Codenamed “Zen 5,” AMD’s next-generation, energy-efficient high-performance x86 core targets a wide array of client, server, and embedded markets. Fabricated in TSMC’s 4nm FinFET process, the 55mm2 core complex (CCX), shown in Fig. 2.1.1., contains 8.6B transistors across eight cores, each with a 1MB private L2 cache and a shared 32MB L3 cache. The “Zen 5” implementation supports configurable FP256 and FP512 data paths. The “Zen 5” family includes a “Zen 5c” variant with increased density and power efficiency for key markets. The main design priorities for “Zen 5” are to improve per-core performance and energy efficiency, while aintaining similar area footprint as the prior generation [1]. The “Zen 5” core delivers a ~16% generational IPC increase in desktop PC applications [2] while supporting frequencies up to 5.7GHz [3].
Zen5是AMD的下一代高能效高性能 X86架構的cpu,面向廣泛的客戶端、服務器和嵌入式市場,采用TSMC的4nm finFET工藝,面積55mm2,86億個晶體管,共有8個核,每個核包含1MB的L2緩存和32MB的L3緩存,還支持FP256和FP512數據通路。“Zen 5”的主要設計重點是提升單核性能和能效,同時保持與前代相近的面積在桌面PC應用中,“Zen 5”核心實現了約16%的IPC提升[2],同時支持最高5.7GHz的頻率[3]

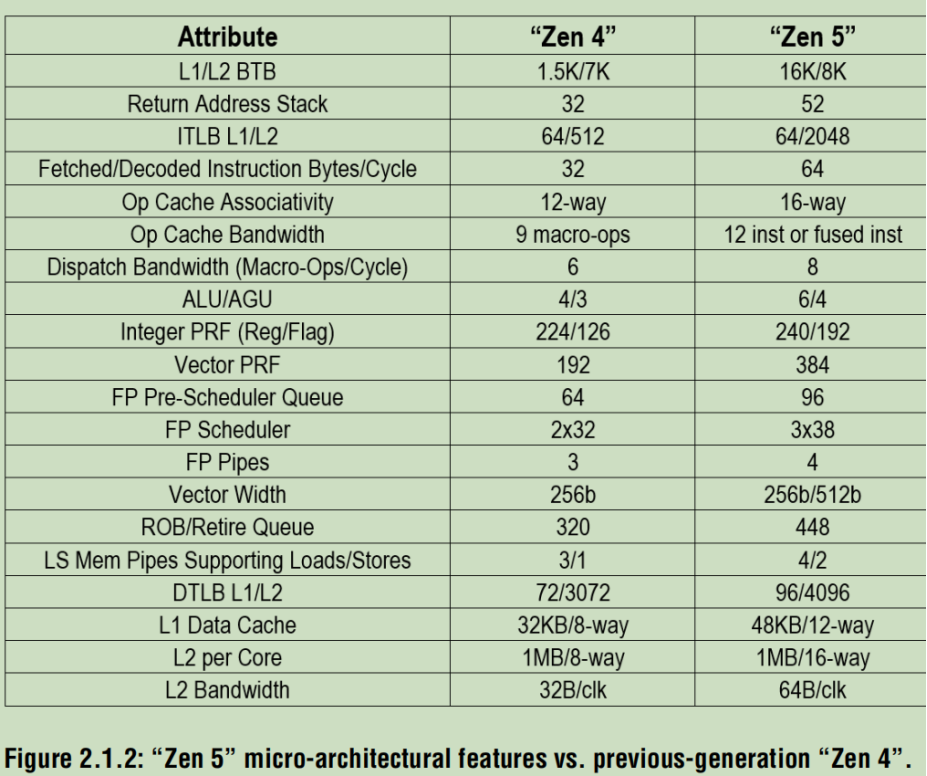
The “Zen 5” micro-architecture focuses on balanced throughput enhancements across the pipeline to achieve the performance uplift while maintaining power and area efficiency. Figure 2.1.2 presents key feature comparisons from the previous “Zen 4” generation. Improved branch prediction is combined with front-end parallelism, in the form of dual instruction fetch and micro-op cache pipes, to increase the dispatch width from six to eight micro-ops per cycle. To improve integer-based workloads, the ALU count increases to six units from the four found on all previous “Zen” generations.
