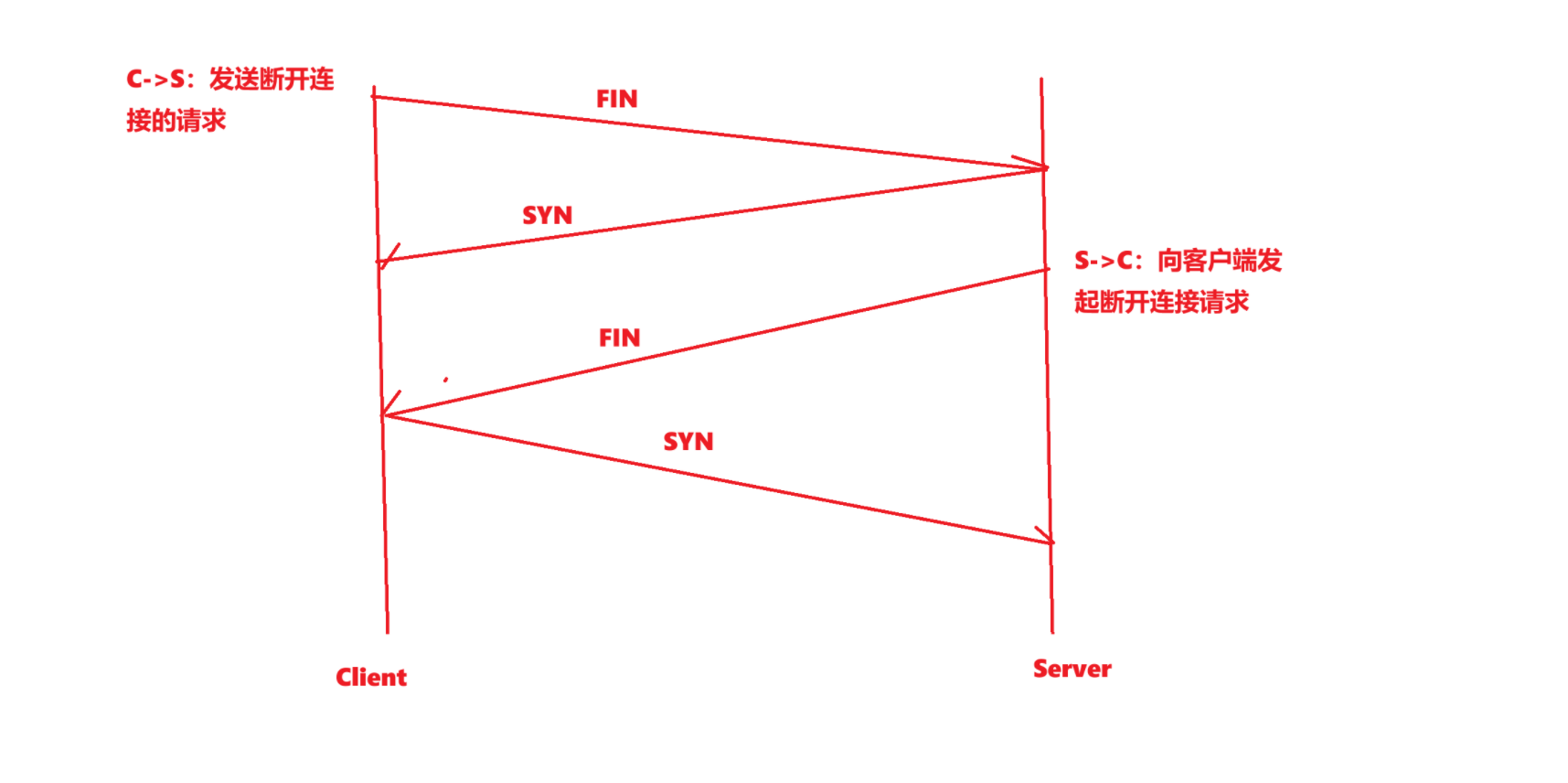
還是一樣的,通過上述的四次揮手:
就能完成客戶端和服務器之間雙方之間的通信連接關閉了(TCP是全雙工,需要兩邊進行關閉)。我們現在只需要知道FIN標志位是用來標志斷開連接報文的即可!
