
【導讀】
目標跟蹤(Visual Object Tracking, VOT)一直是計算機視覺領域的核心問題之一,廣泛應用于自動駕駛、無人機監控、人機交互等場景。隨著單模態方法在復雜環境下逐漸遇到瓶頸,多模態視覺目標跟蹤(Multi-Modal VOT)應運而生,它通過融合不同傳感器模態(RGB、紅外、深度、語義等),顯著提升了魯棒性與精度。本文將帶你走進最新的多模態目標跟蹤研究進展。
目錄
一、為什么需要多模態目標跟蹤?
二、方法發展脈絡
三、一個全景式框架:四大核心環節
多模態數據采集(Data Collection)
模態對齊與標注(Alignment & Annotation)
多模態模型設計(Model Designing)
評測與基準(Evaluation & Benchmarking)
四、框架亮點:兩個首次提出的問題
多模態融合是否總是更優?
數據分布的偏差
五、未來發展方向
總結
一、為什么需要多模態目標跟蹤?
傳統的單模態視覺跟蹤往往依賴RGB視頻。然而在弱光、遮擋、背景雜亂等情況下,RGB信息容易失效。多模態跟蹤的優勢在于:
-
互補性:紅外可在夜間或低光環境中穩定工作,深度信息能提供空間結構,語義模態帶來場景理解。
-
魯棒性:在目標外觀變化、尺度變化或部分遮擋時,多模態融合往往比單模態更可靠。
-
廣泛應用:自動駕駛中的激光雷達與攝像頭、安防監控中的紅外與可見光融合,都是多模態跟蹤的典型需求。
