Redis 數據類型有哪些?
詳細可以查看:數據類型及其應用場景
基本數據類型:
-
String:最常用的一種數據類型,String類型的值可以是字符串、數字或者二進制,但值最大不能超過512MB。一般用于 緩存和計數器
-
Hash:Hash 是一個鍵值對集合。存儲商品的各個屬性
-
Set:無序去重的集合。Set 提供了交集、并集等方法,對于實現共同好友、共同關注等功能特別方便。
-
List:有序可重復的集合,底層是依賴雙向鏈表實現的。用于消息隊列
-
SortedSet:有序Set。內部維護了一個
score的參數來實現。適用于排行榜和帶權重的消息隊列等場景。
特殊的數據類型:
-
Bitmap:位圖,可以認為是一個以位為單位數組,數組中的每個單元只能存0或者1,數組的下標在 Bitmap 中叫做偏移量。Bitmap的長度與集合中元素個數無關,而是與基數的上限有關。
-
Hyperloglog。HyperLogLog 是用來做基數統計的算法,其優點是,在輸入元素的數量或者體積非常非常大時,計算基數所需的空間總是固定的、并且是很小的。典型的使用場景是統計獨立訪客。
-
Geospatial?:主要用于存儲地理位置信息,并對存儲的信息進行操作,適用場景如定位、附近的人等。
-
Stream :一種日志數據結構,適合于存儲時間序列數據或消息流。支持高效的消息生產和消費模式,具有持久性和序列化特性。
SortedSet和List異同點?
相同點:
-
都是有序的;
-
都可以獲得某個范圍內的元素。
不同點:
-
列表基于鏈表實現,獲取兩端元素速度快,訪問中間元素速度慢;
-
有序集合基于散列表和跳躍表實現,訪問中間元素時間復雜度是OlogN;
-
列表不能簡單的調整某個元素的位置,有序列表可以(更改元素的分數);
-
有序集合更耗內存。
Redis 怎么實現消息隊列?
BLPOP queue 0 //0表示不限制等待時間BLPOP和LPOP命令相似,唯一的區別就是當列表沒有元素時BLPOP命令會一直阻塞連接,直到有新元素加入。
redis可以通過pub/sub主題訂閱模式實現一個生產者,多個消費者,當然也存在一定的缺點,當消費者下線時,生產的消息會丟失。
PUBLISH channel1 hi
SUBSCRIBE channel1
UNSUBSCRIBE channel1 //退訂通過SUBSCRIBE命令訂閱的頻道。
PSUBSCRIBE channel?*?按照規則訂閱。PUNSUBSCRIBE channel?*?退訂通過PSUBSCRIBE命令按照某種規則訂閱的頻道。其中訂閱規則要進行嚴格的字符串匹配,PUNSUBSCRIBE *無法退訂channel?*規則。
如何在 Redis 中實現隊列和棧數據結構?
可以通過 List 類型 來實現 隊列 和 棧
實現隊列(FIFO):隊列是一種 先進先出(FIFO)的數據結構。在Redis中,可以使用 PUSH 和 RPOP命令組合來實現隊列。LPUSH 向列表的左側推入元素,而 RPOP從列表的右側彈出元素,這樣可以保證最先進入的元素最先被彈出
實現棧(LIFO):棧是一種 后進先出(LIFO)的數據結構。在Redis 中,可以使用 LPUSH和 LPoP命令組合來實現棧。LPUSH 向列表的左側推入元素,而 LPoP從列表的左側彈出元素,這樣可以保證最后進入的元素最先被彈出。
Redis 怎么實現延時隊列
使用sortedset,拿時間戳作為score,消息內容作為key,調用zadd來生產消息,消費者用zrangebyscore指令獲取N秒之前的數據輪詢進行處理。
如何使用 Redis 快速實現排行榜?
