神經網絡作為深度學習的核心技術,其復雜性常常令人望而卻步。然而,盡管神經網絡的結構、參數和計算過程看似繁瑣,但其核心組件卻是相對簡潔且易于理解的。本文將深入探討神經網絡的四大核心組件——層、模型、損失函數與優化器,并通過PyTorch的nn工具箱構建一個神經網絡的實例,幫助讀者更好地理解這些組件之間的關系及其在實際應用中的作用。
一、神經網絡的核心組件
1. 層(Layer)
層是神經網絡最基本的構建單元,負責將輸入張量(Tensor)轉換為輸出張量。常見的層包括全連接層(Dense Layer)、卷積層(Convolutional Layer)、池化層(Pooling Layer)和歸一化層(Normalization Layer)等。每一層都有其特定的功能,例如:
- 全連接層:用于處理結構化數據,在分類任務中廣泛應用。
- 卷積層:擅長提取圖像中的局部特征,是計算機視覺任務的核心。
- 池化層:用于降低數據維度,減少計算量。
- 激活層:引入非線性因素,使神經網絡能夠擬合復雜函數。
在PyTorch中,torch.nn模塊提供了豐富的層類,例如nn.Linear、nn.Conv2d、nn.MaxPool2d等,開發者只需按需調用即可。
2. 模型(Model)
模型是多個層的組合,構成了神經網絡的整體結構。它定義了數據的流動路徑,從輸入到輸出的轉換過程。一個典型的模型可能包括輸入層、隱藏層和輸出層。在PyTorch中,可以通過繼承nn.Module類來定義模型,并在__init__方法中初始化各層,在forward方法中定義前向傳播邏輯。
例如,一個簡單的全連接神經網絡模型可以定義如下:
import torch.nn as nnclass SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.layer1 = nn.Linear(10, 50)self.layer2 = nn.Linear(50, 1)def forward(self, x):x = torch.relu(self.layer1(x))return self.layer2(x)
3. 損失函數(Loss Function)
損失函數是模型學習的目標函數,用于衡量模型預測值與真實值之間的差異。損失函數的值越小,表示模型的預測越接近真實值。常見的損失函數包括:
- 均方誤差(MSE):適用于回歸任務。
- 交叉熵損失(Cross-Entropy Loss):適用于分類任務。
- 二元交叉熵損失(Binary Cross-Entropy Loss):適用于二分類任務。
在PyTorch中,損失函數可以通過torch.nn模塊調用,例如nn.MSELoss()或nn.CrossEntropyLoss()。
4. 優化器(Optimizer)
優化器負責通過調整模型的權重參數來最小化損失函數。常見的優化器包括:
- 隨機梯度下降(SGD):最基礎的優化算法,簡單但收斂速度較慢。
- Adam:自適應學習率優化器,適用于大多數任務。
- RMSprop:適合處理非平穩目標函數。
在PyTorch中,優化器可以通過torch.optim模塊調用,例如optim.Adam(model.parameters(), lr=0.001)。
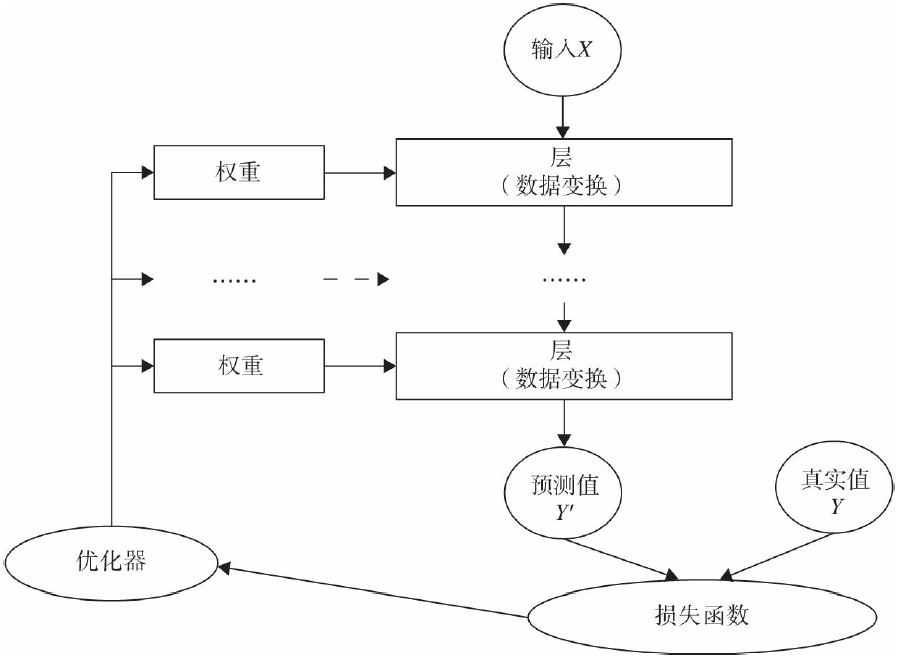
二、核心組件的相互關系
這些核心組件之間并非孤立存在,而是通過緊密協作構成了神經網絡的完整學習過程:
- 數據流動:輸入數據通過模型中的各層進行轉換,最終生成預測值。
- 損失計算:預測值與真實值通過損失函數進行比較,得到損失值。
- 參數更新:優化器利用損失值計算梯度,并更新模型的權重參數。
- 循環迭代:上述過程不斷重復,直到損失值達到預設的閾值或訓練輪次(epoch)結束。
這一過程可以用下圖直觀表示:
三、基于PyTorch的神經網絡實例
為了更直觀地展示上述核心組件的使用方法,我們以一個簡單的回歸任務為例,構建一個基于PyTorch的神經網絡。
1. 數據準備
我們生成一組隨機數據,用于訓練和測試。
import torch
import torch.optim as optim生成隨機數據
X = torch.randn(100, 10)
y = torch.randn(100, 1)
2. 定義模型
我們使用之前定義的SimpleModel類。
model = SimpleModel()
3. 定義損失函數和優化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
4. 訓練模型
我們進行100輪訓練,每輪計算損失并更新參數。
for epoch in range(100):# 前向傳播outputs = model(X)loss = criterion(outputs, y)# 反向傳播和優化optimizer.zero_grad()loss.backward()optimizer.step()if (epoch+1) % 10 == 0:print(f'Epoch {epoch+1}, Loss: {loss.item():.4f}')
5. 評估模型
訓練完成后,我們可以使用測試數據評估模型性能。
test_data = torch.randn(10, 10)
predictions = model(test_data)
print(predictions)
四、總結
神經網絡雖然復雜,但其核心組件相對簡單且功能明確。通過理解層、模型、損失函數與優化器這四個關鍵部分,我們可以快速構建和訓練神經網絡模型。PyTorch的nn工具箱為我們提供了豐富的現成類和函數,極大簡化了開發流程。掌握這些核心概念和工具的使用,是深入學習深度學習的第一步。
未來,隨著對神經網絡理解的加深,我們可以進一步探索更復雜的模型結構、優化策略和損失函數設計,從而應對更復雜的問題和數據集。






Texlive(環境)Vscode(編輯器)環境配置與安裝)
】 GPIO 深度解析:引腳特性、工作模式、速度選型及上下拉電阻詳解)









![[GESP202309 六級] 2023年9月GESP C++六級上機題題解,附帶講解視頻!](http://pic.xiahunao.cn/[GESP202309 六級] 2023年9月GESP C++六級上機題題解,附帶講解視頻!)