近日,一篇綜述論文《Omni Survey for Multimodality Analysis in Visual Object Tracking》對該領域進行了全面梳理。這篇綜述堪稱“全方位”(Omni),不僅因為它覆蓋了迄今為止最廣泛的多模態跟蹤任務,還因為它從數據、模型、評估等多個維度,深入剖析了該領域的現狀、挑戰與未來。論文共引用了338篇參考文獻,為研究者提供了一個極其寶貴的知識庫和路線圖。

論文標題:
Omni Survey for Multimodality Analysis in Visual Object Tracking
論文鏈接:
https://arxiv.org/abs/2508.13000?
二、方法發展脈絡
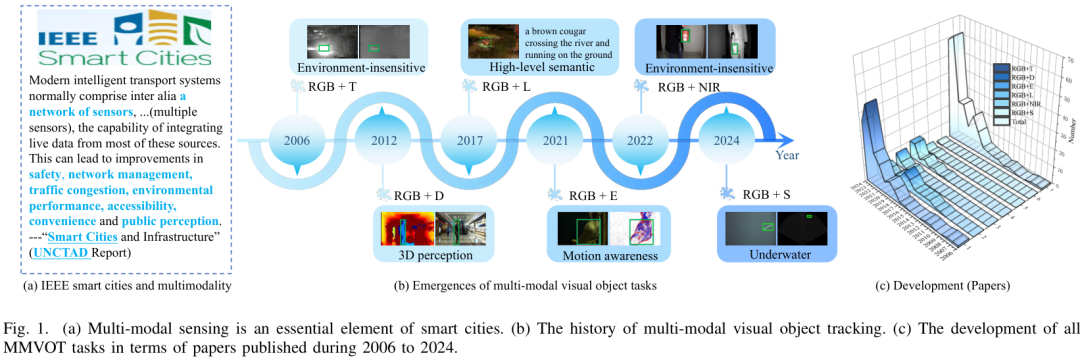
-
早期傳統方法:基于濾波、光流與手工特征的跨模態對齊。
-
深度學習方法:利用卷積神經網絡(CNN)、Transformer等結構對不同模態特征進行融合與增強。
-
融合策略創新:包括特征級融合(early fusion)、決策級融合(late fusion)以及跨模態注意力機制,近年來的趨勢是更靈活的自適應融合。
三、一個全景式框架:四大核心環節
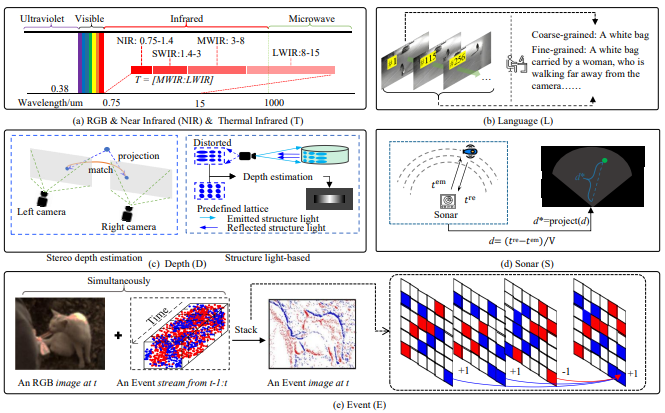
MMVOT 的研究可以被拆解為四個關鍵環節,它們構成了一個全景式的分析框架:
-
多模態數據采集(Data Collection)
視覺模態不僅包括 RGB,還擴展到熱紅外(T)、深度(D)、事件相機(E)、近紅外(NIR)、語言描述(L)、聲吶(S)。
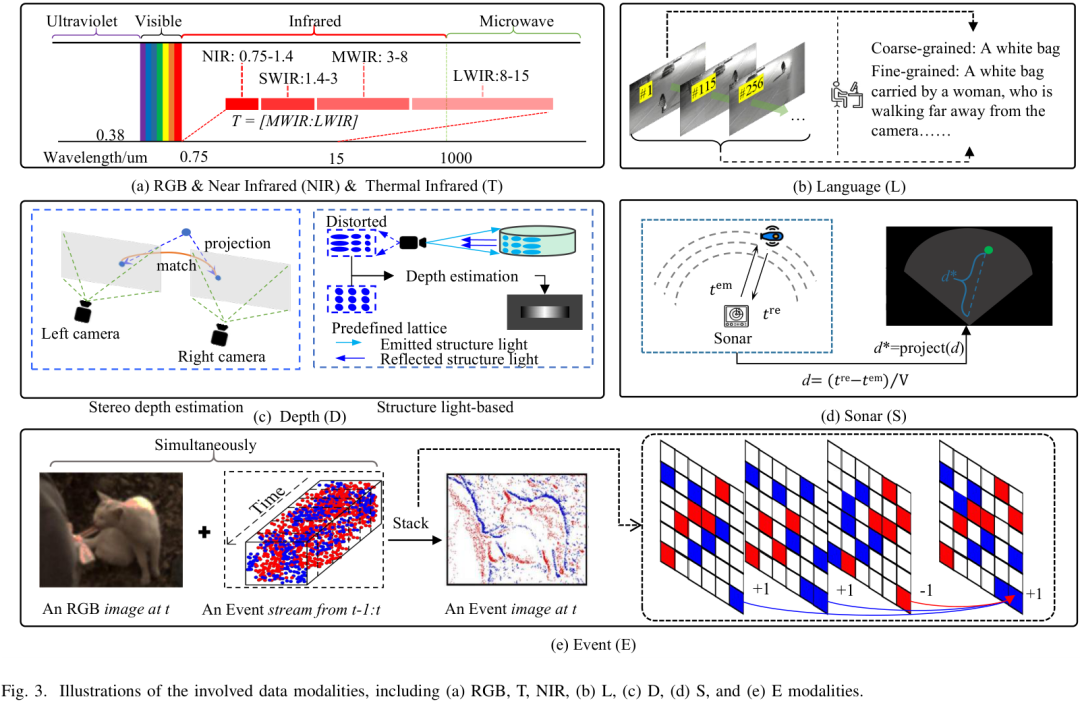
各模態具有物理互補性:例如紅外能在夜晚保持清晰,事件相機對快速運動特別敏感,語言模態能提供高層語義信息。
論文首次系統比較了這些模態的物理特性及優勢,為多模態融合提供理論基礎。
在實際研究或應用中,如何快速調用多模態數據集和主流模型是一個難題。Coovally 平臺內置了400+開源數據集,并集成了YOLO、DETR、Swin-Transformer等前沿模型,用戶可以一鍵調用、訓練與驗證,大幅降低了入門與實驗成本。

-
模態對齊與標注(Alignment & Annotation)
不同傳感器的分辨率、采樣頻率和空間位置往往不同,如何對齊數據是核心挑戰。
RGB+T、RGB+D、RGB+E?數據集需要進行嚴格的幾何或時間對齊,而?RGB+L、RGB+S?則天然具備語義對齊特性。
在標注方面,大部分仍依賴人工的邊框框選,但論文也指出了半自動標注與大語言模型生成描述的趨勢。
-
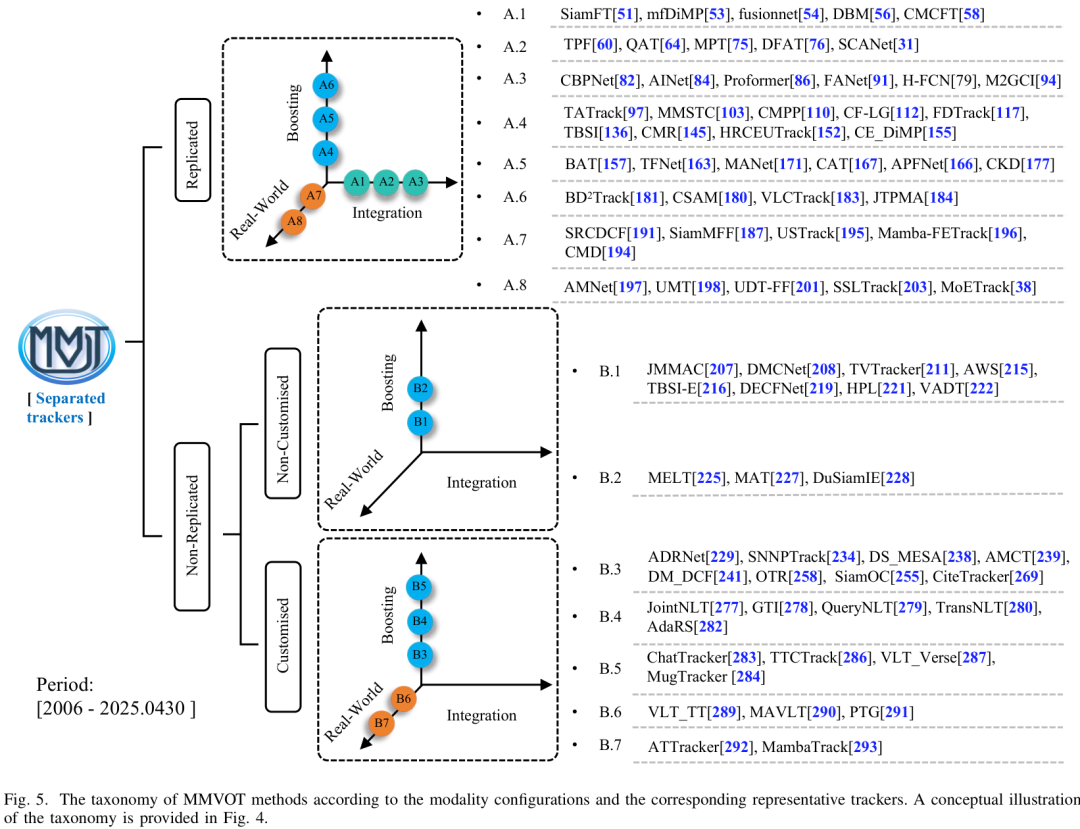
多模態模型設計(Model Designing)
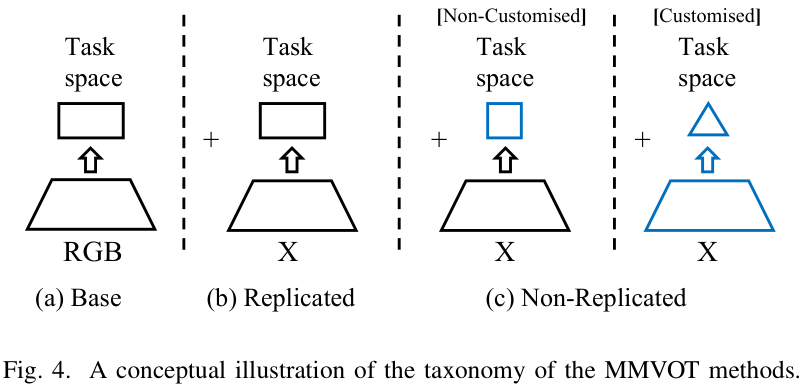