Zen 5微架構聚焦于提升流水線各環節的均衡吞吐量,旨在實現性能躍升,同時降低功耗與面積。圖2.1.2展示了其與前代“Zen 4”架構的關鍵特性對比。改進的分支預測技術與前端并行性設計(采用雙指令取指與微操作緩存流水線)相結合,將每周期微操作(micro-op)發射寬度從6個提升至8個。為強化整數型工作負載處理能力,算術邏輯單元(ALU)數量從前代Zen架構的4個增至6個。(BTB branch target buffer緩存歷史分支的目標地址)
To make use of the additional execution hardware, a wider instruction window is implemented with a larger and higher throughput scheduler, register file, and retire queue. A fourth address generation unit is also inserted to support additional load and store pipes. The L1 data cache capacity is increased 50% to 48KB and 12 ways, while maintaining 4-cycle load-to-use performance. L2/L1 cache fill and victim bandwidth doubles to 64B per cycle. The design moved the majority of 8T SRAMs to 6T to increase density.
為了充分利用新增的執行硬件,設計中實現了更寬的指令窗口,并配備了更大規模、更高吞吐量的調度器、寄存器堆及退役隊列(將完成的指令壓入這個隊列)。此外,設計中還增設了第四個地址生成單元,以支持額外的加載與存儲流水線。一級數據緩存容量提升50%至48KB,采用12路組相聯結構,同時保持4周期的加載至使用延遲性能。二級緩存與一級緩存間的填充及失效帶寬翻倍,達到每周期64字節。設計中將大部分8晶體管SRAM替換為6晶體管結構,以提升存儲密度。
The “Zen 5” floating point (FP) data path increases to 512b from 256b on “Zen 4,” doubling the bandwidth for advanced vector extension (AVX512) instructions. Other notable FP changes include a doubling of dedicated FP registers, enhanced out-of-order scheduling capability, a reduction of the minimum FPADD latency to 2-cycles, and a doubling of the bandwidth for INT8, INT16, and BFLOAT16 AI formats. Through the use of improved on-die sensors, AC capacitance () monitors, and di/dt-based adaptive clocking, “Zen 5” can achieve full AVX512 performance at the peak core frequency. The FP implementation allows for the upper 256b data path to be power gated at boot time. This reverts the FP to the double-pumped AVX512 implementation used on “Zen 4,” achieving similar power efficiency by also using an independent mesh clock to gate the upper 256b data path [4]. This configurable implementation also makes it simple to create discrete 256b data path FP variants for product flexibility.