使用 Redis 實現排行榜的方式主要利用 Sorted Set(有序集合),它可以高效地存儲、更新、以及獲取排名數據。實現排行榜的主要步驟:
-
使用 Sorted Set 存儲分數和成員:使用 Redis 的 ADD命令,將用戶和對應的分數添加到有序集合中。例如:add leaderboard 1000 user1,將用戶 user1 的分數設置為 1000。
-
獲取排名:使用 ZRANK命令獲取某個用戶的排名。例如:zrank leaderboard user1,返回用戶user1 的排名(從0開始)。
-
獲取前 N 名:使用 ZREVRANGE 命令獲取分數最高的前N名。例如:REVRANGE leaderboard 0 9 WITHSCORES ,獲取排行榜前 10 名用戶及其分數。
-
更新分數:如果用戶的分數需要更新,可以使用 ZINCRBY 命令對其分數進行加減操作。例如:ZINCRBY leaderboard 500 user1,將用戶 user1 的分數增加 500。
如何使用 Redis 快速實現布隆過濾器?
可以通過使用 位圖(Bitmap)或使用 Redis 模塊 RedisBloom。
-
使用位圖實現布隆過濾器:使用 Redis 的位圖結構 SETBIT 和 GETBIT 操作來實現布隆過濾器。位圖本質上是一個比特數組,用于標識元素是否存在對于給定的數據,通過多個 哈希函數 計算位置索引,將位圖中的相應位置設置為 1,表示該元素可能存在。
-
使用 RedisBloom 模塊:Redis 提供了一個官方模塊 RedisBloom,封裝了哈希函數、位圖大小等操作,可以直接用于創建和管理布隆過濾器。使用 BF.ADD 來向布隆過濾器添加元素,使用 BF.EXISTS 來檢查某個元素是否可能存在,
如何使用 Redis 統計大量用戶唯一訪問量(UV)?
Redis 中 HyperLogLog 結構,可以快速實現網頁UV、PV 等統計場景。它是一種基數估算算法的概率性數據結構,可以用極少的內存統計海量用戶唯一訪問量的近似值。
Set 也可以實現,用于精確統計唯一用戶訪問量,但是但當用戶數非常大時,內存開銷較高。
Redis 中的 Geo 數據結構是什么?
Redis中的 Geo(Geoloaton的簡寫形式,代表地理坐標) 數據結構主要用于地理位置信息的存儲,通過這個結構,可以方便地進行地理位置的存儲、檢索、以及計算地理距離等課作,GeO 數據結內存層使用了 Sorted set, 并結合了Geohash 編碼算法來對地理位置進行處理。
Redis String 類型的底層實現是什么?(SDS)
Redis 中的 Sting 類型底層實現主要基于 SDS(Simple Dynamic string 簡單動態字符串)結構,并結合 int、embstr、raw 等不同的編碼方式進行優化存儲。
Redis 中的 Ziplist 和 Quicklist 數據結構的特點是什么?
Ziplist:
-
簡單、緊湊、連續存儲,適用于小數據量場景,但對大量數據或頻繁的修改操作不太友好。
-
適合小數據量場景,例如短列表、小哈希表等,因為它的內存緊湊,可以大幅減少內存使用
Quicklist:
-
通過將鏈表和 Ziplist 結合,既實現了鏈表的靈活操作,又能節省內存,在 Redis 3.2 之后成為 List 的默認實現。
-
Quicklist是為了替代純而設計的,適用于需要頻繁對列表進行插入、刪除、查找等提作的場景,并目數據量可能較大,它在存儲多個元素時,既保留了鏈表的靈活性,又具備壓縮列表的內存優勢
Redis Zset 的實現原理是什么?
Redis 中的Zset(有序集合,Sorted set)是一種由?跳表?(Skip List)和哈希表 (Hash Table)組成的數據結構,Zset 結合了集合 (Set)的特性和排序功能,能夠存儲具有唯一性的成員,并根據成員的分數 (score) 進行排序
ZSet 的實現由兩個核心數據結構組成:
-
跳表(Skip List):用于存儲數據的排序和快速查找。
-
哈希表(Hash Table):用于存儲成員與其分數的映射,提供快速查找
當 Zset 元素數量較少時,Redis 會使用壓縮列表(Zip List)來節省內存
-
即元素個數≤ zset-max-ziplist-entries(默認 128)
-
元素成員名和分值的長度 ≤ zset-max-ziplist-value(默認 64 字節)
如果任何一個條件不滿足,Zset 將使用 跳表 +哈希表 作為底層實現,
Redis 的有序集合底層為什么要用跳表,而不用平衡樹、紅黑樹或者 B+樹?