-
復制式配置:X分支(如紅外/深度分支)直接復制RGB分支結構,常見于早期工作。
-
非復制式配置:為不同模態設計定制化結構,例如熱紅外分支引入溫度交叉處理,事件相機分支借鑒類神經元的脈沖網絡。
-
融合策略:從早期的像素級拼接,到特征級跨模態注意力,再到多層次的漸進式融合,方法越來越靈活。
-
現實考量:在效率、魯棒性、跨任務統一模型(Unified Trackers)上,論文也進行了全景總結。
-
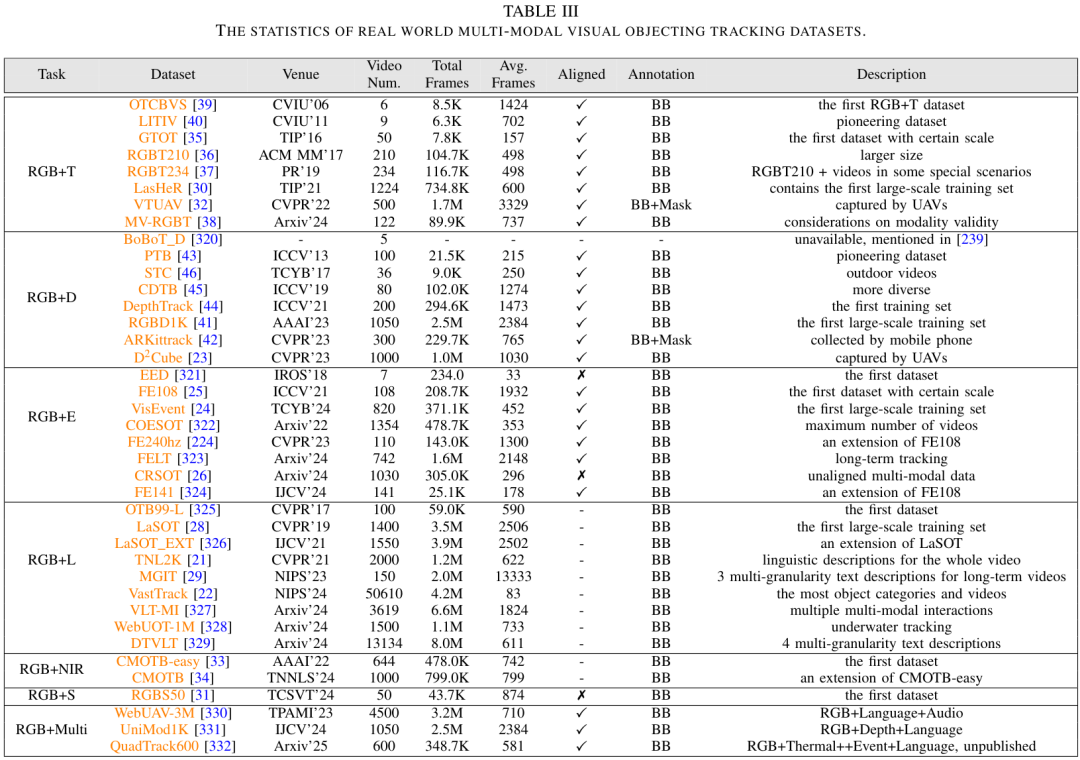
評測與基準(Evaluation & Benchmarking)
該研究收錄并分析了338篇相關研究,覆蓋六大類任務(RGB+T、RGB+D、RGB+E、RGB+L、RGB+NIR、RGB+S)。
提供了詳細的數據集梳理:從最早的GTOT、PTB到近期的LasHeR、DepthTrack、VisEvent、TNL2K。
論文特別指出:現有數據集普遍存在 長尾分布 和 動物類缺失,這對泛化能力構成嚴重挑戰。
在應用層面,如何快速復現這些研究、調用合適的數據與模型,同樣是研究者和企業的痛點。Coovally 平臺通過內置數據倉庫與模型庫,讓用戶能夠即調即用,極大縮短了實驗準備與驗證的周期。
四、框架亮點:兩個首次提出的問題
這篇全景式綜述不僅總結了進展,還提出了兩個前所未有的關鍵問題:
-
多模態融合是否總是更優?
