Memory in LLM Agent
1 為什么需要“記憶” —— 背景與動機
??在構建 LLM Agent(Large Language Model Agent,大語言模型驅動的智能體)的過程中,“記憶”(Memory)是一個繞不開的核心問題。沒有記憶的 Agent,通常只能在有限的上下文窗口內工作,難以保持長期一致性和用戶個性化體驗。本章將從背景、動機和典型需求三個角度出發,解釋為什么記憶機制是 LLM Agent 架構的關鍵組成部分。
1.1 LLM 的上下文窗口限制
??當前主流的大語言模型(如 OpenAI GPT 系列、Anthropic Claude、Meta LLaMA、Mistral 等)都依賴 上下文窗口(Context Window) 來維持短期的對話和任務連貫性。然而,這種機制存在天然限制:
- 容量有限:即使是最新的 GPT-4o 或 Claude 3.5,窗口長度通常在 200K tokens 左右。雖然相比早期的 2K–4K 已經大幅提升,但對于長期運行的 Agent 仍然不足。
- 成本增加:窗口越大,推理延遲和計算成本越高。
- 遺忘機制缺失:LLM 在長上下文中容易“注意力稀釋”(attention dilution),導致早期信息被遺忘或誤解。
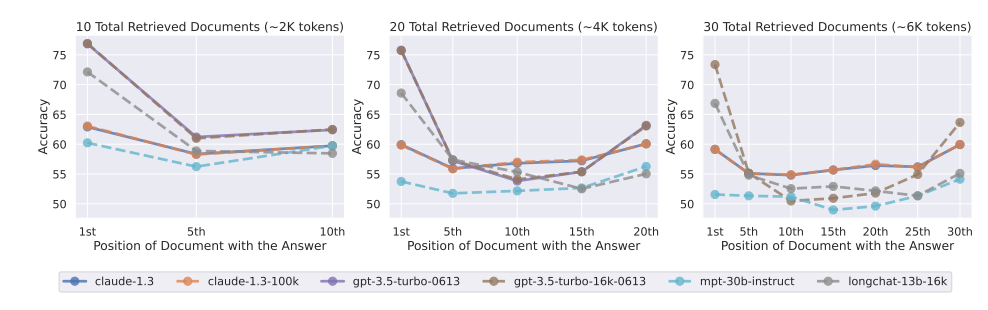
??相關研究已經表明,大模型在處理極長上下文時,性能會顯著下降。參見 Liu et al., 2024, Lost in the Middle,該論文系統性評估了 LLM 在長上下文下的檢索與推理性能。
1.2 多輪交互與長期一致性
??現實中的 Agent 需要在 多輪對話 與 長期交互 中表現穩定。例如:
- 個人助理型 Agent:需要記住用戶的偏好(如常點的外賣、常用的寫作風格)。
- 企業客服 Agent:需要追蹤客戶歷史問題,避免每次重復詢問。
- 研究型 Agent:需要在長時間的探索與迭代中保存上下文與任務鏈條。
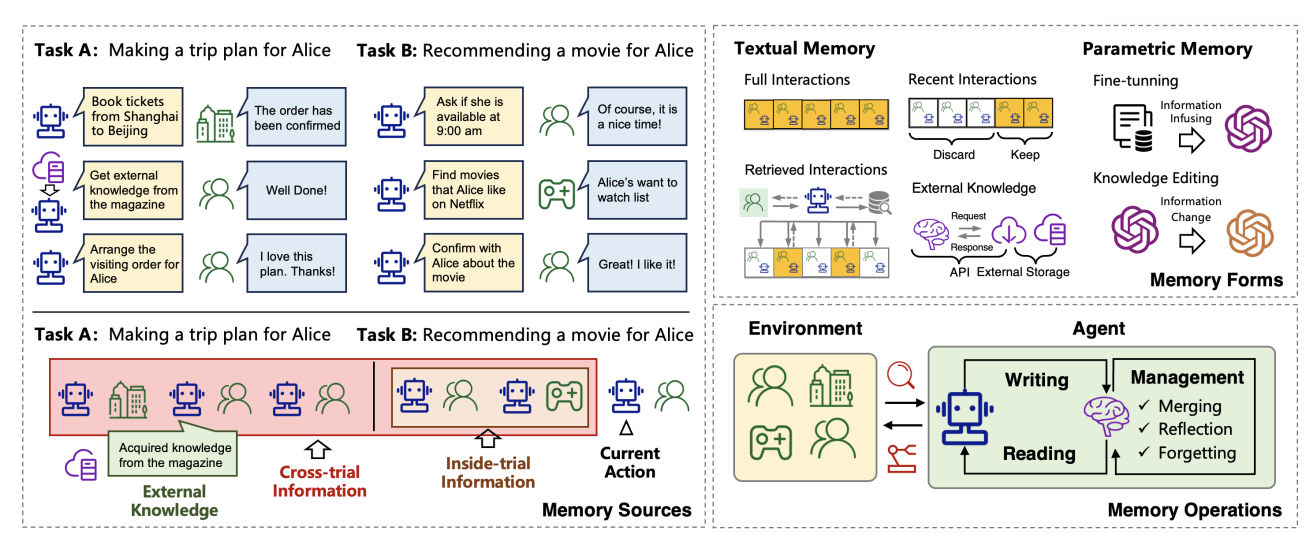
??沒有記憶機制的 LLM Agent,往往在長時間交互后失去一致性,表現出“健忘”的特征。這一點在 Zhang et al., 2024, A Survey on the Memory Mechanism of LLM-based Agents 中有系統性的總結,作者指出記憶是實現持久化和一致性的關鍵前提。
1.3 記憶能解決的關鍵問題
??引入記憶機制,能夠解決以下幾個核心挑戰:
-
個性化(Personalization) Agent 能夠基于用戶歷史行為建立“用戶畫像”,從而提供差異化服務。例如,LangChain 與 LlamaIndex 等框架已支持通過外部數據庫記錄用戶交互并進行定制化。
-
事實更新與知識演化(Knowledge Updating) 世界知識是動態變化的,例如法律法規、股票價格、科研進展。通過記憶機制,Agent 可以在不重新訓練模型的情況下,快速更新事實。相關研究見 Das et al., 2024, Larimar: LLMs with Episodic Memory。
-
糾錯與自我學習(Error Correction & Self-improvement) 通過保存過去的錯誤與修正,Agent 可以避免重復犯錯。這種“經驗回放”(experience replay)與強化學習中的記憶池類似。
-
減少冗余(Efficiency) 避免用戶多次輸入相同信息,降低 token 消耗與推理延遲。
-
提高決策質量(Decision Making) 通過跨任務回溯,Agent 能更好地推理“因果鏈”,在復雜決策問題中表現更穩定。
1.4 認知科學類比 —— 從人類記憶看 Agent 記憶