其余的細節和上述的三次握手一樣,我們講放在后續的TCP連接管理進行說明。
PSH標志位
PSH(PUSH): 提示接收端應用程序立刻從 TCP 緩沖區把數據讀走
這個是什么意思呢?
假設今天C->S發送了報文,但是接收方可能因為上層應用層比較忙,還來不及從緩沖區中讀取相應的數據。所以就會不斷地擠壓在接收方的緩沖區內!
但是,有一些服務,是需要服務器進行快速相應的。所以,TCP的協議就規定了:
當包頭中的PSH位被設為的時候,接收方就需要盡快的把數據從接收緩沖區中讀到上層去。
舉一個場景進行理解:
比如我們通過xshell登錄的Linux云服務器主機,我們輸入的命令,其實最終都是通過網絡發送給遠端的主機,然后執行完后再返回給我們的!
而我們操作這臺主機,正常情況下肯定是希望輸入的命令能夠快速被執行的!所以,我們在xshell上輸入的命令,形成報文發送到遠端的時候,就有可能設置了PSH標志位!
RST標志位
RST(RESET): 對方要求重新建立連接; 我們把攜帶 RST 標識的稱為復位報文段
我們會發現,當在學習網絡的時候,畫雙邊通信流程圖的時候,總是習慣性把報文傳輸斜著畫過去到對方那里!這是為什么呢?
答案:因為省略了一個要素,即報文傳輸是有時間的!從上往下,時間是在不斷地后移。
我們就以雙方進行三次握手為例子:
對于主動發起連接的一方來說:它只要能夠收到對方的應答并且把自己的的應答發送出去,對于這一方來說,就可以認為自己建立連接成功了!
但是對于被動回應連接的一方,它需要等對方返回最后一次(第三次揮手)的應答成功接收后,才能認為這一方是建立連接成功!
👇
上述想說的是:
通信的雙方建立連接成功的時間是有偏差的!即對連接是否成功建立的認知不一致!
上述講那么多,是想說明什么呢?先不急,很快就出結論了:
當通信的雙方建立連接的時候,是一定能成功的嗎?不一定!
還是有一定的概率會建立失敗的!
那么,有沒有一種可能:
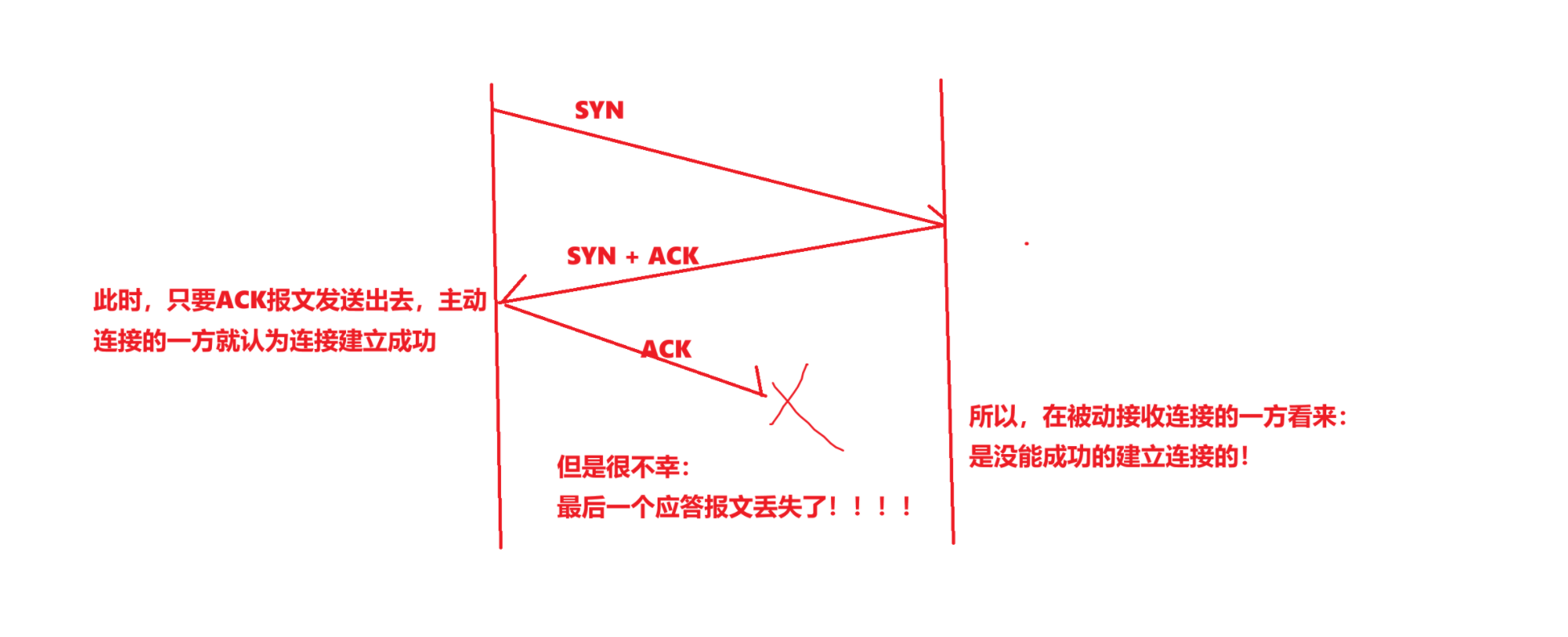
在上述的情況下(我們就假設主動發起連接的是Client,被動的是Server):
Client端認為連接建立好了!就會發送數據過去!我們知道,建立連接的過程中不能帶數據!
