在分布式數據平臺(如 Databricks + Spark)中跑視頻處理任務時,你是否遇到過這種惡心的報錯?
Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe. : org.apache.spark.SparkException: Python worker exited unexpectedly (crashed): Fatal Python error: Segmentation fault
這不是 Python 代碼寫錯了,而是 底層 C/C++ 擴展(OpenCV/NumPy/FFmpeg)崩潰,直接觸發 SIGSEGV。問題在于:
👉 Python 的 try/except 根本捕獲不到這類崩潰,因為解釋器還沒來得及拋異常就被操作系統殺掉了。
結果就是:
整個 Spark Task 掛掉
分區里所有文件的結果丟失
任務反復重試,最終 Stage 失敗
今天我就帶大家看看 如何用子進程隔離(subprocess/multiprocessing)機制,優雅規避 OpenCV 的崩潰,并且保證分布式任務健壯運行。
1、為什么 OpenCV 在 Spark 里容易崩潰?
多線程沖突
OpenCV 默認開啟 OpenMP 線程池 (cv2.setNumThreads(8)),而 Spark Executor 本身也有并行任務。多層并發疊加,容易踩內存。FFmpeg 兼容問題
Databricks Runtime 的 FFmpeg/Ubuntu 依賴和opencv-python編譯參數可能不一致,導致 VideoCapture 解碼異常。視頻文件問題
即使ffprobe驗證過,輕微損壞或不支持的編碼格式也可能讓 OpenCV 在解碼時崩潰。
👉 這些都屬于 底層 C 庫 bug,Python 級別的 try/except 根本無能為力。
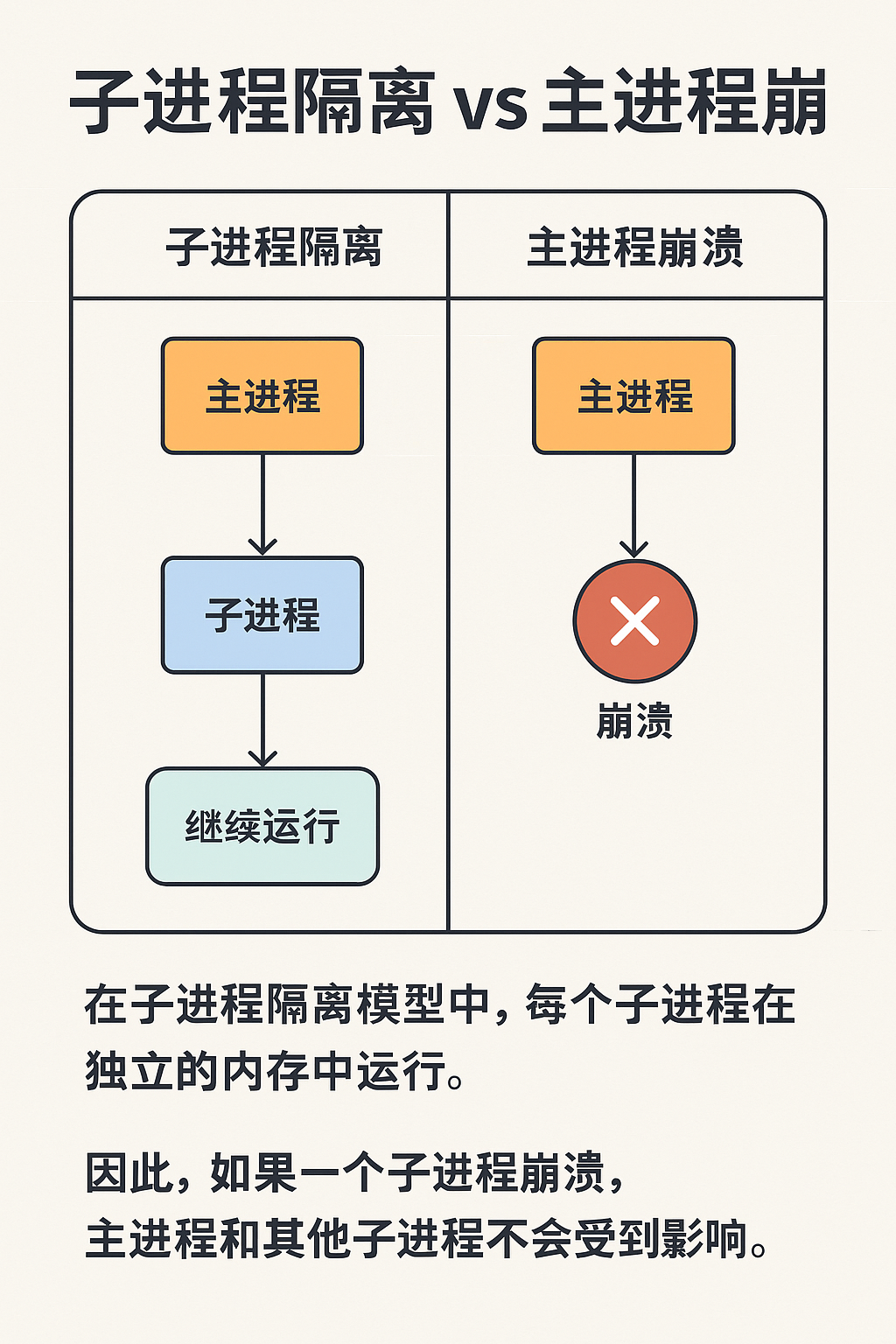
2、解決思路:子進程隔離(Crash Isolation)
核心原理:
用 子進程(獨立 Python 解釋器)運行不穩定的 OpenCV 代碼
如果子進程崩潰(退出碼 -11 = SIGSEGV),只影響它自己
父進程還能捕獲退出碼,記錄錯誤,更新數據庫狀態為
FAILED,并繼續跑其他文件
這就好比給 OpenCV 套了個“防爆盾牌”:它崩潰歸它崩潰,主進程和 Spark Executor 不被拖死。
3、實現代碼
以下示例展示了如何改造 單攝像頭視頻處理函數,用 multiprocessing 包裹 OpenCV 操作:
import multiprocessing as mp
import datetime, os
import cv2class NonRetryableError(Exception):"""不可重試的異常:用于標記為FAILED"""passdef process_single_camera_video_executor(video_path, output_dir):"""Executor端:處理單攝像頭視頻,使用multiprocessing隔離OpenCV崩潰"""timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]print(f"[{timestamp}] [VIDEO] 開始處理單攝像頭視頻(隔離子進程)")def target(q, video_path, output_dir):"""子進程運行的OpenCV邏輯"""try:cap = cv2.VideoCapture(video_path)if not cap.isOpened():raise ValueError("無法打開視頻")total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))step = max(1, total_frames // 5)os.makedirs(output_dir, exist_ok=True)saved_count = 0for i in range(5):cap.set(cv2.CAP_PROP_POS_FRAMES, i * step)ret, frame = cap.read()if