常規思路認為多模態融合必然帶來提升,但論文指出,當某一模態質量極差時(如夜間RGB圖像嚴重噪聲),盲目融合反而會拖累整體性能。
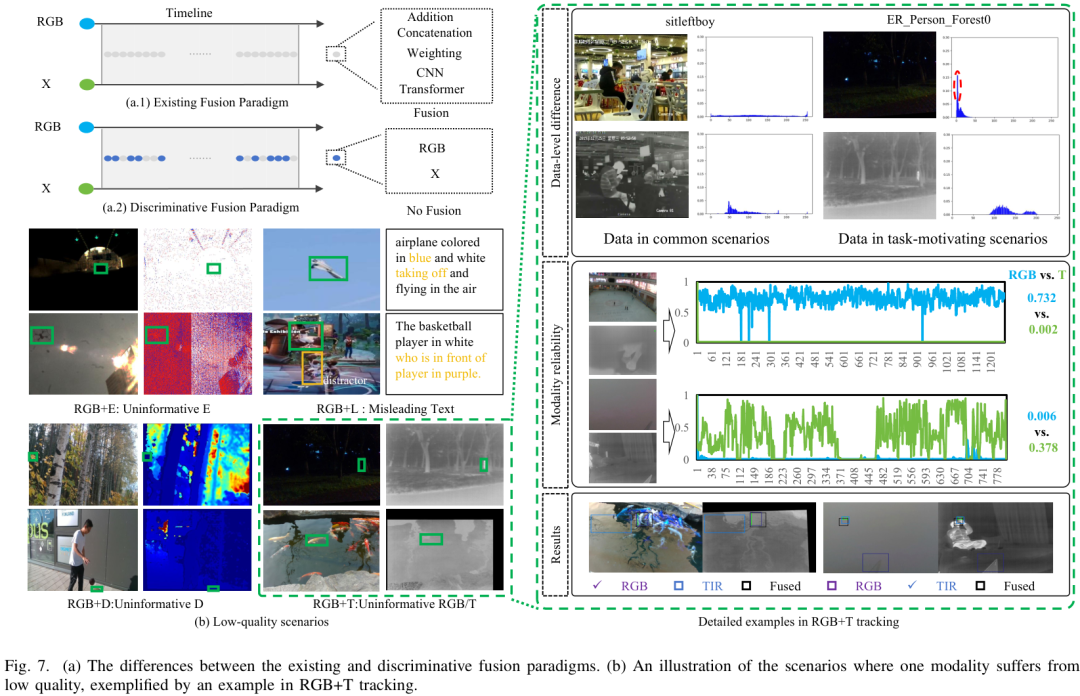
因此,選擇性融合(Discriminative Fusion)比盲目融合更有前景。
-
數據分布的偏差
當前多模態數據集中,大部分目標類別集中在少數幾類,形成嚴重的長尾分布。
特別是“動物類數據”的缺失,限制了多模態跟蹤在生態監測、野生動物保護等實際應用中的推廣。

五、未來發展方向
盡管多模態目標跟蹤取得了長足進展,但論文也指出了幾大挑戰:
-
跨模態對齊問題:不同傳感器的數據在時空分辨率上差異明顯。
-
計算效率:多模態輸入會顯著增加模型復雜度,不利于實時應用。
-
標注成本高:構建大規模高質量的多模態數據集需要大量人力。
-
通用性與泛化性不足:現有方法在跨場景遷移時性能不穩定。
作者提出了幾條值得關注的研究路線:
-
輕量化與實時跟蹤:讓多模態方法能部署在無人機、嵌入式等低算力設備上。
-
自監督與弱監督學習:減少對人工標注的依賴。
-
跨模態預訓練與大模型結合:利用多模態大模型提升特征表示能力。
-
與下游任務融合:如多模態跟蹤 + 行為識別、事件檢測,提升應用價值。
總結
這篇綜述論文系統梳理了多模態視覺目標跟蹤的研究進展,從方法到數據集,再到挑戰與未來趨勢,都為后續研究提供了清晰的脈絡。可以預見,隨著多模態感知和大模型的快速發展,未來的目標跟蹤將在更多實際場景中落地,助力智慧交通、公共安全、智能制造等領域。
Coovally平臺也在探索多模態大模型在目標跟蹤中的應用,未來,依托平臺的持續更新,用戶可以更方便地將學術前沿成果轉化為實際生產力。



網絡編程:IP、端口與 UDP 套接字)

Linux下的網絡編程)










)


)