這道面試題很多大廠比較喜歡問,難度還是有點大的。
-
平衡樹 vs 跳表:平衡樹的插入、刪除和查詢的時間復雜度和跳表一樣都是?O(log n)。對于范圍查詢來說,平衡樹也可以通過中序遍歷的方式達到和跳表一樣的效果。但是它的每一次插入或者刪除操作都需要保證整顆樹左右節點的絕對平衡,只要不平衡就要通過旋轉操作來保持平衡,這個過程是比較耗時的。跳表誕生的初衷就是為了克服平衡樹的一些缺點。跳表使用概率平衡而不是嚴格強制的平衡,因此,跳表中的插入和刪除算法比平衡樹的等效算法簡單得多,速度也快得多。
-
紅黑樹 vs 跳表:相比較于紅黑樹來說,跳表的實現也更簡單一些,不需要通過旋轉和染色(紅黑變換)來保證黑平衡。并且,按照區間來查找數據這個操作,紅黑樹的效率沒有跳表高。
-
B+樹 vs 跳表:B+樹更適合作為數據庫和文件系統中常用的索引結構之一,它的核心思想是通過盡可能少的 IO 定位到盡可能多的索引來獲得查詢數據。對于 Redis 這種內存數據庫來說,它對這些并不感冒,因為 Redis 作為內存數據庫它不可能存儲大量的數據,所以對于索引不需要通過 B+樹這種方式進行維護,只需按照概率進行隨機維護即可,節約內存。而且使用跳表實現 zset 時相較前者來說更簡單一些,在進行插入時只需通過索引將數據插入到鏈表中合適的位置再隨機維護一定高度的索引即可,也不需要像 B+樹那樣插入時發現失衡時還需要對節點分裂與合并。
Redis 中跳表的實現原理是什么?
跳表主要是通過多層鏈表來實現,底層鏈表保存所有元素,而每一層鏈表都是下一層的子集。
插入時,首先從最高層開始查找插入位置,然后隨機決定新節點的層數,最后在相應的層中插入節點并更新指針
刪除時,同樣從最高層開始查找要刪除的節點,并在各層中更新指針,以保持跳表的結構。
查找時,從最高層開始,逐層向下,直到找到目標元素或確定元素不存在。查找效率高,時間復雜度為 O(logn)
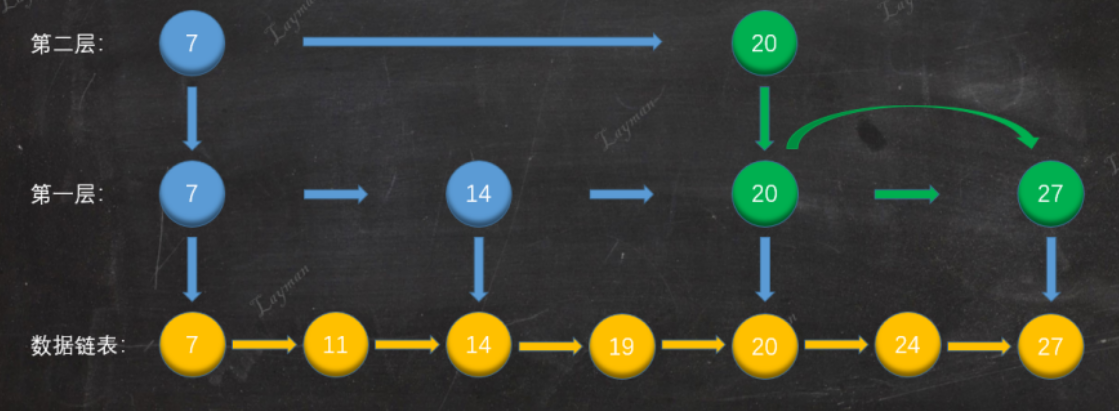
Redis中的跳表是兩步兩步跳的嗎?