??在人類認知科學中,記憶通常分為三類:
- 情景記憶(Episodic Memory):記錄具體事件和經歷,例如一次對話。
- 語義記憶(Semantic Memory):記錄事實與概念,例如“地球圍繞太陽旋轉”。
- 程序性記憶(Procedural Memory):記錄操作與技能,例如騎自行車。
??LLM Agent 的記憶機制也可類比于以上分類:
- 情景記憶 → 保存對話歷史、事件日志;
- 語義記憶 → 保存知識庫、事實索引;
- 程序性記憶 → 保存操作策略或常用任務模版。
??這種認知框架在 Tulving, 1972, Episodic and Semantic Memory 中首次提出,對現代 LLM Agent 的記憶機制設計具有啟發意義。
1.5 RAG 與記憶的結合
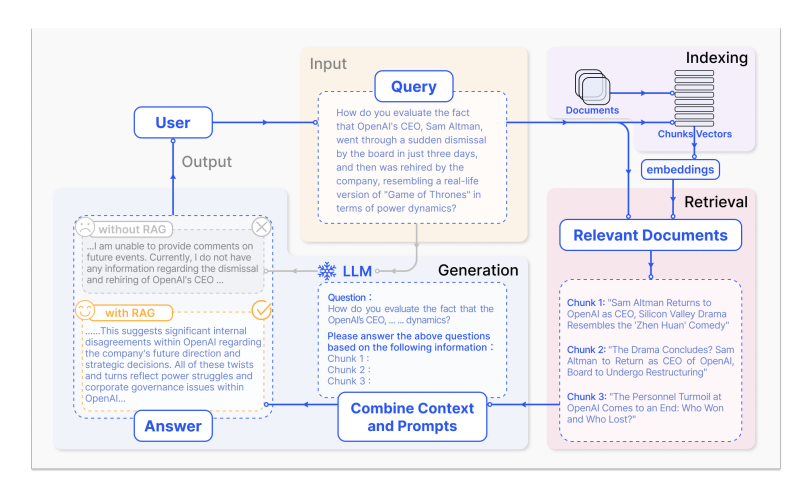
??目前的主流實踐是通過 檢索增強生成(RAG, Retrieval-Augmented Generation) 來補足 LLM 的記憶不足。
RAG 的典型流程:
- 將對話或文檔分割成 chunks
- 使用向量嵌入(embedding)存入外部向量數據庫
- 在推理時檢索相關內容并拼接到上下文
??這類方法本質上是一種“外部記憶”。其關鍵在于如何高效地選擇、壓縮和檢索信息。關于 RAG 的綜述可見 Gao et al., 2024, Retrieval-Augmented Generation for LLMs: A Survey。
??綜上所述,記憶機制對于 LLM Agent 的重要性可以歸納為三點:
- 突破上下文限制:克服 LLM 的短期記憶約束。
- 支撐長期個性化:讓 Agent 能夠在多輪、多任務中保持一致性與連續性。
- 提升可靠性與實用性:通過記憶機制,Agent 不僅能“回答問題”,還能逐步演化為“長期陪伴的智能助手”。
2 記憶的分類
??在 LLM Agent 中,“記憶”并不是單一形式,而是一個多層次、多類型的系統。合理的分類能夠幫助開發者理解不同類型記憶的作用與適用場景,從而在工程實踐中做出設計取舍。本章將從 存儲時長、功能語義 和 實現機制 三個角度,對 LLM Agent 的記憶進行系統化分類。
2.1 按存儲時長劃分
??從時間跨度的角度,可以將記憶分為三類:
-
短期記憶(Short-term Memory)
- 特點:僅在單次會話或上下文窗口內存在。
- 應用:追蹤用戶當下輸入,維持對話連貫性。
- 局限:一旦會話結束或超過窗口大小即丟失。
- 對應實現:LLM 的上下文窗口(context window)。
-
中期記憶(Mid-term Memory)
- 特點:在數小時到數周的時間跨度內保存信息。
- 應用:如個人助手在一周內記住用戶的日程安排。
- 實現方式:外部存儲 + 定期壓縮為摘要。
-
長期記憶(Long-term Memory)
- 特點:跨越數月甚至數年,支持長期個性化與知識積累。
- 應用:持續跟蹤用戶的偏好、研究進展、企業知識庫。
- 實現方式:基于向量數據庫(FAISS、Weaviate、Pinecone 等)或分布式記憶架構。
- 研究參考:Das et al., 2024, Larimar: LLMs with Episodic Memory,提出通過分布式情節記憶機制增強長期知識更新能力。
2.2 按語義/功能劃分
??從功能角度看,LLM Agent 的記憶可以類比于人類認知科學中的分類(Tulving, 1972, Episodic and Semantic Memory),主要包括:
-
情景記憶(Episodic Memory)
- 定義:記錄與用戶交互的具體事件或經歷(帶時間戳、上下文)。
- 應用:對話回溯、事件追蹤。
- 示例:用戶曾經問過“上周我提到的書名是什么?”
