文章目錄
文章目錄
- 01 內容概要
- 02 部分代碼
- 03 代碼解讀
- 04 運行結果
- 05 基于XGBoost算法的數據回歸預測源碼
01 內容概要
XGBoost屬于集成學習中的Boosting方法,其基本思想是:
逐步構建多個弱學習器(通常是CART決策樹),每一棵樹都試圖糾正前一棵樹的殘差(預測誤差),最終將所有樹的輸出加權求和,得到強學習器。
02 部分代碼
%% 清空環境變量
warning off % 關閉報警信息
close all % 關閉開啟的圖窗
clear % 清空變量
clc % 清空命令行
%% 導入數據
res = xlsread('數據集.xlsx');
%% 劃分訓練集和測試集
temp = randperm(103);
P_train = res(temp(1: 80), 1: 7)';
T_train = res(temp(1: 80), 8)';
M = size(P_train, 2);
P_test = res(temp(81: end), 1: 7)';
T_test = res(temp(81: end), 8)';
N = size(P_test, 2);
%% 數據歸一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 建立模型
model = xgboost_train(p_train, t_train, params, num_trees);
%% 預測
t_sim1 = xgboost_test(p_train, model);
t_sim2 = xgboost_test(p_test , model);03 代碼解讀
下面把代碼拆成 8 個關鍵動作,每步用 2-3 句話“展開”說明,方便你快速對應到腳本里的位置。
1.清空環境
關掉彈窗、清變量、清命令行,防止上一趟跑完的圖或數據干擾這次結果。
2.讀 Excel
xlsread 把整個數字區域一次性讀進矩陣 res,行是樣本,列是“7 個特征 + 1 個目標”。
3.隨機拆 80/23
randperm(103) 做隨機索引,前 80 行當訓練集,后 23 行當測試集,避免人為挑數據帶來的偏倚。
4.歸一化到 0-1
mapminmax 把 7 維特征和 1 維目標分別線性壓縮到 [0,1];訓練集得到的“映射結構” ps_input/ps_output 會被保存下來,保證測試集和反歸一化時用的是同一套比例,防止信息泄露。
5.搭 XGBoost 參數并訓練
把學習率、樹深度、任務類型(reg:linear)寫進結構體 params,再告訴它迭代 100 輪;xgboost_train 返回的 model 就是一棵“加法樹” ensemble。
6.預測 + 反歸一化
用 xgboost_test 對訓練集和測試集各跑一次,得到 0-1 區間的預測值;接著用 mapminmax('reverse', ...) 把數據拉回原始量綱,才能跟真實值算誤差。
7.算誤差、畫兩張折線
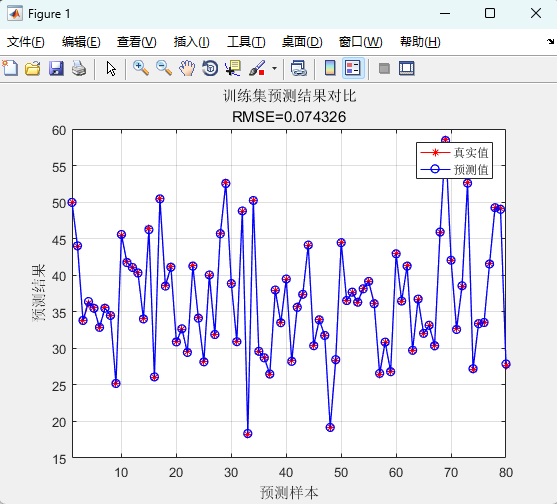
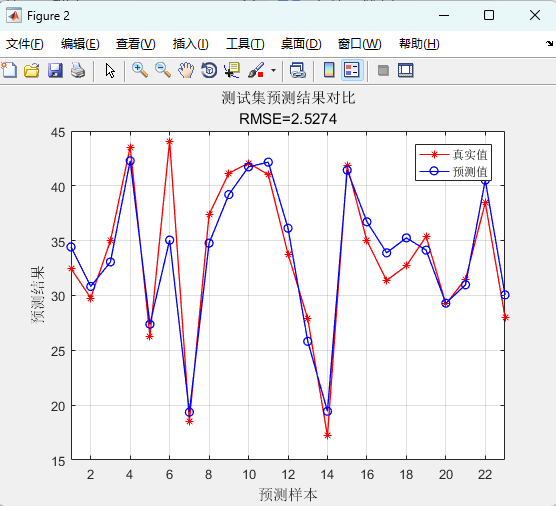
RMSE 看整體偏差,R2 看擬合度,MAE 看平均絕對誤差,MBE 看系統偏高還是偏低;折線圖把真實值與預測值按樣本順序擺在一起,一眼就能瞧見哪里跑偏。
8.畫散點圖
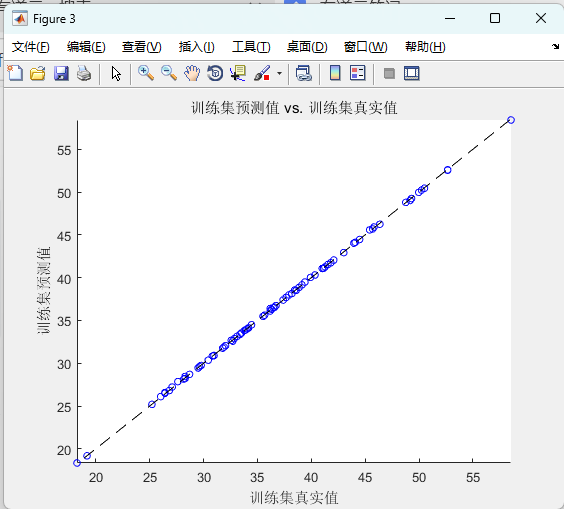
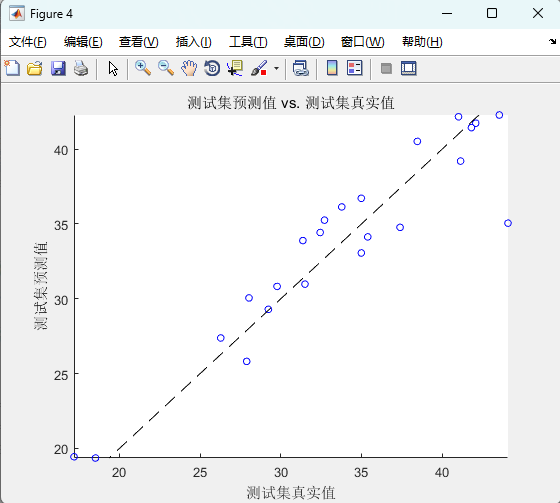
橫軸真值、縱軸預測,理想情況下點應落在對角線上;散點圖比折線圖更能直觀看出“在哪個區間模型容易高估或低估”。
04 運行結果
05 基于XGBoost算法的數據回歸預測源碼
提供了Matlab的實現代碼,使得用戶可以根據自己的需求進行調整和應用。
Matlab代碼下載地址

)

)


】系統可靠性分析與設計詳解:構建高可用軟件系統的核心技術)
+ 最小棧解決方案)





)