“Zen 5”的浮點(FP)數據路徑位寬從“Zen 4”的256位提升至512位,使高級向量擴展(AVX512)指令的帶寬翻倍。其他值得關注的浮點改進包括:專用浮點寄存器數量翻倍、增強的亂序調度能力、浮點加法(FPADD)最小延遲降至2個周期,以及INT8、INT16和BFLOAT16人工智能格式的數據帶寬翻倍。通過改進的片上傳感器、交流電容()(由于信號快速變化在導線附近產生的電容)監測和基于電流變化率(di/dt)的自適應時鐘技術,“Zen 5”可在峰值核心頻率下實現完整的AVX512性能。其浮點實現方案允許在啟動時對上層256位數據路徑進行電源門控,這使得浮點單元回歸到“Zen 4”所采用的雙泵浦AVX512實現方式——通過獨立的網狀時鐘對上層256位數據路徑進行門控,在實現相近能效的同時[4]。這種可配置的實現方式還簡化了獨立256位數據路徑浮點變體的創建,為產品靈活設計提供了便利。
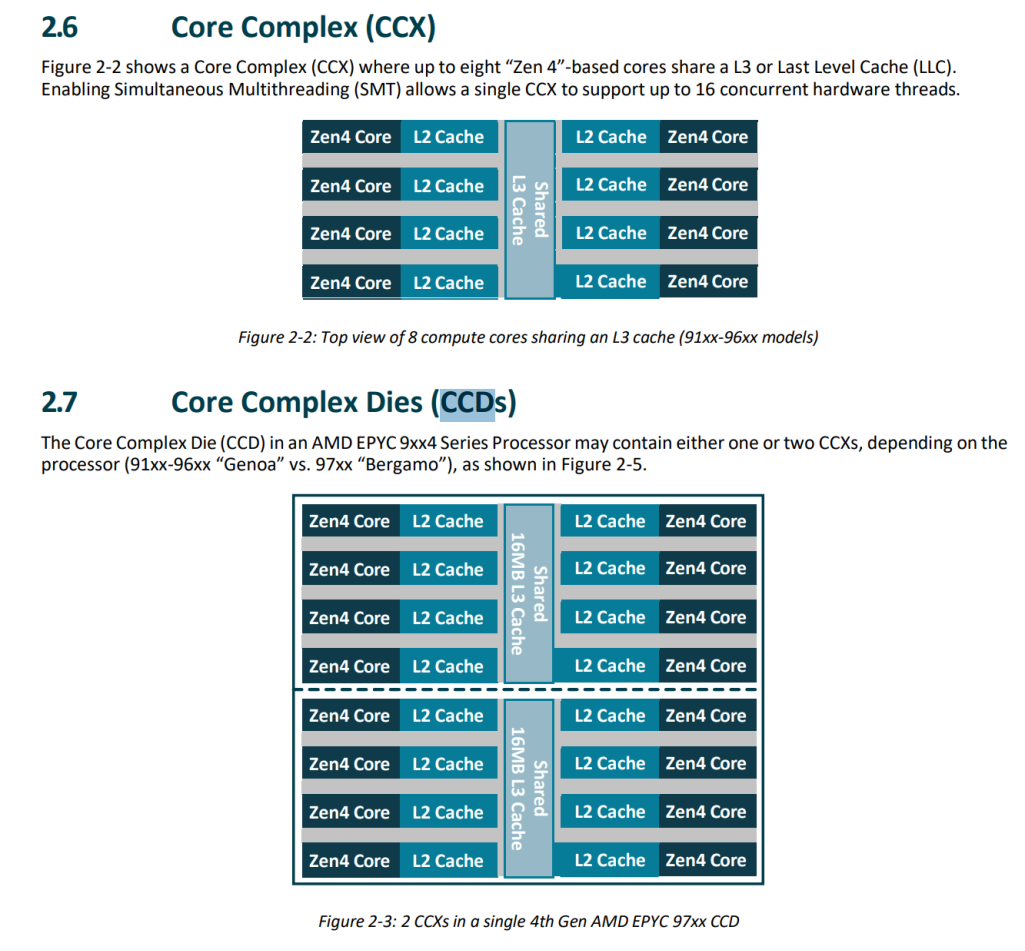
“Zen 5” fits 30% more transistors into the same CCX area as “Zen 4” via numerous advancements across core implementation, 4nm process technology, and cache design. The bulk of the area improvements are in cache design and stacking technology. “Zen 4” significantly improved the stacking area efficiency relative to “Zen 3”, and “Zen 5” continues this trend with a solution that requires minimal core complex die (CCD) area.
通過4nm制程工藝及緩存設計等多方面的改進,在相同CCX面積的情況下“Zen 5”比“Zen 4”多容納了30%的晶體管。面積使用效率的提升主要來自緩存設計與堆疊技術的優化。“Zen 4”相對于“Zen 3”已顯著提升了堆疊面積效率,而“Zen 5”延續了這一趨勢,采用了縮小極小核心復合體芯片(CCD)面積的解決方案。

“Zen 5” L2 is a fast, private cache with 1MB per core as in “Zen 4,” however, the bandwidth between the core and L2 is doubled from 32B/cycle to 64B/cycle. Additionally, the L2 associativity doubles from 8-ways to 16-ways. Logic device area is reducing faster than 6T SRAM in modern process technologies, so cache floorplans must be increasingly flexible to maintain density. Despite the increased performance of the “Zen 5” L2, the density is improved by 11% (process technology neutral) relative to “Zen 4” via flfloorplan changes shown in Fig. 2.1.3.