- 技術實現:事件日志 + 索引機制,支持基于時間和語義的檢索。
- 研究參考:Das et al., 2024, Larimar: LLMs with Episodic Memory。
-
語義記憶(Semantic Memory)
- 定義:存儲抽象化的知識、概念與事實。
- 應用:企業知識庫、FAQ 系統、科研事實數據庫。
- 示例:Agent 知道“光速約為 3×10^8 m/s”。
- 技術實現:通常與檢索增強生成(RAG)結合,基于知識庫或外部數據庫。
- 綜述參考:Gao et al., 2024, Retrieval-Augmented Generation for LLMs: A Survey。
- 程序性記憶(Procedural Memory)
- 定義:存儲操作流程、技能與策略。
- 應用:任務自動化(如執行 API 調用、腳本編排)。
- 示例:Agent 學會“如何通過 API 查詢天氣并生成報告”。
- 技術實現:通常以“工具調用鏈”(tool chain)或“執行計劃”(plan)形式保存,可與 RLHF 或 fine-tuning 結合。
- 最新應用:強化學習結合記憶回放(experience replay)機制,提高 Agent 的任務執行穩定性。
??這種三分法有助于開發者在設計時區分“事實知識”與“交互歷史”,并明確何種信息需要長期保留,何種只需臨時存儲。
2.3 按實現機制劃分
??從工程實現角度,可以將記憶機制分為以下三類:
-
外部檢索型記憶(External Retrieval-based Memory)
- 原理:通過外部數據庫(如向量庫、知識圖譜)存儲信息,LLM 僅在推理時調用。
- 優點:易擴展、易更新,不需要修改 LLM 參數。
- 缺點:依賴檢索質量,可能出現 recall/precision 失衡。
- 案例:RAG(Retrieval-Augmented Generation)。
- 技術綜述:Gao et al., 2024, RAG Survey。
-
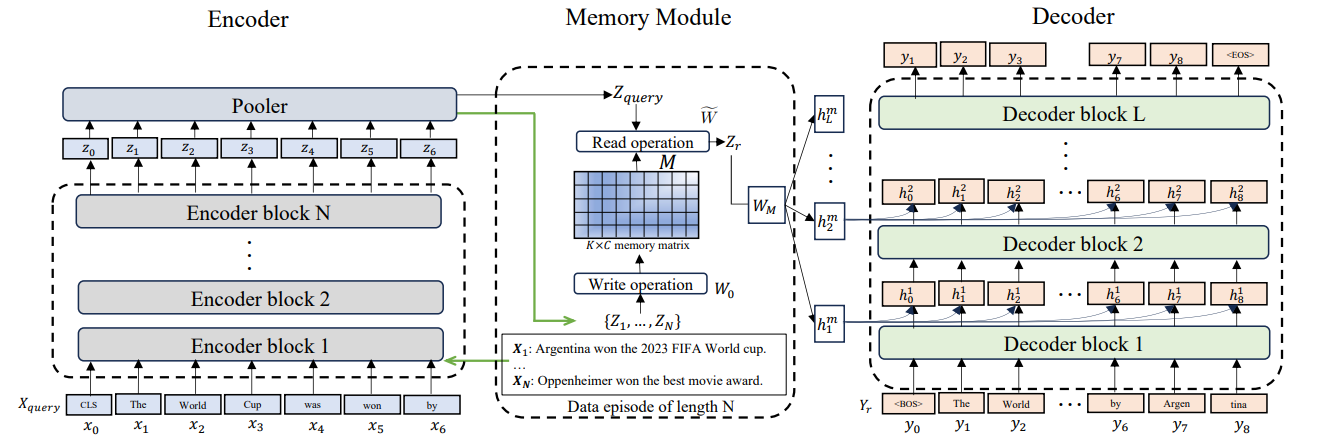
內嵌/可微分記憶(Differentiable / Model-internal Memory)
- 原理:在模型結構中直接集成記憶模塊,例如 Memory-augmented Transformer、Recurrent Memory。
- 優點:高效、一體化,能夠端到端學習。
- 缺點:訓練和推理成本高,更新不靈活。
- 代表性研究:Chen et al., 2024, Recurrent Memory Transformer(arXiv:2207.06881)。
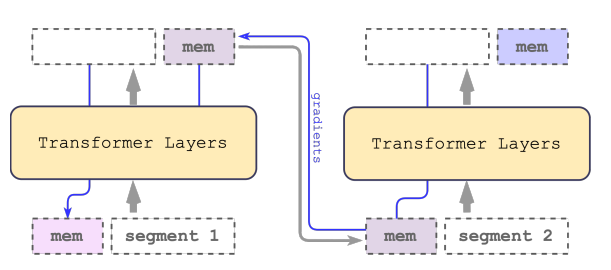
- 混合型記憶(Hybrid Memory)
- 原理:結合外部檢索和內部記憶,例如先用外部向量庫存儲詳細事件,再用模型內部記憶存儲高層抽象。
- 優點:兼顧可擴展性與推理效率。
- 案例:LangChain / LlamaIndex 框架支持“摘要 + 原始記錄”的混合存儲方式。
- 最新研究:Wang et al., 2024, EMG-RAG: Crafting Personalized Agents through Retrieval from Smartphone Memories(arXiv:2409.19401)。
??通過上述三個維度的分類,可以看出 LLM Agent 的記憶并非單一模塊,而是一個 多層次的存儲系統。在實際工程中,往往需要:
- 結合時長分類:短期上下文結合長期數據庫;
- 結合語義分類:情景記憶輔助個性化,語義記憶提供知識支撐,程序性記憶提高執行力;
- 結合機制分類:外部存儲保證擴展性,內部記憶保證實時性,混合架構平衡二者。
3 主要技術路線與實現機制
3.1 檢索增強生成(RAG, Retrieval-Augmented Generation)
??RAG 是目前最廣泛應用的記憶實現方式。它通過將外部知識(文檔、對話歷史、數據庫內容等)存儲在 向量數據庫 中,并在生成時檢索相關內容,再拼接到 LLM 的上下文中,從而突破 LLM 固有的上下文窗口限制。
核心流程:
- 分塊(Chunking):將原始信息切分為合適粒度的片段(100–500 tokens 常見)。
- 嵌入(Embedding):使用專門的 embedding 模型(如 OpenAI text-embedding-3-large、Cohere Embed、BGE)將文本轉化為向量。
- 存儲(Indexing):將向量存儲在數據庫(FAISS、Weaviate、Pinecone、Milvus 等)。
- 檢索(Retrieval):在生成時基于查詢語義找到最相關的信息。
- 拼接(Augmentation):將檢索結果注入到 prompt,交由 LLM 生成最終回答。
工程注意點:
- Chunk 大小:過小會導致語義丟失,過大會浪費 token。
- 檢索精度:需要 reranker(如 BERT-based ranker)進行二次篩選。
- 上下文預算:僅選擇最相關的 top-k 結果,避免冗余。
參考Gao et al., 2024, Retrieval-Augmented Generation for Large Language Models: A Survey(arXiv:2312.10997)
3.2 事件/情景記憶(Episodic Memory)
??情景記憶記錄的是 用戶與 Agent 的交互歷史,類似人類的“經歷”。不同于 RAG 主要聚焦于知識檢索,episodic memory 強調 時間序列性 和 上下文回溯。
實現方式:
- 原始記錄存儲:保存完整的對話/事件日志。
- 摘要壓縮(Summarization):對長對話進行多層次摘要,減少存儲和檢索開銷。
- 元數據(Metadata)索引:增加時間戳、情境標簽、情感標簽等,便于多維度檢索。
應用場景:
- “上次會議我們討論了什么?”