如果采用新增節點或者刪除節點時,來調整跳表節點以維持比例2:1的方法的話,顯然是會帶來額外開銷的。
跳表在創建節點時候,會生成范圍為[0-1]的一個隨機數,如果這個隨機數小于 0.25(相當于概率 25%),那么層數就增加 1 層,然后繼續生成下一個隨機數,直到隨機數的結果大于 0.25 結束,最終確定該節點的層數。因為隨機數取值在[0,0.25)范圍內概率不會超過25%,所以這也說明了增加一層的概率不會超過25%。這樣的話,當插入一個新結點時,只需修改前后結點的指針,而其它結點的層數就不需要隨之改變了,這樣就降低插入操作的復雜度。
// #define ZSKIPLIST_P 0.25
int zslRandomLevel(void) {static const int threshold = ZSKIPLIST_P*RAND_MAX;int level = 1; //初始化為一級索引while (random() < threshold)level += 1;//隨機數小于 0.25就增加一層//如果level 沒有超過最大層數就返回,否則就返回最大層數return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}Redis遇到哈希沖突怎么辦?
當有兩個或以上數量的鍵被分配到了哈希表數組的同一個索引上面時, 我們稱這些鍵發生了沖突(collision)。
而redis是先通過拉鏈法解決,再通過rehash來解決hash沖突問題的,即再hash法,只不過redis的hash使漸進式hash
rehash原理?
漸進式 rehash 步驟如下:
-
先給
哈希表 2分配空間; -
在 rehash 進行期間,每次哈希表元素進行新增、刪除、查找或者更新操作時,Redis 除了會執行對應的操作之外,還會順序將
哈希表 1中索引位置上的所有 key-value 遷移到哈希表 2上; -
隨著處理客戶端發起的哈希表操作請求數量越多,最終在某個時間點會把
哈希表 1的所有 key-value 遷移到哈希表 2,從而完成 rehash 操作。
這樣就把一次性大量數據遷移工作的開銷,分攤到了多次處理請求的過程中,避免了一次性 rehash 的耗時操作。
在進行漸進式 rehash 的過程中,會有兩個哈希表,所以在漸進式 rehash 進行期間,哈希表元素的刪除、查找、更新等操作都會在這兩個哈希表進行。比如,在漸進式 rehash 進行期間,查找一個 key 的值的話,先會在哈希表 1里面進行查找,如果沒找到,就會繼續到哈希表 2?里面進行找到。新增一個 key-value 時,會被保存到哈希表 2里面,而哈希表 1則不再進行任何添加操作,這樣保證了哈希表 1的 key-value 數量只會減少,隨著 rehash 操作的完成,最終哈希表 1就會變成空表。
rehash的觸發條件?
負載因子 = 哈希表已保存節點數量/哈希表大小
觸發 rehash 操作的條件,主要有兩個:
-
當負載因子大于等于 1 ,并且 Redis 沒有在執行 bgsave 命令或者 bgrewiteaof 命令,也就是沒有執行 RDB 快照或沒有進行 AOF 重寫的時候,就會進行 rehash 操作。
-
當負載因子大于等于 5 時,此時說明哈希沖突非常嚴重了,不管有沒有有在執行 RDB 快照或 AOF 重寫,都會強制進行 rehash 操作
一個REDIS實例最多能存放多少KEYS
redis 的每個實例最多可以存放約 2^32 - 1 個keys,即大約 42 億個keys。這是由 Redis 內部使用的哈希表實現決定的,它使用 32 位有符號整數作為索引。Redis 使用的哈希函數和負載因子等因素也會影響實際可存放鍵的數量。
需要注意的是,盡管 Redis 允許存儲數量龐大的鍵,但在實踐中,存儲過多的鍵可能會導致性能下降和內存消耗增加。因此,在設計應用程序時,需要根據實際需求和硬件資源來合理規劃鍵的數量,避免過度使用 Redis 實例造成負擔。如果需要存儲更多的鍵值對,可以考慮使用 Redis 集群或分片技術,以擴展整體存儲容量。
文章轉載自:Seven
原文鏈接:用過redis哪些數據類型?Redis String 類型的底層實現是什么? - 程序員Seven - 博客園
體驗地址:JNPF快速開發平臺



)


)









(日更))