"Zen 5"架構的二級緩存(L2)如同"Zen 4"一樣,每個核心獨占1MB高速私有緩存;不過,其核心與L2 cache之間的帶寬提升了一倍,從每周期32字節增加至每周期64字節。此外,L2的關聯性也翻倍,從8路提升至16路。在現代制程技術中,邏輯器件的面積縮減速度快于6T SRAM,因此,為維持存儲密度,緩存布局必須變得更加靈活。盡管“Zen 5”的二級緩存(L2)性能有所提升,但通過圖2.1.3所示的布局調整,其密度相比“Zen 4”改進了11%。(與工藝制程沒有關系)
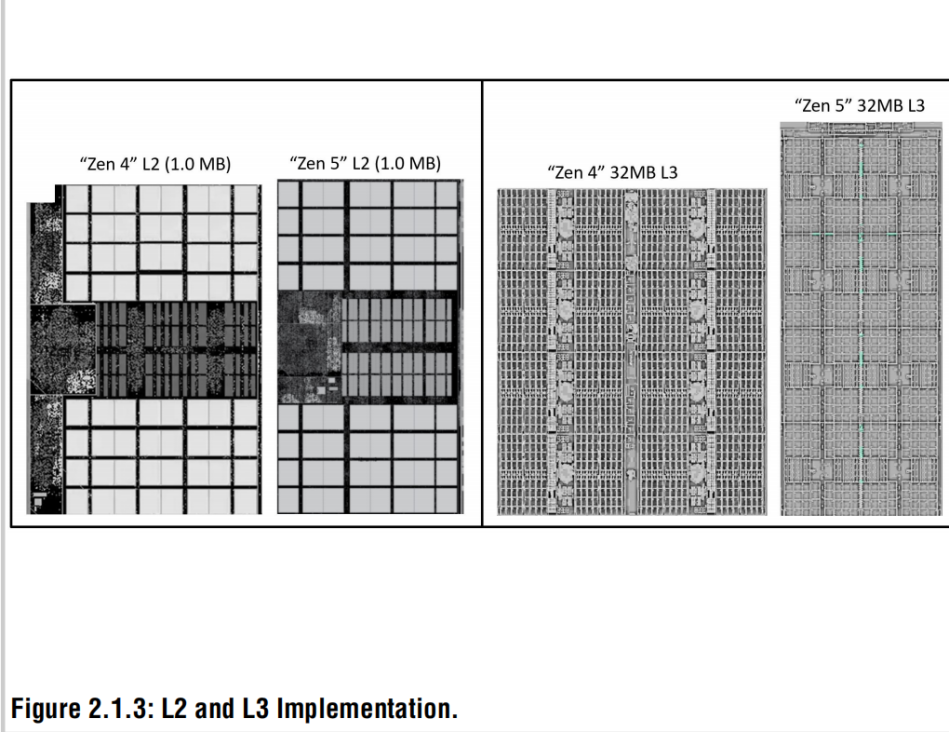
The “Zen 3” and “Zen 4” L3 “ring” fabric topology [5] is replaced by a mesh topology which reduces latency and increases bandwidth, especially for configurations with higher core counts. New L3 macros are created to achieve higher density. L3 data macro capacity is doubled, and its density improved by 10%. Circuit techniques are used to mitigate the frequency loss that typically occurs from doubling the capacity of SRAM macros. The capacity of each tag macro is doubled which leads to an 11% improvement in density.
“Zen 3”與“Zen 4”采用的L3環形拓撲[5] 被替換為網狀拓撲,此舉有效降低延遲并提升帶寬,在高核心數配置中尤為顯著。為實現更高密度,全新設計了L3宏單元:L3數據宏單元容量翻倍,密度提升10%;通過電路設計技術緩解了SRAM宏單元容量翻倍時常見的頻率損失問題;標簽宏單元容量同步翻倍,密度隨之提高11%。
Another primary “Zen 5” objective is to drive an energy-efficient, high-IPC machine that scales across a variety of workloads. Driving high IPC and new features, such as FP512, typically comes with more transistors and is challenging for frequency/power attainment.
“Zen 5”的另一核心設計目標是打造高能效、高IPC(instructions per cycle)的架構,并確保可以擴展到不同的應用中。然而,驅動高IPC及新增特性如FP512,需要集成更多晶體管,這使得頻率提升與功耗控制難以兼顧。
Unlocking improvements in transistor density to reduce switching and leakage power are key for delivering an efficient, high-IPC, 5.7GHz design. In addition to density improvements enabled by the geometric process shrink from a 5nm process to a 4nm process, PD methodology innovations such as array efficiency, SRAM optimizations, standard cell optimizations, design technology co-optimization, and utilization improvements results in higher transistor density.