- “幫我回顧一下昨天寫的代碼思路。”
Das et al., 2024, Larimar: Large Language Models with Episodic Memory(arXiv:2403.11901):提出基于分布式情景記憶機制,支持跨會話追蹤與學習。
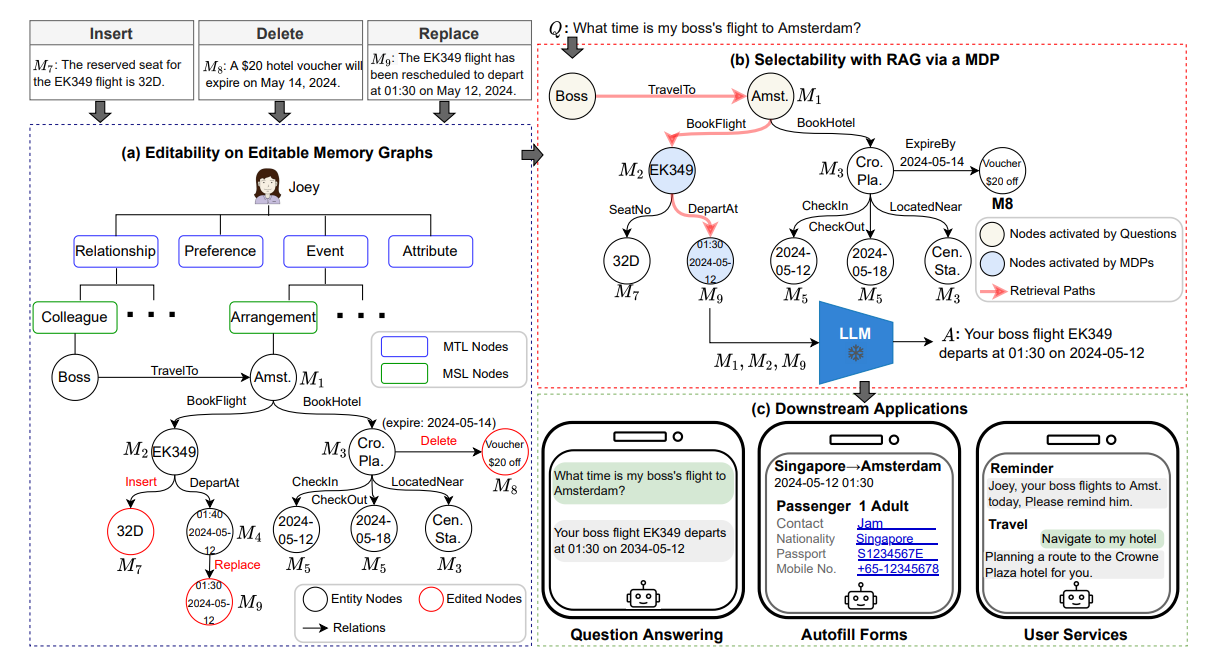
3.3 可編輯記憶與知識更新(Memory Editing)
??現實中的知識不斷演變,Agent 的記憶需要 動態更新。例如,當用戶搬家后,舊地址應被刪除或覆蓋,否則會導致錯誤推薦。
實現機制:
- 直接覆蓋:在向量庫中刪除舊條目,插入新條目。
- 事實糾錯(Knowledge Editing):通過精調或局部 LoRA 注入新知識。
- 索引更新:更新嵌入向量,以反映新的知識狀態。
- Meng et al., 2022, Locating and Editing Factual Associations in LLMs(ROME 方法)
- Das et al., 2024, Larimar: Large Language Models with Episodic Memory(arXiv:2403.11901):強調 episodic memory 的動態可更新性。
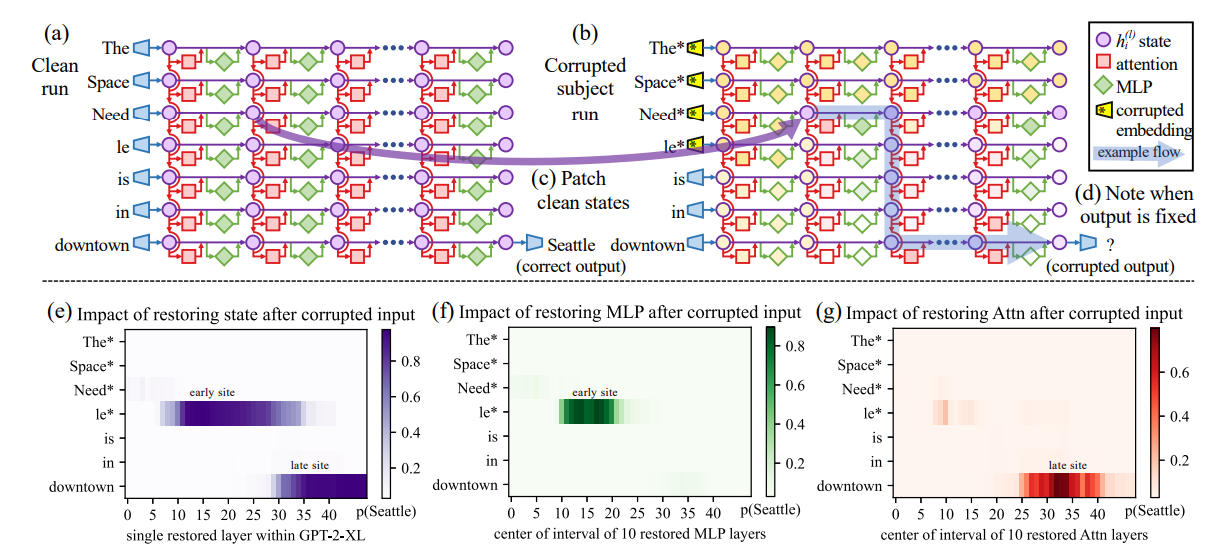
3.4 學習型記憶(Differentiable / Model-internal Memory)
??與 RAG 依賴外部存儲不同,學習型記憶直接將“記憶模塊”融入模型架構中,使其能夠端到端訓練。
??方法:
- 可微分記憶網絡(Memory Networks, Neural Turing Machines):早期方法,可對外部存儲進行可微訪問。
- Recurrent Memory Transformer:在 Transformer 結構中加入循環記憶單元,用于長期依賴建模。
- Stateful Inference:通過緩存和遞歸機制,在推理過程中維持狀態。
??優缺點:
- 優點:高效、緊密集成,避免外部依賴。
- 缺點:訓練成本高,更新困難。
Chen et al., 2024, Recurrent Memory Transformer(arXiv:2404.11699)。
3.5 多模態與具身 Agent 的記憶
??對于機器人或虛擬代理,僅有文本記憶是不夠的。它們需要整合 多模態數據(圖像、語音、動作序列等),形成“具身記憶”。
??實現方式:
- 視覺快照 + 文本描述:結合 CV 模型提取圖像特征,與文本一起存儲。
- 狀態日志:記錄物理狀態(位置、傳感器數據)。
- 檢索增強:在執行任務時檢索過往操作軌跡,避免重復錯誤。
Li et al., 2024, Retrieval-Augmented Embodied Agents (RAEA)(arXiv:2403.09499):提出在具身任務中引入檢索機制,顯著提升長期推理與任務執行。
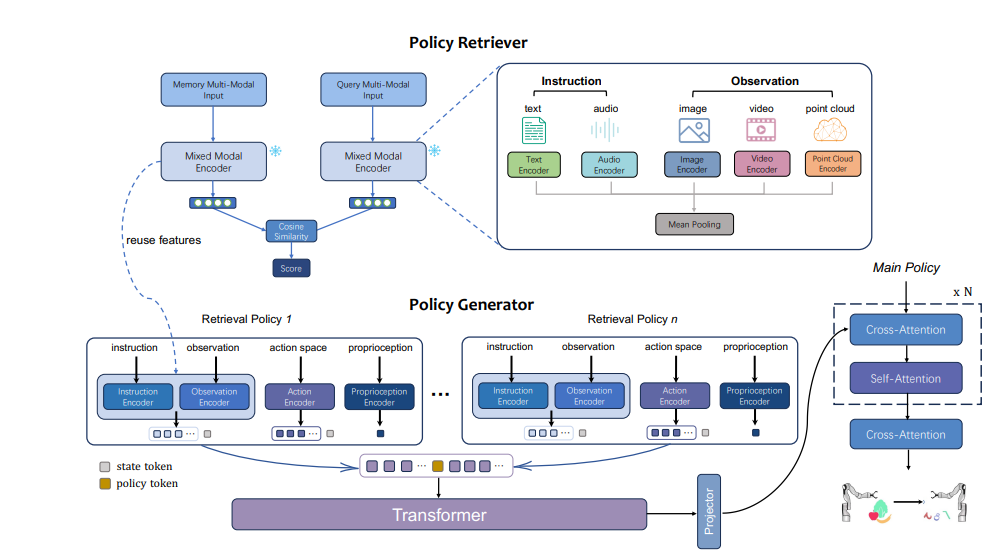
3.6 工程化的記憶堆棧(Memory Stack in Practice)