ret:out_path = os.path.join(output_dir, f"frame_{i}.jpg")cv2.imwrite(out_path, frame)saved_count += 1cap.release()q.put(saved_count)except Exception as e:q.put(('exception', str(e)))q = mp.Queue()p = mp.Process(target=target, args=(q, video_path, output_dir))p.start()p.join()# 🚨 檢查子進程是否崩潰if p.exitcode != 0:error_msg = f"子進程崩潰,退出碼: {p.exitcode} (可能是分段錯誤)"print(f"[{timestamp}] [VIDEO-ERROR] {error_msg}")raise NonRetryableError(error_msg)# ? 正常異常從隊列返回result = q.get()if isinstance(result, tuple) and result[0] == 'exception':error_msg = f"子進程異常: {result[1]}"raise Exception(error_msg)print(f"[{timestamp}] [VIDEO] 成功提取 {result} 幀")return result
4、?為什么要同時做 exitcode 檢查 和 隊列異常檢查?
exitcode != 0 → 捕獲 崩潰類錯誤(如 C++ 層面的 Segfault),直接標記為
FAILED,不可重試隊列異常返回 → 捕獲 Python 級異常(如“文件打不開”、“幀為 None”),可以走
RETRY或FAILED策略
兩者互補,保證了:
崩潰不拖死主進程
正常錯誤能被業務邏輯感知并按需重試
5、multiprocessing 與 subprocess 的區別
很多人會問:為啥用 multiprocessing,而不是直接 subprocess.run("python xxx.py")?
subprocess:適合運行外部命令,通信只能靠字符串/字節流multiprocessing:是subprocess的 Python 高級封裝,支持直接傳遞 Python 對象(通過pickle),更適合 Spark 里函數隔離
👉 如果你只想跑 ffmpeg 命令,用 subprocess;如果是 Python 函數(如 OpenCV),用 multiprocessing。
7、最佳實踐總結
禁用 OpenCV 多線程
import cv2, os os.environ["OMP_NUM_THREADS"] = "1" cv2.setNumThreads(1)首選 FFmpeg 提幀
簡單場景(只需要抽幀),直接subprocess.run(["ffmpeg", "-i", ...])更穩。對子進程 exitcode 檢查
0= 正常-11= Segfault → 標記FAILED
日志 + 狀態更新
崩潰 →FAILED
普通異常 →RETRYorFAILED(視業務邏輯)分區隔離
每個文件單獨 try/except,不要讓一個文件拖死整個分區。
8、結語
在 Databricks / Spark 這類分布式環境中,不穩定的 C 擴展(如 OpenCV)就是定時炸彈。
通過 子進程隔離 + exitcode 檢查 + 隊列通信,我們可以優雅地把崩潰局限在單個文件級別,而不是全盤失敗。
這套思路不僅適用于 OpenCV,還能推廣到:
NumPy 大規模矩陣運算(偶爾崩潰)
GPU 推理代碼(驅動問題導致進程掛掉)
第三方 C 擴展庫
🔗 如果你在生產環境中也遇到過類似問題,歡迎在評論區交流。
📌 覺得有用記得收藏 & 點贊,讓更多同學避免踩坑!
)



lossbase_v2)



)
快速入門完全指南:從零開始構建你的第二大腦(免費好用的筆記軟件的知識管理系統)、黑曜石筆記)
)




![Dism++備份系統時報錯[句柄無效]的解決方法](http://pic.xiahunao.cn/Dism++備份系統時報錯[句柄無效]的解決方法)