要實現5.7GHz高頻、高IPC且能效優異的設計,關鍵在于提升晶體管密度以降低開關功耗與漏電功耗。除借助芯片工藝,從5nm升級至4nm,實現的晶體管密度增長外,物理設計方法論創新——包括存儲黨員陣列效率比(陣列面積與緩存總面積之比)提升、SRAM優化、標準單元優化、設計工藝協同優化以及利用率改進——也共同推動了晶體管密度的進一步躍升。
Significant emphasis is placed on switching power, C_AC, and leakage with detailed tracking of power for each RTL feature. Use of numerous RTL and PD power reduction methods enables “Zen 5” to reduce /IPC cost.
"Zen 5"設計中重點優化了開關功耗及漏電功耗,并追蹤每個RTL模塊的詳細功耗,通過應用大量RTL與PD的功耗優化技術(S家的VCLP工具),成功降低了(/IPC)。
The physical design focuses on timing and power co-optimization in the synthesis, place, and route (SAPR) tools to reduce dynamic and leakage power. The “Zen 5” breakdown is shown in Fig. 2.1.4. Macro power contribution is higher relative to “Zen 4” due to the larger array structures which enable higher performance.
在物理設計中,針對時序,可以通過綜合、布局布線(SAPR)工具進行優化,以降低動態功耗與漏電功耗。"Zen 5"的功耗構成分析見圖2.1.4。由于采用更大規模的陣列結構以實現更高性能,其宏單元(已經設計好的功能塊,比如一個模擬模塊,直接插到后端中)功耗占比相較"Zen 4"有所提升。
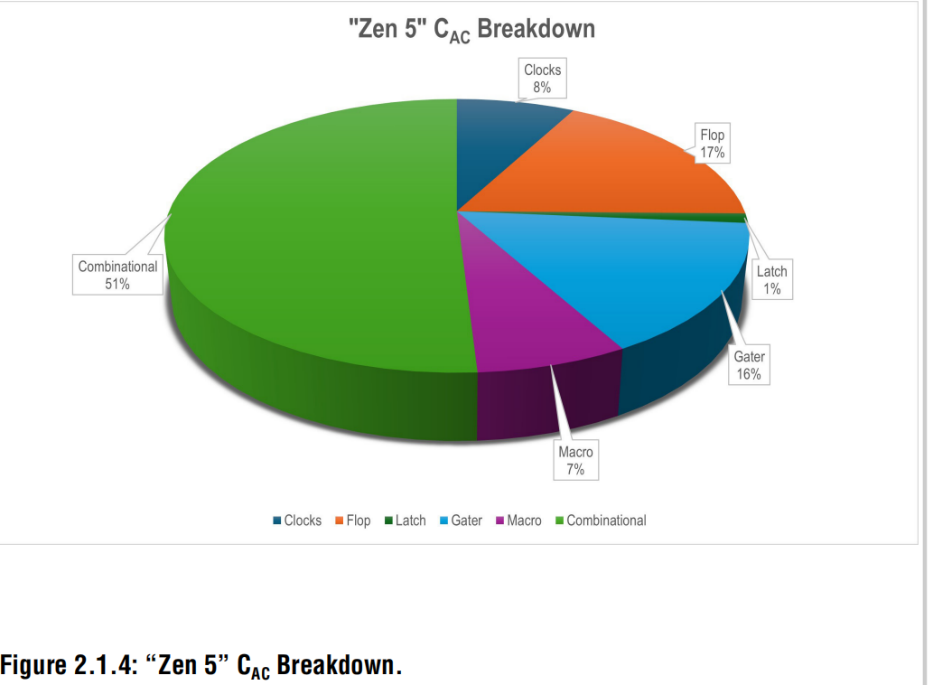
Contributions from flop/gater/clock are lower. High emphasis is put on multi-bit flop banking optimizations as well as attention to the flop cell palette and design usage. Clock gater is optimized with improved clock-gating cells and clock-tree synthesis (CTS) methodology. swap algorithms incorporated optimizations to better balance leakage, power, and frequency attainment.