??在實際工程系統中,LLM Agent 的記憶通常由多個層次堆疊而成:
- 緩存層(Cache Layer):短期存儲最近對話,低延遲、高速。
- 向量檢索層(Vector Store):中長期存儲,支持高維檢索與擴展。
- 摘要層(Summary Layer):壓縮存儲歷史,減少冗余。
- 日志與審計層(Audit Layer):保證可追蹤性和可控性。
??例如,LangChain 和 LlamaIndex 提供了 Memory 模塊,允許開發者選擇不同的存儲與檢索策略,形成“組合式記憶體系”。
??LLM Agent 記憶的主要實現模式:
- RAG:解決外部知識調用問題,靈活高效。
- Episodic Memory:增強交互的連續性與個性化。
- Memory Editing:保證知識動態更新。
- Differentiable Memory:探索端到端集成的未來方向。
- Multimodal & Embodied Memory:面向機器人與多模態 Agent 的新興實踐。
- 工程化 Memory Stack:現實系統的綜合性解決方案。
4 記憶的管理策略(Policy)——什么時候寫、讀、忘
??然而,“是否具備記憶” 并不是唯一問題,更關鍵的是 “如何管理記憶”。如果沒有合理的管理策略,記憶會出現以下問題:
- 記憶冗余,導致檢索效率下降;
- 信息沖突,造成回答不一致;
- 上下文過載,增加 token 成本;
- 隱私和合規風險。
??因此,Agent 必須具備 寫入(Write)、讀取(Read)、遺忘(Forget) 三方面的策略。本章將介紹各類策略、工程實現方式,以及相關研究成果。
4.1 寫入策略(Write Policy)
??Agent 并不是接收到所有信息都要寫入記憶,否則會造成“信息過載”。 關鍵在于 何時寫入 和 寫入什么。常見策略:
-
全量記錄
- 保存所有交互、上下文。
- 優點:完整性高,方便追溯。
- 缺點:存儲和檢索成本極高。
-
觸發式寫入
- 僅當滿足特定條件時才寫入,例如:
- 用戶顯式標記為“重要”
- 檢測到新的事實(如用戶提供了電話號碼、偏好)
- 達到設定的時間或會話節點
- 代表性工作:LangChain 中的
ConversationBufferMemory與ConversationSummaryMemory
- 僅當滿足特定條件時才寫入,例如:
-
摘要式寫入
- 將冗長的對話內容壓縮為摘要,再存入記憶。
- 參考:Zhang et al., 2023, MemoryBank: Enhancing LLMs with Long-Term Memory (arXiv:2305.10250) 提出通過多層次摘要減少冗余。
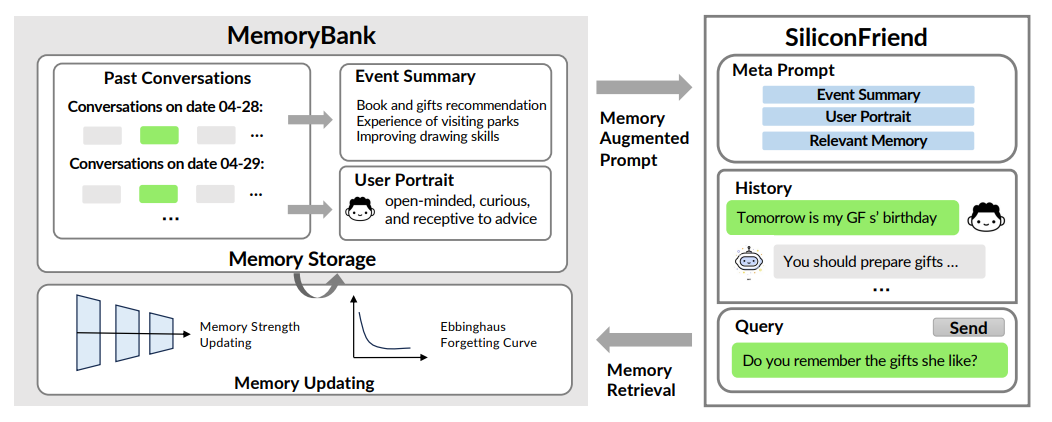
??工程化需要注意的點:
- 事實與觀點區分:用戶表達的臨時情緒不一定要寫入長期記憶。
- 知識更新機制:當新事實出現時,應考慮覆蓋舊內容。
4.2 讀取策略(Read Policy)
??即便存儲了大量信息,也必須決定在 生成時讀取哪些記憶,否則會造成上下文過載。常見策略:
-
基于向量檢索的選擇
- 檢索與當前 query 最相關的 top-k 記憶。
- 可結合 reranker 提升準確率。
-