所以,在Server端看來:
我都沒成功建立連接啊,怎么對面發來數據了呢?所以,Server端就會在報文中的ACK位置設1,同時,RST位也設為1。等到Client看到RST=1的時候就知道,對方沒建立成功,需要重新執行連接過程,就重新進行三次握手了!
反過來服務器主動請求連接也是一樣的道理,這里就不再過多的贅述了!
16位緊急指針 && URG標志位
URG: 緊急指針是否有效
URG為1,緊急指針有效,反之無效!
那么在了解URG標志位之前,我們需要先了解什么是緊急指針!
在今天的我們看來,所謂的接收緩沖區和發送緩沖區,其實就是一個字符數組!這個數組容量比較大而已。當然,我們也可以把這么一個緩沖區當成字符隊列:
從頭出數據,從尾入數據!這就類似于一個隊列。隊列最大的特點就是有序!可以保證先到先得的特性。但是,過于追求公平性也不是什么好事!
在我們的生活中,有一些人是一定會享受到特權的:
比如排隊的時候:軍人優先、老人優先
急診治療的時候:嚴重者優先
所以,在TCP報頭中有這么一個字段:16位緊急指針:
它表示的是:當前有效載荷中,特定偏移量的位置是緊急數據,需要優先處理!
也就是說,當接收到的報文發現,URG被設置為1,就表明緊急指針有效。這個時候去可以讀取出緊急指針的值,得到一個有效載荷的偏移量。就這一個字節是緊急數據,需要“特權”!!
比如這一個字節可以是設置一個狀態碼!
當然,也可能是在一個網絡下載任務中,本來緩沖區內存的是一系列的下載的數據!如果沒有特權,那么我們后面想要暫停的時候,這個暫停信息只能在下載數據后面排隊!
這是有點好笑了,我們要停止下載,但是還得下載完才能停止。這還不如不按停止!
所以,這時候就可以采用緊急指針的做法,把對應的停止、結束等信息存放在緊急指針指向的位置!這樣子系統接收到后就會優先處理了!
當然實際上,也有別的方案來解決這個問題。這里只是提供一種思路。
帶外數據——out-of-band:
當然,在系統中,緊急數據也被稱為帶外數據!即out-of-band。
在接口send和recv的flags選項中,有這么一個選項:
MSG_OOBThis flag requests receipt of out-of-band data that would not be received in the normal datastream. Some protocols place expedited data at the head of the normal data queue, and thus this flag cannot be used with such protocols.
意思就是:
可以在flags中設置對應的選項,使用send可以發送帶外數據!使用recv可以接收帶外數據!
所謂的帶外數據,其實就是讓這個數據繞靠正常的字節流!即不會在正常數據的字節流出現!
當然,現在來說,URG這個標志位用的其實比較少!了解一下即可。

基本操作第41題)


 ARM 軟中斷, IMX6ULL 點燈)
)

:idea2025.1.3版本啟動springboot服務輸入jvm參數解決辦法)











)