觸發器/門電路/時鐘網絡的功耗占比有所降低。設計重點集中于:多比特觸發器組優化觸發器單元庫的精選與使用策略優化時鐘門控(clock gater)通過以下手段升級:改進型時鐘門控單元創新的時鐘樹綜合方法學交換算法引入優化機制,更精準平衡漏電功耗、動態功耗與頻率目標。
As with past “Zen” products [1], AMD utilizes the AM5 package for “Zen 5” desktop comprised of the CCX, a system management unit (SMU), test/debug logic, and dual Infinity Fabric? On-Package (IFOP) SerDes links. One or two CCDs are once again combined with a 6nm IO die (IOD) to deliver a broad range of “Zen 5”-based client desktop products codenamed “Granite Ridge” ranging from 6-core to 16-core.
如同歷代“Zen”產品[1],AMD在“Zen 5”桌面處理器中繼續采用AM5封裝,其包含:CCX、一個系統管理單元(SMU)、測試/調試邏輯、用兩個IF互聯、SerDes鏈路。1個或2個CCD與6nm I/O芯片連接,提供代號“Granite Ridge”的“Zen 5”客戶端桌面產品系列,核心數覆蓋6核至16核。
An over-arching goal for “Zen 5” is to create a family strategy to extend the dynamic range and leverage the “Zen 5” core in a wider set of use-cases [3]. Setting this strategy early-on allows the team to push the “Zen 5” core into the client notebook product offering as well as desktop. Using versions of the “Zen 5” core with a 256b flfloating point data path width, multiple CCX variants are developed for the “Strix” product family including a 4 “Zen 5” core plus 16MB L3 variant and an 8 “Zen 5c” plus 8MB L3 variant [6] as shown in Fig. 2.1.5. These “Zen 5” family options are instrumental in allowing AMD to deliver “Zen 5” core performance into laptop products with initial product offerings available at the same time as our desktop platforms, thus delivering optimal performance, power, and cost targets for multiple market segments.
"Zen 5"的核心戰略目標是構建統一的架構家族策略,以擴展動態性能范圍并將"Zen 5"應用于更廣泛的使用場景[3]。該策略的早期制定使團隊能將"Zen 5"核心同時推向筆記本和PC。通過采用256位浮點數據路徑的"Zen 5"核心變體,為"Strix"產品家族開發了多款CCX配置:4個"Zen 5"核心 + 16MB三級緩存8個"Zen 5c"核心 + 8MB三級緩存[6](架構拓撲見圖2.1.5)這些方案使AMD得以"Zen 5"加入筆記本產品,實現與桌面平臺同步上市,從而在多細分市場上達成性能、功耗與成本的最優平衡。
“Zen 5” performance per watt is improved versus “Zen 4” by delivering more performance at fixed power. The “Zen 5” architecture is wider resulting in more IPC and total . Figure 2.1.6 [7] shows that 1T Cinebench R23 (CBR23) performance per watt improved at high and medium power envelopes. As power is reduced, the performance of the current and previous generations approach a cross-over point at lower power envelopes.
相較于“Zen 4”,“Zen 5”的能效比(性能/瓦特)通過同功耗下提供更高性能實現顯著提升。更寬的“Zen 5”架構(增加執行單元/指令發射寬度)帶來更高IPC與。圖2.1.6 [7]顯示:高/中功耗區間:單線程Cinebench R23(CBR23)能效比顯著優化低功耗區間:兩代架構性能趨近,于特定功耗閾值出現交匯點
在這里插入圖片描述
Client programs leverage “Zen 5c” cores which have lower , area, and frequency to deliver better energy-efficiency at the lower power envelopes and maximize nT performance. Figure 2.1.7 [8,9] shows the performance uplift of the 12-core 9900X vs. the 24-core 14900K and the 8-core 9700X vs. the 20-core 14700K across a variety of workloads. The uplift varies from 1% for office productivity and up to 40% for Handbrake, which makes use of AVX512 instructions.