基于上下文的動態裁剪
- 根據 prompt 的 token 限制,優先保留高相關度內容。
- 例如 Anthropic 的 Contextual Compression 技術,通過 LLM 自身對候選記憶進行壓縮再拼接。
-
基于記憶類型的分層檢索
- 例如優先檢索 episodic memory(用戶交互歷史),其次是 semantic memory(知識庫),再結合 working memory。
- 類似人腦的“分層激活”。
- Gao et al., 2024, RAG Survey (arXiv:2312.10997) 總結了不同檢索策略的性能差異。
4.3 遺忘策略(Forget Policy)
??如果所有記憶都永久保存,將導致:
- 存儲與檢索開銷過大
- 知識過時,答案可能錯誤
- 隱私風險加劇
??因此,Agent 需要具備“遺忘”機制。常見策略:
-
基于時間的衰減(Time Decay)
- 設定記憶有效期,超過時限自動歸檔或刪除。
- 適合用戶臨時性需求(如一次性驗證碼)。
-
基于使用頻率的遺忘(Usage-based Forgetting)
- 類似緩存替換策略(LRU, LFU)。
- 被頻繁訪問的記憶保留,長期不用的逐步淘汰。
-
基于重要度的遺忘
- 由模型評估記憶的重要性(例如是否包含核心事實)。
- 不重要的信息會被丟棄或轉為摘要。
-
人工觸發遺忘
- 用戶可以顯式要求刪除或更新(符合 GDPR / CCPA 合規要求)。
Das et al., 2024, Larimar: Large Language Models with Episodic Memory (arXiv:2403.11901) 提出了基于“記憶重加權”的動態遺忘機制。
Khandelwal et al., 2020, Generalization through Memorization (arXiv:1911.00172) 指出長期保留低價值記憶會影響模型泛化。
4.4 綜合記憶管理框架
??在實際工程中,寫、讀、忘需要配合,形成完整的記憶管理閉環。一個典型的框架包括:
-
寫入層
- 原始記錄 + 摘要存儲
- 觸發式保存重要信息
-
讀取層
- 多通道檢索(向量檢索 + 語義 rerank + 上下文壓縮)
- 動態裁剪
-
遺忘層
- 時間衰減 + 使用頻率 + 重要性權重
- 人工可控
??這種 策略組合 已在 LangChain、LlamaIndex、MemGPT 等系統中得到應用。
- 例如,MemGPT(Wu et al., 2023, arXiv:2310.08560)實現了“多層內存管理”,支持自動寫入、裁剪和遺忘。
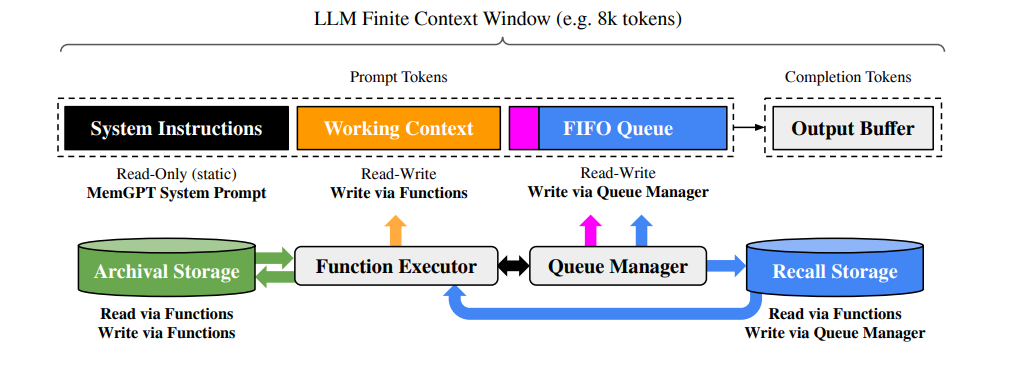
記憶管理策略是 LLM Agent 的核心機制之一,其目標是:
- 寫入時:避免冗余,確保重要信息被保留
- 讀取時:高效檢索,保證生成相關性
- 遺忘時:動態清理,提升系統健康度與合規性
??可以說,記憶管理是讓 LLM Agent 從“記憶一切的黑盒”走向“有序思考的智能體”的關鍵一步。
5 評估指標與基準
??在設計與實現 LLM Agent 的記憶機制后,一個不可或缺的問題是:如何評估記憶的有效性與質量?