客戶端程序借助“Zen 5c”核心,其功耗、面積及頻率更低,在更低功耗范圍內實現了更優的能效表現,并最大化了nT性能(注:nT通常指每瓦特性能或特定場景下的綜合性能指標)。如圖2.1.7 [8,9]所示,在各類工作負載下,12核9900X處理器的性能相較于24核14900K,以及8核9700X相較于20核14700K均有提升。具體來看,辦公生產力任務的性能提升幅度僅為1%,而依賴AVX512指令的視頻轉換軟件Handbrake的性能提升幅度則高達40%。
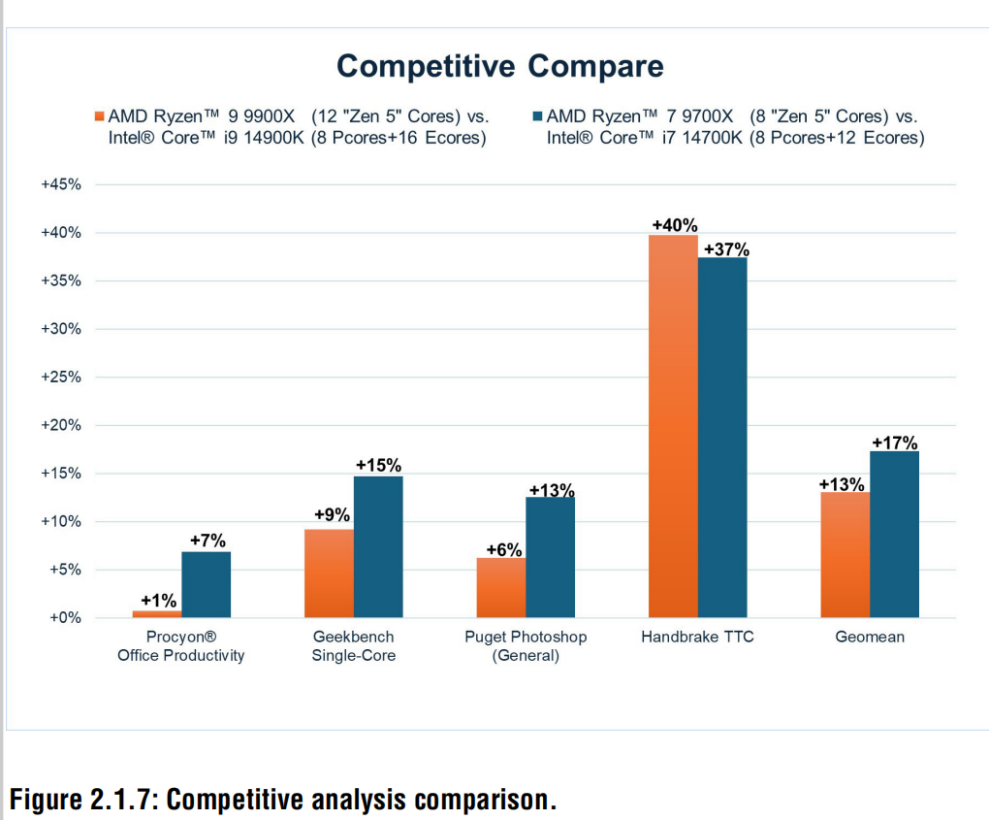
Despite having half or even less of the total core count, the 9900X and 9700X have a 13% and 17% geomean uplift over the 14900K and 14700K, respectively. Usage of high-efficiency cores and aggressive power-saving physical design techniques enables a 17% improvement in CBR23 nT IPC.
盡管核心總數僅為競品一半甚至更少,但Ryzen 9900X與9700X仍分別實現了:13%和17%幾何平均性能提升(前后兩個處理器性能之比)(對比Core i9-14900K和14700K) ,高效能核心的設計與先進的低功耗物理設計相結合,使Cinebench R23多線程測試中的IPC提升達17%。
References:
[1] B. Munger et al., “Zen 4: The AMD 5nm 5.7GHz x86-64 Microprocessor Core,” ISSCC, pp. 38-39, 2023.