僅靠功能實現并不能保證系統的實用性和魯棒性。評估指標與基準(Benchmark)為開發者提供了 可量化的對比標準,有助于發現不足、優化策略,并推動領域發展。
5.1 評估的核心目標
??記憶評估的核心目標可以概括為以下幾個方面:
-
準確性(Accuracy)
- 記憶是否能夠被正確檢索與復現?
- 示例:當用戶詢問“我昨天告訴你的會議時間是什么?”時,Agent 能否正確回答。
-
完整性(Completeness)
- 記憶是否覆蓋了所有關鍵信息,而非僅僅部分片段?
- 評估指標通常與 召回率(Recall) 相關。
-
時效性(Timeliness)
- 記憶能否反映最新的事實?是否存在“知識過時”問題?
-
相關性(Relevance)
- 在檢索過程中,Agent 是否能夠挑選出與當前任務最相關的記憶,而不是冗余或噪聲信息。
-
效率(Efficiency)
- 檢索延遲和存儲開銷是否可接受?
- 對于在線 Agent,延遲直接影響用戶體驗。
-
一致性與穩定性(Consistency & Robustness)
- Agent 在不同時間訪問同一記憶時,回答是否穩定一致?
- 遇到沖突信息時,能否給出合理解釋。
-
合規性與隱私(Compliance & Privacy)
- 是否支持用戶刪除/修改記憶(GDPR, CCPA 要求)?
- 是否存在敏感數據泄露的風險?
5.2 常用評估指標
??定量指標
-
檢索準確率(Precision@k) :在 top-k 檢索結果中,有多少條與查詢真正相關。
-
召回率(Recall@k) : 檢索出的相關結果占所有相關結果的比例。
-
F1-score : 平衡準確率和召回率的指標。
-
延遲(Latency) : 記憶寫入/讀取的時間開銷。
-
覆蓋率(Coverage) : 長期交互中,Agent 是否遺漏了用戶提供的重要事實。
-
漂移率(Drift Rate) : 舊知識被新知識覆蓋的程度,以及錯誤保留的比例。
??定性指標
-
人類評估(Human Evaluation) : 人類標注員判斷 Agent 是否正確調用了歷史記憶。
-
用戶滿意度(User Satisfaction) : 用戶主觀打分,例如對連續對話的“上下文感知”體驗。
-
解釋能力(Explainability) : Agent 是否能解釋記憶的來源(例如“這是你上次在 9 月 1 日告訴我的”)。
5.3 基準數據集與評測任務
??近年來,多個基準任務專門針對 LLM Agent 的記憶能力進行評估:
-
MemBench
- Xu et al., 2024, MemBench: Towards More Comprehensive Evaluation on the Memory of LLM-based Agents ([arXiv:2506.21605](https://arxiv.org/abs/2506.21605))
- 提供一系列任務,包括事實記憶、對話記憶和更新/刪除操作,全面評估 Agent 的記憶管理能力。
-
LongBench
- Bai et al., 2023, LongBench: A Benchmark for Long Context Understanding (arXiv:2308.14508)
- 主要測試長上下文能力,與記憶相關,因為良好的記憶管理能降低對超長上下文的依賴。
-
MemGPT Evaluation
- Wu et al., 2023, MemGPT: Towards LLMs as Operating Systems (arXiv:2310.08560)
- 在多會話交互中測試 Agent 的多層內存管理效果。
-
Episodic Memory Benchmarks
- Das et al., 2024, Larimar: LLMs with Episodic Memory (Das et al., 2024, Larimar: LLMs with Episodic Memory)
- 專注于跨會話追蹤與長期交互任務。
5.4 評估流程與方法學
??一個典型的記憶評估流程包括:
-
數據準備
- 構建交互歷史(對話、事件日志等)。
- 插入事實更新、沖突信息、無關干擾信息。
-
任務設定
- 提出查詢,要求 Agent 調用歷史記憶。
- 設置刪除或修改請求,驗證其是否遵循遺忘策略。
-
自動評估 + 人工驗證
- 使用 Precision/Recall/F1 等自動指標。
- 輔以人工標注,驗證復雜語境下的記憶調用質量。
-
多維度分析
- 分別考察準確性、效率、穩定性、合規性。
5.5 工程實踐中的評估挑戰
??在真實系統中,評估記憶還面臨以下挑戰:
- 動態環境:用戶需求和知識隨時間演變,靜態基準難以覆蓋。
- 多模態數據:文本、圖像、語音混合場景評估標準尚不統一。
- 長時間交互:當前多數基準只覆蓋幾小時到幾天的交互,而真實應用可能跨數月甚至數年。
- 用戶隱私:評估過程中必須保護用戶敏感數據,不可隨意公開存儲。
??記憶評估是 LLM Agent 研發中不可或缺的一環。
- 指標層面:需要平衡準確性、完整性、效率與合規性。
- 基準層面:SORT、MemBench、LongBench 等為研究提供了客觀對比平臺。
- 實踐層面:評估必須結合動態更新、多模態輸入和隱私保護。
6 風險、合規與隱私
??隨著 LLM Agent 逐漸在企業、醫療、金融、教育等關鍵領域落地,記憶機制的風險與合規問題 成為必須重點考慮的部分。 記憶可以顯著提升用戶體驗,但同時也帶來 數據安全、隱私保護、合規性 等多方面的挑戰。
本章將從風險識別、合規標準、隱私保護以及最新研究進展展開分析。
6.1 記憶機制帶來的主要風險
-
隱私泄露(Privacy Leakage)
- Agent 在長期交互中會保存用戶的敏感信息(地址、聯系方式、醫療記錄等)。
- 若缺乏適當的保護機制,這些信息可能被錯誤調用、外泄或濫用。
- 相關研究:Carlini et al., 2021, Extracting Training Data from Large Language Models (arXiv:2012.07805) 顯示 LLM 可能在生成時泄露訓練數據。
-
知識過時與錯誤傳播(Stale/Incorrect Memory)
- 已過期的信息未被遺忘,可能導致決策錯誤。
- 示例:用戶搬家后地址未更新,Agent 仍使用舊數據。
-
數據濫用與不當持久化(Misuse of Data Persistence)
- 如果沒有嚴格的“最小化存儲原則”,系統可能存儲過量數據,增加風險面。
-
黑箱性與不可控性(Opacity and Lack of Control)
- 用戶難以知道 Agent 具體保存了哪些信息。
- 缺少透明的記憶管理接口,增加了信任成本。
-
推理中的偏見與歧視(Bias in Memory-based Reasoning)
- 長期存儲的記憶若包含偏見,會在生成中被不斷強化。
6.2 法規與合規要求
各國和地區針對數據保護和隱私有明確的法律框架,LLM Agent 的記憶設計必須遵循.