[2] GNR-03: Testing as of May 2024 by AMD Performance labs. “Zen 5” system configured with: Ryzen 9 9950X GIGABYTE X670E AORUS MASTER motherboard, Balanced, DDR5-6000, Radeon RX 7900 XTX, VBS=ON, SAM=ON, KRACKENX63 vs. “Zen 4” system configured with: Ryzen 7 7700X, ASUS ROG Crosshair X670E motherboard, Balanced, DDR5-6000, Radeon RX 7900 XTX, VBS=ON, SAM=ON, KRAKENX62 {FixedFrequency=4.0 GHz}. Applications tested include: Handbrake, League of Legends, FarCry 6, Puget Adobe
Premiere Pro, 3DMark Physics, Kraken, Blender, Cinebench (n-thread), Geekbench, Octane, Speedometer, and WebXPRT. System manufacturers may vary configurations, yielding different results. GNR-03.
[3] B. Cohen, M. Subramony, M. Clark, “Next Generation “Zen 5” Core,” Hot Chips, 2024.
[4] T. Singh et al., “Zen 2: The AMD 7nm Energy-Efficient High-Performance x86-64 Microprocessor Core,” ISSCC, pp. 42-43, 2020.
[5] T. Burd, et al., “Zen 3: The AMD 2nd-Generation 7nm x86-64 Microprocessor Core,” ISSCC, pp. 54-55, 2022.
[6] T. Burd et al., “Zen 4c: The AMD 5nm Area-Optimized x86-64 Microprocessor Core,” ISSCC, pp. 38-40, 2024.
[7] GNR-19: Testing as of Sept. 2024 by AMD Performance Labs on test systems configured as follows: AMD Ryzen 9 7950X, Ryzen 9 9950X, AMD “Splinter” reference motherboard. 2x8GB dual channel DDR5-5600; Samsung 970 Pro SSD; Radeon RX 6800S graphics (461.4 driver), VBS & SAM off, Windows 10 professional (x64) 20H2 on the following application: Cinebench R23 1T. Results may vary and are based on several factors, including system configuration, application, and software. GNR-19.
[8] GNR-06: Testing as of June 2024 by AMD Performance Labs on test systems configured as follows: AMD Ryzen 9 9900X CPU system: GIGABYTE X670E AORUS MASTER, Balanced, DDR5-6000, Radeon RX 7900 XTX GPU, VBS=On,SAM=On, KRACKENX63 vs. similarly configured Intel Core i9-14900K system: MSI MEG Z790 ACE MAX (MS-7D86), Balanced, DDR5-6000, Radeon RX 7900 XTX, VBS=On, SAM=On, KRAKENX63, {Profile=Intel Default} on the following applications/games: Procyon Office, Geekbench 6.2.1 Single Core, Puget Photoshop (general), Blender (classroom TTC), Handbrake TTC, Borderlands3, DOTA2, Hitman3, Cyberpunk2077, F12023, and Horizon Zero Dawn. All games tested at 1080p resolution. System manufacturers may vary configurations, yielding different results. GNR-06.
[9] GNR-07: Testing as of June 2024 by AMD Performance Labs on test systems configured as follows: AMD Ryzen 7 9700X CPU system: GIGABYTE X670E AORUS MASTER, Balanced, DDR5-6000, Radeon RX 7900 XTX, VBS=On,SAM=On, KRACKENX63 vs. similarly configured Intel Core i7-14700K system: MSI MEG Z790 ACE MAX (MS-7D86), Balanced, DDR5-6000, Radeon RX 7900 XTX, VBS=On, SAM=On, KRAKENX63, {Profile=Intel Default} on the following applications/games: 7-Zip, Procyon Office Productivity, GeekBench 5.4.6 Single Core, Puget Adobe Photoshop, Handbrake, Borderlands 3, DOTA2, Hitman3, Cyberpunk2077, F12023, and Horizon Zero Dawn. All games tested at 1080p resolution. System manufacturers may vary configurations, yielding different results. GNR-07



ES模塊(ESM)、與傳統Webpack對比、Rollup打包)












-- 基礎概念)
![week1-[分支結構]中位數](http://pic.xiahunao.cn/week1-[分支結構]中位數)
![[激光原理與應用-259]:理論 - 幾何光學 - 平面鏡的反射、平面透鏡的折射、平面鏡的反射成像、平面透鏡的成像的規律](http://pic.xiahunao.cn/[激光原理與應用-259]:理論 - 幾何光學 - 平面鏡的反射、平面透鏡的折射、平面鏡的反射成像、平面透鏡的成像的規律)