6.3 隱私保護的技術手段
-
數據加密與安全存儲
- 使用端到端加密保護存儲在記憶中的數據。
- 對檢索和索引數據應用加密搜索(如安全向量檢索)。
-
差分隱私(Differential Privacy, DP)
- 在數據存儲或訓練時引入噪聲,降低重識別風險。
- 參考:Abadi et al., 2016, Deep Learning with Differential Privacy (arXiv:1607.00133)。
-
聯邦學習(Federated Learning)與本地存儲
- 將記憶存儲在用戶設備端,僅在必要時共享嵌入或摘要。
- 避免服務器端集中存儲帶來的泄露風險。
-
可控遺忘(Machine Unlearning)
- 提供技術手段讓系統主動刪除某條記憶,并保證不可恢復。
- 參考:Golatkar et al., 2023, Machine Unlearning in LLMs (arXiv:2405.15152)。
-
訪問控制與審計機制
- 通過訪問日志和權限管理,確保只有被授權的模塊才能調用敏感記憶。
6.4 最新研究與發展趨勢
-
隱私感知型記憶架構
- 研究重點轉向如何在保證功能性的同時,自動識別并標注敏感信息。
-
可解釋記憶(Explainable Memory)
- 提供用戶接口,展示哪些信息被保存、何時被調用。
- 類似“記憶透明化面板”,提升用戶信任度。
-
合規性自動檢查工具
- 引入合規模型,對記憶寫入/讀取進行實時檢測,確保滿足 GDPR/CCPA/PIPL 要求。
-
跨模態隱私保護
- 具身 Agent 中涉及圖像、語音等多模態數據,研究如何在多模態記憶中進行隱私隔離。
7 總結與展望
7.1 核心觀點回顧
-
記憶的本質
- 記憶是 LLM Agent 在長時交互中實現“連續性”和“個性化”的關鍵。
- 從短期上下文緩存(Context Window)到長期持久化存儲(Vector DB、Knowledge Base),記憶讓 Agent 超越單次調用的限制。
-
記憶的類型與機制
- 短期記憶:基于上下文窗口的即時信息。
- 長期記憶:借助向量數據庫、索引檢索機制保存用戶信息。
- 工作記憶:用于任務執行階段的動態存儲。
- 這些機制的有機組合,塑造了智能體的“人格”和“認知連續性”。
-
記憶的管理策略(Policy)
- 何時寫:避免冗余,關注高價值事件。
- 何時讀:結合檢索與注意力機制,平衡效率與準確性。
- 何時忘:引入“遺忘”機制,減少過時或無用數據干擾。
-
評估指標與基準
- 從 準確性、覆蓋率、效率、魯棒性 等多個維度評估記憶質量。
- 新興基準(如 MemBench, LongMemEval)為系統化對比提供了工具。
-
風險與合規
- 隱私泄露、數據濫用、知識過時是記憶系統的核心風險。
- 必須遵循 GDPR、CCPA、PIPL 等法規,結合差分隱私、機器遺忘等技術進行防護。
- 可解釋與可控的記憶接口將成為提升用戶信任的關鍵。
8.2 發展趨勢
-
隱私感知與合規模塊化
- 未來的 Agent 將在記憶模塊中內置合規檢測和隱私保護能力,避免人工審計的高成本。
-
個性化與普適性平衡
- 如何既滿足用戶高度個性化的需求,又保證跨用戶的普適性,是長期研究方向。
-
多模態記憶
- 隨著 Agent 能處理圖像、語音、視頻,記憶將不再局限于文本,如何實現跨模態一致性與隱私保護成為新挑戰。
-
人機共管記憶
- 提供用戶可操作的記憶面板,讓用戶參與“選擇、刪除、標注”,提升透明度和信任度。
-
評估基準標準化
- 隨著學術界與工業界合作,未來將出現統一的 Agent Memory Benchmark,推動系統橫向對比和優化。
8.3 對開發者的建議
- 在設計記憶系統時,始終堅持 最小化原則(僅保存必要信息)。
- 引入 可控遺忘機制,保證用戶能隨時刪除不需要的記憶。
- 在項目早期就考慮 合規性和風險控制,而不是在部署后再補救。
- 關注最新研究與開源框架,如 LangChain Memory、MemGPT、MemBench 等,結合工程需求選擇合適方案。
8.4 總結
??記憶賦予 LLM Agent 連續性、個性化與智能性,是未來智能體發展的重要基石。然而,記憶并非越多越好,而是需要在 功能、效率、隱私與合規 之間尋找平衡點。可以預見,未來的 LLM Agent 將走向:
- 更加人性化 —— 記得用戶的習慣、偏好和歷史,提供自然的交互體驗。
- 更加透明與合規 —— 用戶能掌控自己的數據,系統自動滿足法律與道德要求。
- 更加智能與可靠 —— 記憶成為增強推理和任務執行的重要支撐,而非風險來源。
??最終,記憶不僅是技術問題,更是信任問題。 構建安全、透明、合規的記憶系統,將是推動 LLM Agent 真正走向大規模應用的核心關鍵。
)

)


】系統可靠性分析與設計詳解:構建高可用軟件系統的核心技術)
+ 最小棧解決方案)





)






》)